A Recursive Domain- and Objective-Adaptive Frank-Wolfe Algorithm
Pith reviewed 2026-06-28 08:59 UTC · model grok-4.3
The pith
A recursive Frank-Wolfe variant converges when domain and objective estimators are refined from data during iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By folding domain and objective estimators into the successive linear optimization steps of Frank-Wolfe, the algorithm produces iterates whose distance to the optimum scales with the current estimator error; the projection-free property is retained and experiments confirm that convergence speed approaches the exact-knowledge case once the estimators stabilize.
What carries the argument
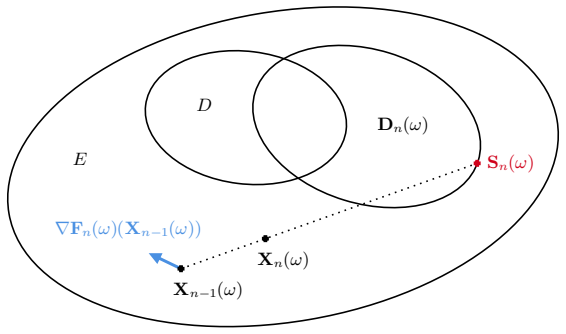
Recursive insertion of domain and objective estimators into the linear optimization oracle at each Frank-Wolfe iteration.
If this is right
- Optimization error is bounded by a term proportional to the estimator inaccuracy plus the usual Frank-Wolfe gap term.
- Each iteration remains projection-free because only the linear oracle on the current estimator is required.
- Computational cost drops when exact domain or objective data are expensive to obtain.
- Convergence rate matches the classical Frank-Wolfe rate once estimator accuracy reaches a fixed tolerance.
Where Pith is reading between the lines
- The same estimator-insertion pattern could be tried inside other conditional-gradient methods that rely on linear oracles.
- If the estimators can be refreshed from streaming observations, the scheme might support online convex optimization with evolving constraints.
- Scaling tests on problems whose dimension grows would reveal whether the reported savings remain linear in problem size.
Load-bearing premise
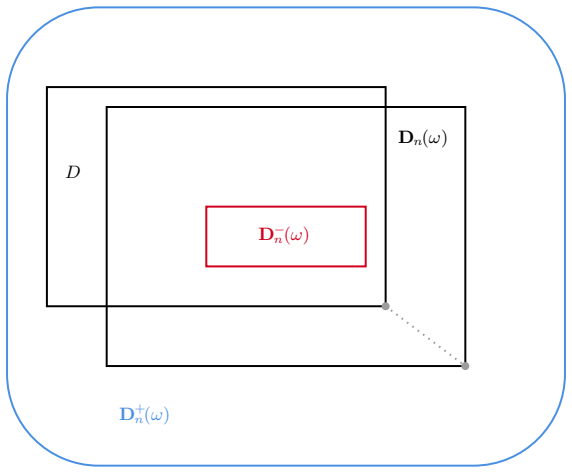
The estimators remain convex and the domain stays compact throughout the updates so that the linear subproblems stay well-defined.
What would settle it
An experiment in which estimator error decreases steadily while the optimization gap stays bounded away from zero would refute the claimed scaling of the error with estimator accuracy.
