OpenEAI-Platform: An Open-source Embodied Artificial Intelligence Hardware-Software Unified Platform
Pith reviewed 2026-06-28 09:29 UTC · model grok-4.3
The pith
An open-source 6+1 dof arm and two-stage VLA model outperform commercial arms and match large pretrained baselines on real manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
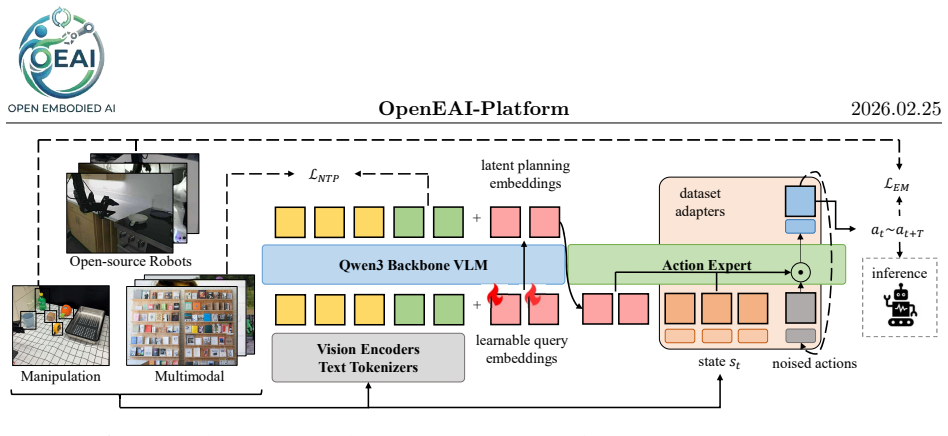
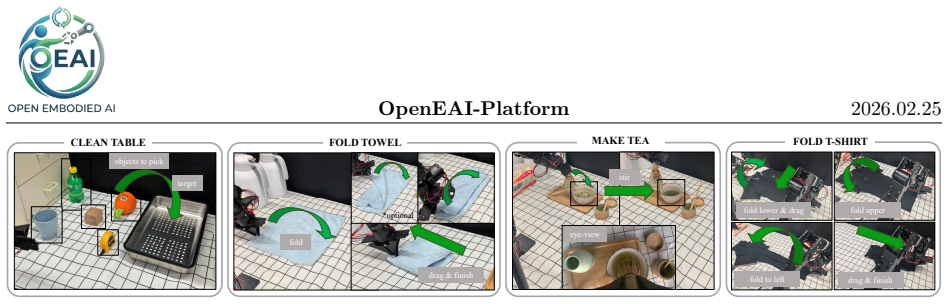
The platform integrates OpenEAI-Arm, whose open-source designs and compliant control deliver higher accuracy at low cost, with OpenEAI-VLA, which applies two-stage training on open robot and multimodal datasets to a Qwen3-VL-4B backbone plus diffusion transformer action head; empirical results show the arm outperforming commercial equivalents and the VLA matching pi0 success rates on four real-world manipulation tasks.
