Link Prediction or Perdition: the Seeds of Instability in Knowledge Graph Embeddings
Pith reviewed 2026-06-28 10:52 UTC · model grok-4.3
The pith
Knowledge graph embedding models produce divergent triple predictions and variable spaces due to random seeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
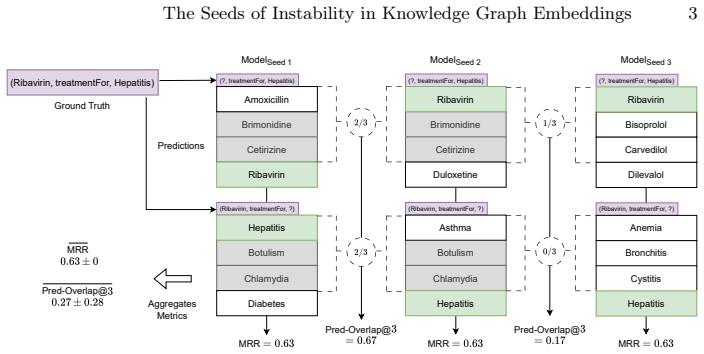
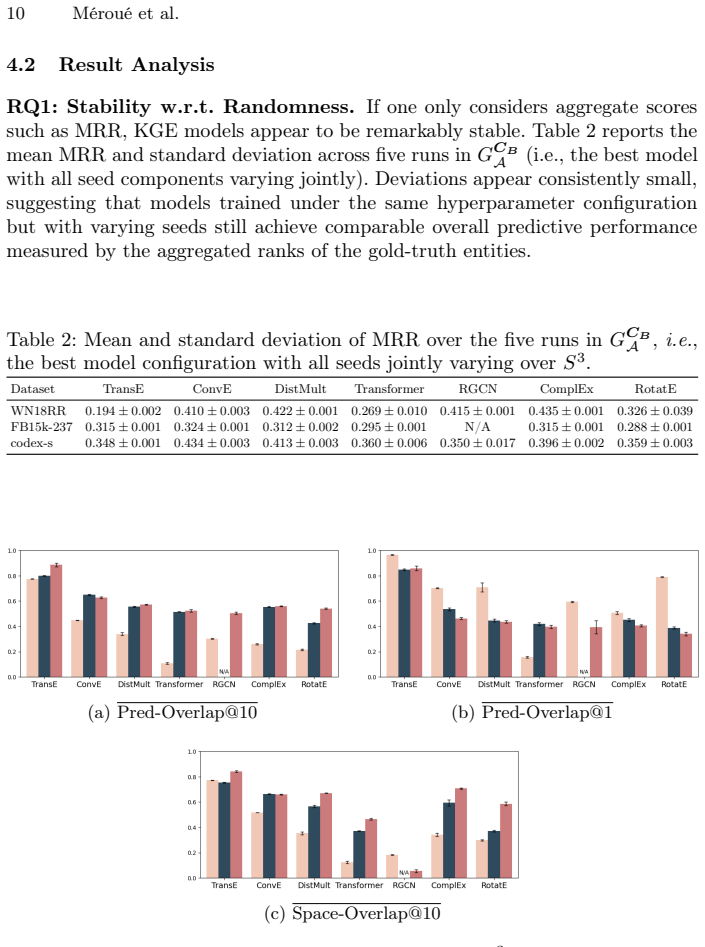
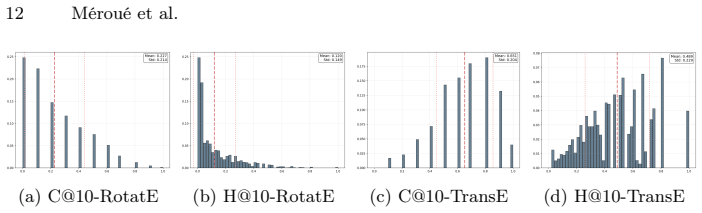
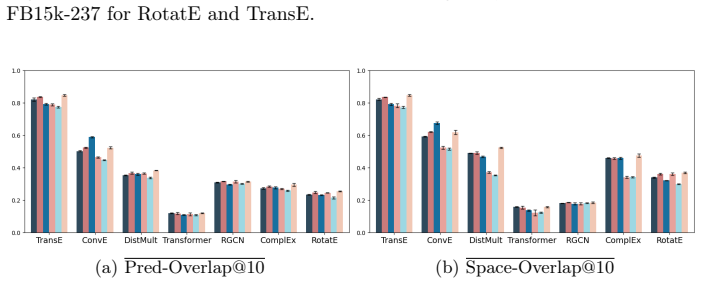
High-performance knowledge graph embedding models actually produce divergent predictions at the triple level and highly variable embedding spaces. By isolating stochastic factors, each of initialization, triple ordering, negative sampling, dropout, and hardware induces instability of comparable magnitude. For any given model, hyperparameter configurations with better MRR are not guaranteed to be more stable, and voting supplies only limited improvement to stability.