Figures
read the original abstract
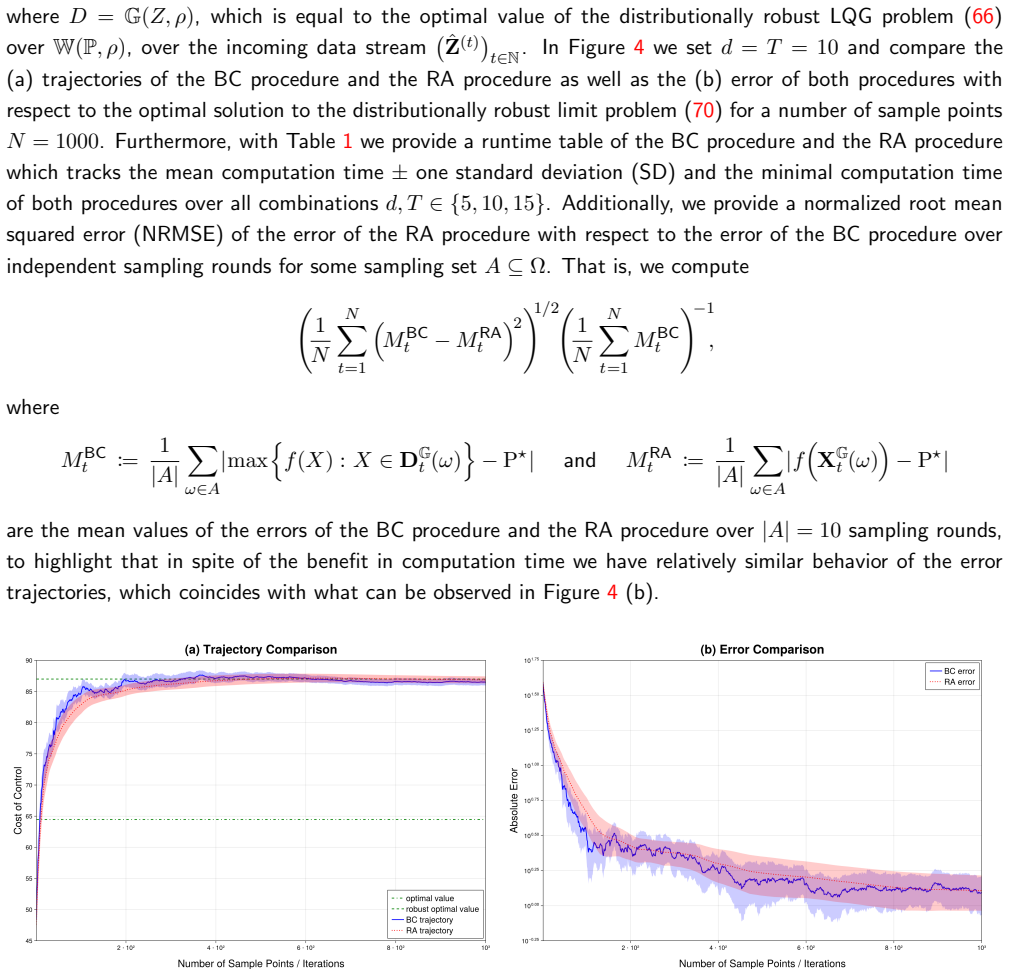
We investigate a recursive variant of the classical Frank-Wolfe algorithm for minimizing a convex differentiable function over a convex compact domain. Unlike the traditional setting, we assume that both the problem domain and the objective function are initially unknown and must be learned from data. To address this, we integrate estimators into the optimization process, allowing the algorithm to iteratively refine approximations of the problem domain and the objective function. Our approach maintains the projection-free nature of the classical Frank-Wolfe algorithm while adapting to the uncertainty inherent in data-driven settings. We establish convergence guarantees for the recursive method, showing that the optimization error scales with the accuracy of the learned estimators. Two experiments support our theoretical findings, demonstrating that the proposed method achieves convergence behavior comparable to that of the classical Frank-Wolfe algorithm under exact knowledge of the problem domain and objective function, while offering significant computational savings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a recursive variant of the Frank-Wolfe algorithm for minimizing a convex differentiable function over a convex compact domain where both the domain and objective are initially unknown and must be learned from data via estimators. The method integrates these estimators into the iterations while preserving the projection-free property, claims convergence guarantees under which optimization error scales with estimator accuracy, and reports two experiments showing convergence behavior comparable to classical Frank-Wolfe (with exact knowledge) alongside computational savings.
Significance. If the claimed convergence guarantees can be established and the estimators integrated without violating convexity or the projection-free property, the work would extend classical Frank-Wolfe methods to data-driven optimization settings with error bounds tied to external estimator quality. This could be relevant for applications where problem parameters are learned iteratively from data.
major comments (1)
- [Abstract] Abstract: the central claim that convergence guarantees are established with optimization error scaling with the accuracy of the learned estimators is unsupported by any derivation steps, explicit bounds, or proof sketch in the manuscript text, which is load-bearing for the paper's main contribution.
minor comments (1)
- The two experiments are mentioned but no details are provided on the test problems, estimator construction, quantitative metrics, or comparison baselines, limiting assessment of the reported computational savings and comparable convergence.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address the major comment point by point below and outline the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that convergence guarantees are established with optimization error scaling with the accuracy of the learned estimators is unsupported by any derivation steps, explicit bounds, or proof sketch in the manuscript text, which is load-bearing for the paper's main contribution.
