SAMatcher: Co-Visibility Modeling with Segment Anything for Robust Feature Matching
Pith reviewed 2026-06-28 11:00 UTC · model grok-4.3
The pith
SAMatcher adapts the Segment Anything Model to predict co-visible regions across image pairs as priors for more reliable feature matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
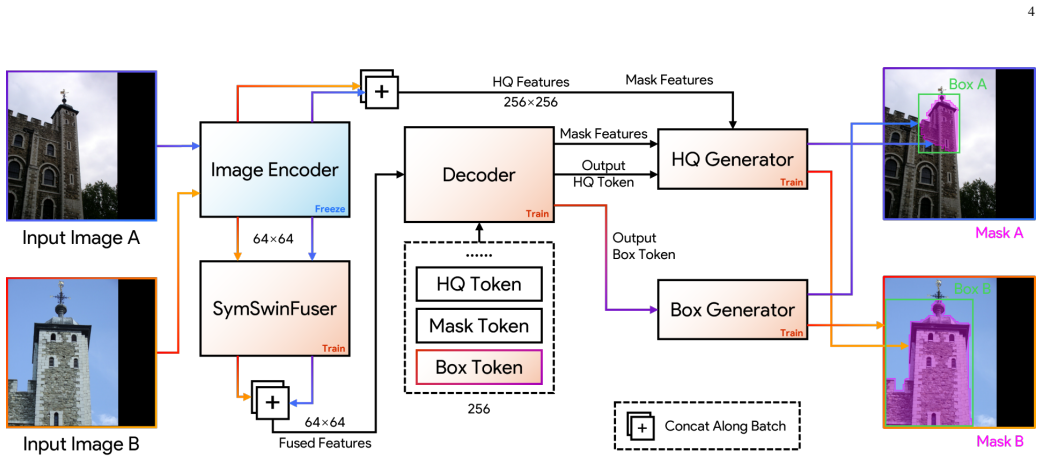
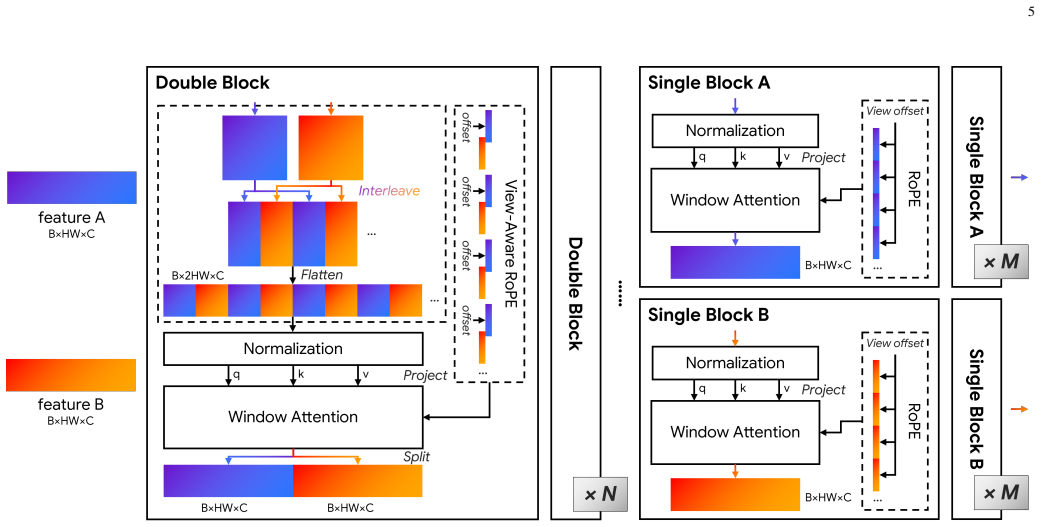
SAMatcher formulates correspondence estimation through co-visibility modeling by first predicting co-visible region masks and bounding boxes as structured priors, using a symmetric cross-view interaction mechanism on the Segment Anything Model that enables bidirectional feature exchange and cross-view semantic alignment, together with a unified supervision scheme that jointly optimizes mask prediction, box regression, and mask-box consistency constraints.
What carries the argument
Symmetric cross-view interaction mechanism on the Segment Anything Model that performs bidirectional feature exchange and cross-view semantic alignment to produce co-visible masks and boxes.