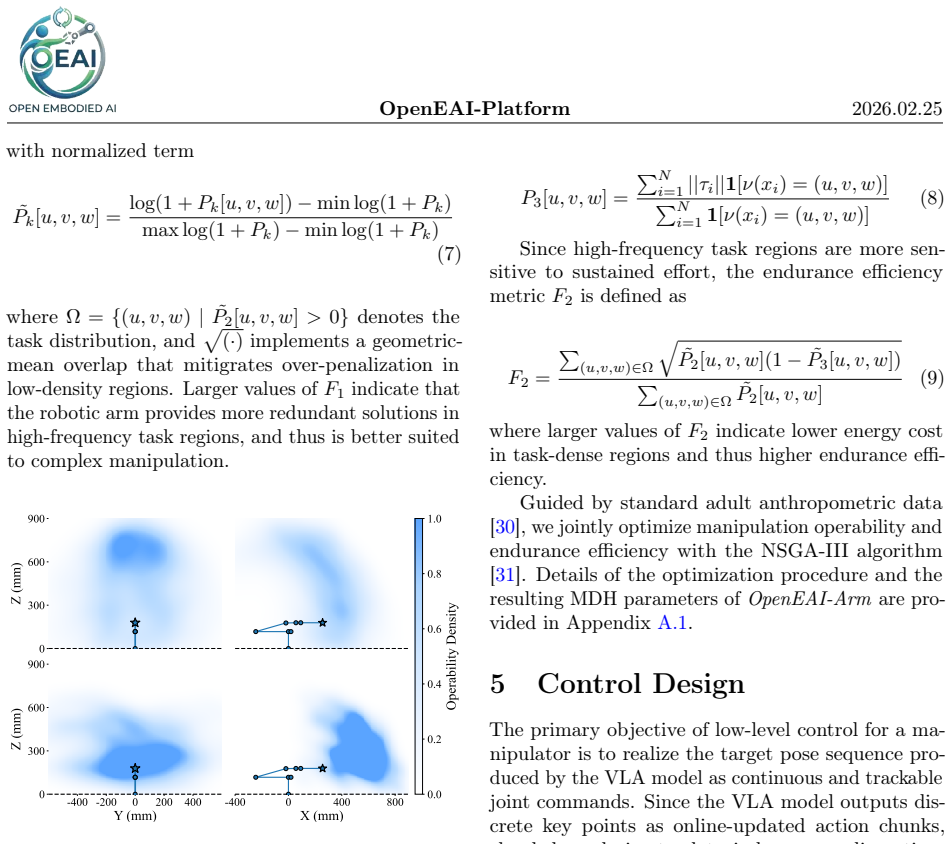
What carries the argument
OpenEAI-Arm mechanical designs with compliant control for accuracy, paired with OpenEAI-VLA's two-stage training on open datasets using Qwen3-VL-4B and a diffusion transformer action head.
If this is right
- Fully open hardware and model releases enable direct reproduction of the reported arm and VLA results by other labs.
- Low manufacturing cost of the 6+1 dof arm broadens access to high-accuracy manipulation hardware for embodied AI experiments.
- Two-stage training on open datasets alone suffices to reach competitive VLA success rates, reducing reliance on large proprietary pretraining.
- The unified platform supports scalable collection of real-world robot data for further policy improvement.
Where Pith is reading between the lines
- A shared open hardware base could standardize evaluation across different VLA methods and speed community progress.
- The design choices may extend to other manipulation domains where cost and reproducibility currently limit experimentation.
- Releasing complete pipelines invites extensions such as multi-arm coordination or integration with additional sensor modalities.
Load-bearing premise
Performance comparisons with commercial arms and the pi0 baseline are fair, with no undisclosed advantages in task choice or evaluation protocol.
What would settle it
An independent test on the same four tasks where the open-source arm fails to outperform the commercial arms or the VLA model falls short of pi0 success rates under matched conditions.
Figures

read the original abstract
Embodied AI in the real world requires both accurate hardware and robust vision-language-action (VLA) policies. We present OpenEAI-Platform, a fully open-source platform that integrates a low-cost 6+1 degree-of-freedom (dof) robotic arm (OpenEAI-Arm) and a reproducible VLA model (OpenEAI-VLA). OpenEAI-Arm provides open-source mechanical designs for low manufacturing cost and compliant control methods for higher accuracy. OpenEAI-VLA builds on Qwen3-VL-4B and uses a Diffusion Transformer action head, and is trained in two stages with only open-source robot and multimodal datasets. Across four real-world manipulation tasks, OpenEAI-Arm outperforms two commercial 6+1-dof arms under the same policy, and OpenEAI-VLA achieves success rates comparable to the large-scale pretrained pi0 baseline with only limited pretraining data. We will release the full hardware designs, drivers, models, and training/data pipelines to support reproducible research and scalable data collection. Our codes, layouts, and models will be released after the paper is accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OpenEAI-Platform, a fully open-source hardware-software platform consisting of OpenEAI-Arm (a low-cost 6+1 DOF robotic arm with open mechanical designs and compliant control methods) and OpenEAI-VLA (a vision-language-action model built on Qwen3-VL-4B with a Diffusion Transformer action head, trained in two stages on open-source robot and multimodal datasets). It claims that OpenEAI-Arm outperforms two commercial 6+1-DOF arms under the same policy across four real-world manipulation tasks, and that OpenEAI-VLA achieves success rates comparable to the large-scale pretrained pi0 baseline using only limited pretraining data. The authors state they will release full hardware designs, drivers, models, and training/data pipelines after acceptance to support reproducibility.
