Human-AI Collaboration and the Transformation of Software Engineering Work
Pith reviewed 2026-06-28 09:04 UTC · model grok-4.3
The pith
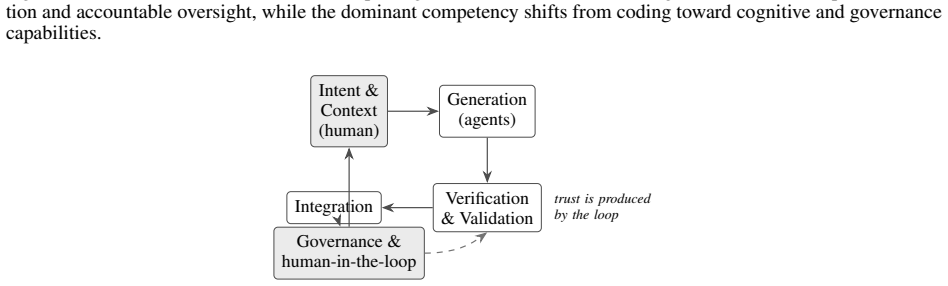
As code becomes abundant through AI, the durable value of software engineers shifts to intent specification, critical judgment, and accountable oversight of autonomous systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
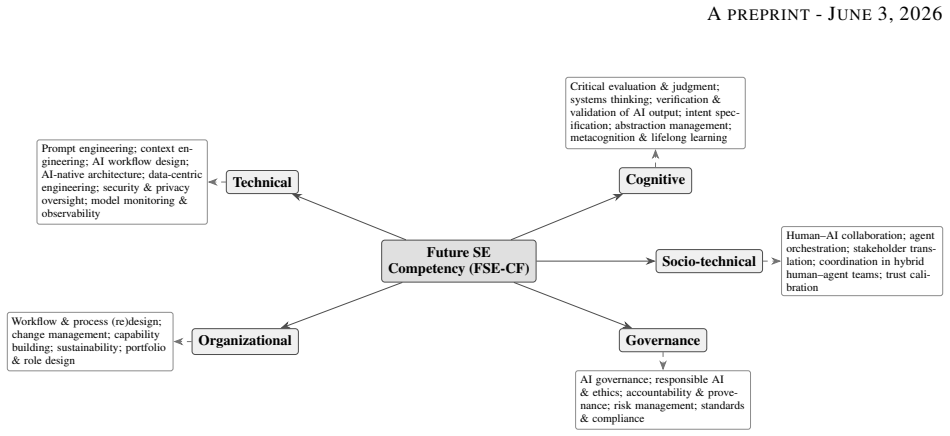
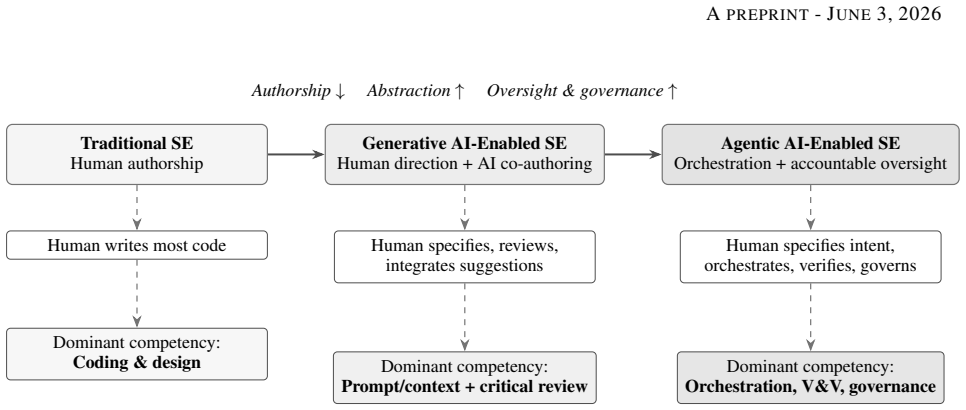
The integration of Generative AI and Agentic AI reconfigures software engineering from an activity centered on human authorship of code into a discipline centered on directing, verifying, and governing autonomous and semi-autonomous systems. Three coexisting paradigms are identified, with activities traced across automation, augmentation, and emergence, leading to an original competency framework in five categories—technical, cognitive, socio-technical, governance, and organizational—operationalized through a matrix and transformation framework. Nine testable propositions are derived, supporting the claim that as code becomes abundant the durable value of the software engineer resides in int
What carries the argument
The competency framework that organizes future engineer capabilities into five interacting categories and links the three paradigms to specific capability demands via a transformation matrix.
