ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
Pith reviewed 2026-06-28 10:05 UTC · model grok-4.3
The pith
ThoughtFold folds correct reasoning trajectories into shorter paths by penalizing redundant explorations with masked preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
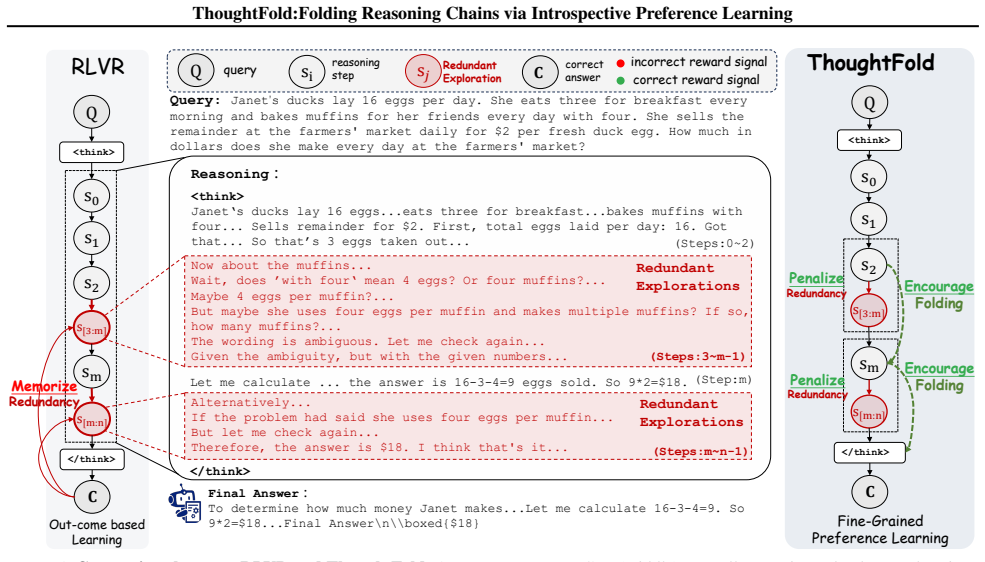
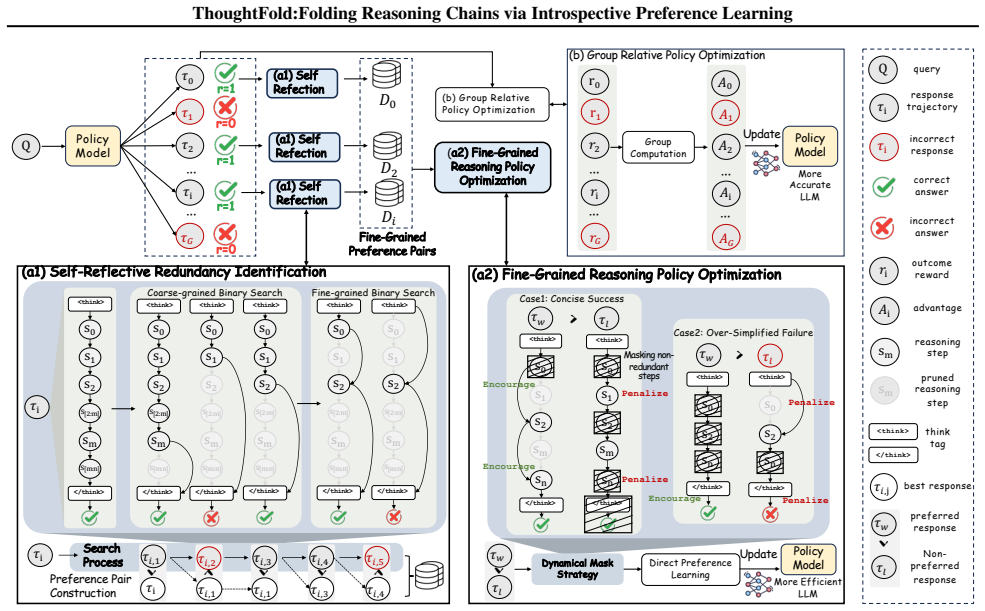
ThoughtFold employs an introspective strategy to identify redundancy within each correct trajectory, which yields a spectrum of candidate sub-trajectories. Leveraging this spectrum, we introduce a masked preference optimization objective that explicitly penalizes redundant explorations and encourages the model to directly bridge essential reasoning segments, effectively folding its reasoning chains into a more concise path.