Significance. If the empirical performance claims are substantiated with verifiable data and protocols, the work could meaningfully advance open-source embodied AI by lowering barriers to hardware and model access, enabling broader community-driven research in manipulation and scalable data collection without dependence on proprietary systems.
major comments (2)
- [Abstract] Abstract: The central claims that OpenEAI-Arm outperforms commercial arms and OpenEAI-VLA matches pi0 success rates on four tasks are stated without any supporting quantitative results, success-rate tables, dataset sizes, error bars, statistical tests, or experimental protocols, making the primary empirical contributions impossible to assess from the manuscript.
- [Abstract] Abstract: The assumption of fair comparisons cannot be evaluated because the manuscript supplies no details on task definitions, success metrics, how policies are adapted to differing arm kinematics or compliance, or the evaluation protocol; combined with the statement that designs and pipelines will be released only after acceptance, the load-bearing performance assertions remain unverifiable.
minor comments (1)
- [Abstract] The phrase 'limited pretraining data' is used without specifying volumes, dataset composition, or direct comparison to the pi0 training regime.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments on the abstract. We will revise the abstract to incorporate key quantitative results, task definitions, success metrics, and evaluation protocol references while keeping it concise. The full manuscript already details these elements in the Methods and Experiments sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that OpenEAI-Arm outperforms commercial arms and OpenEAI-VLA matches pi0 success rates on four tasks are stated without any supporting quantitative results, success-rate tables, dataset sizes, error bars, statistical tests, or experimental protocols, making the primary empirical contributions impossible to assess from the manuscript.
Authors: The abstract is a high-level summary; the full manuscript reports quantitative success rates, dataset sizes, error bars where applicable, and experimental protocols in the Experiments section. To improve immediate assessability of the claims, we will revise the abstract to include the main success-rate numbers and a reference to the detailed protocols. revision: yes
-
Referee: [Abstract] Abstract: The assumption of fair comparisons cannot be evaluated because the manuscript supplies no details on task definitions, success metrics, how policies are adapted to differing arm kinematics or compliance, or the evaluation protocol; combined with the statement that designs and pipelines will be released only after acceptance, the load-bearing performance assertions remain unverifiable.
Authors: Task definitions, success metrics, policy adaptation for kinematics/compliance, and the evaluation protocol are described in Sections 3 and 4 of the manuscript. The post-acceptance release timeline is noted in the abstract as standard practice. We will revise the abstract to briefly summarize task definitions, metrics, and protocol to make these elements explicit at the summary level. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external task benchmarks
full rationale
The paper presents an open-source hardware platform and VLA model with reported success rates on four real-world manipulation tasks. No derivation chain, equations, fitted parameters, or first-principles predictions appear in the provided text. Claims of outperforming commercial arms and matching pi0 baselines are framed as direct empirical outcomes under stated conditions, not as quantities derived from or equivalent to the platform's own inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked to support any mathematical result. The work is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion Transformer architecture can serve as an effective action head for vision-language-action policies when attached to a pretrained vision-language model
- domain assumption Two-stage training on open-source robot and multimodal datasets produces models competitive with large-scale pretrained baselines
invented entities (2)
-
OpenEAI-Arm
no independent evidence
-
OpenEAI-VLA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/ abs/2410.24164
Kevin Black, Noah Brown, Danny Driess, Ad- nan Esmail, Michael Equi, Chelsea Finn, Nic- colo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyim- ing Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xi- aoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0:...