If this is right
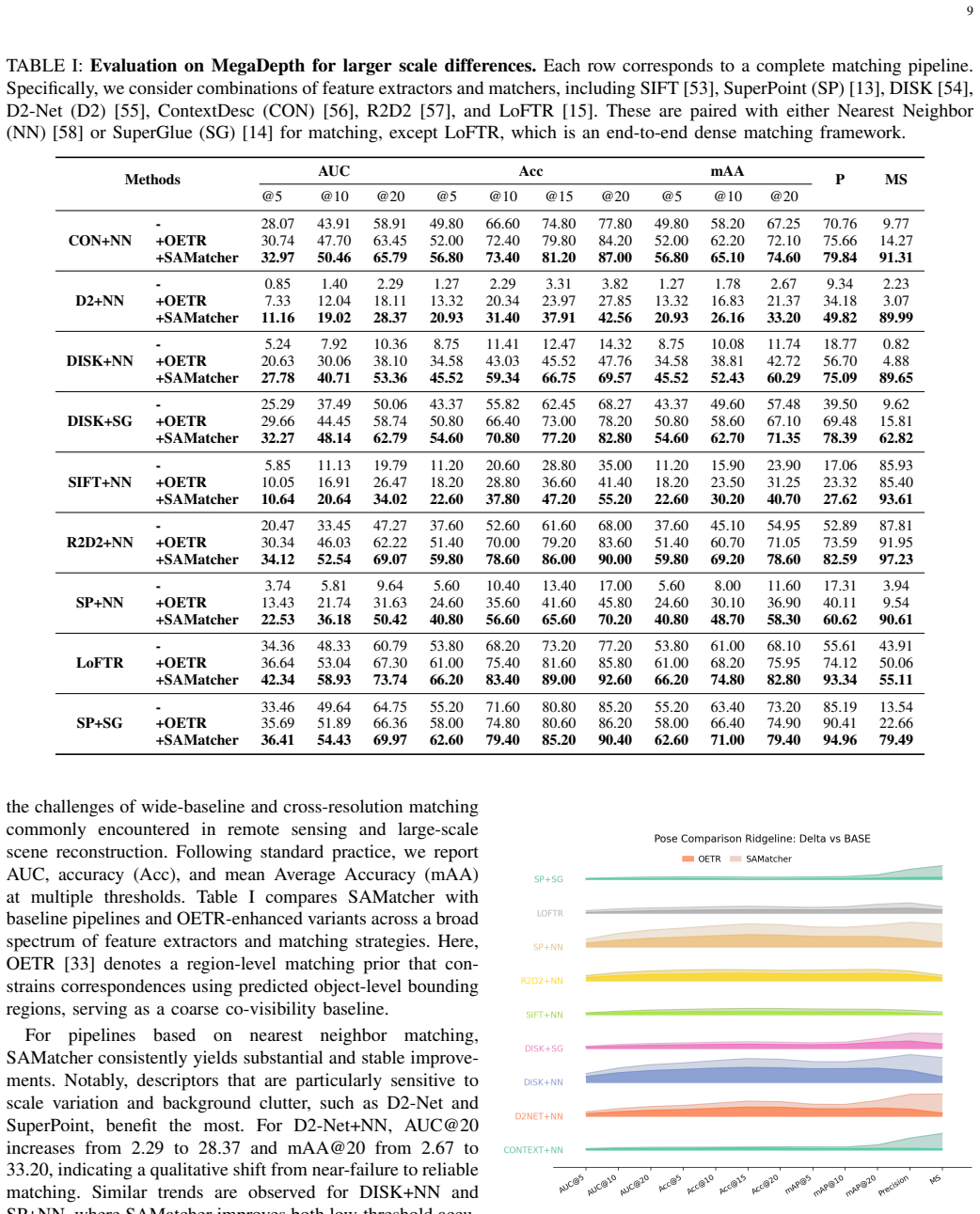
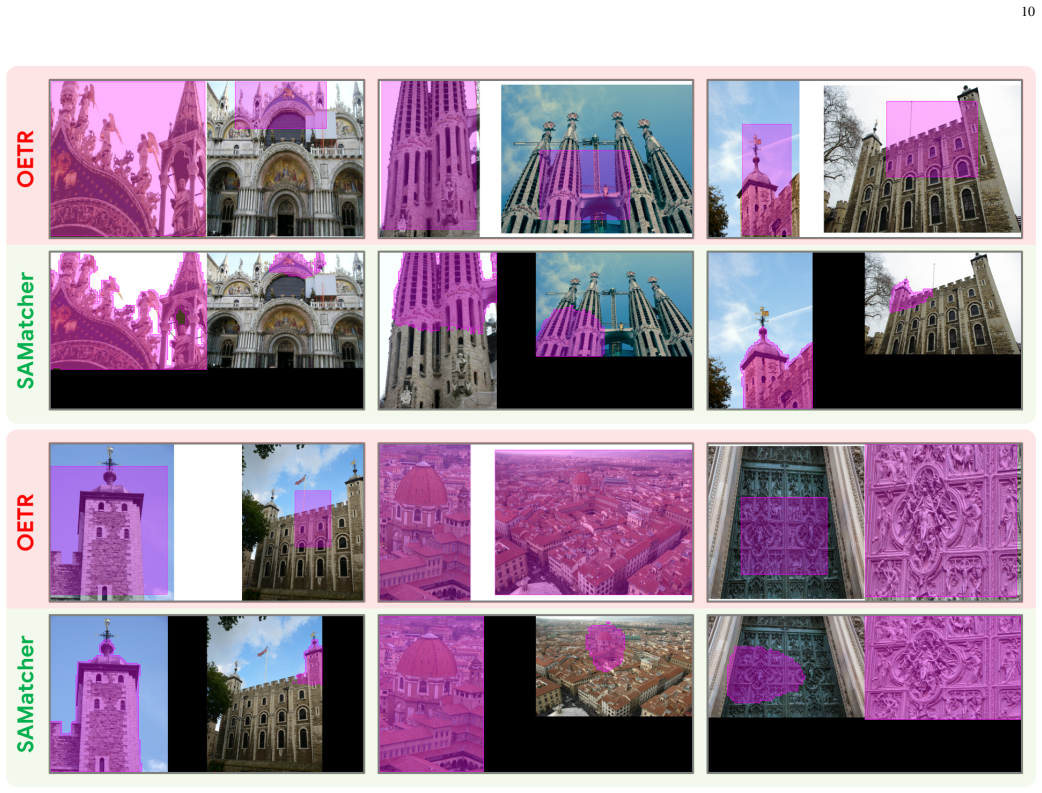
- Matching performance improves substantially on benchmarks that contain large viewpoint and scale variations.
- Structured region-level priors outperform methods that operate only at the pixel or patch level.
- Joint optimization through mask learning, box regression, and mask-box consistency yields better priors than separate training.
- Foundation models trained on monocular segmentation can be extended to multi-view correspondence tasks.
Where Pith is reading between the lines
- The same co-visibility idea could be tested on other pre-trained segmentation or detection models to see if the benefit is specific to SAM.
- In Structure-from-Motion pipelines the region masks might be used to filter outliers before bundle adjustment.
- The approach may help matching when parts of the scene are occluded in one view but not the other.
- If the masks alone prove sufficient, the method could simplify pipelines by reducing reliance on dense local descriptors.
Load-bearing premise
Accurate prediction of co-visible region masks and bounding boxes through the SAM-based symmetric interaction will supply effective structured priors that improve correspondence estimation over direct local feature matching.
What would settle it
On standard matching benchmarks, replace the predicted co-visible masks and boxes with random or empty regions and check whether overall matching accuracy falls back to the level of direct local-feature baselines; if it does not, the value of the co-visibility priors is not supported.
