Knowledge-Preserved Model Tuning in Null-Space for Robust Spatio-Temporal Video Grounding
Pith reviewed 2026-06-28 11:12 UTC · model grok-4.3
The pith
Null-space tuning adapts spatio-temporal video grounding models to low-quality inputs while leaving high-quality performance unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
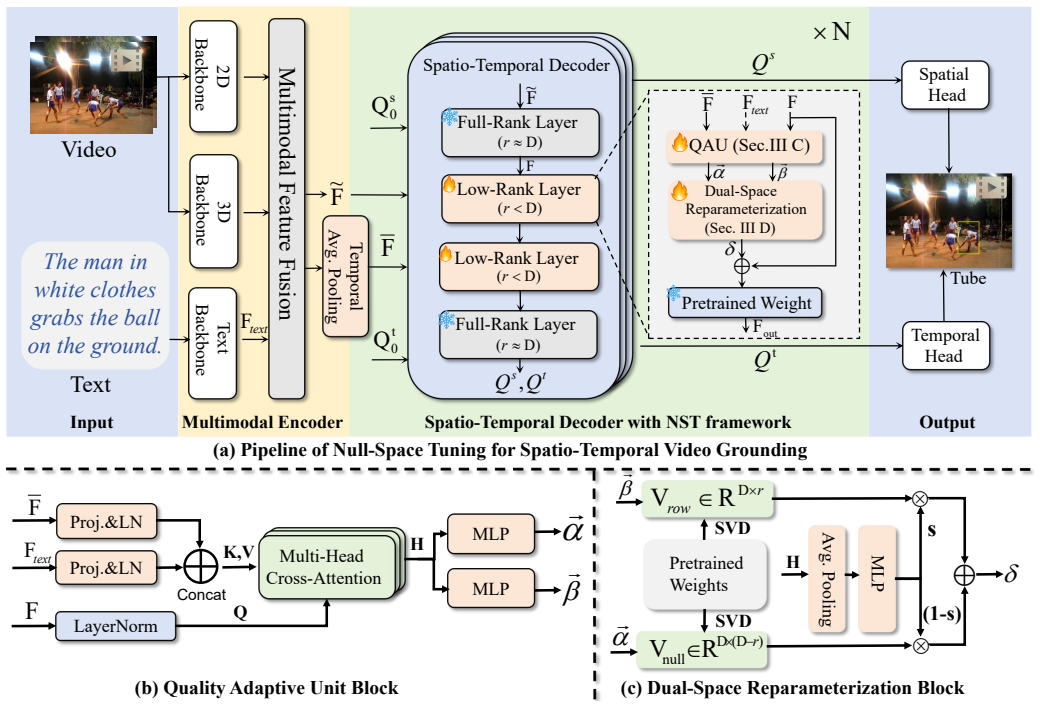
Null-Space Tuning injects learnable residuals into input features that can be made selectively invisible to the pre-trained backbone. The Quality-Adaptive Unit and Dual-Space Reparameterization synthesize these residuals so that components for high-quality inputs stay inside the null space while restoration components for low-quality inputs occupy the non-null space; because the frozen weights remove any null-space contribution, degraded inputs are rectified and pre-trained knowledge is preserved for clean inputs.
What carries the argument
Null-Space Tuning framework that combines the Quality-Adaptive Unit and Dual-Space Reparameterization to confine high-quality residuals to the null space of frozen weights.
If this is right
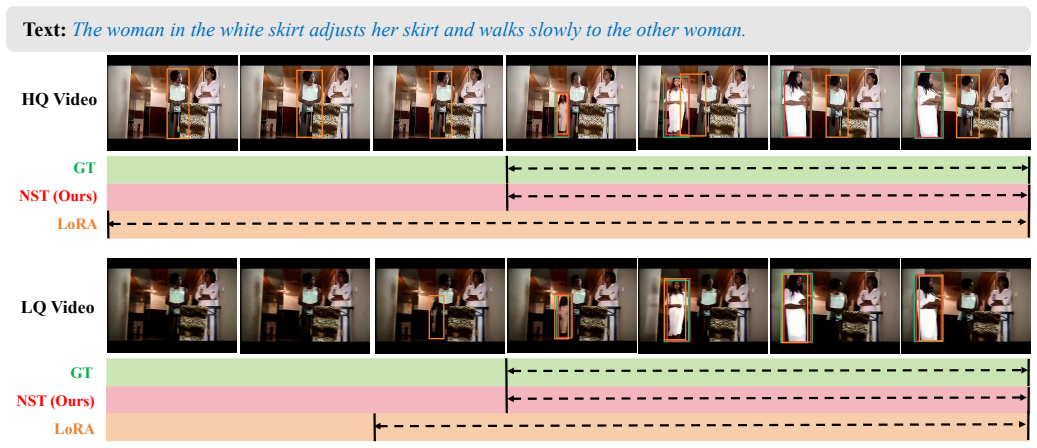
- The model improves accuracy on low-quality video inputs while matching the original model on high-quality inputs.