What carries the argument
Isolation of individual stochastic factors during training of knowledge graph embedding models to quantify their separate effects on prediction and embedding stability.
If this is right
- Hyperparameter configurations that raise MRR do not necessarily raise stability.
- Voting across runs supplies only limited gains in prediction consistency.
- Rank-based metrics alone do not reveal instabilities at the level of single triples.
- Benchmarking protocols that ignore random-seed effects give an incomplete picture of model reliability for knowledge graph completion.
Where Pith is reading between the lines
- Reproducibility checks in this field would need to control or average over multiple random factors rather than single runs.
- Systems that use these models for concrete link predictions may need repeated trainings to detect and manage output variation.
Load-bearing premise
The chosen models, datasets, and instability metrics are representative enough for the observed instabilities to generalize beyond the specific experimental conditions.
What would settle it
Re-running the experiments on the same models and datasets and finding that predictions for individual triples stay identical across different random seeds would falsify the instability claim.
Figures
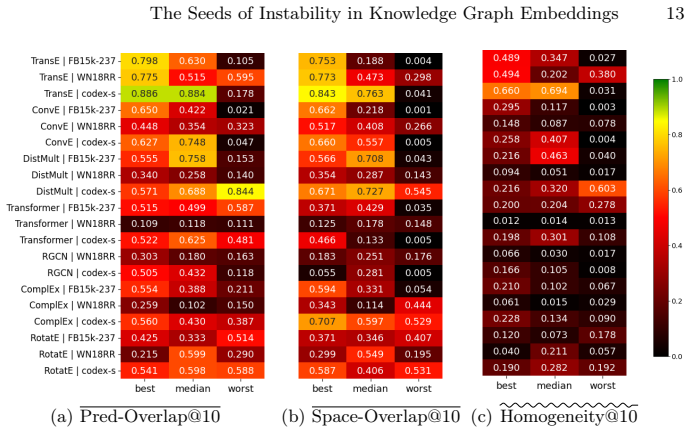
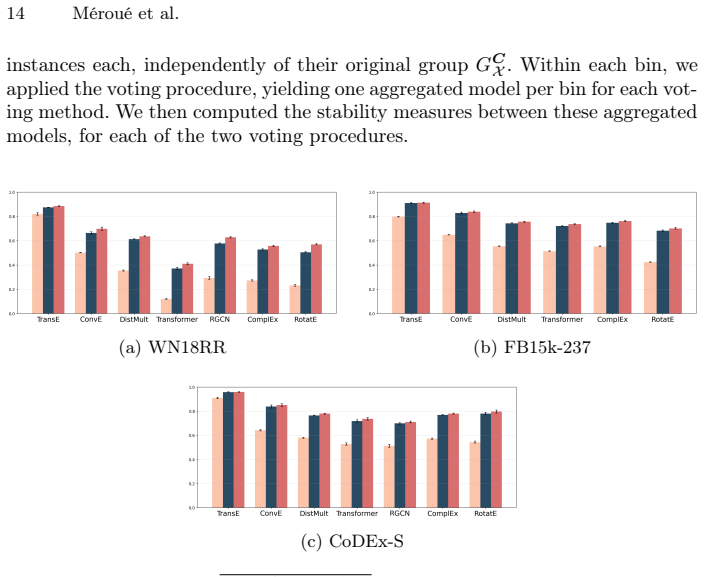

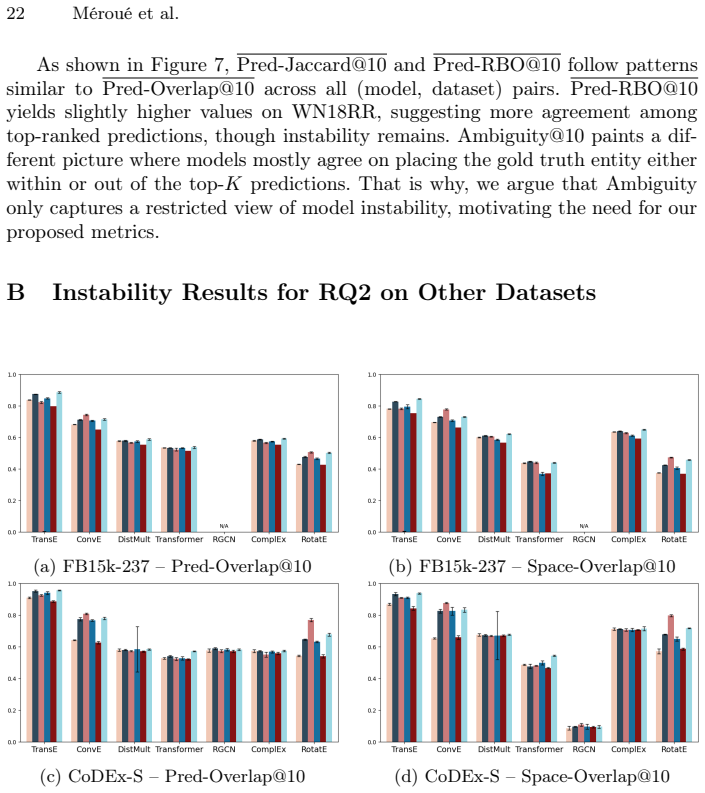
read the original abstract
Embedding models (KGEMs) constitute the main link prediction approach to complete knowledge graphs. Standard evaluation protocols emphasize rank-based metrics such as MRR or Hits@$K$, but usually overlook the influence of random seeds on result stability. Moreover, these metrics conceal potential instabilities in individual predictions and in the organization of embedding spaces. In this work, we conduct a systematic stability analysis of multiple KGEMs across several datasets. We find that high-performance models actually produce divergent predictions at the triple level and highly variable embedding spaces. By isolating stochastic factors (i.e., initialization, triple ordering, negative sampling, dropout, hardware), we show