Figures




read the original abstract
Reliable correspondence estimation is a fundamental problem in image processing, underpinning applications such as Structure from Motion, visual localization, and image registration. Existing learning-based methods have significantly improved local feature representations, yet most still operate at the pixel or patch level and lack explicit modeling of regions that are jointly visible across views. We propose SAMatcher, a feature matching framework that formulates correspondence estimation through co-visibility modeling. Instead of directly matching local features, SAMatcher first predicts co-visible region masks and bounding boxes as structured priors for correspondence estimation. Built upon the Segment Anything Model (SAM), it introduces a symmetric cross-view interaction mechanism that enables bidirectional feature exchange and cross-view semantic alignment. We further develop a unified supervision scheme that jointly optimizes mask prediction and box localization through mask learning, box regression, and mask-box consistency constraints. Extensive experiments on challenging benchmarks demonstrate substantial improvements over existing matching pipelines, particularly under large viewpoint and scale variations. Our results show that foundation models originally designed for monocular segmentation can be effectively extended to multi-view correspondence reasoning through explicit co-visibility modeling, offering a new perspective on structured representation learning for image matching. Code and project page: https://xupan.top/Projects/samatcher
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAMatcher, a feature matching framework built on the Segment Anything Model (SAM) that predicts co-visible region masks and bounding boxes via a symmetric cross-view interaction mechanism. These predictions serve as structured priors for correspondence estimation rather than direct local feature matching. A unified supervision scheme jointly optimizes mask prediction, box regression, and mask-box consistency. The work claims substantial improvements over existing pipelines on benchmarks with large viewpoint and scale variations, arguing that monocular segmentation foundation models can be extended to multi-view correspondence through explicit co-visibility modeling.
Significance. If the co-visibility predictions can be shown to function as effective structured priors that improve matching beyond the SAM backbone and interaction module alone, the approach would provide a concrete demonstration of transferring monocular foundation models to multi-view geometric tasks. This could influence future work on structured representation learning for SfM, localization, and registration by offering an alternative to purely pixel- or patch-level matching.
major comments (2)
- [Experiments] The central claim that predicted co-visible masks and boxes act as effective structured priors for correspondence estimation (as opposed to gains arising from the SAM features or symmetric interaction alone) is load-bearing but not isolated. No ablation is described that (a) disables the co-visibility branch while retaining the SAM backbone and cross-view interaction or (b) substitutes oracle co-visible regions; without this, benchmark gains cannot be attributed specifically to the co-visibility modeling.
- [Method] The integration step that uses the predicted masks/boxes as priors in the final correspondence estimation is not detailed with sufficient specificity (e.g., how mask and box outputs modulate feature matching or are combined with local descriptors). This leaves the precise mechanism by which co-visibility modeling improves matching unclear.
minor comments (2)
- [Abstract] The abstract states 'substantial improvements' but does not report concrete metrics (e.g., AUC@5° or matching score deltas on specific datasets); adding these numbers would strengthen the summary of results.
- [Method] Notation for the symmetric interaction and the three supervision terms (mask learning, box regression, mask-box consistency) should be introduced with explicit equations or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on isolating the contribution of co-visibility modeling and clarifying the integration mechanism. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Experiments] The central claim that predicted co-visible masks and boxes act as effective structured priors for correspondence estimation (as opposed to gains arising from the SAM features or symmetric interaction alone) is load-bearing but not isolated. No ablation is described that (a) disables the co-visibility branch while retaining the SAM backbone and cross-view interaction or (b) substitutes oracle co-visible regions; without this, benchmark gains cannot be attributed specifically to the co-visibility modeling.
Authors: We agree that an explicit ablation isolating the co-visibility branch is needed to attribute gains specifically to the structured priors rather than the SAM backbone or interaction module alone. The current experiments compare the full model against external baselines but do not include an internal ablation that removes the mask/box heads while retaining the backbone and cross-view interaction. We will add this ablation (and, if space permits, an oracle co-visible region experiment) in the revised manuscript to directly address the concern. revision: yes
-
Referee: [Method] The integration step that uses the predicted masks/boxes as priors in the final correspondence estimation is not detailed with sufficient specificity (e.g., how mask and box outputs modulate feature matching or are combined with local descriptors). This leaves the precise mechanism by which co-visibility modeling improves matching unclear.
