CAPER: Clause-Aligned Process Supervision for Text-to-SQL
Pith reviewed 2026-06-28 08:08 UTC · model grok-4.3
The pith
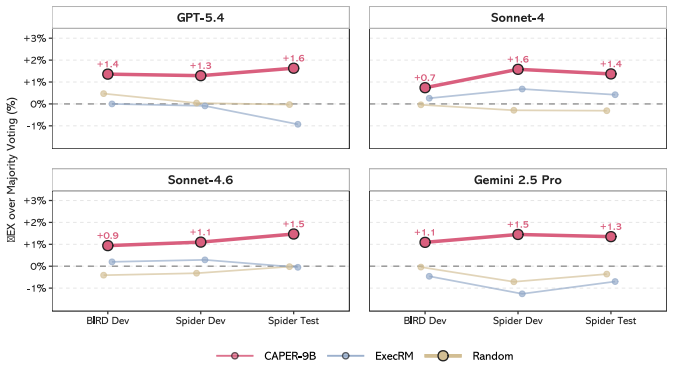
Clause-level supervision derived from SQL syntax trees raises Text-to-SQL execution accuracy up to 15.3 percent relative and reaches 84.53 percent failure localization accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAPER automatically derives clause-level supervision via counterfactual intervention on the SQL abstract syntax tree, enabling root-cause error localization for reward modeling; the resulting data is used to train CAPER-9B, a lightweight Clause-PRM that provides clause-boundary feedback for policy optimization and candidate verification. Experiments on BIRD and Spider show that clause-aligned supervision not only improves execution accuracy, achieving up to a 15.3% relative EX improvement over GPT-5.4, but also strengthens failure-localization capability, reaching 84.53% accuracy and 90.60% MRR on held-out failures.
What carries the argument
Clause-level supervision signals obtained by counterfactual intervention on the SQL abstract syntax tree
If this is right
- Execution accuracy improves by up to 15.3 percent relative to GPT-5.4 on BIRD and Spider.
- Failure localization reaches 84.53 percent accuracy and 90.60 percent MRR on held-out errors.
- Clause-boundary feedback supports both policy optimization and candidate verification.
- The same supervision data can be reused to train lightweight process reward models.
Where Pith is reading between the lines
- The clause-labeling technique could transfer to other structured generation domains such as code synthesis where token boundaries do not match semantic units.
- Clause supervision may lower the cost of creating training signals compared with full query execution or human token annotation.
- Larger base models fine-tuned with the same clause signals might show amplified gains on queries with deep nesting or multiple joins.
Load-bearing premise
Counterfactual intervention on the SQL abstract syntax tree produces clause-level labels that accurately reflect semantic decision points without systematically biasing error localization or reward modeling.
What would settle it
Train a Clause-PRM and a query-level baseline on the same data, then measure whether the clause model shows no gain in execution accuracy or localization MRR on a held-out set of complex nested queries from BIRD or Spider.
Figures




read the original abstract
Text-to-SQL systems are typically evaluated by query-level execution correctness, but this terminal signal provides little guidance about which intermediate SQL decision caused success or failure. Token-level dense supervision is also ill-suited: SQL tokens do not align with complete semantic decisions, can penalize execution-equivalent queries, and are difficult to label reliably at scale. We therefore propose CAPER, which automatically derives clause-level supervision via counterfactual intervention on the SQL abstract syntax tree, enabling root-cause error localization for reward modeling; the resulting data is used to train CAPER-9B, a lightweight Clause-PRM that provides clause-boundary feedback for policy optimization and candidate verification. Experiments on BIRD and Spider show that clause-aligned supervision not only improves execution accuracy, achieving up to a 15.3% relative EX improvement over GPT-5.4, but also strengthens failure-localization capability, reaching 84.53% accuracy and 90.60% MRR on held-out failures. Our project page is at https://github.com/banrichard/RL-NL2SQL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAPER, a framework that automatically derives clause-level supervision signals for Text-to-SQL via counterfactual intervention on the SQL abstract syntax tree. These signals train a lightweight Clause-PRM (CAPER-9B) used for policy optimization and candidate verification. Experiments on BIRD and Spider report up to 15.3% relative execution accuracy improvement over GPT-5.4 together with 84.53% failure-localization accuracy and 90.60% MRR on held-out failures.
