Large Language Models Are Overconfident in Their Own Responses
Pith reviewed 2026-06-28 10:12 UTC · model grok-4.3
The pith
Instruction-tuned LLMs assign up to 26% higher confidence to answers they generated themselves than to identical answers framed as user input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
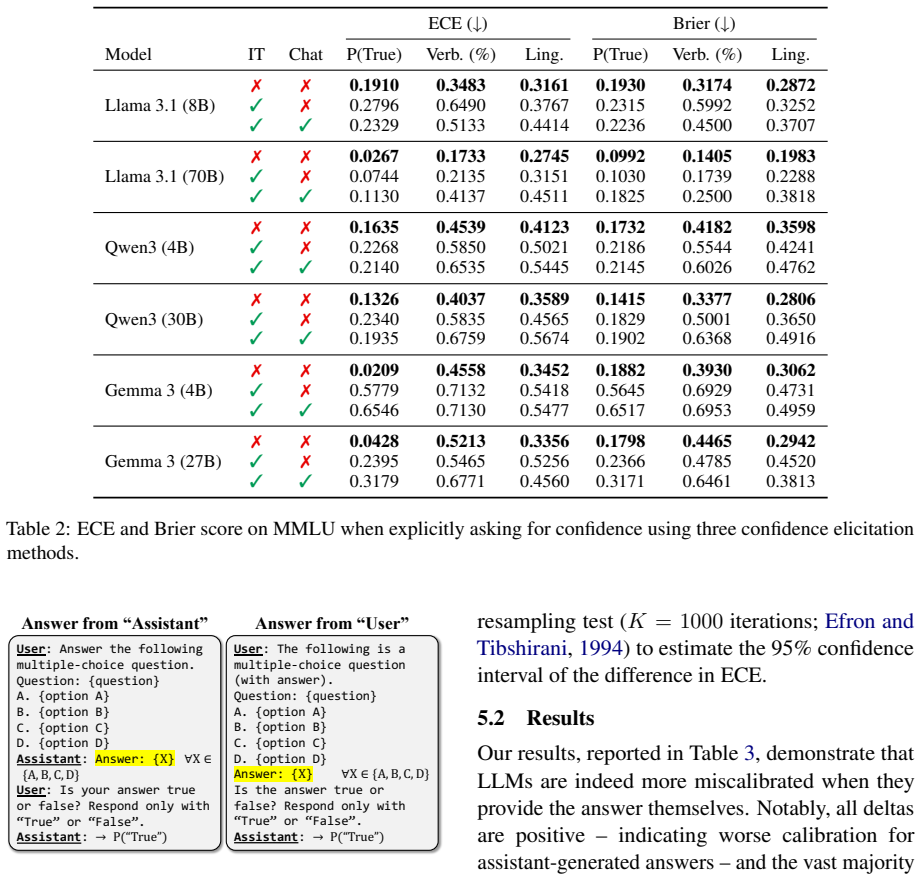
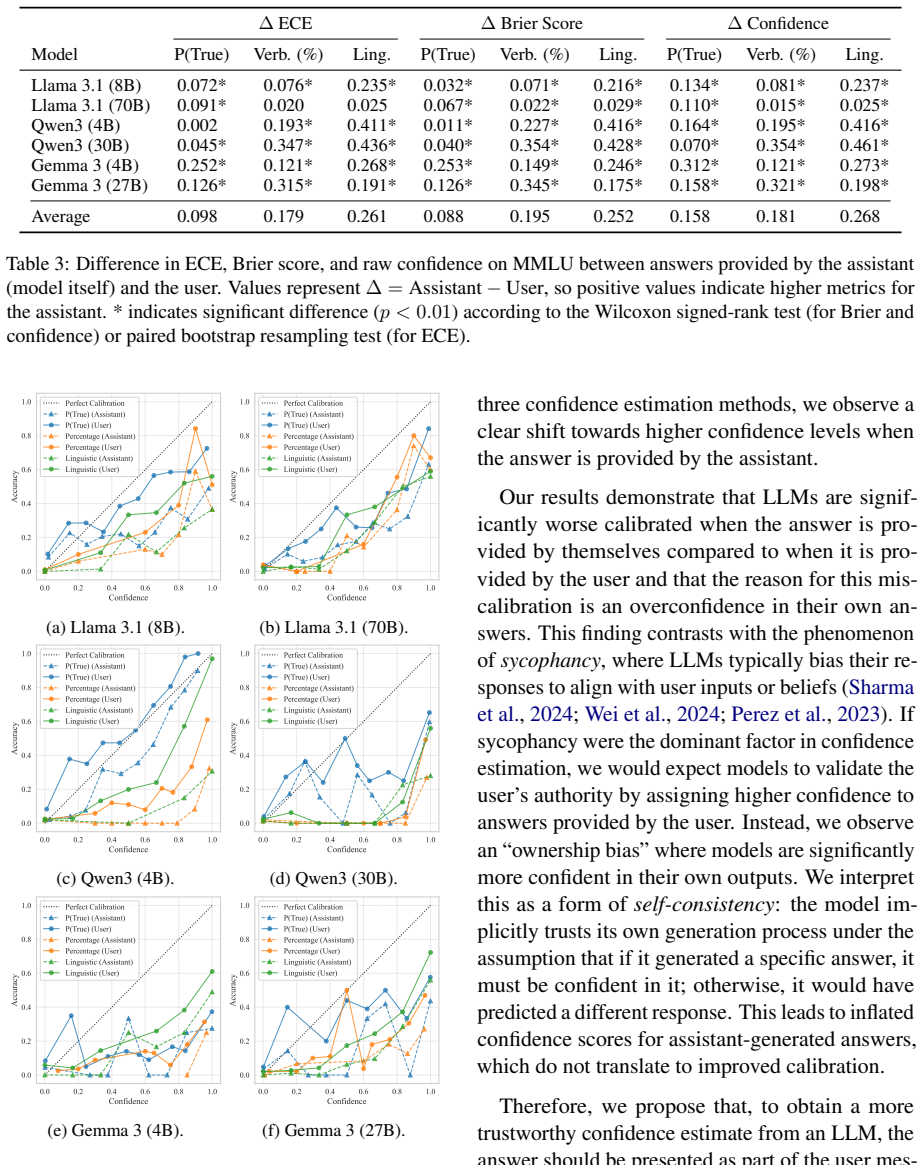
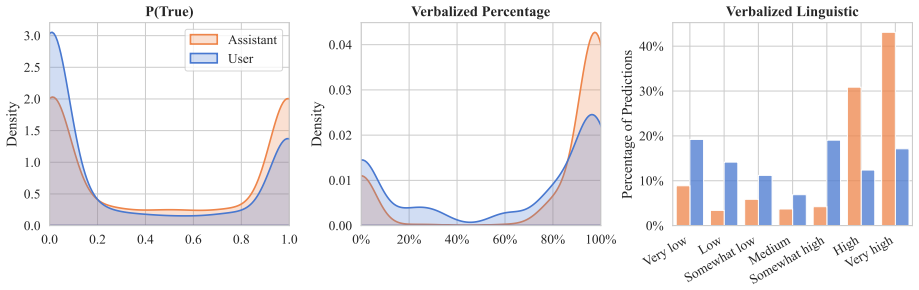
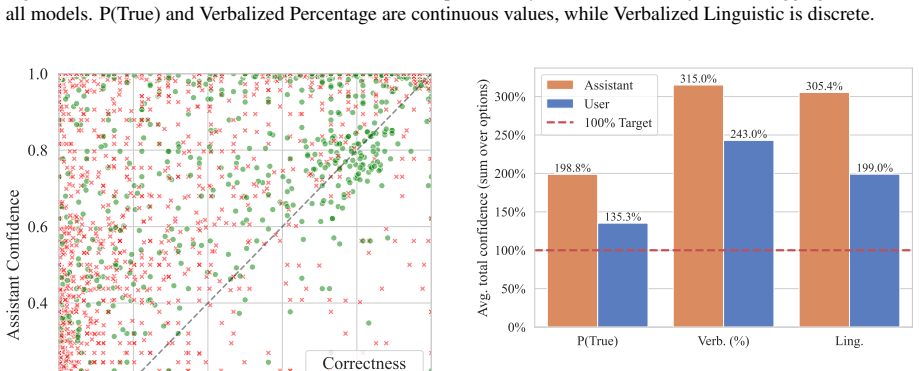
Instruction tuning harms calibration, yet the chat template aggravates the problem through an ownership bias: models assign significantly higher confidence to their own responses than to identical responses attributed to a user. This effect reaches 26% across six open-weight LLMs, three benchmarks, and three elicitation methods. Reframing the model's answer as user input during confidence elicitation reduces overconfidence and improves calibration by up to 26% without retraining.
