PerchRL: Vision-Based Agile Perching on Inclined Platforms under Rapid and Irregular Motion
Pith reviewed 2026-06-28 09:24 UTC · model grok-4.3
The pith
A two-stage reinforcement learning method enables quadrotors to perch on inclined platforms moving rapidly and irregularly using only vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
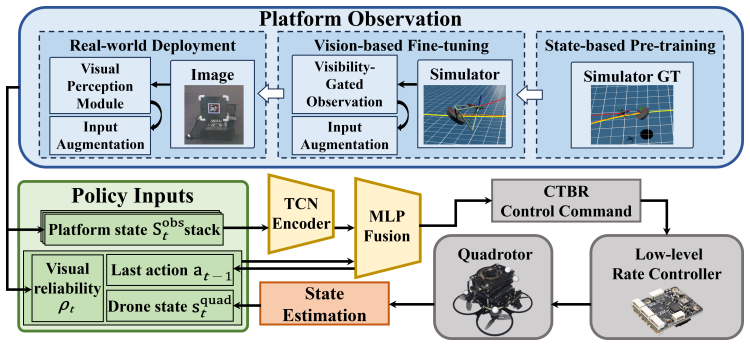
PerchRL shows that a reinforcement learning policy trained in two stages—state-based pre-training followed by vision-based fine-tuning—can achieve stable agile perching on inclined platforms under rapid irregular motion when the training distribution includes randomized trajectories, temporal history augmentation, visibility-aware image augmentation, and active-perception rewards.
What carries the argument
Two-stage RL pipeline that pre-trains on full state then fine-tunes on vision, with randomized platform trajectories, temporal augmentation of observations, visibility-aware state augmentation, and active perception rewards.
If this is right
- The learned policies run in real time on physical quadrotors.
- The same policy transfers across distinct quadrotor platforms without retuning.
- Successful perching occurs under both simulated and real rapid irregular platform motion.
- The hybrid visibility and active-perception components maintain performance during intermittent visual loss.
Where Pith is reading between the lines
- The same training recipe could be applied to perching on other surface orientations if the randomization range is expanded accordingly.
- Temporal augmentation may allow the policy to anticipate short-term platform motion even without an explicit predictor.
- Cross-platform success suggests the policy has captured platform-agnostic dynamics rather than hardware-specific parameters.
Load-bearing premise
Randomized platform trajectories during training plus temporal augmentation will produce policies that generalize to the distribution of real-world irregular motions without requiring platform-specific tuning.
What would settle it
Real-world trials in which the platform follows an irregular trajectory outside the randomized training distribution produce repeated perching failures or loss of stability.
Figures


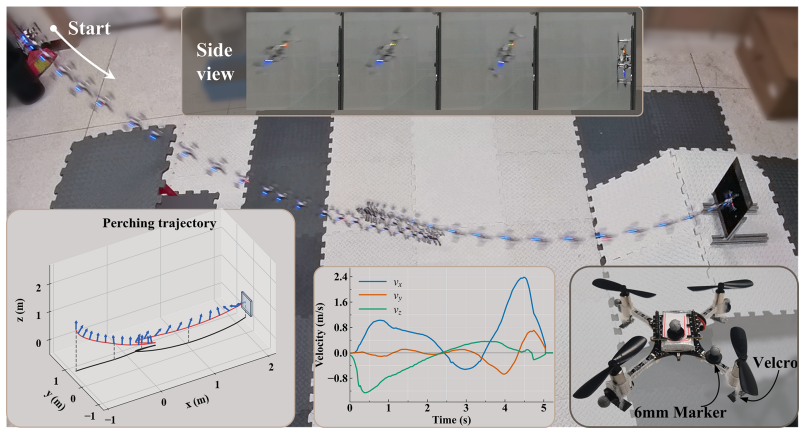


read the original abstract
Autonomous vision-based perching of quadrotors on moving inclined platforms is critical for air-ground collaboration but remains challenging due to the limited field of view (FOV). In this paper, we propose PerchRL, a reinforcement learning (RL) framework for vision-based agile perching on inclined platforms under rapid and irregular motion. Specifically, we employ a two-stage learning strategy consisting of state-based pre-training followed by vision-based fine-tuning. To improve generalization across diverse platform motions, we employ randomized platform trajectories to prevent overfitting and temporal augmentation methods to capture latent motion patterns from historical observations. During vision-based fine-tuning, a hybrid learning framework consisting of visibility-aware state augmentation and active perception rewards is presented to improve robustness under intermittent visual loss. Extensive simulation and real-world experiments demonstrate the feasibility, stability, and real-time performance of PerchRL, while successful deployment across distinct quadrotor platforms further validates its adaptability. The source code will be released to benefit the community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PerchRL, a two-stage RL framework for vision-based agile perching of quadrotors on inclined platforms undergoing rapid and irregular motion. It consists of state-based pre-training on randomized trajectories with temporal augmentation to improve generalization, followed by vision-based fine-tuning using a hybrid framework with visibility-aware state augmentation and active perception rewards to handle intermittent visual loss. The central claim is that extensive simulation and real-world experiments demonstrate feasibility, stability, real-time performance, and adaptability across distinct quadrotor platforms without platform-specific tuning.