that each independently induces instability of comparable magnitude. Furthermore, for a given model, hyperparameter configurations with better MRR are not guaranteed to be more stable. Moreover, voting, albeit a known remediation mechanism, only provides a limited enhancement of stability. These findings highlight critical limitations of current benchmarking protocols, and raise concerns about the reliability of KGEMs for knowledge graph completion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a systematic empirical analysis of stability in knowledge graph embedding models (KGEMs) for link prediction. It claims that even high-performing models produce divergent triple-level predictions and highly variable embedding spaces; that each isolated stochastic factor (initialization, triple ordering, negative sampling, dropout, hardware) induces instability of comparable magnitude; that hyperparameter configurations with higher MRR are not guaranteed to be more stable; and that ensemble voting yields only limited stability gains. These observations are used to argue that standard rank-based metrics (MRR, Hits@K) are insufficient and that current benchmarking protocols have critical limitations.
Significance. If the experimental isolation and magnitude comparisons hold, the work is significant for the KGEM literature: it supplies concrete evidence that stochasticity can dominate predictive behavior even when aggregate metrics look strong, and it supplies a multi-factor experimental template that future studies can adopt. The multi-model, multi-dataset design and the explicit separation of stochastic sources are strengths that increase the credibility of the instability claims within the reported conditions.
major comments (2)
- [Abstract / §4] Abstract and §4 (results on factor isolation): the central claim that each stochastic factor 'induces instability of comparable magnitude' is load-bearing for the paper's argument, yet the abstract provides no description of the instability metric(s), the number of runs per condition, or the statistical procedure used to declare magnitudes comparable. Without these details the claim cannot be evaluated for robustness.