What carries the argument
Introspective extraction of sub-trajectories from outcome-correct CoTs combined with a masked preference optimization objective that penalizes redundant segments.
If this is right
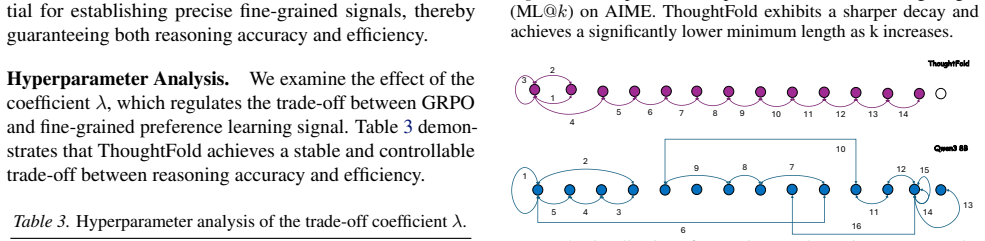
- Token usage of DeepSeek-R1-Distill-Qwen-7B drops by approximately 56 percent.
- State-of-the-art accuracy is preserved across tested reasoning tasks.
- Over-thinking from reinforced redundant explorations in long CoTs is reduced.
- Learning signals become finer-grained than pure outcome-based reinforcement.
Where Pith is reading between the lines
- The same folding approach could be tested on code-generation or mathematical proof tasks that also produce long correct trajectories.
- Combining ThoughtFold with other inference-time compression techniques might yield further efficiency gains.
- Deployment of large reasoning models in resource-constrained settings becomes more practical if the token savings hold across domains.
- The work raises the open question of how much conciseness can be added before essential intermediate verification steps are lost.
Load-bearing premise
The introspective strategy can reliably extract a spectrum of valid sub-trajectories from each correct CoT without introducing selection bias or lowering the quality of the underlying reasoning.
What would settle it
An experiment in which ThoughtFold-trained models show no token reduction or drop below baseline accuracy on the same reasoning benchmarks would falsify the central efficiency claim.
Figures

read the original abstract
Large Reasoning Models (LRMs) have achieved remarkable progress thanks to Reinforcement Learning with Verifiable Rewards (RLVR) on Chain-of-Thoughts (CoTs). However, since long CoTs naturally contain trial and errors and mainstream RLVR approaches choose outcome-correct CoT trajectories for memorization, the redundant explorations in long CoTs are inevitably reinforced, which results in the over-thinking issues of LRMs. Previous attempts to resolve this issue mainly give more advantage to shorter trajectories, yet their learning signals are still outcome-based and cannot reduce the memorization of redundant explorations in long CoTs. Therefore, we propose ThoughtFold, a framework that leverages fine-grained preference learning to mitigate redundant explorations for efficient reasoning. ThoughtFold employs an introspective strategy to identify redundancy within each correct trajectory, which yields a spectrum of candidate sub-trajectories. Leveraging this spectrum, we introduce a masked preference optimization objective that explicitly penalizes redundant explorations and encourages the model to directly bridge essential reasoning segments, effectively folding its reasoning chains into a more concise path. Extensive experiments show that ThoughtFold significantly enhances efficiency. It reduces the token usage of DeepSeek-R1-Distill-Qwen-7B by approximately 56% while maintaining state-of-the-art accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ThoughtFold, a framework for efficient reasoning in Large Reasoning Models. It uses an introspective strategy to detect redundancy within outcome-correct CoT trajectories, producing a spectrum of candidate sub-trajectories, then applies a masked preference optimization objective that penalizes redundant explorations and encourages direct bridging of essential segments. Experiments report that this yields an approximately 56% token reduction on DeepSeek-R1-Distill-Qwen-7B while preserving state-of-the-art accuracy.