Significance. If the experimental results hold with proper quantitative support, the work would contribute to agile aerial robotics by offering a generalizable approach to vision-based perching under challenging motion conditions, with potential applications in air-ground collaboration. The planned release of source code would support reproducibility in the field.
major comments (3)
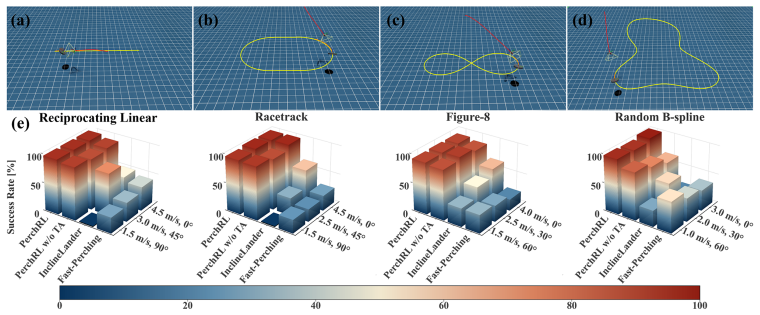
- [Abstract, §4] Abstract and §4 (Experiments): The central claim that 'extensive simulation and real-world experiments demonstrate the feasibility, stability, and real-time performance' is unsupported, as the manuscript provides no quantitative metrics, success rates, baseline comparisons, failure rates, or error bars to substantiate performance or generalization.
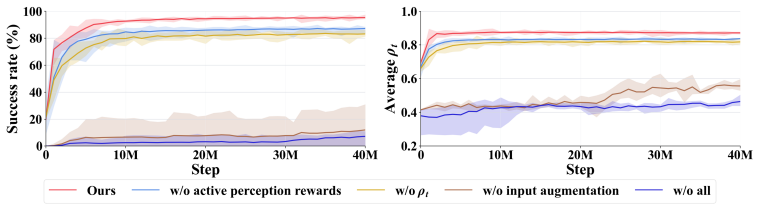
- [§3.2, §3.3] §3.2 (two-stage pipeline) and §3.3 (hybrid vision fine-tuning): The adaptability claim without platform-specific tuning rests on randomized trajectories plus temporal augmentation producing policies robust to real irregular motions, but no distributional validation (e.g., power spectra, acceleration histograms, or KL divergence between training and test motions) or ablations isolating their effect on cross-platform success is reported.