- The method avoids the knowledge disruption that occurs with standard low-rank adaptation techniques such as LoRA.
- Performance gains hold across the introduced Mixed-Quality benchmark that mixes high- and low-quality videos.
- The geometric null-space property is used to make restoration signals visible only when needed.
Where Pith is reading between the lines
- The same null-space confinement could be tested on other video-language tasks that also suffer from variable input quality.
- If the Quality-Adaptive Unit can be made input-dependent at inference time, the method might handle streaming video with changing quality without retraining.
- Extending the dual-space reparameterization to multiple layers simultaneously could increase the capacity for restoration without increasing visible parameter count.
Load-bearing premise
Adding vectors inside the null space of the frozen weights leaves the layer output exactly unchanged.
What would settle it
On the Mixed-Quality benchmark, measure whether high-quality video performance drops below the untuned baseline after NST is applied; any measurable drop falsifies the preservation claim.
Figures

read the original abstract
Spatio-Temporal Video Grounding aims to localize object tubes based on textual queries. While recent methods have achieved remarkable success, they mainly focus on high-quality(HQ) inputs, neglecting the widespread presence of low-quality(LQ) videos in real-world scenarios. Although tuning methods like LoRA can adapt to degraded inputs, they inevitably disrupt pre-trained knowledge. To address this, we propose Null-Space Tuning (NST). This framework exploits the geometric property that adding vectors within the null-space of frozen weights to the layer input does not affect the output. Leveraging this, NST injects learnable residuals into input features that can be selectively invisible to the pre-trained backbone. Specifically, NST combines the Quality-Adaptive Unit and Dual-Space Reparameterization to synthesize these residuals by confining components for HQ inputs to the null-space, while directing restoration components for LQ inputs to the non-null space. As the frozen weights eliminate null-space components, we effectively rectify degraded inputs while preserving pre-trained knowledge for HQ inputs. Extensive experiments show that NST outperforms state-of-the-art methods on our Mixed-Quality benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Null-Space Tuning (NST) for spatio-temporal video grounding to handle both high-quality (HQ) and low-quality (LQ) video inputs. It exploits the geometric property that vectors in the null-space of frozen pre-trained weights do not affect layer outputs when added to inputs. NST uses a Quality-Adaptive Unit and Dual-Space Reparameterization to synthesize learnable residuals that are confined to the null-space (thus invisible) for HQ inputs while directing restoration components for LQ inputs to the non-null space, thereby rectifying degraded inputs without disrupting pre-trained knowledge. The paper claims NST outperforms state-of-the-art methods on a newly introduced Mixed-Quality benchmark.
Significance. If substantiated, the result would be significant for robust video grounding in real-world settings with variable input quality. The approach applies a standard linear-algebra fact (null-space invariance) in a novel way to achieve knowledge-preserving adaptation, which could generalize to other vision-language tuning tasks and reduce the need for full fine-tuning or data augmentation for degradation.
