IDO: Incongruity-aware Distribution Optimization for Multimodal Fake News Detection
Pith reviewed 2026-06-28 10:51 UTC · model grok-4.3
The pith
IDO models factual and modality incongruity to improve multimodal fake news detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
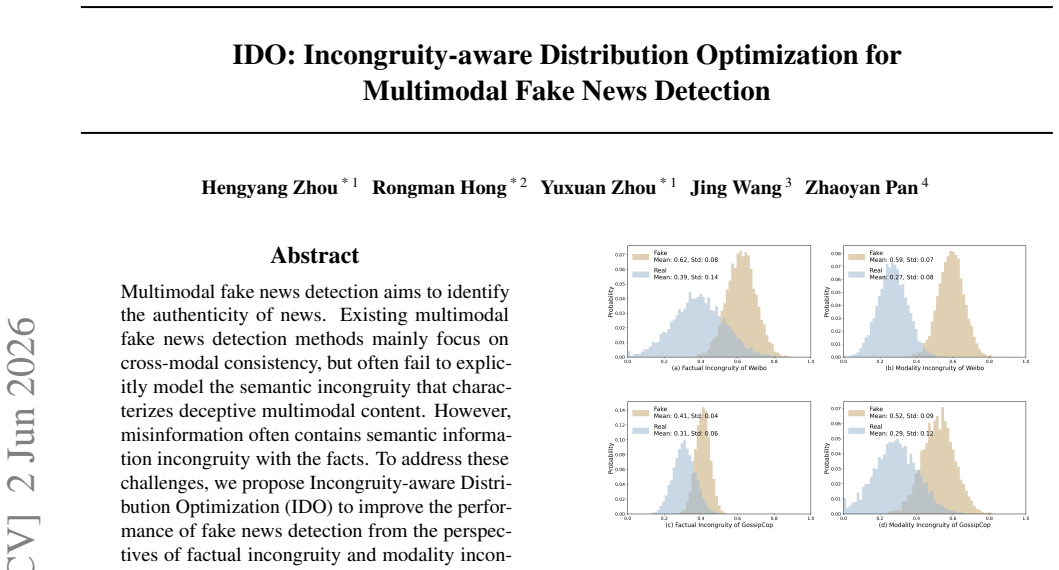
IDO improves fake news detection by addressing factual incongruity through a channel-wise reweighting strategy that yields semantically discriminative embeddings and Gaussian distributions that model the uncertain correlation caused by factual mismatch, and by addressing modality incongruity through incongruity contrastive learning that learns cross-modal semantic information.
What carries the argument
Incongruity-aware Distribution Optimization (IDO) using channel-wise reweighting, Gaussian distribution modeling for factual incongruity, and incongruity contrastive learning for modality incongruity.
If this is right
- Channel-wise reweighting produces embeddings that better separate real from deceptive multimodal content.
- Gaussian modeling captures uncertainty arising from factual mismatches between text and image.
- Incongruity contrastive learning strengthens cross-modal representations for detection.
- The combined approach reaches state-of-the-art accuracy on standard multimodal fake news benchmarks.
Where Pith is reading between the lines
- The same reweighting-plus-Gaussian-plus-contrastive pattern could be tested on other mismatch-sensitive tasks such as multimodal rumor verification.
- Performance gains may be largest on news items where image and text contradict each other on key facts.
- The method could be extended by replacing the Gaussian with other uncertainty distributions if the data exhibit heavier tails.
Load-bearing premise
Existing multimodal fake news detection methods mainly focus on cross-modal consistency but fail to explicitly model the semantic incongruity that characterizes deceptive content.
What would settle it
A controlled experiment on a dataset of fake multimodal items engineered to contain no factual or modality incongruity, in which IDO fails to outperform standard consistency-based detectors, would falsify the claim.
Figures
read the original abstract
Multimodal fake news detection aims to identify the authenticity of news. Existing multimodal fake news detection methods mainly focus on cross-modal consistency, but often fail to explicitly model the semantic incongruity that characterizes deceptive multimodal content. However, misinformation often contains semantic information incongruity with the facts. To address these challenges, we propose Incongruity-aware Distribution Optimization (IDO) to improve the performance of fake news detection from the perspectives of factual incongruity and modality incongruity. For factual incongruity, we introduce a channel-wise reweighting strategy to obtain semantically discriminative embeddings and utilize gaussian distribution to model the uncertain correlation caused by factual incongruity. For modality incongruity, we utilize incongruity contrastive learning to learn cross-modal semantic information. Experiments demonstrate that IDO achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Incongruity-aware Distribution Optimization (IDO) for multimodal fake news detection. It claims that prior methods emphasize cross-modal consistency but overlook semantic incongruity in deceptive content. IDO targets factual incongruity via channel-wise reweighting to produce discriminative embeddings and Gaussian distributions to capture uncertain correlations, while addressing modality incongruity through incongruity contrastive learning. The abstract states that experiments show IDO attains state-of-the-art performance.