Significance. If the introspective extraction and masked optimization are shown to operate without systematic bias, the approach supplies a concrete mechanism for moving beyond purely outcome-based RLVR signals, directly targeting over-thinking in LRMs and offering a path to shorter yet reliable reasoning chains.
major comments (3)
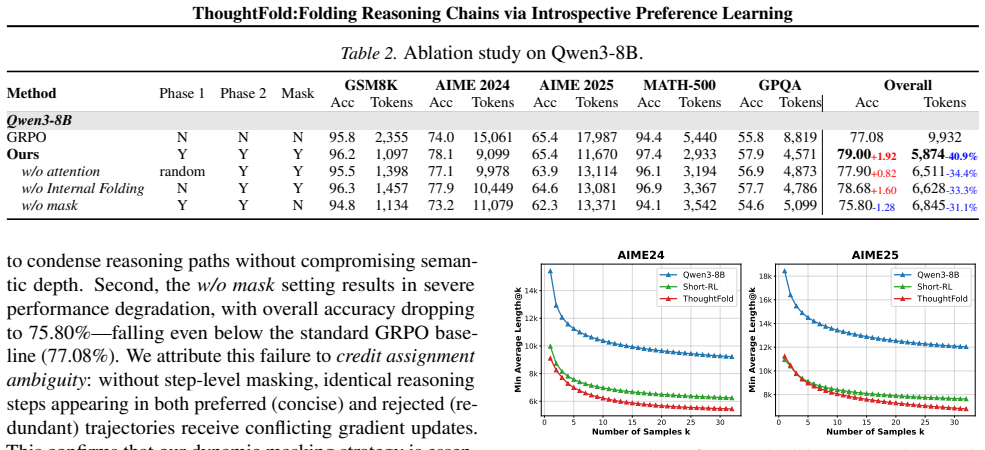
- [Method (introspective strategy)] The introspective strategy for identifying redundancy (described in the method section) supplies no explicit validation, ablation, or human/automated check that the extracted sub-trajectories preserve semantic coverage and reasoning robustness; without this, the masked preference optimization risks training on systematically shorter but lower-quality trajectories, undermining the efficiency claim.
- [Experiments] The headline result of 56% token reduction on DeepSeek-R1-Distill-Qwen-7B (reported in the abstract and experiments) is presented without error bars, multiple random seeds, or controls that isolate the contribution of the folding mechanism from possible post-hoc trajectory selection or length-based filtering.
- [Method (masked preference optimization)] The masked preference optimization objective is introduced as explicitly penalizing redundant explorations, yet the manuscript provides no formal definition or pseudocode showing how the mask is constructed from the introspective spectrum, leaving open whether the objective is outcome-independent or still implicitly relies on the original trajectory length.
minor comments (2)
- Add a clear notation table or diagram illustrating the spectrum of sub-trajectories and the masking operation.
- Clarify whether the introspective identification step uses the same base model or an auxiliary model, and report any additional compute cost.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (introspective strategy)] The introspective strategy for identifying redundancy (described in the method section) supplies no explicit validation, ablation, or human/automated check that the extracted sub-trajectories preserve semantic coverage and reasoning robustness; without this, the masked preference optimization risks training on systematically shorter but lower-quality trajectories, undermining the efficiency claim.
Authors: We acknowledge the value of explicit validation for the introspective redundancy detection. The strategy identifies redundant segments via self-consistency within outcome-correct CoTs to form the spectrum, ensuring essential reasoning steps are retained by construction. To strengthen this, we will add an ablation study isolating the introspective step and automated checks using embedding-based semantic similarity to verify coverage between original and sub-trajectories in the revised manuscript. revision: yes
-
Referee: [Experiments] The headline result of 56% token reduction on DeepSeek-R1-Distill-Qwen-7B (reported in the abstract and experiments) is presented without error bars, multiple random seeds, or controls that isolate the contribution of the folding mechanism from possible post-hoc trajectory selection or length-based filtering.