Significance. If the clause-level labels prove reliable, the work supplies a concrete mechanism for moving beyond query-level terminal rewards toward process supervision in semantic parsing, which could improve both accuracy and error diagnosis in NL2SQL pipelines. The public GitHub release supports reproducibility.
major comments (2)
- [Section describing the counterfactual intervention and label generation] The central performance and localization claims rest on the assumption that counterfactual AST interventions isolate semantically meaningful decision points without systematic attribution bias (e.g., favoring SELECT over WHERE clauses). The manuscript provides no human validation, inter-annotator agreement, or ablation against alternative labeling procedures to demonstrate that the generated clause labels are independent of the automated procedure itself.
- [Experiments section and associated tables] Table reporting the 15.3% relative EX gain and the 84.53%/90.60% localization metrics: the results are presented without baseline implementation details, statistical significance tests, controls for data leakage between training and held-out failures, or sensitivity analysis to the precise clause-boundary definitions, leaving open whether the reported improvements are attributable to clause-aligned supervision.
minor comments (1)
- [Abstract and §4] The abstract and method sections use “GPT-5.4” without clarifying whether this refers to a specific model version or a typographical reference; consistent naming with the experimental tables would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the reliability of the clause-level labels and the experimental reporting. We address each major comment below with specific plans for revision.
read point-by-point responses
-
Referee: [Section describing the counterfactual intervention and label generation] The central performance and localization claims rest on the assumption that counterfactual AST interventions isolate semantically meaningful decision points without systematic attribution bias (e.g., favoring SELECT over WHERE clauses). The manuscript provides no human validation, inter-annotator agreement, or ablation against alternative labeling procedures to demonstrate that the generated clause labels are independent of the automated procedure itself.
Authors: We acknowledge the absence of human validation and ablations in the current manuscript. The counterfactual procedure is designed to isolate clause-level semantic differences via AST edits that preserve execution equivalence for the original query, which inherently ties labels to verifiable outcomes rather than arbitrary attribution. To address the concern directly, the revised version will add (1) an ablation comparing our labels against random clause assignment and token-level alternatives, and (2) a small-scale human validation study reporting inter-annotator agreement on a sampled subset of generated labels. These additions will quantify independence from the automated procedure. revision: partial
-
Referee: [Experiments section and associated tables] Table reporting the 15.3% relative EX gain and the 84.53%/90.60% localization metrics: the results are presented without baseline implementation details, statistical significance tests, controls for data leakage between training and held-out failures, or sensitivity analysis to the precise clause-boundary definitions, leaving open whether the reported improvements are attributable to clause-aligned supervision.
Authors: We agree that the experimental section requires additional rigor. In the revision we will: provide full baseline implementation details and hyperparameters in an appendix; report statistical significance using McNemar's test on execution accuracy differences; explicitly document the train/held-out failure split procedure (including that held-out failures are drawn from a disjoint set of queries with no overlap in underlying database instances); and include a sensitivity analysis that varies clause-boundary definitions (e.g., treating subqueries as single vs. separate clauses) to confirm robustness. These changes will strengthen attribution of gains to clause-aligned supervision. revision: yes
Circularity Check
No circularity; supervision derived from external execution outcomes on held-out data.