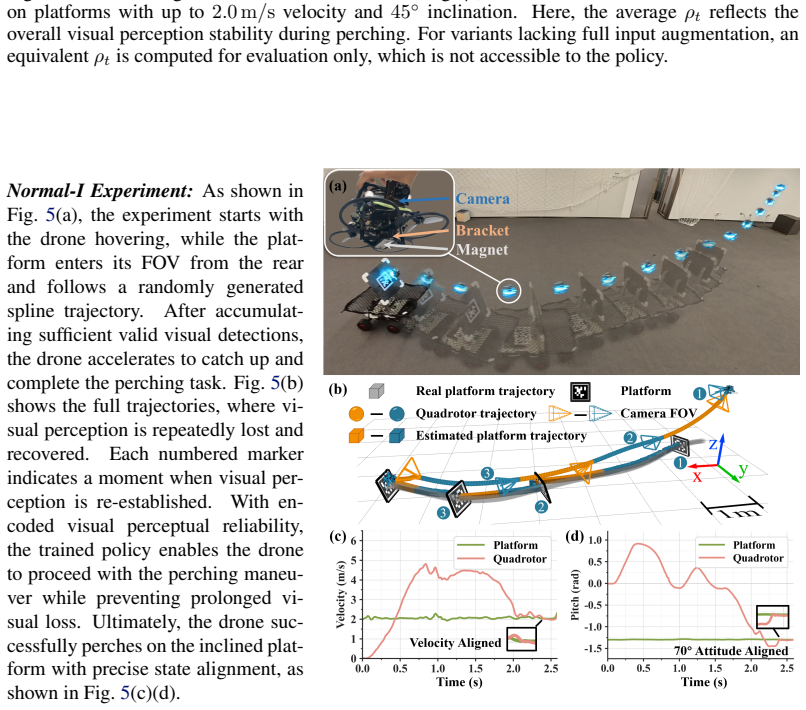
- [§4] §4 (real-world deployment): The assertion of successful deployment across distinct quadrotor platforms validating adaptability lacks any reported quantitative cross-platform metrics or controls for test diversity, leaving open whether results reflect the claimed generalization or limited test conditions.
minor comments (2)
- [§3] Notation for the temporal augmentation and active perception reward terms is introduced without explicit equations or parameter definitions, reducing clarity for readers attempting to reproduce the method.
- [Abstract] The abstract states source code will be released, but no link or repository is provided in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened with additional quantitative support. We address each major comment below and will revise the manuscript to incorporate the suggested analyses and metrics.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central claim that 'extensive simulation and real-world experiments demonstrate the feasibility, stability, and real-time performance' is unsupported, as the manuscript provides no quantitative metrics, success rates, baseline comparisons, failure rates, or error bars to substantiate performance or generalization.
Authors: We agree that the abstract and experiments section would benefit from explicit quantitative metrics. In the revised manuscript, we will add tables reporting success rates, failure rates, baseline comparisons, and error bars from repeated trials to substantiate the claims of feasibility, stability, and real-time performance. revision: yes
-
Referee: [§3.2, §3.3] §3.2 (two-stage pipeline) and §3.3 (hybrid vision fine-tuning): The adaptability claim without platform-specific tuning rests on randomized trajectories plus temporal augmentation producing policies robust to real irregular motions, but no distributional validation (e.g., power spectra, acceleration histograms, or KL divergence between training and test motions) or ablations isolating their effect on cross-platform success is reported.
Authors: The referee is correct that distributional validation and targeted ablations are not currently reported. We will include comparisons of motion distributions (power spectra, acceleration histograms, KL divergence) between training and test sets, as well as ablation studies isolating the impact of randomized trajectories and temporal augmentation on cross-platform generalization. revision: yes
-
Referee: [§4] §4 (real-world deployment): The assertion of successful deployment across distinct quadrotor platforms validating adaptability lacks any reported quantitative cross-platform metrics or controls for test diversity, leaving open whether results reflect the claimed generalization or limited test conditions.