If this is right
- Traditional coding activities are automated or augmented while new activities in agent orchestration, verification, validation, and governance emerge.
- Role trajectories over the next decade will emphasize socio-technical systems thinking and accountability over individual coding productivity.
- University curricula must adapt to prioritize intent specification and critical judgment alongside technical skills.
- Organizational leadership needs to redesign performance evaluation and workforce planning around the five competency categories.
- Nine empirically testable propositions provide concrete directions for research on paradigm coexistence and capability evolution.
Where Pith is reading between the lines
- If the framework is adopted, performance reviews in software teams could shift from lines of code or commit counts to measures of successful intent translation and oversight accuracy.
- The three-paradigm model implies that organizations may maintain hybrid teams blending traditional, generative, and agentic practices for different project types rather than a single transition point.
- Extending the propositions could involve controlled experiments comparing oversight effectiveness when engineers use agentic systems versus direct coding on equivalent tasks.
- The emphasis on governance suggests emerging needs for standardized protocols on AI agent accountability that parallel existing software quality assurance processes.
Load-bearing premise
The curated multi-source evidence base of recent peer-reviewed and archival studies is representative and unbiased enough to characterize the three paradigms and support the derived competency framework.
What would settle it
A comprehensive longitudinal study of development teams showing that manual coding volume remains the primary performance metric and that AI agents do not meaningfully shift work toward oversight and governance would falsify the central shift claim.
Figures
read the original abstract
The integration of Generative AI (GenAI) and Agentic AI into software development is reconfiguring software engineering from an activity centered on human authorship of code into a discipline centered on directing, verifying, and governing autonomous and semi-autonomous systems. Drawing on a curated, multi-source evidence base of recent peer-reviewed and archival studies -- including large-scale empirical observations of autonomous coding agents contributing hundreds of thousands of pull requests to open-source repositories -- this paper synthesizes how the locus of engineering work is shifting from individual coding productivity toward human--AI collaboration, agent orchestration, verification and validation, governance, and socio-technical systems thinking. We adopt a structured interpretive synthesis to characterize three coexisting paradigms: Traditional, Generative AI-Enabled, and Agentic AI-Enabled software engineering. We map which traditional activities are being automated, which are being augmented, and which are newly emerging, and we trace plausible role trajectories over the next decade. The paper's principal contribution is an original, theory-driven competency framework that organizes the capabilities required of future engineers into five interacting categories -- % technical, cognitive, socio-technical, governance, and organizational -- % operationalized through a competency matrix and a transformation framework linking paradigm shifts to capability demands. We derive nine empirically testable propositions and articulate implications for theory, industry workforce transformation, university curricula, and organizational leadership. We argue that, as code becomes abundant, the durable value of the software engineer increasingly resides in intent specification, critical judgment, and accountable oversight rather than in the sheer volume of code produced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Generative and Agentic AI are reconfiguring software engineering from human code authorship toward directing, verifying, and governing AI systems. Drawing on a curated multi-source evidence base of peer-reviewed studies and large-scale observations of autonomous agents' pull requests, it characterizes three coexisting paradigms (Traditional, Generative AI-Enabled, Agentic AI-Enabled), maps shifts in activities, and presents an original competency framework organized into five interacting categories. It derives nine empirically testable propositions and argues that, as code becomes abundant, engineer value resides in intent specification, critical judgment, and accountable oversight.
Significance. If the synthesis holds, the paper supplies a useful interpretive lens on AI-driven shifts in software engineering roles, with direct implications for theory, workforce planning, university curricula, and organizational leadership. Credit is due for deriving nine testable propositions from the synthesis and for grounding the framework in large-scale empirical observations of autonomous coding agents, which strengthens the link between observed activity changes and capability demands.
major comments (2)
- [Abstract] Abstract (evidence synthesis paragraph): The description of the 'structured interpretive synthesis' and 'curated, multi-source evidence base' provides no inclusion/exclusion criteria, search strategy, or protocol for handling contradictory evidence. This is load-bearing for the central claim that the three paradigms are supported by the evidence and for the derived competency framework and nine propositions.
- [Competency framework section] Section presenting the competency framework and nine propositions: The mapping from specific studies (including the large-scale PR observations) to the five categories and the nine propositions is not shown explicitly, leaving the empirical grounding of the claim that value shifts to intent specification, judgment, and oversight open to selection concerns.
minor comments (1)
- [Abstract] Abstract: The list of five categories contains stray '%' symbols ('-- % technical, cognitive...') that appear to be editing artifacts and reduce readability.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on methodological transparency. Both points identify areas where greater explicitness will strengthen the paper without changing its interpretive nature or core claims. We address each below.
read point-by-point responses
-
Referee: [Abstract] Abstract (evidence synthesis paragraph): The description of the 'structured interpretive synthesis' and 'curated, multi-source evidence base' provides no inclusion/exclusion criteria, search strategy, or protocol for handling contradictory evidence. This is load-bearing for the central claim that the three paradigms are supported by the evidence and for the derived competency framework and nine propositions.