full rationale
The paper derives clause-level labels via counterfactual AST intervention grounded in execution results, then reports EX gains and localization metrics on held-out failures. No equations, self-citations, or definitions in the provided text reduce the reported performance numbers or localization accuracy to quantities defined by the labeling procedure itself. The chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of text-to-sql in the era of llms: Where are we, and where are we going?IEEE Transactions on Knowledge and Data Engineering, 37(10):5735–5754,
Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, and Yuyu Luo. A survey of text-to-sql in the era of llms: Where are we, and where are we going?IEEE Transactions on Knowledge and Data Engineering, 37(10):5735–5754,
-
[2]
URL https://dblp.org/rec/journals/tkde/ LiuSLMJZFLTL25
doi: 10.1109/TKDE.2025.3592032. URL https://dblp.org/rec/journals/tkde/ LiuSLMJZFLTL25
-
[3]
Next-generation database interfaces: A survey of llm-based text-to-sql.IEEE Transactions on Knowledge and Data Engineering, 2025
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang. Next-generation database interfaces: A survey of llm-based text-to-sql.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[4]
Deepeye: A data science system for monitoring and exploring covid-19 data.IEEE Data Eng
Yuyu Luo, Nan Tang, Guoliang Li, Wenbo Li, Tianyu Zhao, and Xiang Yu. Deepeye: A data science system for monitoring and exploring covid-19 data.IEEE Data Eng. Bull., 43(2): 121–132, 2020
2020
-
[5]
Steerable self-driving data visualization.IEEE Transactions on Knowledge and Data Engineering, 34(1): 475–490, 2020
Yuyu Luo, Xuedi Qin, Chengliang Chai, Nan Tang, Guoliang Li, and Wenbo Li. Steerable self-driving data visualization.IEEE Transactions on Knowledge and Data Engineering, 34(1): 475–490, 2020
2020
-
[6]
Starqa: A question answering dataset for complex analytical reasoning over structured databases
Mounica Maddela, Lingjue Xie, Daniel Preo¸ tiuc-Pietro, et al. Starqa: A question answering dataset for complex analytical reasoning over structured databases. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34475–34487, 2025
2025
-
[7]
Quest: a natural language interface to relational databases
Vadim Sheinin, Elahe Khorashani, Hangu Yeo, Kun Xu, Ngoc Phuoc An V o, and Octavian Popescu. Quest: a natural language interface to relational databases. InProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), 2018
2018
-
[8]
ADEPT-SQL: A high-performance text-to-SQL application for real-world enterprise-level databases
Yongnan Chen, Zhuo Chang, Shijia Gu, Yuanhang Zong, Mei Zhang, Shiyu Wang, Zixiang He, HongZhi Chen, Wei Jin, and Bin Cui. ADEPT-SQL: A high-performance text-to-SQL application for real-world enterprise-level databases. In Pushkar Mishra, Smaranda Mure- san, and Tao Yu, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Li...
-
[9]
Abacus- sql: a text-to-sql system empowering cross-domain and open-domain database retrieval
Keyan Xu, Dingzirui Wang, Xuanliang Zhang, Qingfu Zhu, and Wanxiang Che. Abacus- sql: a text-to-sql system empowering cross-domain and open-domain database retrieval. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 118–128, 2025
2025
-
[10]
Hoi, Richard Socher, Caiming Xiong, Michael Lyu, and Irwin King
Jichuan Zeng, Xi Victoria Lin, Steven C.H. Hoi, Richard Socher, Caiming Xiong, Michael Lyu, and Irwin King. Photon: A robust cross-domain text-to-SQL system. In Asli Celikyilmaz and Tsung-Hsien Wen, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 204–214, Online, July 2020. Asso...
-
[11]
Swe-sql: Illuminating llm pathways to solve user sql issues in real- world applications
Jinyang Li, Xiaolong Li, Ge Qu, Per Jacobsson, Bowen Qin, Binyuan Hui, Shuzheng Si, Nan Huo, Xiaohan Xu, Yue Zhang, Ziwei Tang, Yuanshuai Li, Florensia Widjaja, Xintong Zhu, Feige Zhou, Yongfeng Huang, Yannis Papakonstantinou, Fatma Ozcan, Ma Chenhao, and Reynold Cheng. Swe-sql: Illuminating llm pathways to solve user sql issues in real- world application...
2025
-
[12]
BIRD-INTERACT: Re-imagining text-to- SQL evaluation via lens of dynamic interactions
Nan Huo, Xiaohan Xu, Jinyang Li, Per Jacobsson, Shipei Lin, Bowen Qin, Binyuan Hui, Xiaolong Li, Ge Qu, Shuzheng Si, Linheng Han, Edward Alexander, Xintong Zhu, Rui Qin, Ruihan Yu, Yiyao Jin, Feige Zhou, Weihao Zhong, Yun Chen, Hongyu Liu, Chenhao Ma, Fatma Ozcan, Yannis Papakonstantinou, and Reynold Cheng. BIRD-INTERACT: Re-imagining text-to- SQL evaluat...
