GPU-Parallel Multi-Task Reinforcement Learning with Demonstration Guided Policy Optimization
Pith reviewed 2026-06-28 09:44 UTC · model grok-4.3
The pith
DGPO combines PPO with adaptive behavior cloning to let multi-task robot policies prefer demonstrated task distributions to a tunable degree.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
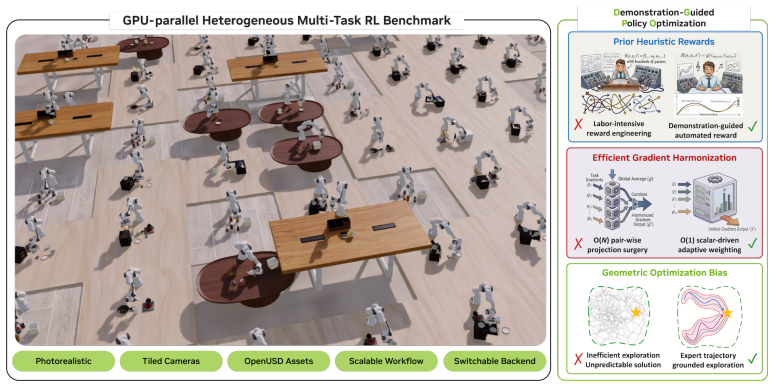
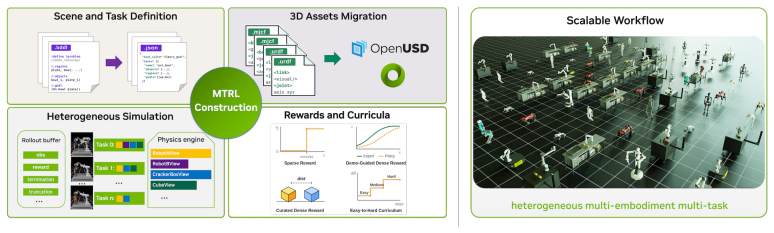
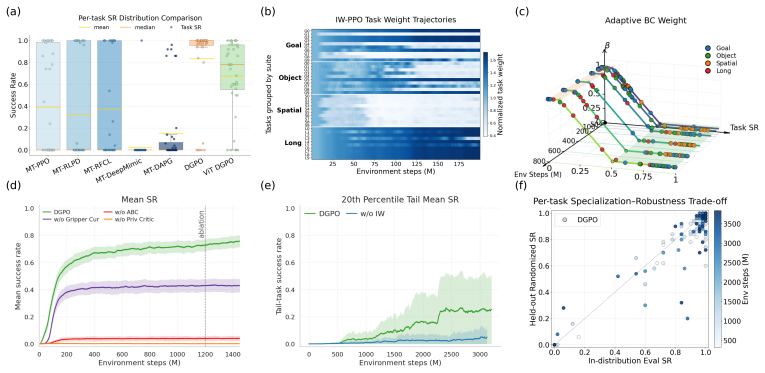
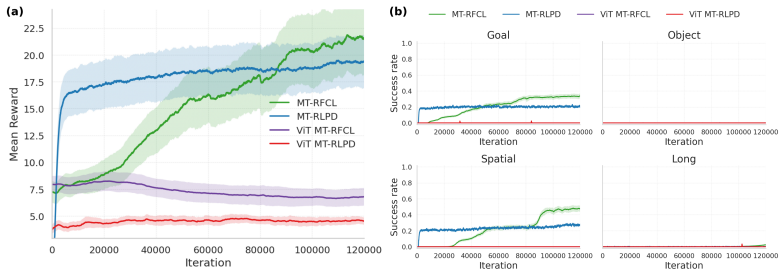
DGPO is an on-policy demonstration guided method that combines importance weighted PPO with adaptive behavior cloning on matched demonstration actions. It enables a tunable preference toward demonstrated task distributions, outperforming both prior-free RL and existing demonstration-based methods while preserving the stability and online improvement benefits of on-policy PPO. The supporting benchmark MT-Libero is built by a construction methodology that converts structured manipulation task families into GPU-parallel environments supporting simultaneous heterogeneous training.
What carries the argument
DGPO (Demonstration Guided Policy Optimization), which integrates importance-weighted PPO with adaptive behavior cloning on matched demonstration actions to control the strength of preference for demonstrated behaviors.