Authors: We thank the referee for identifying this gap. The abstract summarizes the main result, but we agree that the manuscript text would benefit from more direct support for the claim. In the revised version, we will insert a concise proof sketch and the explicit error bound (showing optimization error scaling linearly with estimator accuracy plus the standard Frank-Wolfe rate) into the introduction or a new short subsection immediately following the problem statement. This addition will make the central contribution self-contained and fully substantiated in the main text. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a recursive Frank-Wolfe variant that incorporates external estimators for the unknown domain and objective, with convergence bounds stated to scale directly with the accuracy of those estimators. No derivation step reduces a claimed prediction or guarantee to a fitted quantity defined inside the algorithm itself, nor does any load-bearing premise rest on self-citation chains or ansatzes imported from prior author work. The abstract and described structure treat estimator accuracy as an independent input parameter rather than a quantity constructed from the optimization iterates, leaving the central claims self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- estimator accuracy
axioms (1)
- domain assumption The domain is convex and compact and the objective is convex and differentiable.
Reference graph
Works this paper leans on
-
[1]
Combettes, Hamed Hassani, Amin Karbasi, Aryan Mokhtari, and Sebastian Pokutta.Conditional Gradient Methods: From Core Principles to AI Applications
G´ abor Braun, Alejandro Carderera, Cyrille W. Combettes, Hamed Hassani, Amin Karbasi, Aryan Mokhtari, and Sebastian Pokutta.Conditional Gradient Methods: From Core Principles to AI Applications. Society for Industrial and Applied Mathematics, 2025. 43 d T BC Procedure RA Procedure NRMSE Mean±SD Minimum Mean±SD Minimum 5 5 0.09282±0.03906 0.05889 0.05185±...
2025
-
[2]
An Algorithm for Quadratic Programming
Marguerite Frank and Philip Wolfe. “An Algorithm for Quadratic Programming”. In:Naval Research Logistics Quarterly3.1-2 (1956), 95 –110
1956
-
[3]
Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization
Martin Jaggi. “Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization”. In:International Conference on Machine Learning. PMLR. 2013, 427– 435
2013
-
[4]
Distributionally Robust Optimization
Daniel Kuhn, Soroosh Shafiee, and Wolfram Wiesemann. “Distributionally Robust Optimization”. In: Acta Numerica34 (2025), 579 – 804
2025
-
[5]
The Complexity of Large-scale Convex Programming under a Linear Optimization Oracle
Guanghui Lan. “The Complexity of Large-Scale Convex Programming under a Linear Optimization Oracle”. In:arXiv preprint, arXiv:1309.5550(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Frank-Wolfe Beyond 1/t Convergence
Sebastian Pokutta. “Frank-Wolfe Beyond 1/t Convergence”. In:arXiv preprint, arXiv:2604.28006(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Linearly Convergent Frank-Wolfe with Backtracking Line -Search
Fabian Pedregosa, Geoffrey Negiar, Armin Askari, and Martin Jaggi. “Linearly Convergent Frank-Wolfe with Backtracking Line -Search”. In:International Conference on Artificial Intelligence and Statistics. PMLR. 2020, 1–10
2020
-
[8]
On the Global Linear Convergence of Frank-Wolfe Optimization Variants
Simon Lacoste -Julien and Martin Jaggi. “On the Global Linear Convergence of Frank-Wolfe Optimization Variants”. In:Advances in Neural Information Processing Systems28 (2015)
2015
-
[9]
Variance-Reduced and Projection-Free Stochastic Optimization
Elad Hazan and Haipeng Luo. “Variance-Reduced and Projection-Free Stochastic Optimization”. In: International Conference on Machine Learning. PMLR. 2016, 1263 –1271
2016
-
[10]
Conditional Gradient Sliding for Convex Optimization