Authors: We acknowledge that the description of how the predicted masks and boxes are integrated into correspondence estimation could be more precise. Section 3.3 states that the outputs serve as structured priors by restricting matching to co-visible regions and using boxes for region-level guidance, but the exact modulation of the similarity matrix or combination with local descriptors is only sketched. In the revision we will expand this section with additional equations, a pseudocode listing, and a figure that explicitly shows the masking operation on the feature correlation volume and the box-guided descriptor aggregation step. revision: yes
Circularity Check
No significant circularity; empirical extension of SAM with independent experimental validation
full rationale
The paper presents an architectural extension of the external Segment Anything Model (SAM) via added symmetric cross-view interaction, mask/box prediction heads, and a joint supervision scheme. No equations, predictions, or uniqueness claims reduce by construction to fitted inputs or self-citations. Performance claims rest on benchmark experiments rather than tautological derivations. The reader's noted weakest assumption concerns empirical effectiveness (addressable by ablation) but does not constitute circularity under the defined criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 4104–4113
2016
-
[2]
Orb-slam: A versatile and accurate monocular slam system,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “Orb-slam: A versatile and accurate monocular slam system,”IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015
2015
-
[3]
Direct sparse odometry,
J. Engel, V . Koltun, and D. Cremers, “Direct sparse odometry,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 3, pp. 611–625, 2017
2017
-
[4]
A comparison and evaluation of multi-view stereo reconstruction al- gorithms,
S. M. Seitz, B. Curless, J. Diebel, D. Scharstein, and R. Szeliski, “A comparison and evaluation of multi-view stereo reconstruction al- gorithms,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, vol. 1. IEEE, 2006, pp. 519–528
2006
-
[5]
Building rome in a day,
S. Agarwal, Y . Furukawa, N. Snavely, I. Simon, B. Curless, S. M. Seitz, and R. Szeliski, “Building rome in a day,”Communications of the ACM, vol. 54, no. 10, pp. 105–112, 2011
2011
-
[6]
Reconstructing the world* in six days*(as captured by the yahoo 100 million image dataset),
J. Heinly, J. L. Schonberger, E. Dunn, and J.-M. Frahm, “Reconstructing the world* in six days*(as captured by the yahoo 100 million image dataset),” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2015, pp. 3287–3295
2015
-
[7]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Computer Vision, vol. 60, pp. 91–110, 2004
2004
-
[8]
Surf: Speeded up robust features,
H. Bay, T. Tuytelaars, and L. Van Gool, “Surf: Speeded up robust features,” inProceedings of the European Conference on Computer Vision. Springer, 2006, pp. 404–417
2006
-
[9]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” inProceedings of the IEEE/CVF International Conference on Computer Vision. Ieee, 2011, pp. 2564–2571
2011
-
[10]
Hartley and A
R. Hartley and A. Zisserman,Multiple view geometry in computer vision. Cambridge university press, 2003
2003
-
[11]
Comparative evaluation of binary features,
J. Heinly, E. Dunn, and J.-M. Frahm, “Comparative evaluation of binary features,” inProceedings of the European Conference on Computer Vision. Springer, 2012, pp. 759–773
2012
-
[12]
Co- matcher: Multi-view collaborative feature matching,
J. Zhang, Z. Xia, M. Dong, S. Shen, L. Yue, and X. Zheng, “Co- matcher: Multi-view collaborative feature matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 21 970–21 980
2025
-
[13]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 224–236
2018
-
[14]
Superglue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superglue: Learning feature matching with graph neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2020, pp. 4938–4947
2020
-
[15]
Loftr: Detector- free local feature matching with transformers,
J. Sun, Z. Shen, Y . Wang, H. Bao, and X. Zhou, “Loftr: Detector- free local feature matching with transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8922–8931
2021
-
[16]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026
2023
-
[17]
Sa-vla: Spatially-aware flow-matching for vision-language- action reinforcement learning,
X. Pan, Z. Wan, X. Yu, X. Zheng, Y . Ke, M. Sun, R. Wang, Z. Wang, and I. Tsang, “Sa-vla: Spatially-aware flow-matching for vision-language- action reinforcement learning,”arXiv preprint arXiv:2602.00743, 2026
-
[18]
Lift: Learned invariant feature transform,