2026
-
[13]
Linkalign: Scalable schema linking for real-world large-scale multi-database text-to-sql
Yihan Wang, Peiyu Liu, and Xin Yang. Linkalign: Scalable schema linking for real-world large-scale multi-database text-to-sql. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 977–991, 2025
2025
-
[14]
Re-appraising the schema linking for text- to-SQL
Yujian Gan, Xinyun Chen, and Matthew Purver. Re-appraising the schema linking for text- to-SQL. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: ACL 2023, pages 835–852, Toronto, Canada, July
2023
-
[15]
doi: 10.18653/v1/2023.findings-acl.53
Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.53. URL https://aclanthology.org/2023.findings-acl.53/
-
[16]
CRUSH4SQL: Collective retrieval using schema hallucination for Text2SQL
Mayank Kothyari, Dhruva Dhingra, Sunita Sarawagi, and Soumen Chakrabarti. CRUSH4SQL: Collective retrieval using schema hallucination for Text2SQL. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14054–14066, Singapore, 2023. Association for Computational Li...
-
[17]
Ucs-sql: uniting content and structure for enhanced semantic bridging in text-to-sql
Zhenhe Wu, Zhongqiu Li, Jie Zhang, Zhongjiang He, Jian Yang, Yu Zhao, Ruiyu Fang, Bing Wang, Hongyan Xie, Shuangyong Song, et al. Ucs-sql: uniting content and structure for enhanced semantic bridging in text-to-sql. InFindings of the Association for Computational Linguistics: ACL 2025, pages 8156–8168, 2025
2025
-
[18]
Ts-sql: Test-driven self-refinement for text-to-sql
Wenbo Xu, Haifeng Zhu, Liang Yan, Chuanyi Liu, Peiyi Han, Shaoming Duan, and Jeff Z Pan. Ts-sql: Test-driven self-refinement for text-to-sql. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 2864–2889, 2025
2025
-
[19]
Share: An slm-based hierarchical action correction assistant for text-to-sql
Ge Qu, Jinyang Li, Bowen Qin, Xiaolong Li, Nan Huo, Chenhao Ma, and Reynold Cheng. Share: An slm-based hierarchical action correction assistant for text-to-sql. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11268–11292, 2025
2025
-
[20]
Omnisql: Synthesizing high-quality text-to-sql data at scale.Proceedings of the VLDB Endowment, 18(11):4695–4709, 2025
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, et al. Omnisql: Synthesizing high-quality text-to-sql data at scale.Proceedings of the VLDB Endowment, 18(11):4695–4709, 2025
2025
-
[21]
Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chen-Chuan Chang, Fei Huang, Reynold Cheng, and Yongbin Li. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. InAdvances in Neural Information P...
-
[22]
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 83fc8fab1710363050bbd1d4b8cc0021-Abstract-Datasets_and_Benchmarks.html
2023
-
[23]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,...
-
[24]
Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin SU, ZHAOQING SUO, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows. InThe Thirteenth International Conference on Learning Representa...
2025
-
[25]
Weakly supervised text-to-SQL pars- ing through question decomposition
Tomer Wolfson, Daniel Deutch, and Jonathan Berant. Weakly supervised text-to-SQL pars- ing through question decomposition. InFindings of the Association for Computational Linguistics: NAACL 2022, pages 2528–2542, Seattle, United States, July 2022. Associ- ation for Computational Linguistics. doi: 10.18653/v1/2022.findings-naacl.193. URL https://aclantholo...
-
[26]
ExeSQL: Self-taught text-to-SQL models with execution-driven bootstrapping for SQL dialects
Jipeng Zhang, Haolin Yang, Kehao Miao, Ruiyuan Zhang, Renjie Pi, Jiahui Gao, and Xiaofang Zhou. ExeSQL: Self-taught text-to-SQL models with execution-driven bootstrapping for SQL dialects. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 24305–24326, Suzhou, China, November 2025. Association for Computational Linguistics. ISB...
-
[27]
Culture is everywhere: A call for intentionally cultural evaluation
Mingqian He, Yongliang Shen, Wenqi Zhang, Qiuying Peng, Jun Wang, and Weiming Lu. Star-sql: Self-taught reasoner for text-to-sql. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 24365–24375, Vienna, Austria, 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025. acl-...