What carries the argument
Ownership bias: the systematic elevation of reported confidence when an answer is framed as the model's own output rather than as user-provided text.
If this is right
- Models assign up to 26% higher confidence to their own responses than to identical user-provided answers.
- Reframing the model's answer as user input during confidence elicitation cuts overconfidence.
- The same reframing improves calibration by up to 26%.
- The improvement narrows the calibration gap between base and instruction-tuned models.
- The ownership bias can be addressed at inference time without retraining.
Where Pith is reading between the lines
- The same framing change may reduce over in other self-evaluation tasks such as self-correction or uncertainty quantification.
- The bias could be measured in closed-source models that expose only chat interfaces.
- If the effect traces to patterns in chat data, it may appear even when different prompts are used to elicit confidence.
Load-bearing premise
The tested models and benchmarks allow the chat-template effect to be isolated from the separate effects of instruction tuning.
What would settle it
A direct comparison in which the identical answer receives statistically indistinguishable confidence scores when framed once as the model's own response and once as user input would falsify the ownership bias.
Figures




read the original abstract
Prior work has shown that instruction-tuned large language models (LLMs) are less well calibrated than their base pre-trained counterparts. However, little is known about the frequently used chat template's effect on the calibration of conversational LLMs. In this work, we investigate the mechanisms driving this miscalibration by decoupling the effects of the post-training algorithm and the chat format. We find that, while instruction tuning fundamentally harms calibration, the chat template aggravates the issue through an "ownership bias" -- models are significantly more confident in their own answers than in identical answers provided by a user. Extensive experiments across six recent open-weight LLMs, three benchmarks, and three confidence elicitation methods show that models assign up to 26% higher confidence to their own responses. Leveraging this insight, we propose a simple inference-time strategy: framing the model's answer as user input during confidence elicitation. This approach significantly reduces overconfidence and improves calibration by up to 26% without the need for retraining, narrowing the gap between base and instruction-tuned models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that while instruction tuning harms calibration in LLMs, the chat template further aggravates miscalibration via an 'ownership bias' in which models assign up to 26% higher confidence to their own responses than to identical content framed as user input. Across six open-weight LLMs, three benchmarks, and three elicitation methods, the authors isolate this effect by decoupling post-training from chat format and propose a simple inference-time intervention (reframing the model's answer as user input) that reduces overconfidence and improves calibration by up to 26%.
Significance. If the isolation of the chat-template effect holds, the work supplies a concrete, training-free mechanism for a known calibration gap and a practical fix that narrows the base-vs-tuned difference. The empirical scale (six models, multiple benchmarks and elicitation protocols) and the falsifiable prediction that reframing reduces the bias are strengths.
major comments (3)
- [Experiments] Experiments section (and any supplementary tables): the central attribution of the 26% confidence gap to the chat template alone requires explicit verification that all four combinations (base vs. instruction-tuned × with vs. without chat template) were tested on every model. If base models cannot accept the template without additional prompting changes, the decoupling is incomplete and the ownership-bias claim is not isolated.
- [Results] Results (the 26% figures): the reported improvements must be accompanied by per-benchmark, per-elicitation-method error bars or confidence intervals and by statistical tests against the no-reframing baseline; without these, it is impossible to judge whether the reduction is robust or driven by a subset of conditions.
- [Proposed method] § on the proposed inference-time strategy: the manuscript should report whether the reframing intervention changes the actual answer content or only the elicited confidence score, because any change in answer distribution would confound the calibration improvement claim.
minor comments (1)
- [Abstract] Clarify in the abstract and introduction whether the three confidence elicitation methods are applied identically to base and tuned models or whether prompt formatting differs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental clarity, statistical reporting, and methodological transparency that we will address in revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and any supplementary tables): the central attribution of the 26% confidence gap to the chat template alone requires explicit verification that all four combinations (base vs. instruction-tuned × with vs. without chat template) were tested on every model. If base models cannot accept the template without additional prompting changes, the decoupling is incomplete and the ownership-bias claim is not isolated.
