What Makes Interaction Trajectories Effective for Training Terminal Agents?
Pith reviewed 2026-06-28 10:15 UTC · model grok-4.3
The pith
Trajectories from a lower-scoring agent produce stronger generalization in fine-tuned terminal agents than those from a higher-scoring agent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
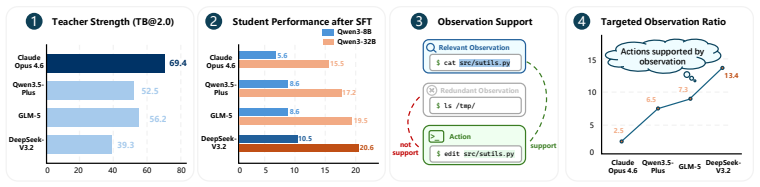
Standalone performance does not dictate teaching efficacy. Students fine-tuned on trajectories from DeepSeek-V3.2, a lower-scoring agent, exhibit significantly stronger generalization than those trained on trajectories from Claude Opus 4.6. This pedagogical paradox arises because trajectories that explicitly expose inspect-act-verify behaviors through harness-visible interactions allow students to internalize robust problem-solving routines rather than fragile action sequences.
What carries the argument
Environment-Grounded Supervision (EGS): trajectories that explicitly expose inspect-act-verify behaviors through harness-visible interactions.
If this is right
- Agent post-training should prioritize trajectories that make inspect-act-verify loops visible over trajectories from the strongest possible teacher agent.
- Harness engineering that systematically exposes environment interactions can reduce the data volume needed for high performance.
- Reproducible gains in terminal-agent capability become possible by focusing on interaction structure rather than raw outcome matching.
- Scaling laws for agent training shift from total data volume toward the density of environment-grounded signals per trajectory.
Where Pith is reading between the lines
- The same EGS principle could be tested in non-terminal agent domains such as web navigation or tool-use chains where harness visibility can be engineered.
- Future work might quantify EGS density as a measurable property of any trajectory dataset and use it to rank candidate teachers without running full student fine-tunes.
- If harness design is the primary lever, then open-source harnesses could become the main shared resource for agent research instead of proprietary model weights.
Load-bearing premise
Differences in teaching efficacy are caused by the presence of Environment-Grounded Supervision rather than uncontrolled factors such as task difficulty distribution, harness design details, or student model capacity.
What would settle it
An experiment that edits the same set of trajectories to either hide or preserve the explicit verify steps and then measures whether the generalization gap between the two teacher agents disappears.
Figures
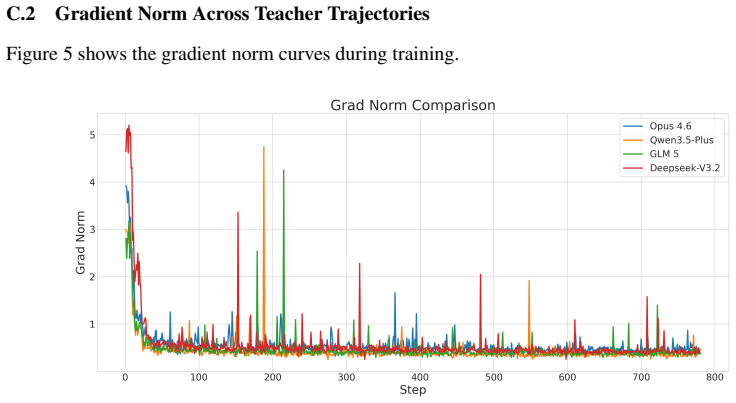
read the original abstract
Stronger code agents are commonly assumed to be superior teachers for post-training, yet this assumption remains poorly disentangled from task difficulty, harness design, and student capacity. We investigate this pedagogical link using Terminal-Lego, a scalable pipeline that transforms multi-domain real-world issues into environment-verified agentic tasks. Surprisingly, standalone performance does not dictate teaching efficacy: while Claude Opus 4.6 achieves higher scores on Terminal-Bench 2.0, students fine-tuned on trajectories from DeepSeek-V3.2, a lower-scoring agent, exhibit significantly stronger generalization. We attribute this "pedagogical paradox" to Environment-Grounded Supervision (EGS): trajectories that explicitly expose inspect-act-verify behaviors through harness-visible interactions allow students to internalize robust problem-solving routines rather than fragile action sequences. Scaling analysis reveals exceptional data efficiency: with only 15.3k Terminal-Lego trajectories, for example, Qwen3-32B achieves a 24.3% score on Terminal-Bench 2.0, rivaling previous SOTA performance established with over 30x the data volume. Our results suggest that the frontier of agent post-training lies beyond mere outcome-matching, shifting the focus toward "Harness Engineering", where the systematic design of