K. M. Yi, E. Trulls, V . Lepetit, and P. Fua, “Lift: Learned invariant feature transform,” inProceedings of the European Conference on Computer Vision. Springer, 2016, pp. 467–483
2016
-
[19]
Match- former: Interleaving attention in transformers for feature matching,
Q. Wang, J. Zhang, K. Yang, K. Peng, and R. Stiefelhagen, “Match- former: Interleaving attention in transformers for feature matching,” in Proceedings of the Asian Conference on Computer Vision, 2022, pp. 2746–2762
2022
-
[20]
Lightglue: Local feature matching at light speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “Lightglue: Local feature matching at light speed,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 627–17 638
2023
-
[21]
Local feature matching using deep learning: A survey,
S. Xu, S. Chen, R. Xu, C. Wang, P. Lu, and L. Guo, “Local feature matching using deep learning: A survey,”Information Fusion, vol. 107, p. 102344, 2024
2024
-
[22]
Fully convolutional networks for semantic segmentation,
J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2015, pp. 3431–3440
2015
-
[23]
Mask r-cnn,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2017, pp. 2961–2969
2017
-
[24]
Per-pixel classification is not all you need for semantic segmentation,
B. Cheng, A. Schwing, and A. Kirillov, “Per-pixel classification is not all you need for semantic segmentation,”Advances in Neural Information Processing Systems, vol. 34, pp. 17 864–17 875, 2021
2021
-
[25]
Segformer: Simple and efficient design for semantic segmentation with transformers,
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,”Advances in Neural Information Processing Systems, vol. 34, pp. 12 077–12 090, 2021
2021
-
[26]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1290–1299
2022
-
[27]
Panoptic segformer: Delving deeper into panoptic segmen- tation with transformers,
Z. Li, W. Wang, E. Xie, Z. Yu, A. Anandkumar, J. M. Alvarez, P. Luo, and T. Lu, “Panoptic segformer: Delving deeper into panoptic segmen- tation with transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1280–1289
2022
-
[28]
Gsva: Generalized segmentation via multimodal large language models,
Z. Xia, D. Han, Y . Han, X. Pan, S. Song, and G. Huang, “Gsva: Generalized segmentation via multimodal large language models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 3858–3869
2024
-
[29]
Image matching across wide baselines: From paper to practice,
Y . Jin, D. Mishkin, A. Mishchuk, J. Matas, P. Fua, K. M. Yi, and E. Trulls, “Image matching across wide baselines: From paper to practice,”International Journal of Computer Vision, vol. 129, no. 2, pp. 517–547, 2021
2021
-
[30]
Eto: Ef- ficient transformer-based local feature matching by organizing multiple homography hypotheses,
J. Ni, G. Zhang, G. Li, Y . Li, X. Liu, Z. Huang, and H. Bao, “Eto: Ef- ficient transformer-based local feature matching by organizing multiple homography hypotheses,”Advances in Neural Information Processing Systems, vol. 37, pp. 60 260–60 274, 2024
2024
-
[31]
Cotr: Correspondence transformer for matching across images,
W. Jiang, E. Trulls, J. Hosang, A. Tagliasacchi, and K. M. Yi, “Cotr: Correspondence transformer for matching across images,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6207–6217
2021
-
[32]
Back to the feature: Learning robust camera localization from pixels to pose,
P.-E. Sarlin, A. Unagar, M. Larsson, H. Germain, C. Toft, V . Larsson, M. Pollefeys, V . Lepetit, L. Hammarstrand, F. Kahlet al., “Back to the feature: Learning robust camera localization from pixels to pose,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3247–3257
2021
-
[33]
Guide local feature matching by overlap estimation,
Y . Chen, D. Huang, S. Xu, J. Liu, and Y . Liu, “Guide local feature matching by overlap estimation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 1, 2022, pp. 365–373
2022
-
[34]
Is-mvsnet: Importance sampling-based mvsnet,
L. Wang, Y . Gong, X. Ma, Q. Wang, K. Zhou, and L. Chen, “Is-mvsnet: Importance sampling-based mvsnet,” inProceedings of the European Conference on Computer Vision. Springer, 2022, pp. 668–683
2022
-
[35]
Learning intra- view and cross-view geometric knowledge for stereo matching,
R. Gong, W. Liu, Z. Gu, X. Yang, and J. Cheng, “Learning intra- view and cross-view geometric knowledge for stereo matching,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 752–20 762
2024
-
[36]
Telling left from right: Identifying geometry-aware semantic correspondence,
J. Zhang, C. Herrmann, J. Hur, E. Chen, V . Jampani, D. Sun, and M.- H. Yang, “Telling left from right: Identifying geometry-aware semantic correspondence,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 3076–3085
2024
-