Authors: The decoupling of post-training and chat format is central to our claims, and the experimental design did evaluate the four combinations wherever the base models could process the chat template (using the identical template strings as the tuned versions, with no additional system prompts). Results for these conditions appear in the main experiments and supplementary tables, though we agree the presentation could make the four-way breakdown more explicit. In the revision we will add a dedicated table (or expanded supplementary table) that explicitly lists results for base-with-template, base-without-template, tuned-with-template, and tuned-without-template for each model and benchmark. revision: yes
-
Referee: [Results] Results (the 26% figures): the reported improvements must be accompanied by per-benchmark, per-elicitation-method error bars or confidence intervals and by statistical tests against the no-reframing baseline; without these, it is impossible to judge whether the reduction is robust or driven by a subset of conditions.
Authors: We agree that error bars and statistical tests would strengthen the presentation of the 26% figures. The current manuscript reports aggregate improvements but does not include per-benchmark/per-method confidence intervals or formal tests. In the revised version we will add standard-error bars (computed across the three benchmarks or repeated runs where applicable) to all relevant figures and tables, and we will report paired statistical tests (e.g., Wilcoxon signed-rank or t-tests) comparing the reframing condition against the no-reframing baseline for each elicitation method. revision: yes
-
Referee: [Proposed method] § on the proposed inference-time strategy: the manuscript should report whether the reframing intervention changes the actual answer content or only the elicited confidence score, because any change in answer distribution would confound the calibration improvement claim.
Authors: The reframing step occurs strictly after answer generation: the model first produces its response using the standard chat template, and only the subsequent confidence-elicitation prompt is modified to present that same answer as user input. Consequently the answer distribution itself is unchanged; only the numeric confidence score is affected. We will insert a clarifying sentence (and, if space permits, a short illustrative example) in the proposed-method section to make this separation explicit. revision: yes
Circularity Check
Empirical measurement study with no derivations or self-referential predictions
full rationale
The paper conducts direct experimental measurements of confidence scores across six LLMs, three benchmarks, and three elicitation methods, comparing responses under different template and tuning conditions. No equations, first-principles derivations, or fitted parameters are used to define or predict the target quantities (e.g., the 26% confidence gap or calibration improvement). The 'ownership bias' is reported as an observed empirical pattern, not derived from prior self-citations or ansatzes. The proposed inference-time framing strategy is a straightforward application of the measured effect rather than a circular redefinition. This is a standard non-circular empirical study; the decoupling experiments, while potentially incomplete per external critique, do not reduce to self-definition or fitted-input renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Glenn W. Brier. 1950. https://doi.org/10.1175/1520-0493(1950)078<0001:vofeit>2.0.co;2 Verification of forecasts expressed in terms of probability . Monthly Weather Review, 78(1):1--3
-
[2]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
Pith/arXiv arXiv 2021
-
[3]
Bradley Efron and Robert J Tibshirani. 1994. https://doi.org/10.1201/9780429246593 An introduction to the bootstrap . Chapman and Hall/CRC
-
[4]
Gemma Team , Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.1978...
Pith/arXiv arXiv 2025
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The Llama 3...
Pith/arXiv arXiv 2024
-
[6]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. 2017. https://proceedings.mlr.press/v70/guo17a.html On calibration of modern neural networks . In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1321--1330. PMLR
2017
-
[7]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. https://openreview.net/forum?id=d7KBjmI3GmQ Measuring massive multitask language understanding . In International Conference on Learning Representations
2021
-
[8]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, and 17 others. 2022. https://arxiv.org/abs/2207.05221 Language models (mostly...
Pith/arXiv arXiv 2022
-
[9]
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. 2025. https://arxiv.org/abs/2509.04664 Why language models hallucinate . Preprint, arXiv:2509.04664
Pith/arXiv arXiv 2025
-
[10]
Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. 2025. https://openreview.net/forum?id=l0tg0jzsdL Taming overconfidence in LLM s: Reward calibration in RLHF . In The Thirteenth International Conference on Learning Representations
2025
-
[11]
Rensis Likert. 1932. A technique for the measurement of attitudes. Archives of Psychology, 22(140):55
1932
-
[12]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022 a . https://openreview.net/forum?id=8s8K2UZGTZ Teaching models to express their uncertainty in words . Transactions on Machine Learning Research
2022
-
[13]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022 b . https://doi.org/10.18653/v1/2022.acl-long.229 T ruthful QA : Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
-
[14]
Beier Luo, Shuoyuan Wang, Sharon Li, and Hongxin Wei. 2025. https://openreview.net/forum?id=I4PJYZvfW5 Your pre-trained LLM is secretly an unsupervised confidence calibrator . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[15]
Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau
Sabrina J. Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau. 2022. https://doi.org/10.1162/tacl_a_00494 Reducing conversational agents' overconfidence through linguistic calibration . Transactions of the Association for Computational Linguistics, 10:857--872
-
[16]
Preetum Nakkiran, Arwen Bradley, Adam Goliński, Eugene Ndiaye, Michael Kirchhof, and Sinead Williamson. 2025. https://arxiv.org/abs/2511.04869 Trained on tokens, calibrated on concepts: The emergence of semantic calibration in LLM s . Preprint, arXiv:2511.04869
arXiv 2025
-
[17]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, and 262 others. 2024. https://arxiv.org/abs/2303.08774 GPT -4 technical ...