Guanghui Lan and Yi Zhou. “Conditional Gradient Sliding for Convex Optimization”. In:SIAM Journal on Optimization26.2 (2016), 1379 –1409
2016
-
[11]
Generalized Stochastic Frank-Wolfe Algorithm with Stochastic “Substitute
Haihao Lu and Robert M. Freund. “Generalized Stochastic Frank-Wolfe Algorithm with Stochastic “Substitute” Gradient for Structured Convex Optimization”. In:Mathematical Programming187.1 (2021), 317– 349. 44
2021
-
[12]
Non-Convex Conditional Gradient Sliding
Chao Qu, Yan Li, and Huan Xu. “Non-Convex Conditional Gradient Sliding”. In:International Conference on Machine Learning. PMLR. 2018, 4208 – 4217
2018
-
[13]
Block-Coordinate Frank- Wolfe Optimization for Structural SVMs
Simon Lacoste -Julien, Martin Jaggi, Mark Schmidt, and Patrick Pletscher. “Block-Coordinate Frank- Wolfe Optimization for Structural SVMs”. In:International Conference on Machine Learning. PMLR. 2013, 53 – 61
2013
-
[14]
A Dis- tributed Frank-Wolfe Algorithm for Communication-Efficient Sparse Learning
Aur´ elien Bellet, Yingyu Liang, Alireza Bagheri Garakani, Maria-Florina Balcan, and Fei Sha. “A Dis- tributed Frank-Wolfe Algorithm for Communication-Efficient Sparse Learning”. In:Proceedings of the 2015 SIAM International Conference on Data Mining. 2015, 478 – 486
2015
-
[15]
The Knowledge Gradient for Sequential Decision Making with Stochastic Binary Feedbacks
Yingfei Wang, Chu Wang, and Warren Powell. “The Knowledge Gradient for Sequential Decision Making with Stochastic Binary Feedbacks”. In:Proceedings of The 33rd International Conference on Machine Learning. Vol. 48. 2016, 1138 –1147
2016
-
[16]
Stochastic Frank-Wolfe: Unified Analysis and Zoo of Special Cases
Ruslan Nazykov, Aleksandr Shestakov, Vladimir Solodkin, Aleksandr Beznosikov, Gauthier Gidel, and Alexander Gasnikov. “Stochastic Frank-Wolfe: Unified Analysis and Zoo of Special Cases”. In:Proceed- ings of The 27th International Conference on Artificial Intelligence and Statistics. Vol. 238. PMLR, 2024, 4870 – 4878
2024
-
[17]
Society for Industrial and Applied Mathematics, 2014
Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczy´ nski.Lectures on Stochastic Programming: Modeling and Theory. Society for Industrial and Applied Mathematics, 2014
2014
-
[18]
Introduction to Online Convex Optimization
Elad Hazan. “Introduction to Online Convex Optimization”. In:Foundations and Trends in Optimization 2.3-4 (2016), 157–325
2016
-
[19]
Rolf Schneider.Convex Bodies: The Brunn-Minkowski Theory. Vol. 151. Cambridge University Press, 2013
2013
-
[20]
Gerald Beer.Topologies on Closed and Closed Convex Sets. Vol. 268. Springer Science & Business Media, 1993
1993
-
[21]
Ilya Molchanov.Theory of Random Sets. Vol. 87. Springer, 2017
2017
-
[22]
Whitney Extension Theorems for Convex Functions of the Classes C1 andC 1,ω
Daniel Azagra and Carlos Mudarra. “Whitney Extension Theorems for Convex Functions of the Classes C1 andC 1,ω ”. In:Proceedings of the London Mathematical Society114.1 (2017), 133 –158
2017
-
[23]
Aliprantis and Kim C
Charalambos D. Aliprantis and Kim C. Border.Infinite Dimensional Analysis: A Hitchhiker’s Guide. Springer, 2006
2006
-
[24]
Bogachev.Measure Theory
Vladimir I. Bogachev.Measure Theory. Springer, 2007
2007
-
[25]
Tyrrell Rockafellar and Roger J.-B
R. Tyrrell Rockafellar and Roger J.-B. Wets.Variational Analysis. Springer, 1998
1998
-
[26]
Springer, 1977
Charles Castaing and Michel Valadier.Convex Analysis and Measurable Multifunctions. Springer, 1977
1977
-
[27]
Coresets, Sparse Greedy Approximation, and the Frank-Wolfe Algorithm
Kenneth L. Clarkson. “Coresets, Sparse Greedy Approximation, and the Frank-Wolfe Algorithm”. In: ACM Transactions on Algorithms (TALG)6.4 (2010), 1–30
2010
-
[28]
New Analysis and Results for the Frank-Wolfe Method
Robert M. Freund and Paul Grigas. “New Analysis and Results for the Frank-Wolfe Method”. In:Math- ematical Programming155.1 (2016), 199 –230