- [§5] §5 (voting experiments): the statement that voting 'only provides a limited enhancement of stability' requires the precise definition of the stability metric before and after voting, the ensemble size, and the baseline single-run variance; these are not visible in the supplied text and are necessary to judge whether the limited benefit is a general finding or an artifact of the chosen aggregation.
minor comments (1)
- [Abstract] The abstract repeatedly uses 'comparable magnitude' without a forward reference to the exact quantitative definition; a brief parenthetical or footnote would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the clarity of our claims. We address each major comment below and will incorporate revisions to provide the requested details on metrics, experimental setups, and statistical procedures.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (results on factor isolation): the central claim that each stochastic factor 'induces instability of comparable magnitude' is load-bearing for the paper's argument, yet the abstract provides no description of the instability metric(s), the number of runs per condition, or the statistical procedure used to declare magnitudes comparable. Without these details the claim cannot be evaluated for robustness.
Authors: We agree that the abstract and §4 require additional detail to support the comparability claim. The instability metric is a normalized measure of prediction divergence (fraction of triples with differing ranks across runs) and embedding cosine variance; each condition used 10 independent runs, with comparability assessed via overlapping 95% confidence intervals on the normalized variances. In revision we will add a concise description of the metric and run count to the abstract, and expand §4 with the exact statistical procedure and per-factor variance tables. revision: yes
-
Referee: [§5] §5 (voting experiments): the statement that voting 'only provides a limited enhancement of stability' requires the precise definition of the stability metric before and after voting, the ensemble size, and the baseline single-run variance; these are not visible in the supplied text and are necessary to judge whether the limited benefit is a general finding or an artifact of the chosen aggregation.
Authors: We accept that §5 must make these quantities explicit. The stability metric is the same prediction-divergence measure used elsewhere; ensembles of size 5 were formed by majority vote on link predictions; baseline single-run variance is reported as the mean divergence across the 10 runs per model. Revision will insert these definitions, the ensemble size, and a direct before/after comparison table in §5. revision: yes
Circularity Check
No significant circularity detected
full rationale
This is a purely empirical study that isolates stochastic factors (initialization, ordering, sampling, dropout, hardware) through controlled experiments on KGEMs and reports observed instabilities in predictions and embedding spaces via rank metrics and direct measurements. No mathematical derivations, equations, or fitted parameters are presented as predictions; all claims rest on experimental observations rather than self-referential definitions or reductions to inputs by construction. Any self-citations are incidental and non-load-bearing for the central empirical findings, which remain independently verifiable from the reported protocols.
Axiom & Free-Parameter Ledger
free parameters (1)
- Selection of specific KGEM architectures and datasets
axioms (1)
- domain assumption Rank-based metrics such as MRR and Hits@K are the appropriate standard for evaluating link prediction quality
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2013 Conference on Empirical Meth- ods in Natural Language Processing
Berant, J., Chou, A., Frostig, R., Liang, P.: Semantic parsing on Freebase from question-answer pairs. In: Proceedings of the 2013 Conference on Empirical Meth- ods in Natural Language Processing. pp. 1533–1544. Association for Computa- tional Linguistics, Seattle, Washington, USA (Oct 2013),https://aclanthology. org/D13-1160/
2013
-
[2]
TGDK1(1), 4:1–4:32 (2023).https://doi.org/10.4230/TGDK.1.1.4
Biswas, R., Kaffee, L., Cochez, M., Dumbrava, S., Jendal, T.E., Lissandrini, M., López, V., Mencía, E.L., Paulheim, H., Sack, H., Vakaj, E., de Melo, G.: Knowl- edge graph embeddings: Open challenges and opportunities. TGDK1(1), 4:1–4:32 (2023).https://doi.org/10.4230/TGDK.1.1.4
-
[3]
Artificial Intelligence in the Life Sciences2, 100036 (2022)
Bonner, S., Barrett, I.P., Ye, C., Swiers, R., Engkvist, O., Hoyt, C.T., Hamilton, W.L.: Understanding the performance of knowledge graph embeddings in drug discovery. Artificial Intelligence in the Life Sciences2, 100036 (2022)
2022
-
[4]
In: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013
Bordes, A., Usunier, N., García-Durán, A., Weston, J., Yakhnenko, O.: Translating embeddings for modeling multi-relational data. In: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States. pp. 2787–2795 (...