Pith/arXiv arXiv 2024
-
[18]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/b...
2022
-
[19]
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. 2015. https://doi.org/10.1609/aaai.v29i1.9602 Obtaining well calibrated probabilities using bayesian binning . Proceedings of the AAAI Conference on Artificial Intelligence, 29(1)
-
[20]
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, Andy Jones, Anna Chen, Benjamin Mann, Brian Israel, Bryan Seethor, Cameron McKinnon, Christopher Olah, Da Yan, Daniela Amodei, and 44 others. 2023. https://doi.org/10.18653/v1/2023.findings-acl.847 Discoverin...
-
[21]
Mario Sanz-Guerrero, Minh Duc Bui, and Katharina von der Wense. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.988 Mind the gap: A closer look at tokenization for multiple-choice question answering with LLM s . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19573--19583, Suzhou, China. Association for C...
-
[22]
Mario Sanz-Guerrero and Katharina von der Wense. 2025. https://doi.org/10.18653/v1/2025.ijcnlp-long.78 Mitigating label length bias in large language models . In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 14...
-
[23]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
Pith/arXiv arXiv 2017
-
[24]
Sagi Shaier, Mario Sanz-Guerrero, and Katharina von der Wense. 2025. https://arxiv.org/abs/2412.07923 Asking again and again: Exploring llm robustness to repeated questions . Preprint, arXiv:2412.07923
arXiv 2025
-
[25]
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, Shauna M Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. 2024. https://openreview.net/forum?id=tvhaxkMKAn Towards understanding sycoph...
2024
-
[26]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.330 Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback . In Proceedings of the 2023 Conference on Em...
-
[27]
Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Oh. 2024. https://doi.org/10.18653/v1/2024.acl-long.824 Calibrating large language models using their generations only . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15440--15459, Bangkok, Thailand. Association for Co...
-
[28]
Xinpeng Wang, Bolei Ma, Chengzhi Hu, Leon Weber-Genzel, Paul R \"o ttger, Frauke Kreuter, Dirk Hovy, and Barbara Plank. 2024. https://doi.org/10.18653/v1/2024.findings-acl.441 `` My answer is C '': First-token probabilities do not match text answers in instruction-tuned language models . In Findings of the Association for Computational Linguistics: ACL 20...
-
[29]
Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V. Le. 2024. https://arxiv.org/abs/2308.03958 Simple synthetic data reduces sycophancy in large language models . Preprint, arXiv:2308.03958
Pith/arXiv arXiv 2024
-
[30]
Frank Wilcoxon. 1945. http://www.jstor.org/stable/3001968 Individual comparisons by ranking methods . Biometrics Bulletin, 1(6):80--83
arXiv 1945
-
[31]
Jiancong Xiao, Bojian Hou, Zhanliang Wang, Ruochen Jin, Qi Long, Weijie J Su, and Li Shen. 2025. https://openreview.net/forum?id=51tMpvPNSm Restoring calibration for aligned large language models: A calibration-aware fine-tuning approach . In Forty-second International Conference on Machine Learning
2025
-
[32]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2024. https://openreview.net/forum?id=gjeQKFxFpZ Can LLM s express their uncertainty? An empirical evaluation of confidence elicitation in LLM s . In The Twelfth International Conference on Learning Representations
2024
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[34]
Chiwei Zhu, Benfeng Xu, Quan Wang, Yongdong Zhang, and Zhendong Mao. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.654 On the calibration of large language models and alignment . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9778--9795, Singapore. Association for Computational Linguistics
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.