If this is right
- Simultaneous reinforcement learning over heterogeneous task suites becomes practical with parallel rendering, physics randomization, and support for state-input or visual-input policies.
- Policies gain a controllable bias toward demonstrated task distributions without giving up the ability to improve online through PPO updates.
- Sparse success signals in multi-task robot manipulation can be addressed by blending on-policy RL with adaptive cloning on available demonstration actions.
- The same training run can handle multiple tasks at once while still allowing per-task specialization through the tunable preference mechanism.
Where Pith is reading between the lines
- The benchmark construction approach could be applied to other simulation platforms or task domains beyond manipulation to create additional large-scale parallel training suites.
- Tunable demonstration preference might reduce the sample complexity needed for real-robot fine-tuning after simulation training.
- If the importance weighting in DGPO can be adjusted dynamically per task, it could enable automatic balancing across task difficulties within one training run.
Load-bearing premise
The construction methodology can turn arbitrary structured manipulation task families into GPU-parallel benchmarks that support simultaneous heterogeneous training with matched demonstration actions for the adaptive behavior cloning component.
What would settle it
A direct comparison in MT-Libero where DGPO either loses PPO-style stability during training or fails to exceed the success rates of prior-free PPO and existing demonstration methods across the task suite.
Figures


read the original abstract
Large scale GPU-parallel reinforcement learning has changed what can be trained in robot simulation, yet most systems still optimize one specialist policy per task. We propose a construction methodology for turning structured manipulation task families into GPU-parallel multi-task RL benchmarks, and instantiate it as MT-Libero using LIBERO assets and task predicates in Isaac Lab. The resulting benchmark supports simultaneous reinforcement learning over heterogeneous task suites with parallel rendering, physics randomization, and state-input or visual-input policies. To make such training practical under sparse success signals and limited prior data, we further propose DGPO, an on-policy demonstration guided method that combines importance weighted PPO with adaptive behavior cloning on matched demonstration actions. DGPO enables a tunable preference toward demonstrated task distributions, outperforming both prior-free RL and existing demonstration-based methods while preserving the stability and online improvement benefits of on-policy PPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide a construction methodology for turning structured manipulation task families into GPU-parallel multi-task RL benchmarks, instantiated as MT-Libero using LIBERO assets and task predicates in Isaac Lab. This benchmark supports simultaneous heterogeneous training with parallel rendering, physics randomization, and state or visual policies. It further proposes DGPO, an on-policy method combining importance-weighted PPO with adaptive behavior cloning on matched demonstration actions, which enables a tunable preference toward demonstrated task distributions and is claimed to outperform both prior-free RL and existing demonstration-based methods while preserving PPO stability and online improvement benefits.
Significance. If the empirical claims hold, the work could meaningfully advance scalable multi-task robot learning by enabling efficient GPU-parallel training across heterogeneous tasks with tunable demonstration guidance under sparse rewards. The on-policy formulation and preservation of PPO's stability properties address a practical need in robotics where demonstrations are available but must be balanced with continued online improvement.
major comments (1)
- Abstract: The abstract asserts outperformance over prior-free RL and existing demonstration-based methods, but supplies no experimental details, metrics, baselines, or statistical evidence, so the data-to-claim link cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the need to strengthen the connection between claims and evidence in the abstract. We address this point below.