Authors: The 56% figure represents the observed average token reduction across benchmarks. We will rerun experiments with multiple random seeds and report means with standard deviations and error bars. We will also include a control ablation applying post-hoc length filtering or random shortening to isolate the folding mechanism's contribution from selection effects. revision: yes
-
Referee: [Method (masked preference optimization)] The masked preference optimization objective is introduced as explicitly penalizing redundant explorations, yet the manuscript provides no formal definition or pseudocode showing how the mask is constructed from the introspective spectrum, leaving open whether the objective is outcome-independent or still implicitly relies on the original trajectory length.
Authors: We will include a formal mathematical definition of the mask construction from the introspective spectrum along with pseudocode in the revised method section. The mask is built exclusively from preference pairs within the spectrum to target redundant segments; the objective remains outcome-independent as it does not reference original trajectory length beyond the initial correctness selection. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces ThoughtFold as an empirical framework consisting of an introspective redundancy identification step followed by masked preference optimization on extracted sub-trajectories. No equations, fitted parameters, or derivation steps are shown that reduce any claimed prediction or result to the inputs by construction. The efficiency and accuracy claims rest on experimental outcomes rather than self-referential definitions or self-citation chains that would make the central result tautological. The method is presented as a novel proposal whose validity is tested externally via token reduction and accuracy metrics on held-out models.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aggarwal, P. and Welleck, S. L1: Controlling how long a reasoning model thinks with reinforcement learning. arXiv preprint arXiv:2503.04697,
-
[2]
Arora, D. and Zanette, A. Training language models to rea- son efficiently.arXiv preprint arXiv:2502.04463, 2025a. Arora, D. and Zanette, A. Training language models to rea- son efficiently, 2025b. URL https://arxiv.org/ abs/2502.04463. Bai, L., Cai, Z., Cao, Y ., Cao, M., Cao, W., Chen, C., Chen, H., Chen, K., Chen, P., Chen, Y ., et al. Intern-s1: A sci...
-
[3]
URL https://arxiv.org/abs/ 2107.03374. Chen, X., Xu, J., Liang, T., He, Z., Pang, J., Yu, D., Song, L., Liu, Q., Zhou, M., Zhang, Z., Wang, R., Tu, Z., Mi, H., and Yu, D. Do not think that much for 2+3=? on the overthinking of o1-like llms,
-
[4]
Chen, Y ., Liu, Z., Huang, Z., Gui, R., Wang, H., and Liu, L
URL https: //arxiv.org/abs/2412.21187. Chen, Y ., Liu, Z., Huang, Z., Gui, R., Wang, H., and Liu, L. Arborkv: Structure-aware kv cache manage- ment for scaling tree-based llm reasoning.arXiv preprint arXiv:2605.22106,
-
[5]
URL https://arxiv. org/abs/2110.14168. Comanici, G., Bieber, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,
-
[6]
URLhttps://arxiv.org/abs/2507.06261. Dai, M., Yang, C., and Si, Q. S-grpo: Early exit via re- inforcement learning in reasoning models,
-
[7]
URL https://arxiv.org/abs/2505.07686. DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y ., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F....
