Neural Change Prediction: Relating Software Changes to Their Effects and Vice Versa
Pith reviewed 2026-06-28 09:07 UTC · model grok-4.3
The pith
Neural Change Prediction trains models on mutation pairs to predict code edits from desired behavior changes and behavior changes from code edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neural Change Prediction generates numerous (changes to software, changes in behavior)-pairs by automatically mutating programs and observing output differences on test inputs, then trains models on these pairs to enable bidirectional prediction between code modifications and their dynamic effects.
What carries the argument
The automatic creation of (changes to software, changes in behavior)-pairs from mutations, which serve as training data for models that map between code edits and output effects in both directions.
If this is right
- For a desired change in program behavior, the models can predict the code locations and modifications needed.
- For a given code change, the models can predict the resulting change in program output.
- The approach supports tasks such as feature localization, software evolution, and automated repair.
- It requires only the ability to execute the program and observe outputs, with no prior semantic knowledge of the code.
Where Pith is reading between the lines
- If generalization holds, the technique could integrate into development environments to suggest edits during debugging sessions.
- The mutation-based data generation might be extended with more targeted operators to better approximate real-world change distributions.
- Applying the same pairing process to other executable artifacts, such as configuration systems or data pipelines, could yield similar predictive models.
Load-bearing premise
Models trained on pairs from automatic mutations will generalize to produce useful predictions for real developer tasks and unseen code changes.
What would settle it
Evaluating the trained models on a collection of actual developer-submitted changes and measuring whether their predictions of output effects match the observed effects at rates significantly above chance.
Figures

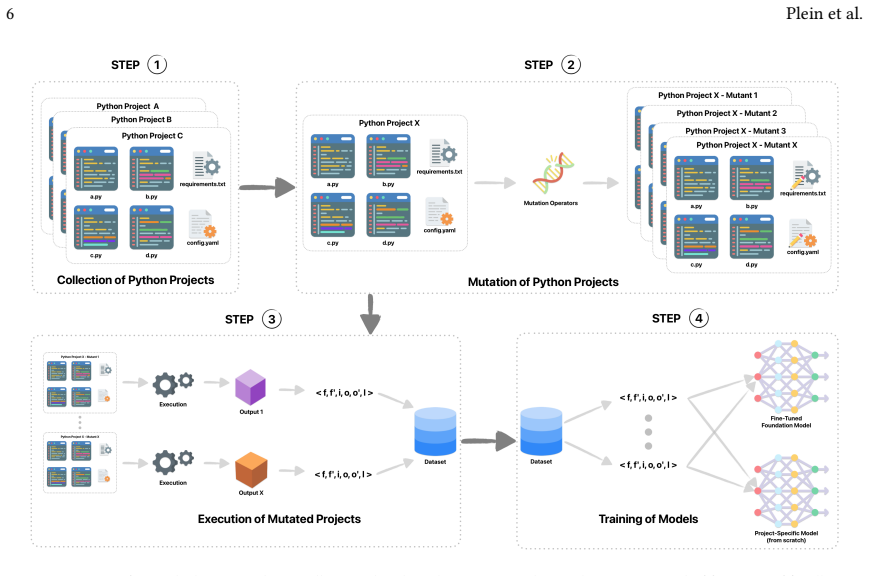
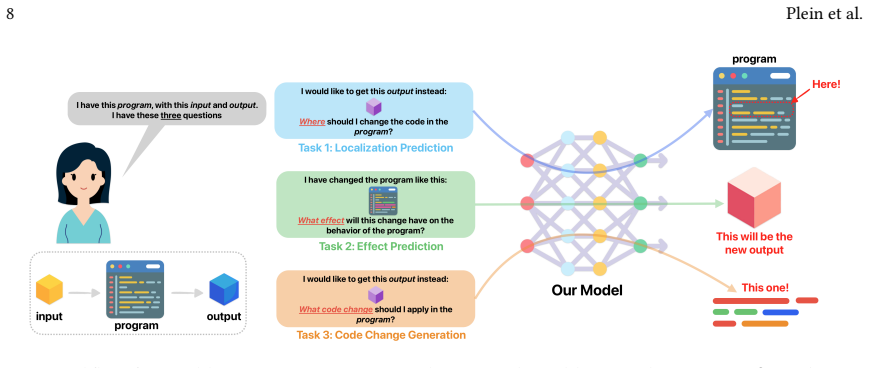
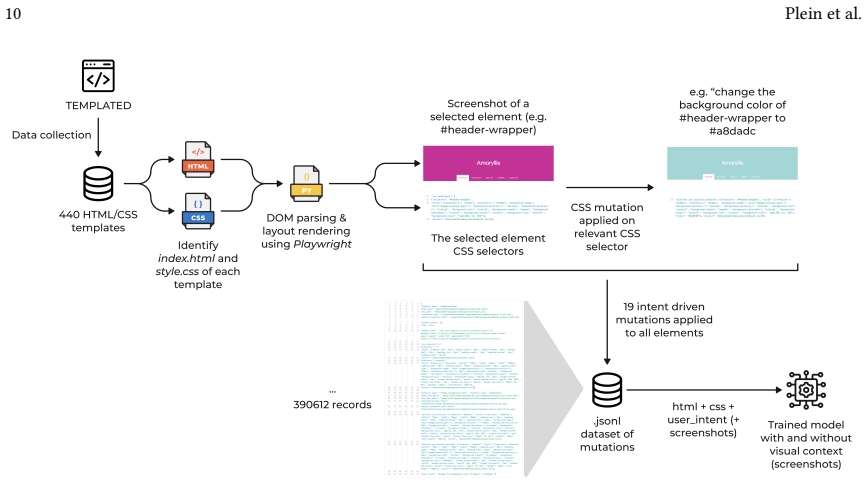
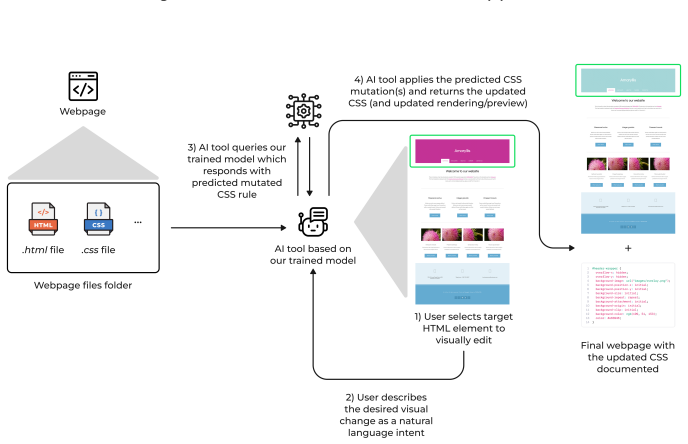
read the original abstract
