Demystifying Pipeline Parallelism: First Theory for PipeDream
Pith reviewed 2026-06-28 11:19 UTC · model grok-4.3
The pith
Randomized PipeDream yields the first clean nonconvex convergence guarantee for a PipeDream-style pipeline method.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
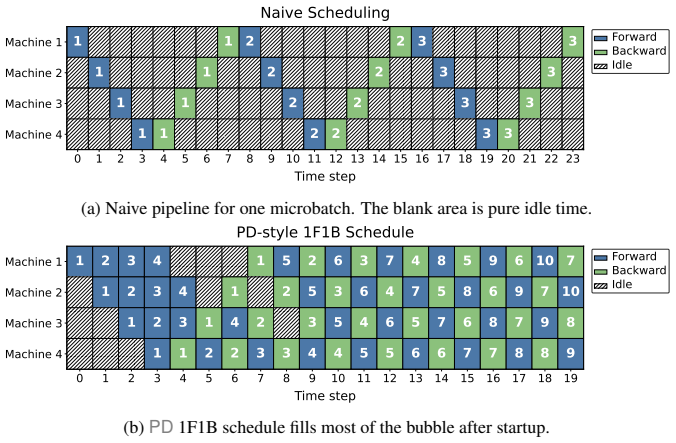
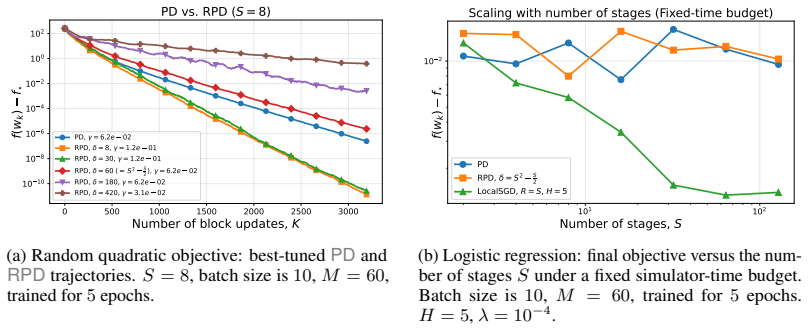
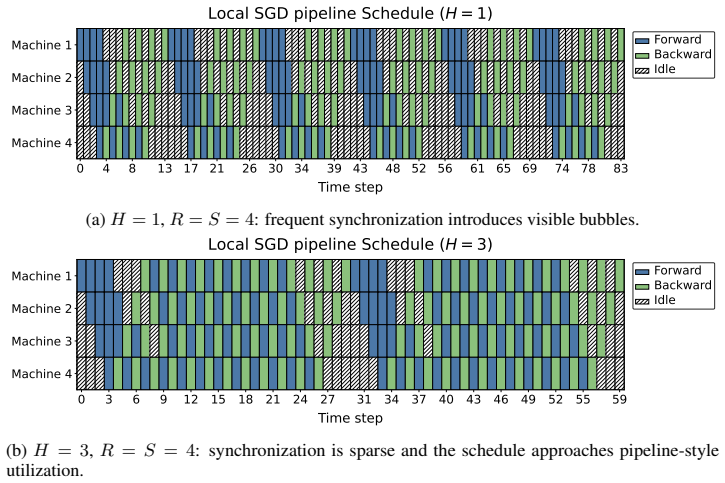
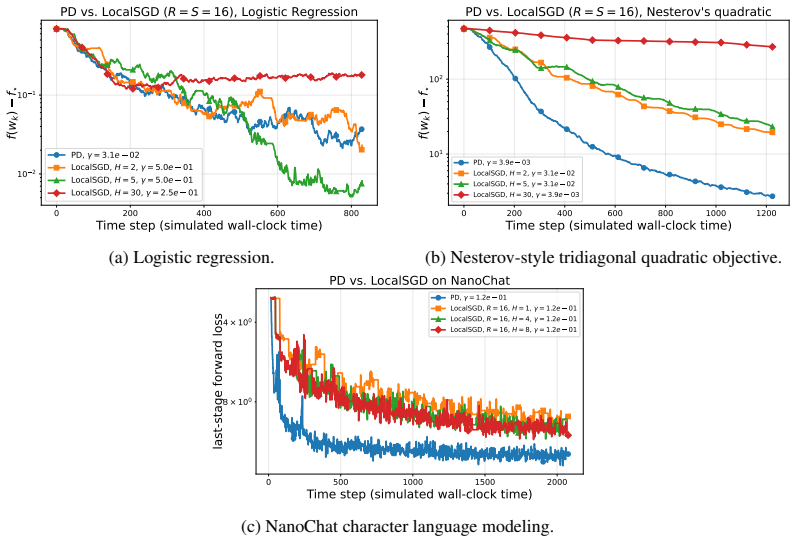
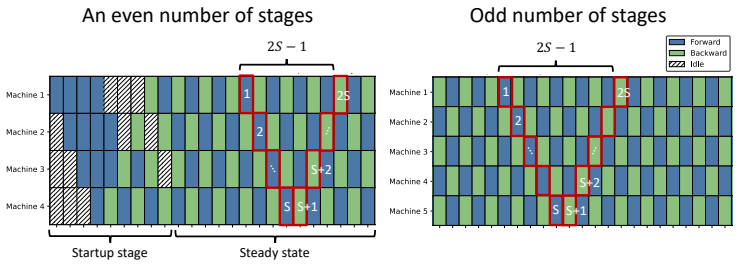
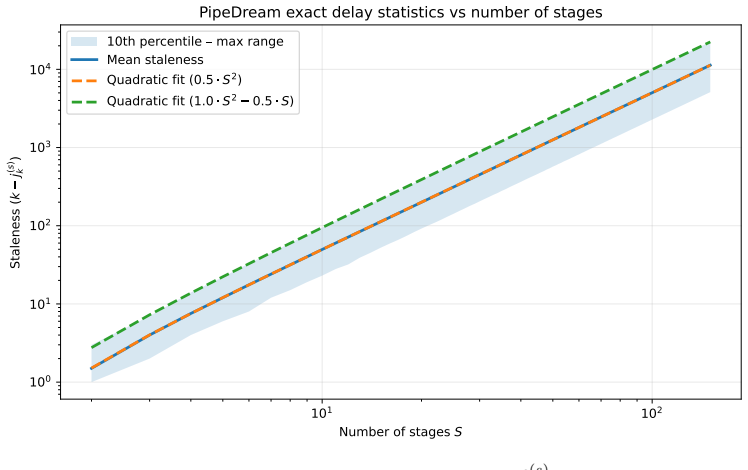
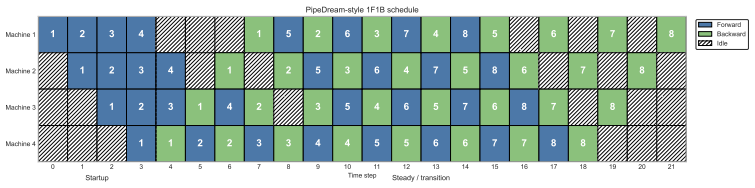
We introduce Randomized PipeDream (RPD), a stale block-SGD abstraction that yields, to our knowledge, the first clean nonconvex convergence guarantee for a PD-style method. We prove that the delay induced by steady-state PD grows as S^2 - S/2 + O(1) for S stages, so the stale-read contribution in the convergence theorem scales as Θ(γ² S⁴), equivalently as Θ(S⁴/K) in the tuned-rate form. In simulated-time experiments the better-performing method between PD and LocalSGD depends on the objective.
What carries the argument
Randomized PipeDream (RPD), a stale block-SGD abstraction of pipeline parallelism that models asynchronous stage updates via a fixed delay distribution.
If this is right
- Pipeline-parallel training of nonconvex models now possesses a provable rate that accounts for staleness.
- The staleness error term grows with the fourth power of the number of stages, limiting how many stages can be used before the rate degrades.
- For quadratic objectives and small language-modeling tasks, pipeline methods can outperform periodic averaging even with the induced delay.
- For logistic regression the advantage reverses as the stage count rises, because synchronization bubbles in LocalSGD become relatively cheaper.
Where Pith is reading between the lines
- The S^4 dependence suggests that pipeline schedules minimizing variance in stage delays could improve the practical rate more than simply adding stages.
- The same stale-block abstraction might be reused to analyze hybrid data-plus-pipeline schemes that combine both forms of parallelism.