read point-by-point responses
-
Referee: Abstract: The abstract asserts outperformance over prior-free RL and existing demonstration-based methods, but supplies no experimental details, metrics, baselines, or statistical evidence, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract, in its current form, states the performance claims at a high level without referencing specific metrics or baselines. While abstracts are necessarily concise, we acknowledge that this can make it difficult for readers to immediately assess the strength of the empirical support. In the revised manuscript we will update the abstract to include a brief mention of the primary evaluation metrics (success rate under sparse rewards), the main baselines (prior-free PPO and standard behavior cloning variants), and the key result that DGPO achieves higher average success across the MT-Libero task suite while retaining on-policy stability. Full tables, statistical details, and ablation studies remain in Sections 4 and 5. revision: yes
Circularity Check
No significant circularity; method combines established PPO and BC components with empirical validation
full rationale
The paper proposes a benchmark construction (MT-Libero) and DGPO as an on-policy combination of importance-weighted PPO with adaptive behavior cloning. No equations or claims reduce a prediction or result to its own fitted inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present in the provided abstract or description. The central claims rest on empirical outperformance rather than definitional equivalence. This is the expected honest non-finding for a methods paper that extends standard RL primitives without internal reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- tunable preference weight
axioms (1)
- domain assumption Demonstration actions can be reliably matched to the current policy's action space across heterogeneous tasks
invented entities (2)
-
MT-Libero benchmark
no independent evidence
-
DGPO algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
D’Eramo, D
C. D’Eramo, D. Tateo, A. Bonarini, M. Restelli, and J. Peters. Sharing knowledge in multi-task deep reinforcement learning. InInternational Conference on Learning Representations, 2020
2020
-
[2]
Z. Xu, Z. Xu, R. Jiang, P. Stone, and A. Tewari. Sample efficient myopic exploration through multitask reinforcement learning with diverse tasks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T.-K. Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Demonstrating GPU Parallelized Robot Simulation and Rendering for Generalizable Embodied AI with ManiSkill3. InProceedings o...
-
[4]
Joshi, Z
V . Joshi, Z. Xu, B. Liu, P. Stone, and A. Zhang. Benchmarking massively parallelized multi- task reinforcement learning for robotics tasks, 2025. URLhttps://arxiv.org/abs/2507. 23172
2025
-
[5]
Janwani, E
N. Janwani, E. Novoseller, V . J. Lawhern, and M. Tucker. Mo-playground: Massively paral- lelized multi-objective reinforcement learning for robotics, 2026
2026
-
[6]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, vol- ume 36, pages 44776–44791. Curran Associates, Inc., 2023
2023
-
[7]
Mittal, P
NVIDIA, :, M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G....
2025
-
[8]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In L. P. Kaelbling, D. Kragic, and K. Sugiura, editors,Proceedings of the Conference on Robot Learning, volume 100 ofProceedings of Machine Learning Research, pages 1094–1100. PMLR, 30 Oct–01 Nov 2020
2020
-
[9]
McLean, E
R. McLean, E. Chatzaroulas, L. McCutcheon, F. R ¨oder, T. Yu, Z. He, K. Zentner, R. Julian, J. K. Terry, I. Woungang, N. Farsad, and P. S. Castro. Meta-world+: An improved, standard- ized, RL benchmark. InThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems Datasets and Benchmarks Track, 2026
2026
-
[10]
H. Geng, F. Wang, S. Wei, Y . Li, B. Wang, B. An, H. Lou, C. T. Cheng, P. Li, H. Chen, Y . Liang, Y . Qian, J. Mao, W. Wan, Y . Geng, M. Zhang, J. Lyu, S. Zhao, J. Zhang, C. Xu, J. Zhang, C. Zhao, H. Lu, Y . Ding, R. Gong, Y . Wang, Y . Kuang, R. Wu, B. Jia, H. Dong, S. Huang, Y . Wang, J. Malik, and P. Abbeel. RoboVerse: A Unified Platform, Benchmark and...