2016
-
[29]
Generalized Self-Concordant Analysis of Frank-Wolfe Algorithms
Pavel Dvurechensky, Kamil Safin, Shimrit Shtern, and Mathias Staudigl. “Generalized Self-Concordant Analysis of Frank-Wolfe Algorithms”. In:Mathematical Programming198.1 (2023), 255 –323. 45
2023
-
[30]
Oxford University Press, 2013
St´ ephane Boucheron, G´ abor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013
2013
-
[31]
Acceleration of Frank-Wolfe Algorithms with Open-Loop Step-Sizes
Elias Wirth, Thomas Kerdreux, and Sebastian Pokutta. “Acceleration of Frank-Wolfe Algorithms with Open-Loop Step-Sizes”. In:International Conference on Artificial Intelligence and Statistics. PMLR. 2023, 77–100
2023
-
[32]
Accelerated Affine-Invariant Convergence Rates of the Frank-Wolfe Algorithm with Open-Loop Step-Sizes
Elias Wirth, Javier Pena, and Sebastian Pokutta. “Accelerated Affine-Invariant Convergence Rates of the Frank-Wolfe Algorithm with Open-Loop Step-Sizes”. In:Mathematical Programming(2025), 1– 45
2025
-
[33]
Faster Rates for the Frank-Wolfe Method over Strongly-Convex Sets
Dan Garber and Elad Hazan. “Faster Rates for the Frank-Wolfe Method over Strongly-Convex Sets”. In:International Conference on Machine Learning. PMLR. 2015, 541–549
2015
-
[34]
Projection-Free Optimization on Uniformly Convex Sets
Thomas Kerdreux, Alexandre d’Aspremont, and Sebastian Pokutta. “Projection-Free Optimization on Uniformly Convex Sets”. In:International Conference on Artificial Intelligence and Statistics. PMLR. 2021, 19 –27
2021
-
[35]
Brian D. O. Anderson and John B. Moore.Optimal Control: Linear Quadratic Methods. Courier Corpo- ration, 2007
2007
-
[36]
Athena Scientific, 2012
Dimitri Bertsekas.Dynamic Programming and Optimal Control: Volume I. Athena Scientific, 2012
2012
-
[37]
Distributionally Robust Linear Quadratic Control
Bahar Ta¸ skesen, Dan Iancu, C ¸a˘ gil Ko¸ cyi˘ git, and Daniel Kuhn. “Distributionally Robust Linear Quadratic Control”. In:Advances in Neural Information Processing Systems36 (2023), 18613 –18632
2023
-
[38]
Oliver and Boyd, 1963
Claude Berge.Topological Spaces: Including a Treatment of Multi-Valued Functions, Vector Spaces and Convexity. Oliver and Boyd, 1963
1963
-
[39]
Hausdorff Distance and Convex Sets
Michael D. Wills. “Hausdorff Distance and Convex Sets”. In:Journal of Convex Analysis14.1 (2007), 109 –117
2007
-
[40]
Andrews, Richard Askey, and Ranjan Roy.Special Functions
George E. Andrews, Richard Askey, and Ranjan Roy.Special Functions. Cambridge University Press, 1999
1999
-
[41]
On the Bures-Wasserstein Distance Between Positive Definite Matrices
Rajendra Bhatia, Tanvi Jain, and Yongdo Lim. “On the Bures-Wasserstein Distance Between Positive Definite Matrices”. In:Expositiones Mathematicae37.2 (2019), 165 –191
2019
-
[42]
Free States of the Canonical Anticommutation Relations
Robert T. Powers and Erling Størmer. “Free States of the Canonical Anticommutation Relations”. In: Communications in Mathematical Physics16.1 (1970), 1–33
1970
-
[43]
Bridg- ing Bayesian and Minimax Mean Square Error Estimation via Wasserstein Distributionally Robust Opti- mization
Viet Anh Nguyen, Soroosh Shafieezadeh-Abadeh, Daniel Kuhn, and Peyman Mohajerin Esfahani. “Bridg- ing Bayesian and Minimax Mean Square Error Estimation via Wasserstein Distributionally Robust Opti- mization”. In:Mathematics of Operations Research48.1 (2023), 1–37
2023
-
[44]
Bures-Wasserstein Minimizing Geodesics Between Covariance Matrices of Different Ranks
Yann Thanwerdas and Xavier Pennec. “Bures-Wasserstein Minimizing Geodesics Between Covariance Matrices of Different Ranks”. In:SIAM Journal on Matrix Analysis and Applications44.3 (2023), 1447–1476. A. Measurable Correspondences In this section we briefly introduce the notion of correspondences, their measurability and some basic results on measurability ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.