Significance. If the empirical claims hold with proper validation, the work could advance multimodal fake news detection by shifting focus from consistency to explicit incongruity modeling, using distribution-based uncertainty handling and contrastive objectives. This direction aligns with known challenges in deceptive multimodal content and might yield more robust detectors if the components prove additive and generalizable.
major comments (1)
- [Abstract] Abstract: The central claim that IDO achieves state-of-the-art performance is unsupported by any reported metrics, baselines, datasets, ablation results, or experimental protocol. Without these, the soundness of the factual-incongruity and modality-incongruity components cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the detailed review. The single major comment concerns the abstract's SOTA claim lacking supporting details. We address this below and propose a targeted revision to the abstract while noting that the full manuscript already contains the requested experimental information.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that IDO achieves state-of-the-art performance is unsupported by any reported metrics, baselines, datasets, ablation results, or experimental protocol. Without these, the soundness of the factual-incongruity and modality-incongruity components cannot be assessed.
Authors: The abstract is written as a concise summary, with the full experimental protocol, datasets (e.g., typical multimodal fake news benchmarks), baselines, quantitative metrics, and ablation studies reported in the Experiments section of the manuscript. We agree that the abstract would benefit from being more self-contained. We will revise the abstract to briefly include the key datasets, main baselines, and primary performance metrics demonstrating SOTA results. This change will allow readers to evaluate the central claim directly from the abstract without needing to consult the full text. revision: yes
Circularity Check
No significant circularity
full rationale
The provided document contains only the abstract. No equations, loss functions, optimization procedures, or derivation steps are present that could be inspected for reductions to fitted inputs, self-definitions, or self-citation chains. The method is described at a high level (channel-wise reweighting, Gaussian modeling, contrastive learning) without any visible construction that equates a claimed prediction to its own inputs. This is the normal case of an abstract-only view where no circularity can be exhibited by quote and reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
Zhou, Xinyi and Zafarani, Reza , title =. 2020 , issue_date =. doi:10.1145/3395046 , journal =
-
[13]
Khattar, Dhruv and Goud, Jaipal Singh and Gupta, Manish and Varma, Vasudeva , title =. 2019 , isbn =. doi:10.1145/3308558.3313552 , booktitle =
-
[14]
SpotFake: A Multi-modal Framework for Fake News Detection , year=
Singhal, Shivangi and Shah, Rajiv Ratn and Chakraborty, Tanmoy and Kumaraguru, Ponnurangam and Satoh, Shin'ichi , booktitle=. SpotFake: A Multi-modal Framework for Fake News Detection , year=
-
[15]
Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=
SAFE: Similarity-Aware Multi-modal Fake News Detection , author=. Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=. 2020 , organization=
2020
-
[16]
Multimodal Fusion with Co-Attention Networks for Fake News Detection
Wu, Yang and Zhan, Pengwei and Zhang, Yunjian and Wang, Liming and Xu, Zhen. Multimodal Fusion with Co-Attention Networks for Fake News Detection. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.226
-
[17]
Detecting fake news by exploring the consistency of multimodal data , journal =
Junxiao Xue and Yabo Wang and Yichen Tian and Yafei Li and Lei Shi and Lin Wei , keywords =. Detecting fake news by exploring the consistency of multimodal data , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.ipm.2021.102610 , url =
-
[18]
Chen, Yixuan and Li, Dongsheng and Zhang, Peng and Sui, Jie and Lv, Qin and Tun, Lu and Shang, Li , title =. 2022 , isbn =. doi:10.1145/3485447.3511968 , booktitle =
-
[19]
Wang, Longzheng and Zhang, Chuang and Xu, Hongbo and Xu, Yongxiu and Xu, Xiaohan and Wang, Siqi , title =. 2023 , isbn =. doi:10.1145/3581783.3613850 , booktitle =
-
[20]
Ying, Qichao and Hu, Xiaoxiao and Zhou, Yangming and Qian, Zhenxing and Zeng, Dan and Ge, Shiming , title =. 2023 , isbn =. doi:10.1609/aaai.v37i4.25670 , booktitle =
-
[21]
Multimodal Fake News Detection via CLIP-Guided Learning , year=
Zhou, Yangming and Yang, Yuzhou and Ying, Qichao and Qian, Zhenxing and Zhang, Xinpeng , booktitle=. Multimodal Fake News Detection via CLIP-Guided Learning , year=
-
[22]
Liu, Yifan and Liu, Yaokun and Li, Zelin and Yao, Ruichen and Zhang, Yang and Wang, Dong , title =. 2025 , isbn =. doi:10.1145/3696410.3714522 , booktitle =
-
[23]
Wang, Yaqing and Ma, Fenglong and Jin, Zhiwei and Yuan, Ye and Xun, Guangxu and Jha, Kishlay and Su, Lu and Gao, Jing , title =. 2018 , isbn =. doi:10.1145/3219819.3219903 , booktitle =
-
[24]
Wang, Jiandong and Zhang, Hongguang and Liu, Chun and Yang, Xiongjun , title =. 2024 , isbn =. doi:10.1145/3626772.3657905 , booktitle =
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
RaCMC: Residual-Aware Compensation Network with Multi-Granularity Constraints for Fake News Detection , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i1.32084 , abstractNote=
-
[26]
Novel Visual and Statistical Image Features for Microblogs News Verification , year=
Jin, Zhiwei and Cao, Juan and Zhang, Yongdong and Zhou, Jianshe and Tian, Qi , journal=. Novel Visual and Statistical Image Features for Microblogs News Verification , year=
-
[27]