-
[28]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Victor Zhong, Caiming Xiong, and Richard Socher. Seq2sql: Generating structured queries from natural language using reinforcement learning.CoRR, abs/1709.00103, 2017. doi: 10.48550/arXiv.1709.00103. URLhttps://arxiv.org/abs/1709.00103
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1709.00103 2017
-
[29]
Sql-r1: Training natural language to sql reasoning model by reinforcement learning
Ma Peixian, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, and Jian Guo. Sql-r1: Training natural language to sql reasoning model by reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[30]
Arctic-text2sql-r1: Simple rewards, strong reasoning in text-to-sql, 2025
Zhewei Yao, Guoheng Sun, Lukasz Borchmann, Gaurav Nuti, Zheyu Shen, Minghang Deng, Bohan Zhai, Hao Zhang, Ang Li, and Yuxiong He. Arctic-text2sql-r1: Simple rewards, strong reasoning in text-to-sql, 2025. URLhttps://arxiv.org/abs/2505.20315
arXiv 2025
-
[31]
Han Weng, Puzhen Wu, Cui Longjie, Yi Zhan, Boyi Liu, Yuanfeng Song, Dun Zeng, Yingx- iang Yang, Qianru Zhang, Dong Huang, Xiaoming Yin, Yang Sun, and Xing Chen. Graph- reward-SQL: Execution-free reinforcement learning for text-to-SQL via graph matching and stepwise reward. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 1291...
-
[32]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[33]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[34]
Claude Sonnet 4, 2025
Anthropic. Claude Sonnet 4, 2025. URLhttps://www.anthropic.com/news/claude-4
2025
-
[35]
Introducing GPT-5.4, March 2026
OpenAI. Introducing GPT-5.4, March 2026. URL https://openai.com/index/ introducing-gpt-5-4/
2026
-
[36]
Introducing Claude Sonnet 4.6, February 2026
Anthropic. Introducing Claude Sonnet 4.6, February 2026. URL https://www.anthropic. com/research/claude-sonnet-4-6
2026
-
[37]
DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework
Boyan Li, Chong Chen, Zhujun Xue, Yinan Mei, and Yuyu Luo. Deepeye-sql: A software- engineering-inspired text-to-sql framework. 2025. doi: 10.48550/arXiv.2510.17586. URL https://arxiv.org/abs/2510.17586
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.17586 2025
-
[38]
Yifu Liu, Yin Zhu, Yingqi Gao, Zhiling Luo, Xiaoxia Li, Xiaorong Shi, Yuntao Hong, Jinyang Gao, Yu Li, Bolin Ding, and Jingren Zhou. Xiyan-sql: A novel multi-generator framework for text-to-sql.IEEE Transactions on Knowledge and Data Engineering, pages 1–14, 2026. doi: 10.1109/TKDE.2026.3657851
-
[39]
Alpha-SQL: Zero-shot text-to-SQL using Monte Carlo tree search
Boyan Li, Jiayi Zhang, Ju Fan, Yanwei Xu, Chong Chen, Nan Tang, and Yuyu Luo. Alpha-SQL: Zero-shot text-to-SQL using Monte Carlo tree search. InProceedings of the 42nd Interna- tional Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 36810–36830. PMLR, 2025. URL https://proceedings.mlr.press/ v267/li25dt.html. 12
2025
-
[40]
Qwen3.5: Towards native multimodal agents, 2026
QwenTeam. Qwen3.5: Towards native multimodal agents, 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[41]
Towards complex text-to-sql in cross-domain database with intermediate representation
Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, and Dongmei Zhang. Towards complex text-to-sql in cross-domain database with intermediate representation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4524–4535, Florence, Italy, 2019. Association for Computational Linguistics. doi: 1...
-
[42]
Rat- sql: Relation-aware schema encoding and linking for text-to-sql parsers
Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson. Rat- sql: Relation-aware schema encoding and linking for text-to-sql parsers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7567–7578, Online, 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main...
-
[43]
Picard: Parsing incrementally for constrained auto-regressive decoding from language models
Torsten Scholak, Nathan Schucher, and Dzmitry Bahdanau. Picard: Parsing incrementally for constrained auto-regressive decoding from language models. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 9895–9901, Online and Punta Cana, Dominican Republic, 2021. Association for Computational Linguistics. doi: 10. ...