Authors: We agree the abstract is too terse on method. This is an interpretive synthesis drawing on a curated multi-source base (peer-reviewed studies plus large-scale agent PR data) rather than a systematic review, so formal PRISMA-style criteria were not applied. We will revise the abstract to briefly note the curation approach and add a short methods subsection in the main text describing source selection, handling of contradictory findings, and rationale for the three-paradigm framing. This will make the evidential support for the paradigms, framework, and propositions more transparent. revision: yes
-
Referee: [Competency framework section] Section presenting the competency framework and nine propositions: The mapping from specific studies (including the large-scale PR observations) to the five categories and the nine propositions is not shown explicitly, leaving the empirical grounding of the claim that value shifts to intent specification, judgment, and oversight open to selection concerns.
Authors: We accept that an explicit mapping is needed. We will add a supplementary table (or appendix) that cross-references the cited studies and the autonomous-agent PR observations to each of the five competency categories and to each of the nine propositions. This will document the empirical links without altering the synthesis or the propositions themselves. revision: yes
Circularity Check
No significant circularity; synthesis draws on external evidence and presents original framework
full rationale
The paper performs an interpretive synthesis of external peer-reviewed and archival studies (including large-scale PR observations) to characterize three paradigms and derive an original competency framework plus nine propositions. No load-bearing step reduces by definition, fitted parameter, or self-citation chain to the paper's own inputs; the central claims about shifting engineer value and role trajectories rest on the external evidence base rather than self-referential construction. This is the expected non-finding for a conceptual synthesis paper whose derivation chain is self-contained against independent sources.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The curated multi-source evidence base accurately reflects current trends in AI-assisted software engineering.
Reference graph
Works this paper leans on
-
[1]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. The rise of AI teammates in software engineering (SE) 3.0: How autonomous coding agents are reshaping software engineering.arXiv preprint arXiv:2507.15003, 2025. AIDev dataset available athttps://github.com/SAILResearch/AI_Teammates_in_SE3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Agentic AI software engineers: Programming with trust.arXiv preprint arXiv:2502.13767, 2025
Abhik Roychoudhury, Corina P˘as˘areanu, Michael Pradel, and Baishakhi Ray. Agentic AI software engineers: Programming with trust.arXiv preprint arXiv:2502.13767, 2025
-
[3]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021. 13 APREPRINT- JUNE3, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InProceedings of the Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[6]
Vivek Acharya. Generative AI and the transformation of software development practices.arXiv preprint arXiv:2510.10819, 2025
-
[7]
Human-ai collaboration in software engineering: Lessons learned from a hands-on workshop
Muhammad Hamza, Dominik Siemon, Muhammad Azeem Akbar, and Tahsinur Rahman. Human-ai collaboration in software engineering: Lessons learned from a hands-on workshop. InProceedings of the 7th ACM/IEEE International Workshop on Software-intensive Business, pages 7–14, 2024
2024
-
[8]
How developers interact with ai: A taxonomy of human-ai collaboration in software engineering
Christoph Treude and Marco A Gerosa. How developers interact with ai: A taxonomy of human-ai collaboration in software engineering. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), pages 236–240. IEEE, 2025
2025
-
[9]
Rethinking Software Engineering for Agentic AI Systems
Mamdouh Alenezi. Rethinking software engineering for agentic ai systems.arXiv preprint arXiv:2604.10599, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
When code becomes abundant: Redefining software engineering around orchestration and verification
Karina Kohl and Luigi Carro. When code becomes abundant: Redefining software engineering around orchestration and verification. InProceedings of the 2026 IEEE/ACM 48th International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), 2026
2026
-
[11]
Simin Sun and Miroslaw Staron. Agentic pipelines in embedded software engineering: Emerging practices and challenges.arXiv preprint arXiv:2601.10220, 2026
-
[12]
Tamburri
Silvia Abrahão, John Grundy, Mauro Pezzè, Margaret-Anne Storey, and Damian A. Tamburri. Software engineer- ing by and for humans in an AI era.ACM Transactions on Software Engineering and Methodology, 34(5):1–46, 2025