Much of software development revolves around understanding the relationship between software changes and their effects. If we could learn and predict those relationships, such predictions could benefit several areas of software engineering. While recent advances in artificial intelligence have shown great promise in software engineering tasks, predicting the semantics of code without executing it remains a big challenge. In this paper, we present Neural Change Prediction, a novel and fundamental technique to learn and predict associations between software changes and their dynamic effects on program behavior. Specifically, for a given program and test inputs, we automatically apply numerous mutations to the code and observe how these changes alter the program's output. From these (changes to software, changes in behavior)-pairs, we create models that: (1) for a desired change in behavior, predict where and how the code should be changed (feature localization, software evolution, and software repair); and (2) for a given code change, predict how this code change affects the output (effect prediction). We have conducted a detailed case study on CSS configuration files and an evaluation on Python programs to demonstrate the generality and wide applicability of Neural Change Prediction. While Neural Change Prediction requires numerous mutations (and thus numerous executions of the program under test), Neural Change Prediction is fully automatic and does not require any prior knowledge of the code or its semantics, making it applicable to any software artifact that can be executed and whose output can be observed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural Change Prediction, a technique that automatically generates (code mutation, behavioral effect) pairs by applying numerous mutations to a program under given test inputs and observing output changes. These pairs are used to train models for two directions: (1) predicting the location and nature of code changes needed to achieve a desired behavioral change (supporting feature localization, evolution, and repair), and (2) predicting the behavioral effects of a given code change. The method is claimed to be fully automatic, requiring no prior semantic knowledge, and is demonstrated via a case study on CSS configuration files plus an evaluation on Python programs.