-
[11]
Hansen, H
N. Hansen, H. Su, and X. Wang. Learning massively multitask world models for continuous control. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[12]
Zhang, M
Z. Zhang, M. Duan, Y . Ye, and H. R. Zhang. Scalable multi-objective and meta reinforcement learning via gradient estimation, 2026
2026
-
[13]
C. Bai, L. Wang, J. Hao, Z. Yang, B. Zhao, Z. Wang, and X. Li. Pessimistic value iteration for multi-task data sharing in offline reinforcement learning.Artificial Intelligence, 326:104048, Jan. 2024. ISSN 0004-3702. doi:10.1016/j.artint.2023.104048. URLhttp://dx.doi.org/ 10.1016/j.artint.2023.104048
-
[14]
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn. Gradient surgery for multi- task learning. InNeurIPS, 2020
2020
-
[15]
B. Liu, X. Liu, X. Jin, P. Stone, and Q. Liu. Conflict-averse gradient descent for multi-task learning. InNeurIPS, pages 18878–18890, 2021
2021
-
[16]
B. Liu, Y . Feng, P. Stone, and Q. Liu. Famo: Fast adaptive multitask optimization, 2023. URL https://arxiv.org/abs/2306.03792
arXiv 2023
-
[17]
Z. Chen, V . Badrinarayanan, C.-Y . Lee, and A. Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InICML, pages 793–802, 2018
2018
-
[18]
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schulman, E. Todorov, and S. Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstra- tions. InProceedings of Robotics: Science and Systems, Pittsburgh, Pennsylvania, June 2018. doi:10.15607/RSS.2018.XIV .049
-
[19]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 1577–1594. PMLR, 23–29 Jul 2023
2023
-
[20]
D. Bhatt, S.-C. Chou, and N. Atanasov. Rainbow-demorl: Combining improvements in demonstration-augmented reinforcement learning. 2026. URLhttps://arxiv.org/abs/ 2603.27400
arXiv 2026
-
[21]
H. Fu, R. Gong, X. Zhang, M. V . Minniti, J. Patel, and K. Schmeckpeper. Data-efficient multitask dagger, 2025
2025
-
[22]
S. Tao, A. Shukla, T. kai Chan, and H. Su. Reverse forward curriculum learning for extreme sample and demo efficiency. InThe Twelfth International Conference on Learning Represen- tations, 2024
2024
-
[23]
T. Mu, M. Liu, and H. Su. Drs: Learning reusable dense rewards for multi-stage tasks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[24]
A. L. Escoriza, N. Hansen, S. Tao, T. Mu, and H. Su. Multi-stage manipulation with demonstration-augmented reward, policy, and world model learning. In A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu, editors,Pro- ceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceed- ings...
2025
-
[25]
C. Cao, M. R. Garcia, M. Nabail, X. Wang, and N. Rhinehart. Residual reward models for preference-based reinforcement learning.CoRR, abs/2507.00611, July 2025. 10
arXiv 2025
-
[26]
Baimukashev, G
D. Baimukashev, G. Alcan, K. S. Luck, and V . Kyrki. Learning transparent reward models via unsupervised feature selection. In8th Annual Conference on Robot Learning, 2024
2024
-
[27]
Y . Tang, Y . Shang, Y . Chen, B. Wei, X. Zhang, S. Yu, L. Shi, C. Yu, C. Gao, W. Wu, and Y . Li. Roboscape-r: Unified reward-observation world models for generalizable robotics training via rl, 2025
2025
-
[28]
Ferraro, P
S. Ferraro, P. Mazzaglia, T. Verbelen, and B. Dhoedt. FOCUS: Object-centric world mod- els for robotic manipulation. InIntrinsically-Motivated and Open-Ended Learning Workshop @NeurIPS2023, 2023
2023
-
[29]
Kuang, L
Y . Kuang, L. J. Manso, and G. V ogiatzis. Goal-based self-adaptive generative adversarial imitation learning (goal-sagail) for multi-goal robotic manipulation tasks, 2025
2025
-
[30]
Glazer, A
N. Glazer, A. Navon, A. Shamsian, and E. Fetaya. Multi task inverse reinforcement learning for common sense reward, 2025
2025
-
[31]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[32]
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills.ACM Trans. Graph., 37(4):143:1– 143:14, July 2018. ISSN 0730-0301. doi:10.1145/3197517.3201311. URLhttp://doi. acm.org/10.1145/3197517.3201311
-
[33]
Y . Mu, T. Chen, Z. Chen, S. Peng, Z. Lan, Z. Gao, Z. Liang, Q. Yu, Y . Zou, M. Xu, L. Lin, Z. Xie, M. Ding, and P. Luo. Robotwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 27649–27660, June 2025
2025
-
[34]
Shang, K
J. Shang, K. Schmeckpeper, B. B. May, M. V . Minniti, T. Kelestemur, D. Watkins, and L. Her- lant. Theia: Distilling diverse vision foundation models for robot learning. In8th Annual Conference on Robot Learning, 2024
2024
-
[35]
M. Jiang, E. Grefenstette, and T. Rockt ¨aschel. Prioritized level replay. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 4940–4950. PMLR, 18–24 Jul 2021. URLhttps://proceedings.mlr.press/v139/jiang21b.html. 11 A Implementation Details Thi...
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.