2013
-
[5]
Chen, J., Dong, H., Hastings, J., Jiménez-Ruiz, E., López, V., Monnin, P., Pesquita, C., Skoda, P., Tamma, V.: Knowledge graphs for the life sciences: Re- cent developments, challenges and opportunities. TGDK1(1), 5:1–5:33 (2023). https://doi.org/10.4230/TGDK.1.1.5
-
[6]
In: Proceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing
Chen, S., Liu, X., Gao, J., Jiao, J., Zhang, R., Ji, Y.: HittER: Hierarchical trans- formers for knowledge graph embeddings. In: Proceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing. pp. 10395–10407. Association for Computational Linguistics, Online and Punta Cana, Domini- can Republic (Nov 2021).https://doi.org/10.1865...
-
[7]
org/abs/1711.05851 The Seeds of Instability in Knowledge Graph Embeddings 17
Das, R., Dhuliawala, S., Zaheer, M., Vilnis, L., Durugkar, I., Krishnamurthy, A., Smola, A., McCallum, A.: Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning (2018),https://arxiv. org/abs/1711.05851 The Seeds of Instability in Knowledge Graph Embeddings 17
Pith/arXiv arXiv 2018
-
[8]
Dettmers, T., Minervini, P., Stenetorp, P., Riedel, S.: Convolutional 2d knowledge graphembeddings.In:ProceedingsoftheThirty-SecondAAAIConferenceonArti- ficial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelli- gence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artifi- cial Intelligence (EAAI-18), New Orle...
-
[9]
In: Taylor, K.L., Gonçalves, R.S., Lécué, F., Yan, J
Gad-Elrab, M.H., Ho, V.T., Levinkov, E., Tran, T., Stepanova, D.: Towards uti- lizing knowledge graph embedding models for conceptual clustering. In: Taylor, K.L., Gonçalves, R.S., Lécué, F., Yan, J. (eds.) Proceedings of the ISWC 2020 Demos and Industry Tracks: From Novel Ideas to Industrial Practice co-located with 19th International Semantic Web Confer...
2020
-
[10]
VLDB J.24(6), 707–730 (2015).https://doi.org/10.1007/S00778-015-0394-1,https://doi.org/10
Galárraga, L., Teflioudi, C., Hose, K., Suchanek, F.M.: Fast rule min- ing in ontological knowledge bases with AMIE+. VLDB J.24(6), 707–730 (2015).https://doi.org/10.1007/S00778-015-0394-1,https://doi.org/10. 1007/s00778-015-0394-1
-
[11]
ACM Computing Surveys (Csur)54(4), 1–37 (2021)
Hogan, A., Blomqvist, E., Cochez, M., d’Amato, C., Melo, G.D., Gutierrez, C., Kirrane, S., Gayo, J.E.L., Navigli, R., Neumaier, S., et al.: Knowledge graphs. ACM Computing Surveys (Csur)54(4), 1–37 (2021)
2021
-
[12]
Lecture Notes in Computer Science, vol
Hubert, N., Paulheim, H., Brun, A., Monticolo, D.: Do similar entities have similar embeddings? In: The Semantic Web - 21st International Conference, ESWC 2024, Hersonissos, Crete, Greece, May 26-30, 2024, Proceedings, Part I. Lecture Notes in Computer Science, vol. 14664, pp. 3–21. Springer (2024).https://doi.org/10. 1007/978-3-031-60626-7_1
2024
-
[13]
Jain, N., Kalo, J.C., Balke, W.T., Krestel, R.: Do embeddings actually cap- ture knowledge graph semantics? In: The Semantic Web: 18th International Conference, ESWC 2021, Virtual Event, June 6–10, 2021, Proceedings. p. 143–159. Springer-Verlag, Berlin, Heidelberg (2021).https://doi.org/10.1007/ 978-3-030-77385-4_9,https://doi.org/10.1007/978-3-030-77385-4_9
-
[14]
Ji, S., Pan, S., Cambria, E., Marttinen, P., Yu, P.S.: A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Transactions on Neural Net- works and Learning Systems33(2), 494–514 (2022).https://doi.org/10.1109/ TNNLS.2021.3070843
arXiv 2022
-
[15]
Krompaß, D., Baier, S., Tresp, V.: Type-constrained representation learning in knowledge graphs. In: The Semantic Web - ISWC 2015 - 14th International Se- mantic Web Conference, Bethlehem, PA, USA, October 11-15, 2015, Proceedings, Part I. Lecture Notes in Computer Science, vol. 9366, pp. 640–655. Springer (2015). https://doi.org/10.1007/978-3-319-25007-6...