-
[8]
Gao, S., Gu, Y ., Wu, Z., Kong, L., Zhang, W., Cai, Z., Zheng, F., Ma, T., Shen, J., Zhao, H., et al
URL https://arxiv.org/abs/2501.12948. Gao, S., Gu, Y ., Wu, Z., Kong, L., Zhang, W., Cai, Z., Zheng, F., Ma, T., Shen, J., Zhao, H., et al. Long-horizon reasoning agent for olympiad-level mathematical problem solving.arXiv preprint arXiv:2512.10739,
-
[9]
Mask- dpo: Generalizable fine-grained factuality alignment of llms.arXiv preprint arXiv:2503.02846,
Gu, Y ., Zhang, W., Lyu, C., Lin, D., and Chen, K. Mask- dpo: Generalizable fine-grained factuality alignment of llms.arXiv preprint arXiv:2503.02846,
-
[10]
Gui, R., Li, Y ., Qu, X., Liu, Z., Cheng, Y ., and Cheng, Y . Learning to reason faithfully through step-level faithful- ness maximization.arXiv preprint arXiv:2602.03507, 2026a. Gui, R., Wang, J., Wang, Z., Ma, C., Hao, J., and Wu, F. Short chains, deep thoughts: Balancing reasoning efficiency and intra-segment capability via split-merge optimization.arX...
-
[11]
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J
URL https: //arxiv.org/abs/2504.11456. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding, 2021a. URL https: //arxiv.org/abs/2009.03300. Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical prob...
Pith/arXiv arXiv 2009
-
[12]
How well do llms compress their own chain-of-thought? a token complexity approach
Lee, A., Che, E., and Peng, T. How well do llms compress their own chain-of-thought? a token complexity approach. arXiv preprint arXiv:2503.01141,
-
[13]
Li, Y ., Yuan, P., Feng, S., Pan, B., Wang, X., Sun, B., Wang, H., and Li, K
URLhttps://arxiv.org/abs/2510.04474. Li, Y ., Yuan, P., Feng, S., Pan, B., Wang, X., Sun, B., Wang, H., and Li, K. Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning.arXiv preprint arXiv:2401.10480,
-
[14]
Reward-guided specula- tive decoding for efficient llm reasoning.arXiv preprint arXiv:2501.19324,
Liao, B., Xu, Y ., Dong, H., Li, J., Monz, C., Savarese, S., Sahoo, D., and Xiong, C. Reward-guided specula- tive decoding for efficient llm reasoning.arXiv preprint arXiv:2501.19324,
-
[15]
Liu, Z., Chen, Y ., Cai, H., Lin, T., Yang, S., Liu, Z., and Zhao, B. Vla-pruner: Temporal-aware dual-level visual token pruning for efficient vision-language-action infer- ence.arXiv preprint arXiv:2511.16449,
-
[16]
Meta-cognitive memory policy optimization for long-horizon llm agents
Liu, Z., Hao, Z., Chen, Y ., Wang, H., Hou, J., Ding, R., Yang, Y ., Ji, W., Xia, W., and Liu, F. Meta-cognitive memory policy optimization for long-horizon llm agents. arXiv preprint arXiv:2605.30159,
-
[17]
Luo, H., Shen, L., He, H., Wang, Y ., Liu, S., Li, W., Tan, N., Cao, X., and Tao, D. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning.arXiv preprint arXiv:2501.12570,
-
[18]
Luo, H., Jiang, Z., Hasan, M. Z., Chen, Y ., and Sarkar, S. Frost: Filtering reasoning outliers with attention for efficient reasoning.arXiv preprint arXiv:2601.19001,
-
[19]
Luo, L., Liu, Y ., Liu, R., Phatale, S., Guo, M., Lara, H., Li, Y ., Shu, L., Zhu, Y ., Meng, L., et al. Improve mathemati- cal reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592,
-
[20]
Reasoning models can be effective without thinking
Ma, W., He, J., Snell, C., Griggs, T., Min, S., and Zaharia, M. Reasoning models can be effective without thinking. arXiv preprint arXiv:2504.09858, 2025a. 10 ThoughtFold:Folding Reasoning Chains via Introspective Preference Learning Ma, X., Wan, G., Yu, R., Fang, G., and Wang, X. Cot-valve: Length-compressible chain-of-thought tuning.arXiv preprint arXiv...