major comments (2)
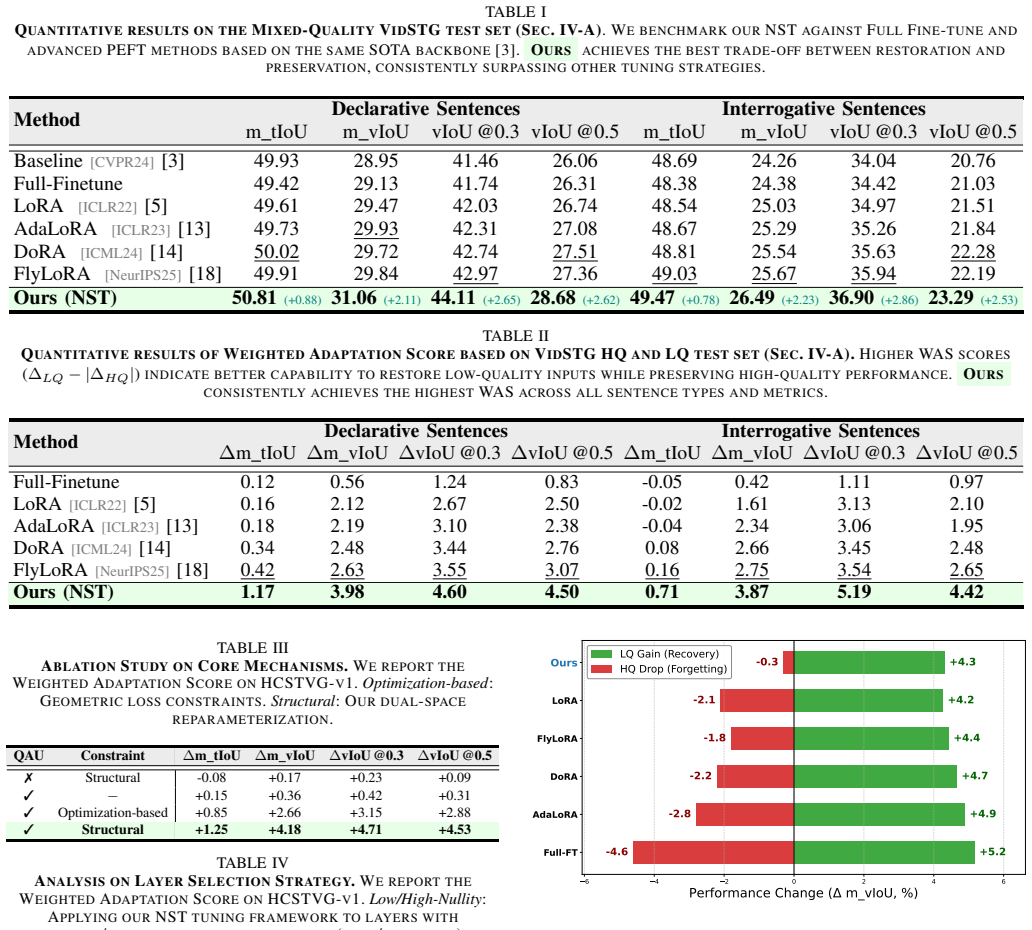
- [Abstract] Abstract: the central claim that 'NST outperforms state-of-the-art methods on our Mixed-Quality benchmark' is asserted without any quantitative results, metrics (e.g., mIoU or recall), baselines, dataset statistics, or error analysis, rendering the superiority claim impossible to evaluate.
- [Method] Method description: no equations or algorithmic details are supplied for the Quality-Adaptive Unit or Dual-Space Reparameterization, so it is impossible to verify that the routing actually confines HQ residuals to the null-space while placing LQ restoration components outside it.
minor comments (2)
- [Abstract] Abstract: 'high-quality(HQ)' lacks a space before the parenthesis; consistent spacing improves readability.
- The construction and composition of the 'Mixed-Quality benchmark' (how LQ videos are synthesized, proportion of LQ/HQ samples, source datasets) is not described.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and will make the necessary revisions to improve clarity and substantiation of claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'NST outperforms state-of-the-art methods on our Mixed-Quality benchmark' is asserted without any quantitative results, metrics (e.g., mIoU or recall), baselines, dataset statistics, or error analysis, rendering the superiority claim impossible to evaluate.
Authors: We agree that the abstract should be self-contained and include key quantitative evidence to support the performance claim. In the revised manuscript, we will update the abstract to report specific metrics (e.g., mIoU and recall improvements) along with brief baseline comparisons on the Mixed-Quality benchmark. The full paper already contains detailed experimental results, tables, and analysis, but we acknowledge the abstract requires this augmentation for immediate evaluability. revision: yes
-
Referee: [Method] Method description: no equations or algorithmic details are supplied for the Quality-Adaptive Unit or Dual-Space Reparameterization, so it is impossible to verify that the routing actually confines HQ residuals to the null-space while placing LQ restoration components outside it.
Authors: We will revise the method section to include explicit mathematical equations defining the Quality-Adaptive Unit and Dual-Space Reparameterization, along with pseudocode for the routing mechanism. This will formally show how null-space projection confines HQ residuals (ensuring they are eliminated by frozen weights) while directing LQ restoration components into the non-null space. The current description relies on geometric explanation, but additional formalism will enable direct verification. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central mechanism rests on the standard linear-algebra identity that any vector v in the null space of frozen weights W satisfies W(x + v) = Wx. This identity is external to the paper and is not derived from its own data, fits, or self-citations. The Quality-Adaptive Unit and Dual-Space Reparameterization are introduced as concrete, novel constructions that route residuals into or out of that null space; they do not presuppose the selective invisibility result they are meant to achieve. No equations, uniqueness theorems, or parameter-fitting steps are shown that reduce the claimed outcome to the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable residuals
axioms (1)
- standard math Adding vectors within the null-space of frozen weights to the layer input does not affect the output.