2025
-
[13]
The rise and fall(?) of software engineering.arXiv preprint arXiv:2406.10141, 2024
Antonio Mastropaolo, Camilo Escobar-Velásquez, and Mario Linares-Vásquez. The rise and fall(?) of software engineering.arXiv preprint arXiv:2406.10141, 2024
-
[14]
Pearson London, UK, 2020
Ian Sommerville.Engineering software products, volume 355. Pearson London, UK, 2020
2020
-
[15]
Brooks.The Mythical Man-Month: Essays on Software Engineering
Frederick P. Brooks.The Mythical Man-Month: Essays on Software Engineering. Addison-Wesley, 1975
1975
-
[16]
Programming as theory building.Microprocessing and Microprogramming, 15(5):253–261, 1985
Peter Naur. Programming as theory building.Microprocessing and Microprogramming, 15(5):253–261, 1985
1985
-
[17]
The SPACE of developer productivity.ACM Queue, 19(1):20–48, 2021
Nicole Forsgren, Margaret-Anne Storey, Chandra Maddila, Thomas Zimmermann, Brian Houck, and Jenna Butler. The SPACE of developer productivity.ACM Queue, 19(1):20–48, 2021
2021
-
[18]
Artificial intelligence for software engineering: The journey so far and the road ahead
Iftekhar Ahmed, Aldeida Aleti, Haipeng Cai, Alexander Chatzigeorgiou, Pinjia He, Xing Hu, Mauro Pezzè, Denys Poshyvanyk, and Xin Xia. Artificial intelligence for software engineering: The journey so far and the road ahead. ACM Transactions on Software Engineering and Methodology, 34(5):1–27, 2025
2025
-
[19]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. The impact of AI on developer productivity: Evidence from GitHub Copilot.arXiv preprint arXiv:2302.06590, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Glassman
Priyan Vaithilingam, Tianyi Zhang, and Elena L. Glassman. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. InExtended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems (CHI EA ’22). ACM, 2022
2022
-
[21]
James, and Nadia Polikarpova
Shraddha Barke, Michael B. James, and Nadia Polikarpova. Grounded Copilot: How programmers interact with code-generating models.Proceedings of the ACM on Programming Languages, 7(OOPSLA1):85–111, 2023
2023
-
[22]
Liang, Chenyang Yang, and Brad A
Jenny T. Liang, Chenyang Yang, and Brad A. Myers. A large-scale survey on the usability of AI programming assistants: Successes and challenges. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE ’24). ACM, 2024
2024
-
[23]
With great power comes great responsibility: The role of software engineers.ACM Transactions on Software Engineering and Methodology, 34(5):1–21, 2025
Stefanie Betz and Birgit Penzenstadler. With great power comes great responsibility: The role of software engineers.ACM Transactions on Software Engineering and Methodology, 34(5):1–21, 2025
2025
-
[24]
Marlowe, Cyril S
Thomas J. Marlowe, Cyril S. Ku, Joseph R. Laracy, Vassilka D. Kirova, and Katherine G. Herbert. A systemic view of a software engineering education curriculum: Requirements and guidelines in the era of generative AI. Journal of Integrated Design and Process Science, 2026
2026
-
[25]
Foundational competencies and responsibili- ties of a research software engineer: Current state and suggestions for future directions.F1000Research, 13:1429, 2025
Florian Goth, Renato Alves, Matthias Braun, Leyla Jael Castro, et al. Foundational competencies and responsibili- ties of a research software engineer: Current state and suggestions for future directions.F1000Research, 13:1429, 2025
2025
-
[26]
GenAI and software engineering: Strategies for shaping the core of tomorrow’s software engineering practice
Olivia Bruhin, Philipp Ebel, Leon Mueller, and Mahei Manhai Li. GenAI and software engineering: Strategies for shaping the core of tomorrow’s software engineering practice. InProceedings of the International Conference on Information Systems (ICIS). Association for Information Systems, 2024. 14 APREPRINT- JUNE3, 2026
2024
-
[27]
AI-driven innovations in software engineering: A review of current practices and future directions.Applied Sciences, 15(3):1344, 2025
Mamdouh Alenezi and Mohammed Akour. AI-driven innovations in software engineering: A review of current practices and future directions.Applied Sciences, 15(3):1344, 2025
2025
-
[28]
Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-François Crespo, and Dan Dennison
D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-François Crespo, and Dan Dennison. Hidden technical debt in machine learning systems. InAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[29]
Software engineering for machine learning: A case study
Saleema Amershi, Andrew Begel, Christian Bird, Robert DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, and Thomas Zimmermann. Software engineering for machine learning: A case study. In Proceedings of the 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 291–300, 2019. 15
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.