-
[21]
Mnih, V ., Kavukcuoglu, K., Silver, D., Rusu, A
URLhttps://arxiv.org/abs/2506.05744. Mnih, V ., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidje- land, A. K., Ostrovski, G., et al. Human-level control through deep reinforcement learning.nature, 518(7540): 529–533,
-
[22]
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C
URL https: //arxiv.org/abs/2412.15115. Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct preference optimization: Your language model is secretly a reward model,
-
[23]
URL https://arxiv.org/abs/2305.18290. Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. Gpqa: A graduate-level google-proof q&a benchmark,
-
[24]
URL https://arxiv.org/abs/2311.12022. Renze, M. and Guven, E. The benefits of a concise chain of thought on problem-solving in large language models. In 2024 2nd International Conference on Foundation and Large Language Models (FLLM), pp. 476–483. IEEE,
Pith/arXiv arXiv 2024
-
[25]
Silver, D., Huang, A., Maddison, C
URL https://arxiv.org/abs/ 1707.06347. Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V ., Lanctot, M., et al. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489,
-
[26]
URLhttps://arxiv.org/abs/2405.04776. Sui, Y ., Chuang, Y .-N., Wang, G., Zhang, J., Zhang, T., Yuan, J., Liu, H., Wen, A., Zhong, S., Chen, H., and Hu, X. Stop overthinking: A survey on efficient reasoning for large language models,
-
[27]
URL https://arxiv. org/abs/2503.16419. Sun, W., Du, Q., Cui, F., and Zhang, J. An efficient and precise training data construction framework for process- supervised reward model in mathematical reasoning. In Proceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), pp. 4292–4305,
-
[28]
Kimi k1.5: Scaling reinforcement learning with llms, 2025a
Team, K., Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., Tang, C., Wang, C., Zhang, D., Yuan, E., Lu, E., Tang, F., Sung, F., Wei, G., Lai, G., Guo, H., Zhu, H., Ding, H., Hu, H., Yang, H., Zhang, H., Yao, H., Zhao, H., Lu, H., Li, H., Yu, H., Gao, H., Zheng, H., Yuan, H., Chen, J., Guo, J., Su, J., Wang, J., Zhao, J.,...
-
[29]
URL https: //arxiv.org/abs/2505.09388. Uesato, J., Kushman, N., Kumar, R., Song, F., Siegel, N., Wang, L., Creswell, A., Irving, G., and Higgins, I. Solv- ing math word problems with process- and outcome- based feedback,
-
[30]
Wang, Z., Geng, Z., Tu, Z., Wang, J., Qian, Y ., Xu, Z., Liu, Z., Xu, S., Tang, Z., Kai, S., et al
URL https://arxiv.org/ abs/2211.14275. Wang, Z., Geng, Z., Tu, Z., Wang, J., Qian, Y ., Xu, Z., Liu, Z., Xu, S., Tang, Z., Kai, S., et al. Benchmarking end-to- end performance of ai-based chip placement algorithms. Advances in Neural Information Processing Systems, 38,
-
[31]
Weston, J., Chopra, S., and Bordes, A
URL https://arxiv.org/abs/ 2201.11903. Weston, J., Chopra, S., and Bordes, A. Memory net- works,
-
[32]
Wu, Z., Kong, L., Zhang, W., Gao, S., Gu, Y ., Cai, Z., Ma, T., Liu, Y ., Wang, Z., Ma, R., et al
URL https://arxiv.org/abs/ 1410.3916. Wu, Z., Kong, L., Zhang, W., Gao, S., Gu, Y ., Cai, Z., Ma, T., Liu, Y ., Wang, Z., Ma, R., et al. Opv: Outcome- based process verifier for efficient long chain-of-thought verification.arXiv preprint arXiv:2512.10756, 2025a. Wu, Z., Zeng, Q., Zhang, Z., Tan, Z., Shen, C., and Jiang, M. Enhancing mathematical reasoning...
-
[33]
Towards large reasoning models: A survey of reinforced reasoning with large language models, 2025a
Xu, F., Hao, Q., Zong, Z., Wang, J., Zhang, Y ., Wang, J., Lan, X., Gong, J., Ouyang, T., Meng, F., Shao, C., Yan, Y ., Yang, Q., Song, Y ., Ren, S., Hu, X., Li, Y ., Feng, J., Gao, C., and Li, Y . Towards large reasoning models: A survey of reinforced reasoning with large language models, 2025a. URL https://arxiv.org/abs/ 2501.09686. Xu, S., Xie, W., Zha...