environment-grounded interaction structures serves as the primary catalyst for reproducible and generalizable agentic intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that stronger standalone performance does not make an agent a better teacher for post-training terminal agents. Using the Terminal-Lego pipeline to generate environment-verified tasks, it shows that fine-tuning on trajectories from DeepSeek-V3.2 (lower Terminal-Bench 2.0 score) produces students with significantly stronger generalization than those trained on Claude Opus 4.6 trajectories. The authors attribute this to Environment-Grounded Supervision (EGS) in the form of harness-visible inspect-act-verify loops and report that 15.3k such trajectories suffice for Qwen3-32B to reach 24.3% on Terminal-Bench 2.0, rivaling prior SOTA with >30x more data.
Significance. If the causal role of EGS can be isolated, the result would usefully redirect agent post-training research from pure outcome matching toward systematic harness design that elicits grounded interaction patterns, with the reported data-efficiency numbers providing a concrete empirical anchor for that shift.
major comments (2)
- [Abstract] Abstract: the central claim that EGS (rather than uncontrolled differences in task difficulty distribution, harness design, error patterns, or trajectory statistics) explains the generalization gap is not supported by any described controls or ablations that hold those factors fixed while varying only the presence of harness-visible inspect-act-verify loops.
- [Experiments] The comparison between DeepSeek-V3.2 and Claude Opus 4.6 trajectories simultaneously varies capability, interaction style, and error distribution; without an experiment that decouples EGS from these covariates (e.g., via synthetic trajectory editing or matched-difficulty subsets), the pedagogical-paradox attribution remains correlational.
minor comments (1)
- The scaling result (15.3k trajectories, 24.3% score) is presented without the exact baseline data volume, model sizes, or statistical error bars that would allow direct comparison to the cited prior SOTA.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the need to better isolate the causal contribution of Environment-Grounded Supervision. We agree that the current evidence for attributing the generalization gap specifically to harness-visible inspect-act-verify loops remains correlational, as multiple factors differ between the DeepSeek-V3.2 and Claude Opus 4.6 trajectory sets. In the revised manuscript we will explicitly acknowledge this limitation, temper the strength of the EGS claim in the abstract and discussion, and add analyses of matched-difficulty subsets where possible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that EGS (rather than uncontrolled differences in task difficulty distribution, harness design, error patterns, or trajectory statistics) explains the generalization gap is not supported by any described controls or ablations that hold those factors fixed while varying only the presence of harness-visible inspect-act-verify loops.
Authors: We accept this assessment. The manuscript currently infers the role of EGS from observed trajectory differences and downstream performance but does not present ablations that isolate harness-visible loops while holding task difficulty, error patterns, and other statistics fixed. We will revise the abstract to present the EGS interpretation as a hypothesis supported by correlational evidence rather than a demonstrated causal mechanism, and we will add a limitations paragraph outlining the required controls. revision: yes
-
Referee: [Experiments] The comparison between DeepSeek-V3.2 and Claude Opus 4.6 trajectories simultaneously varies capability, interaction style, and error distribution; without an experiment that decouples EGS from these covariates (e.g., via synthetic trajectory editing or matched-difficulty subsets), the pedagogical-paradox attribution remains correlational.