-
[16]
W3C recommendation, W3C (Feb 2014), https://www.w3.org/TR/2014/REC- rdf11-concepts-20140225/
Lanthaler, M., Cyganiak, R., Wood, D.: RDF 1.1 concepts and abstract syntax. W3C recommendation, W3C (Feb 2014), https://www.w3.org/TR/2014/REC- rdf11-concepts-20140225/
2014
-
[17]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Li, Q., Zhong, Y., Qin, Y.: MoCoKGC: Momentum contrast entity encod- ing for knowledge graph completion. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 14940–14952. As- sociation for Computational Linguistics, Miami, Florida, USA (Nov 2024). https://doi.org/10.18653/v1/2024.emnlp-main.832,https://aclantholo...
-
[18]
Lin, Y., Liu, Z., Sun, M., Liu, Y., Zhu, X.: Learning entity and relation embed- dings for knowledge graph completion. In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25-30, 2015, Austin, Texas, USA. pp. 2181–2187. AAAI Press (2015).https://doi.org/10.1609/AAAI.V29I1.9491, https://doi.org/10.1609/aaai.v29i1.9491
-
[19]
In: Proceedings of the 34th International Conference on Machine Learning, ICML 2017,Sydney,NSW,Australia,6-11August2017.ProceedingsofMachineLearning Research, vol
Liu, H., Wu, Y., Yang, Y.: Analogical inference for multi-relational embeddings. In: Proceedings of the 34th International Conference on Machine Learning, ICML 2017,Sydney,NSW,Australia,6-11August2017.ProceedingsofMachineLearning Research, vol. 70, pp. 2168–2178. PMLR (2017),http://proceedings.mlr.press/ v70/liu17d.html
2017
-
[20]
Madhyastha, P., Jain, R.: On model stability as a function of random seed (2019), https://arxiv.org/abs/1909.10447
arXiv 2019
-
[21]
Marx, C.T., du Pin Calmon, F., Ustun, B.: Predictive multiplicity in classification (2020),https://arxiv.org/abs/1909.06677
arXiv 2020
-
[22]
Meilicke, C., Chekol, M.W., Betz, P., Fink, M., Stuckenschmidt, H.: Anytime bottom-uprulelearningforlarge-scaleknowledgegraphcompletion.VLDBJournal 33(1), 131–161 (2024).https://doi.org/10.1007/S00778-023-00800-5,https: //doi.org/10.1007/s00778-023-00800-5
-
[23]
Semantic Web13(3), 379–398 (2022).https://doi.org/10.3233/SW-210452
Monnin, P., Raïssi, C., Napoli, A., Coulet, A.: Discovering alignment relations with graph convolutional networks: A biomedical case study. Semantic Web13(3), 379–398 (2022).https://doi.org/10.3233/SW-210452
-
[24]
Nguyen, D.Q., Nguyen, T.D., Nguyen, D.Q., Phung, D.Q.: A novel embedding model for knowledge base completion based on convolutional neural network. In: Proceedings of the 2018 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, NAACL- HLT, New Orleans, Louisiana, USA, June 1-6, 2018, Vo...