Authors: We acknowledge the need for quantitative cross-platform metrics. The revision will report specific success rates, performance metrics, and controls for test diversity across the distinct quadrotor platforms to better support the adaptability claim. revision: yes
Circularity Check
No circularity in claimed results or derivation chain
full rationale
The paper describes an empirical RL pipeline (two-stage training with randomized trajectories and temporal augmentation, followed by hybrid vision fine-tuning) and supports its claims exclusively via simulation and real-world experiments on multiple platforms. No equations, fitted parameters, or self-citations are presented that would make reported success rates or generalization reduce to the training choices by construction. The central claims rest on external experimental outcomes rather than any self-definitional, fitted-input, or uniqueness-imported mechanism.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. N. Das, R. Sewani, J. Wang, and M. K. Tiwari. Synchronized truck and drone routing in package delivery logistics.IEEE Transactions on Intelligent Transportation Systems, 22(9): 5772–5782, 2020
2020
-
[2]
G. Wu, N. Mao, Q. Luo, B. Xu, J. Shi, and P. N. Suganthan. Collaborative truck-drone routing for contactless parcel delivery during the epidemic.IEEE Transactions on Intelligent Trans- portation Systems, 23(12):25077–25091, 2022
2022
-
[3]
Y . Liu, Z. Liu, J. Shi, G. Wu, and W. Pedrycz. Two-echelon routing problem for parcel de- livery by cooperated truck and drone.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 51(12):7450–7465, 2020
2020
-
[4]
G. Wu, W. Pedrycz, H. Li, M. Ma, and J. Liu. Coordinated planning of heterogeneous earth observation resources.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 46(1): 109–125, 2015
2015
-
[5]
Tokekar, J
P. Tokekar, J. Vander Hook, D. Mulla, and V . Isler. Sensor planning for a symbiotic uav and ugv system for precision agriculture.IEEE transactions on robotics, 32(6):1498–1511, 2016
2016
-
[6]
Krogius, A
M. Krogius, A. Haggenmiller, and E. Olson. Flexible layouts for fiducial tags. In2019 ieee/rsj international conference on intelligent robots and systems (iros), pages 1898–1903. IEEE, 2019
1903
-
[7]
B. Wen, C. Mitash, B. Ren, and K. E. Bekris. se (3)-tracknet: Data-driven 6d pose tracking by calibrating image residuals in synthetic domains. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10367–10373. IEEE, 2020
2020
-
[8]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17868–17879, 2024
2024
-
[9]
Liang, Y
T. Liang, Y . Zeng, J. Xie, and B. Zhou. Dynamicpose: Real-time and robust 6d object pose tracking for fast-moving cameras and objects. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2424–2431. IEEE, 2025
2025
-
[10]
Mellinger, N
D. Mellinger, N. Michael, and V . Kumar. Trajectory generation and control for precise ag- gressive maneuvers with quadrotors.The International Journal of Robotics Research, 31(5): 664–674, 2012
2012
-
[11]
Thomas, M
J. Thomas, M. Pope, G. Loianno, E. W. Hawkes, M. A. Estrada, H. Jiang, M. R. Cutkosky, and V . Kumar. Aggressive flight with quadrotors for perching on inclined surfaces.Journal of Mechanisms and Robotics, 8(5):051007, 2016
2016
-
[12]
J. Mao, G. Li, S. Nogar, C. Kroninger, and G. Loianno. Aggressive visual perching with quadrotors on inclined surfaces. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5242–5248. IEEE, 2021
2021
-
[13]
J. Ji, T. Yang, C. Xu, and F. Gao. Real-time trajectory planning for aerial perching. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10516– 10522. IEEE, 2022
2022
-
[14]
Zhang, Z
Y . Zhang, Z. Wu, and T. Wei. Precise landing on moving platform for quadrotor uav via extended disturbance observer.IEEE Transactions on Intelligent Vehicles, 2024
2024
-
[15]
S. Liu, W. Hu, Z. Wang, W. Dong, and X. Sheng. Quadrotors’ perching on moving inclined surfaces using uncertainty tolerant planner and thrust regulation.Robotics and Autonomous Systems, 191:105011, 2025. 10