Significance. If the central claims hold and the learned models generalize beyond the synthetic mutation distribution to support useful predictions on real developer changes, the approach could provide a novel, general data-driven foundation for multiple software engineering tasks by directly relating changes to dynamic effects without manual feature engineering or domain-specific rules.
major comments (1)
- [Evaluation on Python programs] Evaluation on Python programs: the manuscript must explicitly report whether the held-out test changes used to assess prediction accuracy were drawn from real commits/version history or generated via the same automatic mutation process used for training data. This distinction is load-bearing for the claim that the models enable 'useful predictions for real development tasks' such as repair and feature localization, as the skeptic note and abstract provide no such evidence of out-of-distribution generalization.
minor comments (1)
- The abstract summarizes the method and claims but supplies no quantitative results, error metrics, or model details from the case study or Python evaluation; adding a concise summary of key performance numbers would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The single major comment raises an important point about the nature of the evaluation data, which we address directly below. We will revise the manuscript accordingly to improve clarity and align claims with the presented evidence.
read point-by-point responses
-
Referee: [Evaluation on Python programs] Evaluation on Python programs: the manuscript must explicitly report whether the held-out test changes used to assess prediction accuracy were drawn from real commits/version history or generated via the same automatic mutation process used for training data. This distinction is load-bearing for the claim that the models enable 'useful predictions for real development tasks' such as repair and feature localization, as the skeptic note and abstract provide no such evidence of out-of-distribution generalization.
Authors: We agree that this distinction is critical and that the current manuscript does not explicitly state it. The held-out test changes used in the Python evaluation were generated via the same automatic mutation process as the training data (i.e., in-distribution with respect to the synthetic mutation distribution). The manuscript makes no claim of, and presents no evidence for, generalization to real developer commits from version history. We will revise the evaluation section to explicitly report this fact, and we will adjust the discussion of applicability to real tasks (including in the abstract and skeptic note) to reflect that the current results demonstrate learning within the mutation distribution but do not yet address out-of-distribution generalization to real changes. revision: yes
Circularity Check
No circularity; standard mutation-based data generation plus ML training
full rationale
The paper's core procedure generates (change, effect) pairs exclusively by applying mutations to code and observing output changes, then trains models on those pairs. No equations, fitted parameters, or derivations are presented that reduce any claimed prediction back to the inputs by construction. No self-citations are invoked as load-bearing uniqueness results or ansatzes. The approach is a conventional empirical pipeline (data synthesis followed by supervised learning) whose validity rests on external evaluation rather than definitional equivalence. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rui Abreu, Peter Zoeteweij, and Arjan JC Van Gemund. 2007. On the accuracy of spectrum-based fault localization. InTesting: Academic and industrial conference practice and research techniques-MUTATION (TAICPART-MUTATION 2007). IEEE, 89–98
2007
-
[2]
1996.Software change impact analysis
Robert S Arnold. 1996.Software change impact analysis. IEEE Computer Society Press
1996