Pith/arXiv arXiv 2024
-
[2]
Physical Intelligence, Kevin Black, Noah Brown, JamesDarpinian, KaranDhabalia, DannyDriess, Adnan Esmail, Michael Equi, Chelsea Finn, Nic- colo Fusai, Manuel Y. Galliker, Dibya Ghosh, LachyGroom, KarolHausman, BrianIchter, Szy- mon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, ...
Pith/arXiv arXiv 2025
-
[3]
Zhao, and Chelsea Finn
Zipeng Fu, Tony Z. Zhao, and Chelsea Finn. Mo- bile aloha: Learning bimanual mobile manipula- tion with low-cost whole-body teleoperation. In Conference on Robot Learning (CoRL), 2024
2024
-
[4]
Ler- obot: State-of-the-art machine learning for real- world robotics in pytorch
Remi Cadene, Simon Alibert, Alexander Soare, Quentin Gallouedec, Adil Zouitine, Steven Palma, Pepijn Kooijmans, Michel Aractingi, Mustafa Shukor, Dana Aubakirova, Martino Russi, Francesco Capuano, Caroline Pascal, Jade Choghari, Jess Moss, and Thomas Wolf. Ler- obot: State-of-the-art machine learning for real- world robotics in pytorch. https://github. co...
2024
-
[5]
ARX R5 (Product Page)
ARX-X. ARX R5 (Product Page). https: //arx-x.com/?product/22.html, 2026
2026
-
[6]
Realman RM Series (Product Page)
Realman Robotics. Realman RM Series (Product Page). https://www.realman-robotics.com/ rm-series123, 2026
2026
-
[7]
Franka Research 3 (Product Page)
Franka Robotics. Franka Research 3 (Product Page). https://franka.de/ franka-research-3, 2026
2026
-
[8]
Universal Robotics UR Series (Product Page)
Universal Robotics. Universal Robotics UR Series (Product Page). https: //www.universal-robots.com/products/ ur-series/, 2026
2026
-
[9]
Piper: 6-DoF Robotic Arm (Product Page)
AgileX Robotics. Piper: 6-DoF Robotic Arm (Product Page). https://global.agilex.ai/ products/piper, 2026
2026
-
[10]
YAM 6-DOF Arm (Prod- uct Page)
I2RT Robotics. YAM 6-DOF Arm (Prod- uct Page). https://i2rt.com/products/ yam-6-dof-arm, 2026
2026
-
[11]
Igniting vlms toward the embodied space
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang, Hugo Zhou, James Wang, Lights Shi, Lucy Liang, Make Wang, Qian Wang, Roy Gan, Ryan Yu, Shal- fun Li, Starrick Liu, Sylas Chen, Vincent Chen, and Zach Xu. Igniting vlms toward the embodied space. arXiv preprint arXiv:2509.11766, 2025
arXiv 2025
-
[12]
Zhongyi Zhou, Yichen Zhu, Junjie Wen, Chaomin Shen, and Yi Xu. Chatvla-2: Vision- language-action model with open-world embod- ied reasoning from pretrained knowledge, 2025. URLhttps://arxiv.org/abs/2505.21906
arXiv 2025
-
[13]
Dexvla: Vision-language model with plug-in diffusion ex- pert for general robot control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision-language model with plug-in diffusion ex- pert for general robot control. arXiv preprint arXiv:2502.05855, 2025
Pith/arXiv arXiv 2025
-
[14]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karam- cheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pan- nag Sanketi, Quan Vuong, Thomas Kollar, Ben- jamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.0...