-
[25]
Noy, N.F., Gao, Y., Jain, A., Narayanan, A., Patterson, A., Taylor, J.: Industry- scale knowledge graphs: lessons and challenges. Commun. ACM62(8), 36–43 (2019).https://doi.org/10.1145/3331166
-
[26]
Semantic Web8(3), 489–508 (2017).https://doi.org/10.3233/ SW-160218
Paulheim, H.: Knowledge graph refinement: A survey of approaches and evalua- tion methods. Semantic Web8(3), 489–508 (2017).https://doi.org/10.3233/ SW-160218
2017
-
[27]
In: Groth, P., Simperl, E., Gray, A., Sabou, M., Krötzsch, M., Lecue, F., Flöck, F., Gil, Y
Ristoski, P., Paulheim, H.: Rdf2vec: Rdf graph embeddings for data mining. In: Groth, P., Simperl, E., Gray, A., Sabou, M., Krötzsch, M., Lecue, F., Flöck, F., Gil, Y. (eds.) The Semantic Web – ISWC 2016. pp. 498–514. Springer International Publishing, Cham (2016)
2016
-
[28]
In: 8th International Conference on Learn- ing Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020
Ruffinelli, D., Broscheit, S., Gemulla, R.: You CAN teach an old dog new tricks! on training knowledge graph embeddings. In: 8th International Conference on Learn- ing Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. Open- Review.net (2020),https://openreview.net/forum?id=BkxSmlBFvr
2020
-
[29]
Generating radiology reports via memory-driven transformer
Safavi, T., Koutra, D.: CoDEx: A Comprehensive Knowledge Graph Comple- tion Benchmark. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 8328–8350. Association for Com- putational Linguistics, Online (Nov 2020).https://doi.org/10.18653/v1/2020. emnlp-main.669,https://www.aclweb.org/anthology/2020.emnlp...
-
[30]
In: The Semantic Web - 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June The Seeds of Instability in Knowledge Graph Embeddings 19 3-7, 2018, Proceedings
Schlichtkrull, M.S., Kipf, T.N., Bloem, P., van den Berg, R., Titov, I., Welling, M.: Modeling relational data with graph convolutional networks. In: The Semantic Web - 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June The Seeds of Instability in Knowledge Graph Embeddings 19 3-7, 2018, Proceedings. Lecture Notes in Computer Science...
2018
-
[31]
Springer (2018).https://doi.org/10.1007/978-3-319-93417-4_38,https: //doi.org/10.1007/978-3-319-93417-4_38
-
[32]
Schumacher, T., Wolf, H., Ritzert, M., Lemmerich, F., Grohe, M., Strohmaier, M.: The Effects of Randomness on the Stability of Node Embeddings, p. 197–215. Springer International Publishing (2021).https://doi.org/10.1007/ 978-3-030-93736-2_16,http://dx.doi.org/10.1007/978-3-030-93736-2_16
-
[33]
Shchur, O., Mumme, M., Bojchevski, A., Günnemann, S.: Pitfalls of graph neural network evaluation (2019),https://arxiv.org/abs/1811.05868
Pith/arXiv arXiv 2019
-
[34]
Pro- ceedings of the VLDB Endowment13(11), 2326–2340 (2020),http://www.vldb
Sun, Z., Zhang, Q., Hu, W., Wang, C., Chen, M., Akrami, F., Li, C.: A bench- marking study of embedding-based entity alignment for knowledge graphs. Pro- ceedings of the VLDB Endowment13(11), 2326–2340 (2020),http://www.vldb. org/pvldb/vol13/p2326-sun.pdf
2020
-
[35]
In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019
Sun, Z., Deng, Z., Nie, J., Tang, J.: Rotate: Knowledge graph embedding by re- lational rotation in complex space. In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenRe- view.net (2019),https://openreview.net/forum?id=HkgEQnRqYQ
2019
-
[36]
Toutanova, K., Chen, D.: Observed versus latent features for knowledge base and text inference. In: Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality, CVSC 2015, Beijing, China, July 26-31, 2015. pp. 57–66. Association for Computational Linguistics (2015).https://doi.org/ 10.18653/V1/W15-4007,https://doi.org/10.1...