- If the bounded-second-moment assumption fails in very deep pipelines, the convergence guarantee would need an adaptive delay model that tracks trajectory-dependent statistics.
Load-bearing premise
Steady-state PipeDream behavior can be captured by a fixed delay distribution whose second moment remains bounded independently of the optimization trajectory.
What would settle it
Measure the empirical delay distribution inside an actual PipeDream run on a nonconvex problem and check whether its second moment stays bounded as training proceeds or whether the observed convergence rate scales with S^4 when the stage count is increased.
Figures
read the original abstract
Training modern machine learning models increasingly requires computation to be distributed across many accelerators. Data parallelism remains the default choice and is often paired with tensor-parallel sharding, but model parallelism becomes unavoidable once parameters, activations, or optimizer states no longer fit on a single device. This paper studies pipeline model parallelism through the lens of PipeDream (PD) (Harlap et al., 2018). Our first contribution is theoretical: we introduce Randomized PipeDream (RPD), a stale block-SGD abstraction that yields, to our knowledge, the first clean nonconvex convergence guarantee for a PD-style method. Our second contribution is a scaling diagnosis: we prove that the delay induced by steady-state PD grows as $S^2 - S/2 + O(1)$ for $S$ stages, so the stale-read contribution in the convergence theorem scales as $\Theta(\gamma^2 S^4)$, equivalently as $\Theta(S^4/K)$ in the tuned-rate form. Our third contribution is a comparison with LocalSGD, whose periodic model averaging trades weight staleness for synchronization bubbles. In our reported simulated-time experiments, the better-performing method depends on the objective: PD performs better on the quadratic objective and on a small language-modeling training-loss task, while for logistic regression LocalSGD becomes superior as the number of stages increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Randomized PipeDream (RPD), a stale block-SGD abstraction of pipeline parallelism, and claims to provide the first clean nonconvex convergence guarantee for a PipeDream-style method. It derives that steady-state delay in an S-stage pipeline grows as S² - S/2 + O(1), so that the stale-read error term in the convergence bound scales as Θ(γ² S⁴) (or Θ(S⁴/K) after rate tuning). A third contribution compares RPD-style pipeline parallelism against LocalSGD on quadratic objectives, logistic regression, and a small language-modeling task, with simulated-time experiments showing objective-dependent superiority.
Significance. If the nonconvex guarantee holds under the stated modeling assumptions, the work would be significant as the first explicit convergence analysis for pipeline model parallelism and as a scaling diagnosis that quantifies how delay grows with the number of stages. The comparison with LocalSGD supplies concrete guidance on when each approach is preferable. No machine-checked proofs or fully reproducible code are referenced in the provided text.
major comments (1)
- [Theoretical Analysis / Convergence Theorem] The nonconvex convergence guarantee for RPD (stated in the abstract and developed in the theoretical section) rests on modeling steady-state PipeDream as a stale block-SGD process whose delay distribution has second moment bounded independently of the optimization trajectory. This independence is invoked to control the stale-read error term, which is asserted to scale as Θ(γ² S⁴). If stage execution times can vary with current weights, gradient magnitudes, or data-dependent control flow, the delay distribution becomes trajectory-dependent and the second-moment bound may grow, invalidating the error term used in the guarantee. A justification or relaxation of this assumption is required for the central claim.
Simulated Author's Rebuttal
We thank the referee for the detailed comment on the modeling assumptions in our convergence analysis. We respond point-by-point below.
read point-by-point responses
-
Referee: The nonconvex convergence guarantee for RPD (stated in the abstract and developed in the theoretical section) rests on modeling steady-state PipeDream as a stale block-SGD process whose delay distribution has second moment bounded independently of the optimization trajectory. This independence is invoked to control the stale-read error term, which is asserted to scale as Θ(γ² S⁴). If stage execution times can vary with current weights, gradient magnitudes, or data-dependent control flow, the delay distribution becomes trajectory-dependent and the second-moment bound may grow, invalidating the error term used in the guarantee. A justification or relaxation of this assumption is required for the central claim.