Pith/arXiv arXiv 2024
-
[15]
Smolvla: A vision-language-action model for affordable and efficient robotics, 2025
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Mar- tino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Ca- dene. Smolvla: A vision-language-action model for affordable and efficient robotics, 2025. URL https://arxiv.org/abs/2506.01844
Pith/arXiv arXiv 2025
-
[16]
Smolvlm: Redefining small and efficient multi- modal models.arXiv preprintarXiv:2504.05299, 2025
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. Smolvlm: Redefining small and efficient multi- modal models.arXiv preprintarXiv:2504.05299, 2025
Pith/arXiv arXiv 2025
-
[17]
Prismatic vlms: Investigating the design space of visually-conditioned language models, 2024
Siddharth Karamcheti, Suraj Nair, Ashwin Bal- akrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models, 2024. URL https://arxiv.org/abs/ 2402.07865
arXiv 2024
-
[18]
Diffusion pol- icy: Visuomotor policy learning via action dif- fusion, 2024
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion pol- icy: Visuomotor policy learning via action dif- fusion, 2024. URL https://arxiv.org/abs/ 2303.04137
Pith/arXiv arXiv 2024
-
[19]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained biman- ual manipulation with low-cost hardware, 2023. URLhttps://arxiv.org/abs/2304.13705
Pith/arXiv arXiv 2023
-
[20]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[21]
Diffusion trans- former policy, 2025
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Hengjun Pu, Chengyang Zhao, Ronglei Tong, Yu Qiao, Jifeng Dai, and Yuntao Chen. Diffusion trans- former policy, 2025. URLhttps://arxiv.org/ abs/2410.15959
arXiv 2025
-
[22]
Open X-Embodiment Collaboration, Abby O’Neill, Abdul Rehman, Abhinav Gupta, Ab- hiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, Albert Tung, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anchit Gupta, Andrew Wang, Andrey Kolobov, Anikait Singh, Animesh Garg, ...
Pith/arXiv arXiv 2023
-
[23]
Ronchi, Yin Cui, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays Georgia, Pietro Perona, Deva Ramanan, Larry Zitnick, and Piotr Dollár
Tsung-Yi, Genevieve Patterson, Matteo R. Ronchi, Yin Cui, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays Georgia, Pietro Perona, Deva Ramanan, Larry Zitnick, and Piotr Dollár. Coco 2017: Com- mon objects in context 2017, 2017. URLhttps: //cocodataset.org/#home
2017
-
[24]
Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[25]
Smith, Hannaneh Hajishirzi, Ross Gir- shick, Ali Farhadi, and Aniruddha Kembhavi
Matt Deitke, Christopher Clark, Sangho Lee, Ro- hun Tripathi, Yue Yang, Jae Sung Park, Moham- madreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, YenSung Chen, Ajay Patel, Mark Yatskar, Chris Callison- Burch, Andrew Head, Rose Hendrix, Favyen Bas- 14 OpenEAI-Platform2026.02.25 tani,...
Pith/arXiv arXiv 2024
-
[26]
Octo: An open-source generalist robot policy, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yun- liang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024. URL https://arxiv.org/abs/ 2405.12213
Pith/arXiv arXiv 2024
-
[27]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben- Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URL https://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[28]
Rectified flow: A marginal preserv- ing approach to optimal transport, 2022
Qiang Liu. Rectified flow: A marginal preserv- ing approach to optimal transport, 2022. URL https://arxiv.org/abs/2209.14577
Pith/arXiv arXiv 2022
-
[29]
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Jun- jie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, and Feifei Feng. Chatvla: Unified multimodal under- standing and robot control with vision-language- action model, 2025. URLhttps://arxiv.org/ abs/2502.14420
arXiv 2025
-
[30]
Hu- man dimensions of chinese adults
Standardization Administration of China and State Administration for Market Regulation. Hu- man dimensions of chinese adults. Technical Re- port GB/T 10000-2023, Standardization Admin- istration of China (SAC), Beijing, China, 2023. National Standard of the People’s Republic of China; Replaces GB/T 10000-1988
2023
-
[31]