Authors: The referee is correct that the agent comparison confounds multiple variables. Our trajectory analysis shows systematic differences in inspect-act-verify patterns, but we lack experiments that hold other covariates constant. We will incorporate a matched-difficulty subset analysis in the revision to partially address this. Full synthetic trajectory editing to isolate EGS is methodologically complex and may introduce new artifacts; we therefore treat it as future work rather than a revision deliverable. revision: partial
Circularity Check
No circularity: empirical comparison with observational attribution
full rationale
The paper is an empirical study that generates trajectories from two teacher agents, fine-tunes student models on them, and reports generalization differences on Terminal-Bench 2.0. It then attributes the observed advantage to Environment-Grounded Supervision (EGS) on the basis of qualitative differences in the trajectories. No equations, fitted parameters renamed as predictions, ansatzes, or uniqueness theorems appear in the provided text. The central claim is an observational inference rather than a derivation that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for any mathematical step. The noted confounders (task difficulty, harness details, student capacity) affect causal interpretation but do not constitute circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Environment-Grounded Supervision (EGS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mini swe agent
Mini SWE Agent. Mini swe agent. https://github.com/SWE-agent/Mini-SWE-Agent , 2025
2025
-
[2]
GLM-5: from Vibe Coding to Agentic Engineering
Zhipu AI. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Claude code by anthropic
Anthropic. Claude code by anthropic. https://www.anthropic.com/product/ claude-code, 2026
2026
-
[4]
Introducing claude opus 4.6
Anthropic. Introducing claude opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026
2026
-
[5]
Swe- rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents, 2025
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. Swe- rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents, 2025
2025
-
[6]
Gemini cli.https://geminicli.com/, 2025
Deepmind. Gemini cli.https://geminicli.com/, 2025
2025
-
[7]
Hendryx, Zifan Wang, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler
Xiang Deng, Jeff Da, Edwin Pan, Yan He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean M. Hendryx, Zifan Wang, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks? 2025
2025
-
[8]
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. R2e- gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents.arXiv preprint arXiv:2504.07164, 2025
-
[9]
Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[10]
Measuring ai ability to complete long tasks.arXiv preprint arXiv:2503.14499, 2025
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney V on Arx, et al. Measuring ai ability to complete long tasks.arXiv preprint arXiv:2503.14499, 352, 2025
-
[11]
Yusong Lin, Haiyang Wang, Shuzhe Wu, Lue Fan, Feiyang Pan, Sanyuan Zhao, and Dandan Tu. Cli-gym: Scalable cli task generation via agentic environment inversion.arXiv preprint arXiv:2602.10999, 2026
-
[12]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Introducing gpt 5
OpenAI. Introducing gpt 5. https://openai.com/zh-Hans-CN/index/ introducing-gpt-5/, 2025
2025
-
[15]
Introducing gpt oss
OpenAI. Introducing gpt oss. https://openai.com/zh-Hans-CN/index/ introducing-gpt-oss/, 2025
2025
-
[16]
Introducing codex
OpenAI. Introducing codex. https://openai.com/zh-Hans-CN/index/ introducing-codex/, 2026
2026
-
[17]
Introducing gpt-5.5
OpenAI. Introducing gpt-5.5. https://openai.com/zh-Hans-CN/index/ introducing-gpt-5-5/, 2026
2026
-
[18]
On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193, 2026
Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping. On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193, 2026
-
[19]
Mini swe agent plus
Mini SWE Agent Plus. Mini swe agent plus. https://github.com/Kwai-Klear/ mini-swe-agent-plus, 2025
2025
-
[20]
Qwen3-coder: Agentic coding in the world
Qwen. Qwen3-coder: Agentic coding in the world. https://qwenlm.github.io/blog/ qwen3-coder/, 2025. 11
2025
-
[21]
Qwen3.5: Towards native multimodal agents
Qwen. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id=qwen3.5, 2026
2026
-
[22]
Chaofan Tao, Jierun Chen, Yuxin Jiang, Kaiqi Kou, Shaowei Wang, Ruoyu Wang, Xiaohui Li, Sidi Yang, Yiming Du, Jianbo Dai, et al. Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving.arXiv preprint arXiv:2601.01426, 2026
-
[23]
Junhao Wang, Daoguang Zan, Shulin Xin, Siyao Liu, Yurong Wu, and Kai Shen. Swe- mirror: Scaling issue-resolving datasets by mirroring issues across repositories.arXiv preprint arXiv:2509.08724, 2025
-
[24]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Siwei Wu, Yizhi Li, Yuyang Song, Wei Zhang, Yang Wang, Riza Batista-Navarro, Xian Yang, Mingjie Tang, Bryan Dai, Jian Yang, et al. Large-scale terminal agentic trajectory generation from dockerized environments.arXiv preprint arXiv:2602.01244, 2026
-
[26]
Grok 4.https://x.ai/news/grok-4, 2025
XAI. Grok 4.https://x.ai/news/grok-4, 2025
2025
-
[27]
Chengxing Xie, Bowen Li, Chang Gao, He Du, Wai Lam, Difan Zou, and Kai Chen. Swe-fixer: Training open-source llms for effective and efficient github issue resolution.arXiv preprint arXiv:2501.05040, 2025
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[30]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, et al. Termigen: High-fidelity environment and robust trajectory synthesis for terminal agents.arXiv preprint arXiv:2602.07274, 2026. 12 A Terminal-Lego Pipeline: Complete Technical Details This appendix provides complete, reproducible ...