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. Repairagent: An autonomous, llm-based agent for program repair. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2188–2200
2025
- [5]
-
[6]
Anna Derezińska and Konrad Hałas. 2014. Analysis of mutation operators for the Python language. InProceedings of the Ninth International Conference on Dependability and Complex Systems DepCoS-RELCOMEX. June 30–July 4, 2014, Brunów, Poland. Springer, 155–164
2014
-
[7]
Bogdan Dit, Meghan Revelle, Malcom Gethers, and Denys Poshyvanyk. 2013. Feature location in source code: a taxonomy and survey.Journal of software: Evolution and Process25, 1 (2013), 53–95
2013
-
[8]
Zhili Huang, Ling Xu, Chao Liu, Weifeng Sun, Xu Zhang, Yan Lei, Meng Yan, and Hongyu Zhang. 2025. DynaFix: Iterative Automated Program Repair Driven by Execution-Level Dynamic Information.arXiv preprint arXiv:2512.24635(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Yue Jia and Mark Harman. 2011. An Analysis and Survey of the Development of Mutation Testing.IEEE Transactions on Software Engineering37, 5 (2011), 649–678. doi:10.1109/TSE.2010.62 Neural Change Prediction 33
- [10]
-
[11]
James A Jones, Mary Jean Harrold, and John Stasko. 2002. Visualization of test information to assist fault localization. InProceedings of the 24th international conference on Software engineering. 467–477
2002
-
[12]
Tae Soo Kim, DaEun Choi, Yoonseo Choi, and Juho Kim. 2022. Stylette: Styling the Web with Natural Language. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 5, 17 pages. doi:10.1145/3491102.3501931
-
[13]
Kim N King and A Jefferson Offutt. 1991. A FORTRAN language system for mutation-based software testing.Software: Practice and Experience21, 7 (1991), 685–718
1991
-
[14]
Anil Koyuncu, Kui Liu, Tegawendé F Bissyandé, Dongsun Kim, Jacques Klein, Martin Monperrus, and Yves Le Traon. 2020. Fixminer: Mining relevant fix patterns for automated program repair.Empirical Software Engineering25 (2020), 1980–2024
2020
-
[15]
Xuan Bach D Le, David Lo, and Claire Le Goues. 2016. History driven program repair. In2016 IEEE 23rd international conference on software analysis, evolution, and reengineering (SANER), Vol. 1. IEEE, 213–224
2016
-
[16]
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. 2011. Genprog: A generic method for automatic software repair.Ieee transactions on software engineering38, 1 (2011), 54–72
2011
-
[17]
Claire Le Goues, Michael Pradel, and Abhik Roychoudhury. 2019. Automated program repair.Commun. ACM62, 12 (2019), 56–65
2019
-
[18]
Bixin Li, Xiaobing Sun, Hareton Leung, and Sai Zhang. 2013. A survey of code-based change impact analysis techniques.Software Testing, Verification and Reliability23, 8 (2013), 613–646
2013
-
[19]
Derrick Lin, James Koppel, Angela Chen, and Armando Solar-Lezama. 2017. QuixBugs: A multi-lingual program repair benchmark set based on the Quixey Challenge. InProceedings Companion of the 2017 ACM SIGPLAN international conference on systems, programming, languages, and applications: software for humanity. 55–56
2017
-
[20]
Kui Liu, Anil Koyuncu, Tegawendé F Bissyandé, Dongsun Kim, Jacques Klein, and Yves Le Traon. 2019. You cannot fix what you cannot find! an investigation of fault localization bias in benchmarking automated program repair systems. In2019 12th IEEE conference on software testing, validation and verification (ICST). IEEE, 102–113
2019
-
[21]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. Tbar: Revisiting template-based automated program repair. InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis. 31–42
2019
-
[22]
Zixin Liu, Xiaozhi Du, and Hairui Liu. 2025. ReAPR: Automatic program repair via retrieval-augmented large language models: Z. Liu, X. Du, H. Liu. Software Quality Journal33, 3 (2025), 30
2025
- [23]
-
[24]
Sonal Mahajan and William G. J. Halfond. April 2015. WebSee: A Tool for Debugging HTML Presentation Failures. doi:10.1109/ICST.2015.7102638
-
[25]