[37]
Joint semantic segmentation using representations of lidar point clouds and camera images,
Y . Wu, J. Liu, M. Gong, Q. Miao, W. Ma, and C. Xu, “Joint semantic segmentation using representations of lidar point clouds and camera images,”Information Fusion, vol. 108, p. 102370, 2024. 14
2024
-
[38]
Mvg-net: Lidar point cloud semantic segmentation network integrating multi-view images,
Y . Liu, Y . Liu, and Y . Duan, “Mvg-net: Lidar point cloud semantic segmentation network integrating multi-view images,”Remote Sensing, vol. 16, no. 15, p. 2821, 2024
2024
-
[39]
Segment anything in high quality,
L. Ke, M. Ye, M. Danelljan, Y .-W. Tai, C.-K. Tang, F. Yuet al., “Segment anything in high quality,”Advances in Neural Information Processing Systems, vol. 36, pp. 29 914–29 934, 2023
2023
-
[40]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafsonet al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4195–4205
2023
-
[42]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 180–15 190
2023
-
[43]
Swin transformer v2: Scaling up capacity and resolution,
Z. Liu, H. Hu, Y . Lin, Z. Yao, Z. Xie, Y . Wei, J. Ning, Y . Cao, Z. Zhang, L. Donget al., “Swin transformer v2: Scaling up capacity and resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 009–12 019
2022
-
[44]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[45]
Pointrend: Image segmen- tation as rendering,
A. Kirillov, Y . Wu, K. He, and R. Girshick, “Pointrend: Image segmen- tation as rendering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9799–9808
2020
-
[46]
Megadepth: Learning single-view depth predic- tion from internet photos,
Z. Li and N. Snavely, “Megadepth: Learning single-view depth predic- tion from internet photos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[47]
Structure-from-motion revisited,
J. L. Sch ¨onberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016
2016
-
[48]
Pixelwise view selection for unstructured multi-view stereo,
J. L. Sch ¨onberger, E. Zheng, M. Pollefeys, and J.-M. Frahm, “Pixelwise view selection for unstructured multi-view stereo,” inProceedings of the European Conference on Computer Vision, 2016
2016
-
[49]
Scale-aware co-visible region detection for image matching,
X. Pan, Z. Xia, and X. Zheng, “Scale-aware co-visible region detection for image matching,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 229, pp. 122–137, 2025
2025
-
[50]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[51]
Matchable image retrieval by learning from surface reconstruction,
T. Shen, Z. Luo, L. Zhou, R. Zhang, S. Zhu, T. Fang, and L. Quan, “Matchable image retrieval by learning from surface reconstruction,” in Proceedings of the Asian Conference on Computer Vision, 2018
2018
-
[52]
Geodesc: Learning local descriptors by integrating geometry constraints,
Z. Luo, T. Shen, L. Zhou, S. Zhu, R. Zhang, Y . Yao, T. Fang, and L. Quan, “Geodesc: Learning local descriptors by integrating geometry constraints,” inProceedings of the European Conference on Computer Vision, 2018
2018
-
[53]
Object recognition from local scale-invariant features,
D. G. Lowe, “Object recognition from local scale-invariant features,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, vol. 2. Ieee, 1999, pp. 1150–1157
1999
-
[54]
Disk: Learning local features with policy gradient,
M. Tyszkiewicz, P. Fua, and E. Trulls, “Disk: Learning local features with policy gradient,”Advances in Neural Information Processing Sys- tems, vol. 33, pp. 14 254–14 265, 2020
2020
-
[55]
D2-net: A trainable CNN for joint description and detection of local features,
M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, and T. Sattler, “D2-net: A trainable CNN for joint description and detection of local features,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8092–8101
2019
-
[56]
Contextdesc: Local descriptor augmentation with cross-modality con- text,
Z. Luo, T. Shen, L. Zhou, J. Zhang, Y . Yao, S. Li, T. Fang, and L. Quan, “Contextdesc: Local descriptor augmentation with cross-modality con- text,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2527–2536
2019
-
[57]
R2d2: Reliable and repeatable detector and descriptor,
J. Revaud, C. De Souza, M. Humenberger, and P. Weinzaepfel, “R2d2: Reliable and repeatable detector and descriptor,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[58]
Traveling salesman should not be greedy: domination analysis of greedy-type heuristics for the tsp,
G. Gutin, A. Yeo, and A. Zverovich, “Traveling salesman should not be greedy: domination analysis of greedy-type heuristics for the tsp,” Discrete Applied Mathematics, vol. 117, no. 1-3, pp. 81–86, 2002
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.