Nan, Qiong and Cao, Juan and Zhu, Yongchun and Wang, Yanyan and Li, Jintao , title =. 2021 , isbn =. doi:10.1145/3459637.3482139 , booktitle =
-
[28]
arXiv preprint arXiv:1809.01286 , year=
FakeNewsNet: A Data Repository with News Content, Social Context and Dynamic Information for Studying Fake News on Social Media , author=. arXiv preprint arXiv:1809.01286 , year=
-
[29]
International Conference on Machine Learning , pages=
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Balanced multimodal learning via on-the-fly gradient modulation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Pmr: Prototypical modal rebalance for multimodal learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Boosting multi-modal model performance with adaptive gradient modulation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
International Conference on Machine Learning , pages=
ReconBoost: Boosting Can Achieve Modality Reconcilement , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[34]
International Conference on Machine Learning , pages=
MMPareto: Boosting Multimodal Learning with Innocent Unimodal Assistance , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[35]
Advances in Neural Information Processing Systems , volume=
Facilitating multimodal classification via dynamically learning modality gap , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
Classifier-guided gradient modulation for enhanced multimodal learning , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[38]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[39]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[40]
arXiv preprint arXiv:2301.04246 , year=
Generative language models and automated influence operations: Emerging threats and potential mitigations , author=. arXiv preprint arXiv:2301.04246 , year=
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Unveiling implicit deceptive patterns in multi-modal fake news via neuro-symbolic reasoning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Fka-owl: Advancing multimodal fake news detection through knowledge-augmented lvlms , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[43]
Disinformation, Misinformation, and Fake News in Social Media: Emerging Research Challenges and Opportunities , pages=
Exploring the role of visual content in fake news detection , author=. Disinformation, Misinformation, and Fake News in Social Media: Emerging Research Challenges and Opportunities , pages=. 2020 , publisher=
2020
-
[44]
arXiv preprint arXiv:2510.05839 , year=
Towards Robust and Relible Multimodal Misinformation Recognition with Incomplete Modality , author=. arXiv preprint arXiv:2510.05839 , year=
-
[45]
2018 , eprint=
Approximation Methods for Bilevel Programming , author=. 2018 , eprint=
2018
-
[46]
Journal of Global optimization , volume=
Bilevel and multilevel programming: A bibliography review , author=. Journal of Global optimization , volume=. 1994 , publisher=
1994
-
[47]
Proceedings of the 39th International Conference on Machine Learning , pages =
Model Agnostic Sample Reweighting for Out-of-Distribution Learning , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[48]
Uncertainty Modeling for Out-of-Distribution Generalization , author=
-
[49]
Advances in neural information processing systems , volume=
Implicit semantic data augmentation for deep networks , author=. Advances in neural information processing systems , volume=
-
[50]
IEEE transactions on pattern analysis and machine intelligence , volume=
Multimodal machine learning: A survey and taxonomy , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
2018
-
[51]
Proceedings of the european conference on computer vision (ECCV) , pages=
``Factual''or``Emotional'': Stylized Image Captioning with Adaptive Learning and Attention , author=. Proceedings of the european conference on computer vision (ECCV) , pages=
-
[52]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Counterfactual vqa: A cause-effect look at language bias , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[54]
Wei, Yiwei and Yuan, Shaozu and Zhou, Hengyang and Wang, Longbiao and Yan, Zhiling and Yang, Ruosong and Chen, Meng , booktitle=. G\^
-
[55]
Knowledge-Based Systems , volume=
Towards multimodal sarcasm detection via label-aware graph contrastive learning with back-translation augmentation , author=. Knowledge-Based Systems , volume=. 2024 , publisher=
2024
-
[56]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
LDGNet: LLMs Debate-Guided Network for Multimodal Sarcasm Detection , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[57]
IEEE Transactions on Circuits and Systems for Video Technology , year=
DeepMSD: Advancing Multimodal Sarcasm Detection through Knowledge-augmented Graph Reasoning , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[58]
2026 , eprint=
DIVER: Dynamic Iterative Visual Evidence Reasoning for Multimodal Fake News Detection , author=. 2026 , eprint=
2026
-
[59]
IEEE Transactions on Multimedia , year=
Enhancing Semantic Awareness by Sentimental Constraint with Automatic Outlier Masking for Multimodal Sarcasm Detection , author=. IEEE Transactions on Multimedia , year=
-
[60]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards Multimodal Sentiment Analysis via Hierarchical Correlation Modeling with Semantic Distribution Constraints , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[61]
arXiv preprint arXiv:2604.25618 , year=
Beyond Isolated Utterances: Cue-Guided Interaction for Context-Dependent Conversational Multimodal Understanding , author=. arXiv preprint arXiv:2604.25618 , year=
-
[62]
2026 , eprint=
State-Anchored Complete-View Distillation for Robust Conversational Multimodal Emotion Recognition , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.