2025
-
[16]
J. Mao, S. Nogar, C. M. Kroninger, and G. Loianno. Robust active visual perching with quadrotors on inclined surfaces.IEEE Transactions on Robotics, 39(3):1836–1852, 2023
2023
-
[17]
Y . Gao, J. Ji, Q. Wang, R. Jin, Y . Lin, Z. Shang, Y . Cao, S. Shen, C. Xu, and F. Gao. Adaptive tracking and perching for quadrotor in dynamic scenarios.IEEE Transactions on Robotics, 40: 499–519, 2023
2023
-
[18]
Polvara, M
R. Polvara, M. Patacchiola, S. Sharma, J. Wan, A. Manning, R. Sutton, and A. Cangelosi. Toward end-to-end control for uav autonomous landing via deep reinforcement learning. In 2018 International conference on unmanned aircraft systems (ICUAS), pages 115–123. IEEE, 2018
2018
-
[19]
J. E. Kooi and R. Babu ˇska. Inclined quadrotor landing using deep reinforcement learning. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2361–2368. IEEE, 2021
2021
-
[20]
B. van der Heijden, J. Luijkx, L. Ferranti, J. Kober, and R. Babuska. Eagerx: Graph-based framework for sim2real robot learning.arXiv preprint arXiv:2407.04328, 2024
-
[21]
Rodriguez-Ramos, C
A. Rodriguez-Ramos, C. Sampedro, H. Bavle, P. De La Puente, and P. Campoy. A deep reinforcement learning strategy for uav autonomous landing on a moving platform.Journal of Intelligent & Robotic Systems, 93(1):351–366, 2019
2019
-
[22]
Goldschmid and A
P. Goldschmid and A. Ahmad. Reinforcement learning based autonomous multi-rotor landing on moving platforms.Autonomous Robots, 48(4):13, 2024
2024
-
[23]
C. Wang, J. Wang, C. Wei, Y . Zhu, D. Yin, and J. Li. Vision-based deep reinforcement learning of uav-ugv collaborative landing policy using automatic curriculum.Drones, 7(11):676, 2023
2023
-
[24]
Ladosz, M
P. Ladosz, M. Mammadov, H. Shin, W. Shin, and H. Oh. Autonomous landing on a mov- ing platform using vision-based deep reinforcement learning.IEEE Robotics and Automation Letters, 9(5):4575–4582, 2024
2024
-
[25]
W. Shin, M. Kim, T. Park, G. Bae, S. Kim, and H. Oh. Vision-based autonomous drone landing on moving platforms with uncertain motion via deep reinforcement learning.IEEE Robotics and Automation Letters, 2026
2026
-
[26]
Kaufmann, L
E. Kaufmann, L. Bauersfeld, and D. Scaramuzza. A benchmark comparison of learned control policies for agile quadrotor flight. In2022 International Conference on Robotics and Automa- tion (ICRA), pages 10504–10510. IEEE, 2022
2022
-
[27]
L. P. Kaelbling, M. L. Littman, and A. R. Cassandra. Planning and acting in partially observ- able stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
1998
- [28]
-
[29]
T. Wu, Y . Chen, T. Chen, G. Zhao, and F. Gao. Whole-body control through narrow gaps from pixels to action. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11317–11324. IEEE, 2025
2025
-
[30]
Huang, J
Y . Huang, J. Du, Z. Yang, Z. Zhou, L. Zhang, and H. Chen. A survey on trajectory-prediction methods for autonomous driving.IEEE transactions on intelligent vehicles, 7(3):652–674, 2022
2022
-
[31]
G. Chang. Robust kalman filtering based on mahalanobis distance as outlier judging criterion. Journal of Geodesy, 88(4):391–401, 2014
2014
-
[32]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
B. Xu, F. Gao, C. Yu, R. Zhang, Y . Wu, and Y . Wang. Omnidrones: An efficient and flexible platform for reinforcement learning in drone control.IEEE Robotics and Automation Letters, 9(3):2838–2844, 2024
2024
-
[34]
J. Chen, C. Yu, Y . Xie, F. Gao, Y . Chen, S. Yu, W. Tang, S. Ji, M. Mu, Y . Wu, et al. What matters in learning a zero-shot sim-to-real rl policy for quadrotor control? a comprehensive study.IEEE Robotics and Automation Letters, 2025
2025
-
[35]
J. A. Preiss, W. Honig, G. S. Sukhatme, and N. Ayanian. Crazyswarm: A large nano- quadcopter swarm. In2017 IEEE International Conference on Robotics and Automation (ICRA), pages 3299–3304. IEEE, 2017. 12 A Supplementary Materials A.1 System Dynamics for Policy Training Quadrotor Dynamics:The quadrotor is modeled with standard dynamics as follows: ˙p=v, m ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.