Re-Ranking Through an Attribution Lens for Citation Quality in Legal QA
Pith reviewed 2026-06-28 10:32 UTC · model grok-4.3
The pith
Re-ranking passages with attribution scores improves citation faithfulness in legal QA systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
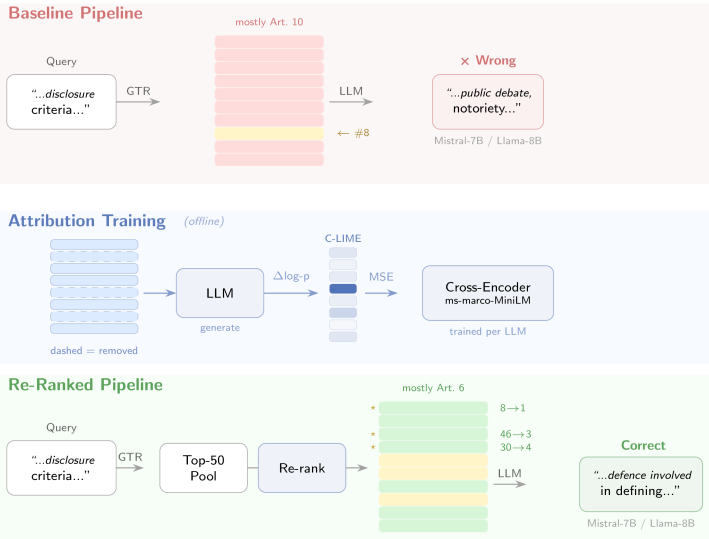
On the AQuAECHR benchmark, semantic similarity ranking performs worse than random at surfacing gold citation paragraphs for legal QA. Training a lightweight cross-encoder on perturbation-based attribution scores to re-rank passages prior to generation substantially improves citation faithfulness and alignment with gold expert answers across two language models and five-fold cross-validation. Re-rankers trained independently on different models converge beyond their raw attribution agreement, indicating the cross-encoder reduces model-specific noise and produces a shared relevance signal.
What carries the argument
lightweight cross-encoder re-ranker trained on continuous perturbation-based attribution scores such as C-LIME
If this is right
- The re-ranker substantially improves citation faithfulness.
- Alignment with gold expert answers increases.
- Re-rankers from different models produce a shared relevance signal that partially transfers across models.
- Same-model re-ranking remains more effective than cross-model.
- Perturbation-based attribution provides a practical training signal for citation-aware retrieval.
Where Pith is reading between the lines
- Attribution-based re-ranking could be tested in non-legal domains where citation accuracy matters.
- The convergence suggests potential for model-agnostic citation retrieval systems.
- Future work might explore whether this signal improves overall answer quality beyond citations.
Load-bearing premise
That perturbation-based attribution scores like C-LIME are a reliable and generalizable training signal for citation quality superior to semantic similarity within the candidate pool.
What would settle it
A failure of the trained cross-encoder to improve citation faithfulness metrics compared to the baseline retriever on the AQuAECHR benchmark under five-fold cross-validation would falsify the claim.
Figures
read the original abstract
Retrieval-augmented generation systems for legal question answering typically retrieve passages based on semantic similarity and provide them to a language model, which then generates cited answers. Prior work assumes that highly ranked passages are most likely to be usefully cited by the model. Perturbation-based attribution methods, such as C-LIME, have been used exclusively for post-hoc explanation. However, on the AQuAECHR benchmark, semantic similarity does not correlate with passage attribution. Within a retriever's candidate pool, similarity-based ranking performs worse than random selection at surfacing gold citation paragraphs. To address this limitation, a lightweight cross-encoder is trained on continuous perturbation-based attribution scores to re-rank passages prior to generation. This approach is evaluated on the AQuAECHR benchmark, using two language models and five-fold cross-validation. The re-ranker substantially improves citation faithfulness and alignment with gold expert answers. Notably, two re-rankers trained independently on different models converge beyond their raw attribution agreement. This finding indicates that the cross-encoder reduces model-specific noise and produces a shared relevance signal that partially transfers across models, although same-model re-ranking remains more effective. These results demonstrate that perturbation-based attribution provides a practical, model-agnostic training signal for citation-aware retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in retrieval-augmented legal QA, semantic similarity ranking within a retriever's candidate pool correlates poorly with perturbation-based attribution (C-LIME) and underperforms random selection at surfacing gold citation paragraphs on the AQuAECHR benchmark. A lightweight cross-encoder is trained on continuous attribution scores to re-rank passages before generation; evaluated with two language models and five-fold cross-validation, this re-ranker improves citation faithfulness and alignment with gold expert answers. Two independently trained re-rankers converge beyond their raw attribution agreement, indicating that the cross-encoder reduces model-specific noise and yields a partially transferable shared relevance signal (though same-model re-ranking remains stronger).