-
[34]
Yeo, E., Tong, Y ., Niu, M., Neubig, G., and Yue, X
URL https://arxiv.org/abs/ 1809.09600. Yeo, E., Tong, Y ., Niu, M., Neubig, G., and Yue, X. Demys- tifying long chain-of-thought reasoning in llms.arXiv preprint arXiv:2502.03373,
-
[35]
URL https://arxiv.org/abs/2504. 21370. Yu, P., Xu, J., Weston, J., and Kulikov, I. Distilling system 2 into system 1.arXiv preprint arXiv:2407.06023,
-
[36]
Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Fan, T., Liu, G., Liu, L., Liu, X., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[37]
Efficient rl training for reasoning models via length-aware optimization
Yuan, D., Xie, T., Huang, S., Gong, Z., Zhang, H., Luo, C., Wei, F., and Zhao, D. Efficient rl training for reasoning models via length-aware optimization. InNeurIPS 2025 Workshop on Efficient Reasoning,
2025
-
[38]
Zelikman, E., Wu, Y ., Mu, J., and Goodman, N
URL https://arxiv.org/ abs/2508.10293. Zelikman, E., Wu, Y ., Mu, J., and Goodman, N. D. Star: Bootstrapping reasoning with reasoning,
-
[39]
Zhang, K., Yao, Q., Liu, S., Wang, Y ., Lai, B., Ye, J., Song, M., and Tao, D
URL https://arxiv.org/abs/2203.14465. Zhang, K., Yao, Q., Liu, S., Wang, Y ., Lai, B., Ye, J., Song, M., and Tao, D. Consistent paths lead to truth: Self-rewarding reinforcement learning for llm reasoning. arXiv preprint arXiv:2506.08745,
-
[40]
Intern-s1-pro: Scientific multimodal foundation model at trillion scale
Zou, Y ., Zhu, D., Zhu, L., Zhu, T., Zhou, Y ., Zhou, P., Zhou, X., Zhou, D., Zhou, Z., Zhou, Y ., et al. Intern-s1-pro: Scientific multimodal foundation model at trillion scale. arXiv preprint arXiv:2603.25040,
-
[41]
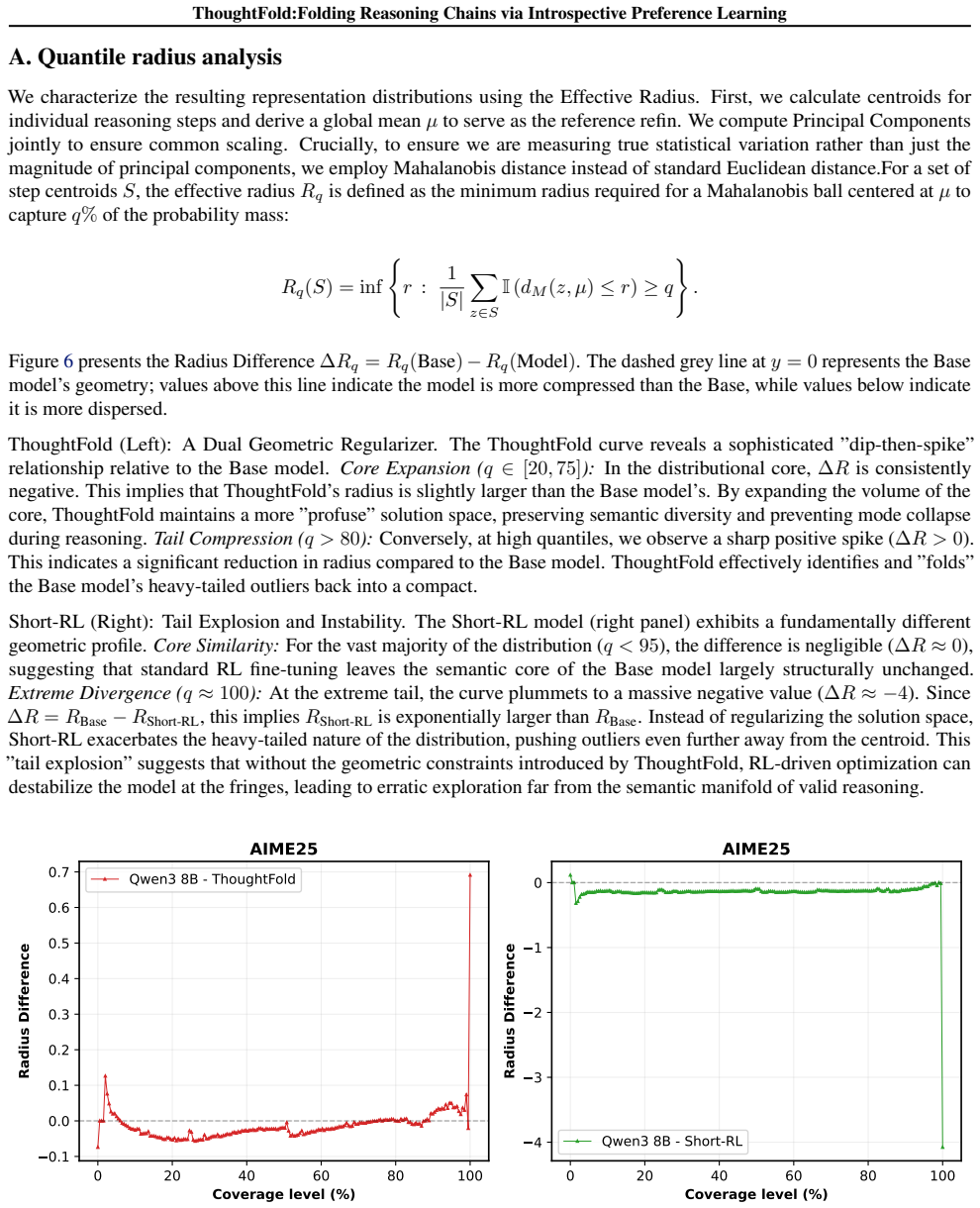
Quantile radius analysis We characterize the resulting representation distributions using the Effective Radius