Sonal Mahajan, Bailan Li, Pooyan Behnamghader, and William G. J. Halfond. 2016. Using Visual Symptoms for Debugging Presentation Failures in Web Applications. In2016 IEEE International Conference on Software Testing, Verification and Validation (ICST). 191–201. doi:10.1109/ICST.2016.35
-
[26]
Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2016. Angelix: Scalable multiline program patch synthesis via symbolic analysis. In Proceedings of the 38th international conference on software engineering. 691–701
2016
-
[27]
Hoang Duong Thien Nguyen, Dawei Qi, Abhik Roychoudhury, and Satish Chandra. 2013. Semfix: Program repair via semantic analysis. In2013 35th International Conference on Software Engineering (ICSE). IEEE, 772–781
2013
- [28]
-
[29]
Mike Papadakis, Marinos Kintis, Jie Zhang, Yue Jia, Yves Le Traon, and Mark Harman. 2019. Mutation testing advances: an analysis and survey. In Advances in computers. Vol. 112. Elsevier, 275–378
2019
-
[30]
Laura Plein, Wendkûuni C Ouédraogo, Jacques Klein, and Tegawendé F Bissyandé. 2024. Automatic generation of test cases based on bug reports: A feasibility study with large language models. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings. 360–361
2024
-
[31]
Xiaoxia Ren, Fenil Shah, Frank Tip, Barbara G Ryder, and Ophelia Chesley. 2004. Chianti: a tool for change impact analysis of java programs. In Proceedings of the 19th annual ACM SIGPLAN conference on Object-oriented programming, systems, languages, and applications. 432–448
2004
-
[32]
Barbara G Ryder and Frank Tip. 2001. Change impact analysis for object-oriented programs. InProceedings of the 2001 ACM SIGPLAN-SIGSOFT workshop on Program analysis for software tools and engineering. 46–53
2001
-
[33]
Kensen Shi, Deniz Altınbüken, Saswat Anand, Mihai Christodorescu, Katja Grünwedel, Alexa Koenings, Sai Naidu, Anurag Pathak, Marc Rasi, Fredde Ribeiro, et al. 2025. Natural language outlines for code: Literate programming in the LLM era. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 150–161
2025
-
[34]
Yuxuan Wan, Chaozheng Wang, Yi Dong, Wenxuan Wang, Shuqing Li, Yintong Huo, and Michael Lyu. 2025. Divide-and-Conquer: Generating UI Code from Screenshots.Proceedings of the ACM on Software Engineering2, FSE (June 2025), 2099–2122. doi:10.1145/3729364
-
[35]
Hanbin Wang, Xiaoxuan Zhou, Zhipeng Xu, Keyuan Cheng, Yuxin Zuo, Kai Tian, Jingwei Song, Junting Lu, Wenhui Hu, and Xueyang Liu. 2025. Code-vision: Evaluating multimodal LLMs logic understanding and code generation capabilities.arXiv preprint arXiv:2502.11829(2025). 34 Plein et al
-
[36]
Yuxiang Wei, Zhiqing Sun, Emily McMilin, Jonas Gehring, David Zhang, Gabriel Synnaeve, Daniel Fried, Lingming Zhang, and Sida Wang. 2025. Toward training superintelligent software agents through self-play swe-rl.arXiv preprint arXiv:2512.18552(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
W Eric Wong, Ruizhi Gao, Yihao Li, Rui Abreu, and Franz Wotawa. 2016. A survey on software fault localization.IEEE Transactions on Software Engineering42, 8 (2016), 707–740
2016
-
[38]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
-
[39]
Jinqiu Yang, Alexey Zhikhartsev, Yuefei Liu, and Lin Tan. 2017. Better test cases for better automated program repair. InProceedings of the 2017 11th joint meeting on foundations of software engineering. 831–841
2017
-
[40]
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang. 2024. Thinkrepair: Self-directed automated program repair. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1274–1286
2024
- [41]
-
[42]
Quanjun Zhang, Chunrong Fang, Yuxiang Ma, Weisong Sun, and Zhenyu Chen. 2023. A survey of learning-based automated program repair.ACM Transactions on Software Engineering and Methodology33, 2 (2023), 1–69
2023
-
[43]
Quanjun Zhang, Chunrong Fang, Yang Xie, YuXiang Ma, Weisong Sun, Yun Yang, and Zhenyu Chen. 2024. A systematic literature review on large language models for automated program repair.ACM Transactions on Software Engineering and Methodology(2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.