Reference graph
Works this paper leans on
-
[1]
Where does it exist: Spatio-temporal video grounding for multi-form sentences,
Zhu Zhang et al., “Where does it exist: Spatio-temporal video grounding for multi-form sentences,” inCVPR, 2020, pp. 10668–10677
2020
-
[2]
End-to-end object detection with transformers,
Nicolas Carion, Francisco Massa, et al., “End-to-end object detection with transformers,” inECCV. Springer, 2020, pp. 213–229
2020
-
[3]
Context-guided spatio-temporal video grounding,
Xin Gu, Heng Fan, et al., “Context-guided spatio-temporal video grounding,” inCVPR, 2024, pp. 18330–18339
2024
-
[4]
Knowing your target: Target-aware transformer makes better spatio-temporal video grounding,
Xin Gu, Yaojie Shen, et al., “Knowing your target: Target-aware transformer makes better spatio-temporal video grounding,” inICLR. 2025, OpenReview.net
2025
-
[5]
Lora: Low-rank adaptation of large language models,
Edward J Hu, Yelong Shen, et al., “Lora: Low-rank adaptation of large language models,”ICLR, vol. 1, no. 2, pp. 3, 2022
2022
-
[6]
Object-aware multi-branch rela- tion networks for spatio-temporal video grounding,
Zhu Zhang, Zhou Zhao, et al., “Object-aware multi-branch rela- tion networks for spatio-temporal video grounding,”arXiv preprint arXiv:2008.06941, 2020
-
[7]
Human-centric spatio-temporal video grounding with visual transformers,
Zongheng Tang, Yue Liao, et al., “Human-centric spatio-temporal video grounding with visual transformers,”IEEE TCSVT, vol. 32, no. 12, pp. 8238–8249, 2021
2021
-
[8]
Stvgbert: A visual-linguistic transformer based framework for spatio-temporal video grounding,
Rui Su et al., “Stvgbert: A visual-linguistic transformer based framework for spatio-temporal video grounding,” inICCV, 2021, pp. 1533–1542
2021
-
[9]
Tubedetr: Spatio-temporal video grounding with transformers,
Antoine Yang, Antoine Miech, et al., “Tubedetr: Spatio-temporal video grounding with transformers,” inCVPR, 2022, pp. 16442–16453
2022
-
[10]
Embracing consistency: A one-stage approach for spatio-temporal video grounding,
Yang Jin, Zehuan Yuan, et al., “Embracing consistency: A one-stage approach for spatio-temporal video grounding,”NeurIPS, vol. 35, pp. 29192–29204, 2022
2022
-
[11]
Parameter-efficient transfer learning for nlp,
Neil Houlsby, Andrei Giurgiu, et al., “Parameter-efficient transfer learning for nlp,” inICML. PMLR, 2019, pp. 2790–2799
2019
-
[12]
Visual prompt tuning,
Menglin Jia, Luming Tang, et al., “Visual prompt tuning,” inECCV. Springer, 2022, pp. 709–727
2022
-
[13]
Adaptive budget allocation for parameter-efficient fine-tuning,
Qingru Zhang, Minshuo Chen, et al., “Adaptive budget allocation for parameter-efficient fine-tuning,” inICLR. 2023, OpenReview.net
2023
-
[14]
Dora: Weight-decomposed low- rank adaptation,
Shih-Yang Liu, Chien-Yi Wang, et al., “Dora: Weight-decomposed low- rank adaptation,” inICML, 2024
2024
-
[15]
Training networks in null space of feature covariance for continual learning,
Shipeng Wang, Xiaorong Li, et al., “Training networks in null space of feature covariance for continual learning,” inCVPR, 2021, pp. 184–193
2021
-
[16]
Alphaedit: Null-space con- strained knowledge editing for language models,
Junfeng Fang, Houcheng Jiang, et al., “Alphaedit: Null-space con- strained knowledge editing for language models,” inICLR. 2025, OpenReview.net
2025
-
[17]
Mamba-cl: Optimizing selective state space model in null space for continual learning,
De Cheng, Yue Lu, et al., “Mamba-cl: Optimizing selective state space model in null space for continual learning,”arXiv preprint arXiv:2411.15469, 2024
-
[18]
Heming Zou, Yunliang Zang, et al., “Flylora: Boosting task decoupling and parameter efficiency via implicit rank-wise mixture-of-experts,” arXiv preprint arXiv:2510.08396, 2025
-
[19]
Deep residual learning for image recognition,
Kaiming He, Xiangyu Zhang, et al., “Deep residual learning for image recognition,” inCVPR, 2016, pp. 770–778
2016
-
[20]
Video swin transformer,
Ze Liu et al., “Video swin transformer,” inCVPR, 2022, pp. 3202–3211
2022
-
[21]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, et al., “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[22]
Mdetr-modulated detection for end-to-end multi-modal understanding,
Aishwarya Kamath et al., “Mdetr-modulated detection for end-to-end multi-modal understanding,” inICCV, 2021, pp. 1780–1790
2021
-
[23]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter, “Decoupled weight decay regulariza- tion,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Collaborative static and dynamic vision-language streams for spatio-temporal video grounding,
Zihang Lin, Chaolei Tan, et al., “Collaborative static and dynamic vision-language streams for spatio-temporal video grounding,” inCVPR, 2023, pp. 23100–23109
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.