13 ThoughtFold:Folding Reasoning Chains via Introspective Preference Learning A. Quantile radius analysis We characterize the resulting representation distributions using the Effective Radius. First, we calculate centroids for individual reasoning steps and derive a global mean µ to serve as the reference refin. We compute Principal Components jointly to ...
2021
-
[42]
Recent works further improve PRM data construction or stepwise correction for mathematical reasoning (Sun et al., 2025; Wu et al., 2025b)
constructs process-supervision data for mathematical reasoning by using Monte Carlo tree search and binary search to locate the first erroneous step. Recent works further improve PRM data construction or stepwise correction for mathematical reasoning (Sun et al., 2025; Wu et al., 2025b). Although these methods also analyze intermediate reasoning steps, th...
2025
-
[43]
Beyond these applications, RL has been widely applied to practical optimization scenarios, such as chip design (Geng et al., 2024; 2025; Wang et al., 2026)
and RLVR (Gui et al., 2026a; Liu et al., 2026; DeepSeek-AI et al., 2025; Wu et al., 2025a). Beyond these applications, RL has been widely applied to practical optimization scenarios, such as chip design (Geng et al., 2024; 2025; Wang et al., 2026). E. Justification of Attention-based Pruning In the internal folding stage, ThoughtFold ranks reasoning steps...
2026
-
[44]
observes that attention over reasoning steps during answer generation is highly sparse: only a subset of reasoning steps receives most of the attention, while many steps receive little attention. These findings support the use of answer-to-reasoning attention as a practical proxy for identifying low-contribution reasoning steps. Formally, for a reasoning ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.