-
[32]
2.Cascaded Task Generation– LLM generates 7 files per task in dependency order
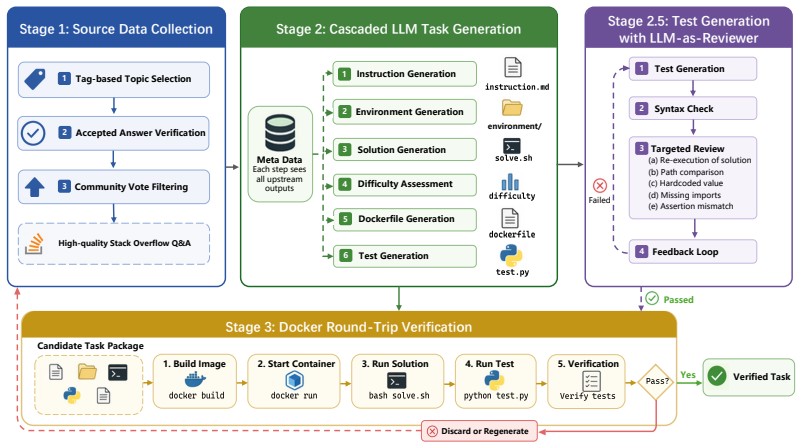
StackOverflow Crawling– Collect ∼36k questions with accepted answers across 98 weighted tags. 2.Cascaded Task Generation– LLM generates 7 files per task in dependency order. 3.Docker Round-Trip Validation– Build→solve→test→check reward. 4.Dataset Packaging– Renumber passed tasks into final corpus. 5.Oracle Evaluation– Sanity-check task solvability with or...
-
[33]
Write a clear task description in Markdown format
-
[34]
The task should be completed in a Linux terminal environment
-
[35]
Specify clear working directory paths (use /app/task_file/ as root directory)
-
[36]
If input files are needed, specify file location (e.g., /app/task_file/input/)
-
[37]
If output files are needed, specify output location (e.g., /app/task_file/output/)
-
[38]
Do NOT wrap in code blocks
Provide specific success criteria Please output the instruction.md content directly in markdown format. Do NOT wrap in code blocks. A.3.2 Stage 2: Environment Generation (temperature=0.3) Based on the following Terminal Bench task, analyze and generate the required environment files. **Task instruction:** {instruction} **Original question info:** Title: {...
-
[39]
Analyze what preset files the task needs (e.g., input data, config files)
-
[40]
Generate reasonable test data
-
[41]
File paths relative to environment/ directory
-
[42]
files": {
If needed, create subdirectory structure like task_file/input/ **Output format (JSON):** ‘‘‘json { "files": { "relative/path/filename": "file content", "task_file/input/example.txt": "example content..." }, "directories": ["task_file", "task_file/input", "task_file/output"] } ‘‘‘ Please output only JSON, wrapped with ‘‘‘json‘‘‘. If no files are needed, re...