-
[37]
In: Proceedings of the 33nd International Confer- enceonMachineLearning,ICML2016,NewYorkCity,NY,USA,June19-24,2016
Trouillon, T., Welbl, J., Riedel, S., Gaussier, É., Bouchard, G.: Complex embed- dings for simple link prediction. In: Proceedings of the 33nd International Confer- enceonMachineLearning,ICML2016,NewYorkCity,NY,USA,June19-24,2016. JMLR Workshop and Conference Proceedings, vol. 48, pp. 2071–2080. JMLR.org (2016),http://proceedings.mlr.press/v48/trouillon16.html
2016
-
[38]
In: Proceedings of the 27th ACM International Conference on Information and Knowl- edge Management
Wang, H., Zhang, F., Wang, J., Zhao, M., Li, W., Xie, X., Guo, M.: Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In: Proceedings of the 27th ACM International Conference on Information and Knowl- edge Management. p. 417–426. CIKM ’18, Association for Computing Machin- ery, New York, NY, USA (2018).https://doi.org/...
-
[39]
CoRRabs/2304.11949 (2023).https://doi.org/10.48550/ARXIV.2304.11949,https://doi.org/10
Xiong, B., Nayyeri, M., Jin, M., He, Y., Cochez, M., Pan, S., Staab, S.: Geometric relational embeddings: A survey. CoRRabs/2304.11949 (2023).https://doi.org/10.48550/ARXIV.2304.11949,https://doi.org/10. 48550/arXiv.2304.11949
-
[41]
Yang, B., Yih, W., He, X., Gao, J., Deng, L.: Embedding entities and relations for learning and inference in knowledge bases. In: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings (2015),http://arxiv.org/abs/1412.6575
Pith/arXiv arXiv 2015
-
[42]
In: Proceed- ings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Yasunaga, M., Ren, H., Bosselut, A., Liang, P., Leskovec, J.: QA-GNN: Reasoning with language models and knowledge graphs for question answering. In: Proceed- ings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 535–546. Asso- ciation for Computational Linguistics, Onl...
2021
-
[43]
In: The World Wide Web Conference, WWW 2019, San Francisco, CA, USA, May 13-17, 2019
Zhang, W., Paudel, B., Wang, L., Chen, J., Zhu, H., Zhang, W., Bernstein, A., Chen, H.: Iteratively learning embeddings and rules for knowledge graph reasoning. In: The World Wide Web Conference, WWW 2019, San Francisco, CA, USA, May 13-17, 2019. pp. 2366–2377. ACM (2019).https://doi.org/10.1145/3308558. 3313612,https://doi.org/10.1145/3308558.3313612
-
[44]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Zhu, Y., Potyka, N., Nayyeri, M., Xiong, B., He, Y., Kharlamov, E., Staab, S.: Predictive multiplicity of knowledge graph embeddings in link prediction. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 334–354. Association for Computational Linguistics, Miami, Florida, USA (Nov 2024).https://doi.org/10.18653/v1/2024.findings-...
-
[45]
Zhu, Z., Zhang, Z., Xhonneux, L.P., Tang, J.: Neural bellman-ford networks: A general graph neural network framework for link prediction. Advances in Neural Information Processing Systems34(2021) The Seeds of Instability in Knowledge Graph Embeddings 21 APPENDICES A Other Metrics Jaccardsimilarity is a natural candidate. However, under the assumption|A|= ...
2021
-
[46]
Each source is independently sufficient to induce instability at both the em- bedding and prediction levels
-
[47]
There is an inherent and persistent instability induced by randomness factors in model training
-
[48]
The observed variations in instability appear to be more strongly tied to the model architecture than to the specific source of randomness
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.