Kalyanmoy Deb and Himanshu Jain. An evolutionary many-objective optimization al- gorithm using reference-point-based nondomi- nated sorting approach, part i: Solving problems with box constraints. IEEE Transactions on EvolutionaryComputation, 18(4):577–601, 2014. doi: 10.1109/TEVC.2013.2281535. URL https: //ieeexplore.ieee.org/document/6600851
-
[32]
In: 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems
Jared Di Carlo, Patrick M. Wensing, Ben- jamin Katz, Gerardo Bledt, and Sangbae Kim. Dynamic locomotion in the MIT cheetah 3 through convex model-predictive control. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1–9, 2018. doi: 10.1109/IROS. 2018.8594448. URL https://ieeexplore. ieee.org/document/8594448
-
[33]
Julyfun. robotoy. https://github.com/ julyfun/robotoy, 2024. GitHub repository, commit 331f676, accessed 2025-12-23
2024
-
[34]
Mv- umi: A scalable multi-view interface for cross-embodiment learning
Omar Rayyan, John Abanes, Mahmoud Hafez, Anthony Tzes, and Fares Abu-Dakka. Mv- umi: A scalable multi-view interface for cross-embodiment learning. arXiv preprint arXiv:2509.18757, 2025
arXiv 2025
-
[35]
Touch in the wild: Learning fine-grained ma- nipulation with a portable visuo-tactile gripper
Xinyue Zhu, Binghao Huang, and Yunzhu Li. Touch in the wild: Learning fine-grained ma- nipulation with a portable visuo-tactile gripper. arXiv preprint arXiv:2507.15062, 2025
arXiv 2025
-
[36]
Vitamin: Learning contact-rich tasks through robot-free visuo-tactile manipulation interface
Fangchen Liu, Chuanyu Li, Yihua Qin, Ankit Shaw, Jing Xu, Pieter Abbeel, and Rui Chen. Vitamin: Learning contact-rich tasks through robot-free visuo-tactile manipulation interface. arXiv preprint arXiv:2504.06156, 2025
arXiv 2025
-
[37]
Data scaling laws in imitation learning for robotic manipula- tion
Fanqi Lin, Yingdong Hu, Pingyue Sheng, Chuan Wen, Jiacheng You, and Yang Gao. Data scaling laws in imitation learning for robotic manipula- tion. arXiv preprint arXiv:2410.18647, 2024
arXiv 2024
-
[38]
Zeyi Liu, Cheng Chi, Eric Cousineau, Naveen Kuppuswamy, Benjamin Burchfiel, and Shu- ran Song. Maniwav: Learning robot manipu- 15 OpenEAI-Platform2026.02.25 lation from in-the-wild audio-visual data.arXiv preprint arXiv:2406.19464, 2024
arXiv 2024
-
[39]
UMI on legs: Making manipula- tion policies mobile with manipulation-centric whole-body controllers
Huy Ha, Yihuai Gao, Zipeng Fu, Jie Tan, and Shuran Song. UMI on legs: Making manipula- tion policies mobile with manipulation-centric whole-body controllers. In Proceedings of the 2024 Conference on Robot Learning, 2024
2024
-
[40]
Universal ma- nipulation interface: In-the-wild robot teach- ing without in-the-wild robots, 2024
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal ma- nipulation interface: In-the-wild robot teach- ing without in-the-wild robots, 2024. URL https://arxiv.org/abs/2402.10329
Pith/arXiv arXiv 2024
-
[41]
Gello: A general, low- cost, and intuitive teleoperation framework for robot manipulators, 2024
Philipp Wu, Yide Shentu, Zhongke Yi, Xingyu Lin, and Pieter Abbeel. Gello: A general, low- cost, and intuitive teleoperation framework for robot manipulators, 2024. URLhttps://arxiv. org/abs/2309.13037. 16 OpenEAI-Platform2026.02.25 A Appendix A.1 Performance Table Of theOpenEAI-Arm T able A.1:Modified D-H parameters of the robotic arm LinkiJoint Angleθ i...
arXiv 2024
-
[42]
Generalization: The gripper should be capable of tightly gripping various kind of objects of different materials
-
[43]
Wide Range: The gripper should have a large gripper width for large objects, or can be easily expanded for a larger width on demand
-
[44]
Lightweight: The gripper should have a small weight to leave loading to the gripped object and maintain control accuracy
-
[45]
We first choose a parallel gripper design instead of a ball-screw-and-rod design
Decoupling: The gripper should be decoupled with the arm’s control, with fewest parameters like gripper mass and max gripper width. We first choose a parallel gripper design instead of a ball-screw-and-rod design. These two grippers have different motion modes and operating principles. With a parallel gripper, the two fingers translate in a straight line ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.