-
[43]
Generate an executable bash script
-
[44]
The script should complete the task requirements
-
[45]
Include necessary comments
-
[46]
Handle possible error cases
-
[47]
Ensure output meets task requirements
-
[48]
‘‘‘ Please output only bash script content, wrapped with ‘‘‘bash‘‘‘
The script runs inside the container at WORKDIR /app **Output format:** ‘‘‘bash #!/bin/bash # Terminal-Bench Canary String, DO NOT REMOVE: # terminal-bench-canary GUID {guid} # Your solution code... ‘‘‘ Please output only bash script content, wrapped with ‘‘‘bash‘‘‘. A.3.4 Stage 4: Difficulty Classification (temperature=0.1) Assess the difficulty of the f...
-
[49]
\$PWD" =
**test.sh** - Test runner script, format: ‘‘‘bash # Terminal-Bench Canary String, DO NOT REMOVE: # terminal-bench-canary GUID {guid} #!/bin/bash apt-get update apt-get install -y curl # Install uv curl -LsSf https://astral.sh/uv/0.9.5/install.sh | sh source \$HOME/.local/bin/env # Check if we’re in a valid working directory if [ "\$PWD" = "/" ]; then echo...
-
[50]
filename
**test_outputs.py** - pytest test file that verifies the state AFTER solve.sh has already been executed: **CRITICAL RULES for test_outputs.py:** - solve.sh has ALREADY been executed before test_outputs.py runs. Do NOT call solve.sh again via subprocess. - Do NOT reference or invoke solve.sh in any test. It does not exist at test time. - Tests should ONLY ...
-
[51]
Does the test try to run solve.sh via subprocess? (FAIL if yes)
-
[52]
Does the test use brittle exact-path comparisons instead of endswith/basename? (WARN)
-
[53]
Does the test hardcode values that don’t match the solution’s actual output? (FAIL)
-
[54]
Does the test have missing imports or syntax errors? (FAIL)
-
[55]
pass": true,
Do the assertions actually check the expected post-solve.sh state? (FAIL if not) **Output format (JSON):** ‘‘‘json { "pass": true, "issues": [] } ‘‘‘ or ‘‘‘json { "pass": false, "issues": ["Issue 1: ...", "Issue 2: ..."] } ‘‘‘ Please output only JSON, wrapped with ‘‘‘json‘‘‘. A.3.7 Stage 7: Dockerfile Generation (temperature=0.3) Based on the following Te...
-
[56]
Choose an appropriate base image based on the task requirements: - For Python tasks: use ‘python:3.13-slim-bookworm‘ - For Node.js tasks: use ‘node:20-slim‘ - For Java tasks: use ‘openjdk:17-slim‘ - For Go tasks: use ‘golang:1.21-bookworm‘ - For general Linux/shell tasks: use ‘ubuntu:22.04‘
-
[57]
Install necessary packages for the task
-
[58]
Include the COPY command to copy task_file into the container
-
[59]
The Dockerfile must start with the canary string comment 18 **Output format:** ‘‘‘dockerfile # Terminal-Bench Canary String, DO NOT REMOVE: # terminal-bench-canary GUID {guid} FROM <base_image> WORKDIR /app RUN apt-get update && apt-get install -y <packages> && rm -rf /var/lib/apt/lists/* COPY ./task_file /app/task_file ‘‘‘ Please output only Dockerfile c...
-
[60]
Start container: docker run –name <container_name> -d <image_tag> sleep infinity 3.Copy solution:docker cp <task_dir>/solution/solve.sh <container>:/app/ 4.Execute solution:docker exec <container> bash /app/solve.sh 5.Copy tests:docker cp <task_dir>/tests <container>:/tests 6.Run tests:docker exec <container> bash /tests/test.sh 7.Read reward:docker cp <c...
-
[61]
what files exist?
Cleanup: docker stop <container> && docker rm <container> && docker rmi <image_tag> Parallelization:8 workers by default. Each worker processes one task at a time to avoid Docker resource contention. Timeout:300 seconds per task (configurable via –timeout). Tasks that exceed the timeout are marked as “timeout” and skipped. Error handling:Build failures, r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.