Authors: The RPD model explicitly treats per-stage execution times as i.i.d. draws from a fixed distribution that does not depend on the current weights, gradients, or data. This is the standard modeling choice for pipeline-parallelism analyses, because forward/backward pass times are dominated by the fixed layer sizes and hardware rather than by parameter values. Under this assumption the steady-state delay distribution (and therefore its second moment) is trajectory-independent and can be bounded by a function of S alone, yielding the claimed Θ(γ² S⁴) stale-read term. We will add an explicit statement of the assumption together with a short discussion of its scope in the revised theoretical section. revision: yes
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 27th ACM symposium on operating systems principles , pages=
PipeDream: Generalized pipeline parallelism for DNN training , author=. Proceedings of the 27th ACM symposium on operating systems principles , pages=
-
[2]
Proceedings of the AAAI conference on artificial intelligence , volume=
Parallel restarted SGD with faster convergence and less communication: Demystifying why model averaging works for deep learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[3]
Advances in neural information processing systems , volume=
Large scale distributed deep networks , author=. Advances in neural information processing systems , volume=
-
[4]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Accurate, large minibatch sgd: Training imagenet in 1 hour , author=. arXiv preprint arXiv:1706.02677 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in neural information processing systems , volume=
Gpipe: Efficient training of giant neural networks using pipeline parallelism , author=. Advances in neural information processing systems , volume=
-
[6]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-lm: Training multi-billion parameter language models using model parallelism , author=. arXiv preprint arXiv:1909.08053 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[7]
Local SGD Converges Fast and Communicates Little
Local SGD converges fast and communicates little , author=. arXiv preprint arXiv:1805.09767 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:1808.07217 , year=
Don't use large mini-batches, use local SGD , author=. arXiv preprint arXiv:1808.07217 , year=
-
[9]
SC20: international conference for high performance computing, networking, storage and analysis , pages=
Zero: Memory optimizations toward training trillion parameter models , author=. SC20: international conference for high performance computing, networking, storage and analysis , pages=. 2020 , organization=
2020
-
[10]
, author=
Beyond data and model parallelism for deep neural networks. , author=. Proceedings of Machine Learning and Systems , volume=
-
[11]
16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
Alpa: Automating inter-and \ Intra-Operator \ parallelism for distributed deep learning , author=. 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
-
[12]
PipeDream: Fast and Efficient Pipeline Parallel DNN Training
Pipedream: Fast and efficient pipeline parallel dnn training , author=. arXiv preprint arXiv:1806.03377 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
International Conference on Machine Learning , pages=
Memory-efficient pipeline-parallel dnn training , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[14]
Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming , pages=
DAPPLE: A pipelined data parallel approach for training large models , author=. Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming , pages=
-
[15]
Advances in neural information processing systems , volume=
Hogwild!: A lock-free approach to parallelizing stochastic gradient descent , author=. Advances in neural information processing systems , volume=
-
[16]
Advances in neural information processing systems , volume=
Asynchronous parallel stochastic gradient for nonconvex optimization , author=. Advances in neural information processing systems , volume=
-
[17]
SIAM Journal on Optimization , volume=
Perturbed iterate analysis for asynchronous stochastic optimization , author=. SIAM Journal on Optimization , volume=. 2017 , publisher=
2017
-
[18]
International conference on machine learning , pages=
Asynchronous stochastic gradient descent with delay compensation , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[19]
SIAM Journal on Optimization , volume=
Efficiency of coordinate descent methods on huge-scale optimization problems , author=. SIAM Journal on Optimization , volume=. 2012 , publisher=
2012
-
[20]
Mathematical Programming , volume=
Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function , author=. Mathematical Programming , volume=. 2014 , publisher=
2014
-
[21]
SIAM Journal on Optimization , volume=
Block stochastic gradient iteration for convex and nonconvex optimization , author=. SIAM Journal on Optimization , volume=. 2015 , publisher=
2015
-
[22]
Advances in neural information processing systems , volume=
Parallelized stochastic gradient descent , author=. Advances in neural information processing systems , volume=
-
[23]
2025 , howpublished =
Karpathy, Andrej , title =. 2025 , howpublished =
2025
-
[24]
2022 , howpublished =
Karpathy, Andrej , title =. 2022 , howpublished =
2022
-
[25]
2015 , howpublished =
Karpathy, Andrej , title =. 2015 , howpublished =
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.