2021
-
[44]
Din-sql: Decomposed in-context learning of text- to-sql with self-correction
Mohammadreza Pourreza and Davood Rafiei. Din-sql: Decomposed in-context learning of text- to-sql with self-correction. InAdvances in Neural Information Processing Systems, volume 36, pages 36339–36348, 2023. URL https://proceedings.neurips.cc/paper_files/ paper/2023/file/72223cc66f63ca1aa59edaec1b3670e6-Paper-Conference.pdf
2023
-
[45]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. Text-to-sql empowered by large language models: A benchmark evaluation.Proceedings of the VLDB Endowment, 17(5):1132–1145, 2024. doi: 10.14778/3641204.3641221. URL https://dblp.org/rec/journals/pvldb/GaoWLSQDZ24
-
[46]
Recent advances in text-to-sql: A survey of what we have and what we expect
Naihao Deng, Yulong Chen, and Yue Zhang. Recent advances in text-to-sql: A survey of what we have and what we expect. InProceedings of the 29th International Conference on Computational Linguistics, pages 2166–2187, Gyeongju, Republic of Korea, 2022. International Committee on Computational Linguistics. URLhttps://aclanthology.org/2022.coling-1.190/
2022
-
[47]
Counterfactual risk minimization: Learning from logged bandit feedback
Adith Swaminathan and Thorsten Joachims. Counterfactual risk minimization: Learning from logged bandit feedback. InProceedings of the 32nd International Conference on Machine Learn- ing, volume 37 ofProceedings of Machine Learning Research, pages 814–823, Lille, France,
-
[48]
URLhttps://proceedings.mlr.press/v37/swaminathan15.html
PMLR. URLhttps://proceedings.mlr.press/v37/swaminathan15.html
-
[49]
Bayesian counterfactual risk minimization
Ben London and Ted Sandler. Bayesian counterfactual risk minimization. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 4125–4133. PMLR, 2019. URL https://proceedings. mlr.press/v97/london19a.html
2019
-
[50]
Se- quential counterfactual risk minimization
Houssam Zenati, Eustache Diemert, Matthieu Martin, Julien Mairal, and Pierre Gaillard. Se- quential counterfactual risk minimization. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 40681– 40706. PMLR, 2023. URLhttps://proceedings.mlr.press/v202/zenati23a.html
2023
-
[51]
Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson
Jakob N. Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, pages 2974–2982. AAAI Press, 2018. doi: 10.1609/ AAAI.V32I1.11794. URLhttps://dblp.org/rec/conf/aaai/FoersterFANW18.html
2018
-
[52]
Counterfactual off-policy evaluation with gumbel-max structural causal models
Michael Oberst and David Sontag. Counterfactual off-policy evaluation with gumbel-max structural causal models. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 4881–4890. PMLR,
-
[53]
URLhttps://proceedings.mlr.press/v97/oberst19a.html. 13
-
[54]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback. 2022. doi: 10.48550/ARXIV .2211.14275. URL https://arxiv.org/abs/2211.14275
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2022
-
[55]
Reward- SQL: Boosting text-to-SQL via stepwise reasoning and process-supervised rewards, 2025
Yuxin Zhang, Meihao Fan, Ju Fan, Mingyang Yi, Yuyu Luo, Jian Tan, and Guoliang Li. Reward- SQL: Boosting text-to-SQL via stepwise reasoning and process-supervised rewards, 2025. URL https://arxiv.org/abs/2505.04671
arXiv 2025
-
[56]
SQLCritic: Correcting text-to-SQL generation via clause-wise critic, 2025
Jikai Chen, Leilei Gan, Ziyu Zhao, Zechuan Wang, Dong Wang, and Chenyi Zhuang. SQLCritic: Correcting text-to-SQL generation via clause-wise critic, 2025. URL https://arxiv.org/ abs/2503.07996. 14 A Limitations While our proposed method demonstrates significant improvements in Text-to-SQL reinforcement learning, there are several limitations to consider. F...
arXiv 2025
-
[57]
You must output exactly one <think>...</think> block followed by one <answer>...</answer> block
-
[58]
‘‘‘ block containing runnable SQLite SQL
Inside <answer>, include exactly one ‘‘‘sql ... ‘‘‘ block containing runnable SQLite SQL
-
[59]
Do not output any text before <think> or after </answer>
-
[60]
Do not use <sql>...</sql>
-
[61]
""sql -- Your SQL query
Keep <think> concise (<=120 words) so the final <answer> is never dropped. Evidence: location coordinates refers to (lat, lng); the US refers to country = ’USA’; Instructions: - Make sure you only output the information that is asked in the question. If the question asks for a specific column, make sure to only include that column in the SELECT clause, no...
-
[62]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.