Significance. If the empirical results hold, the work supplies a practical, model-agnostic training signal for citation-aware retrieval that leverages existing attribution methods rather than requiring gold citation labels. The observation of cross-model convergence after independent training on different LMs is a notable strength, as is the use of five-fold cross-validation; both provide evidence that the approach can distill a general relevance signal. These elements address a documented mismatch between semantic similarity and model attribution in a high-stakes domain.
major comments (2)
- [Abstract] Abstract: the central claim that attribution-trained re-ranking 'substantially improves citation faithfulness and alignment with gold expert answers' is load-bearing yet unsupported by any reported quantitative deltas, confidence intervals, or per-metric values; without these numbers the magnitude of improvement cannot be assessed relative to the semantic-similarity and random baselines already mentioned.
- [Abstract] Abstract / Evaluation description: the premise that continuous C-LIME attribution scores constitute a superior training signal is invoked to justify training the cross-encoder, but no ablation is described that compares this signal against an identically architected cross-encoder trained on gold citation labels (or on model log-probabilities); such a comparison is required to rule out the possibility that any cross-encoder simply learns a generic relevance function.
minor comments (1)
- [Abstract] Abstract: the benchmark is referred to only as 'AQuAECHR'; an expansion or citation on first use would aid readers unfamiliar with the dataset.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that attribution-trained re-ranking 'substantially improves citation faithfulness and alignment with gold expert answers' is load-bearing yet unsupported by any reported quantitative deltas, confidence intervals, or per-metric values; without these numbers the magnitude of improvement cannot be assessed relative to the semantic-similarity and random baselines already mentioned.
Authors: We agree with this observation. The abstract currently summarizes the improvements qualitatively. In the revised version, we will include specific quantitative deltas, confidence intervals, and per-metric values from our five-fold cross-validation experiments to allow readers to assess the magnitude of improvement over the semantic similarity and random baselines. revision: yes
-
Referee: [Abstract] Abstract / Evaluation description: the premise that continuous C-LIME attribution scores constitute a superior training signal is invoked to justify training the cross-encoder, but no ablation is described that compares this signal against an identically architected cross-encoder trained on gold citation labels (or on model log-probabilities); such a comparison is required to rule out the possibility that any cross-encoder simply learns a generic relevance function.
Authors: This is a valid point. Our work focuses on using attribution scores as a training signal in the absence of gold labels, which is a key practical advantage in legal QA. Nevertheless, to address the concern and strengthen the evaluation, we will perform and report an ablation study in the revised manuscript. This will involve training an identical cross-encoder on gold citation labels from the AQuAECHR benchmark and comparing its performance to the attribution-based re-ranker. We will also consider including a comparison to log-probability based training if feasible. The cross-model convergence results already suggest the signal is not entirely generic, but the proposed ablation will provide direct evidence. revision: yes
Circularity Check
No significant circularity; derivation relies on external signals and benchmark
full rationale
The paper trains a cross-encoder re-ranker using continuous C-LIME attribution scores (external perturbation method) as the training target and evaluates citation faithfulness plus expert-answer alignment on the independent AQuAECHR benchmark with five-fold cross-validation. The reported cross-model convergence is an empirical observation on held-out data, not a quantity that reduces by the paper's own equations or definitions to a fitted parameter or self-citation. No self-definitional steps, fitted-input-called-prediction, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the abstract or described method. The central claims remain falsifiable against external gold labels and do not collapse to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- cross-encoder training hyperparameters
axioms (1)
- domain assumption Perturbation-based attribution scores provide a better proxy for citation utility than semantic similarity within a fixed candidate pool
Reference graph
Works this paper leans on
-
[1]
D. M. Katz, M. J. Bommarito, S. Gao, P. Arredondo, GPT-4 passes the bar exam, 2024. doi:10.2139/ ssrn.4389233
2024
-
[2]
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. tau Yih, T. Rocktäschel, S. Riedel, D. Kiela, Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021. URL: https://arxiv.org/abs/2005.11401.arXiv:2005.11401
Pith/arXiv arXiv 2021
-
[3]
K. Q. Weidinger, S. T.y.s.s, O. Ichim, M. Grabmair, AQuAECHR: Attributed question answering for European court of human rights, 2025. URL: https://aclanthology.org/2025.findings-acl.74/. doi:10.18653/v1/2025.findings-acl.74
-
[4]
T. Gao, H. Yen, J. Yu, D. Chen, Enabling large language models to generate text with citations,
-
[5]
URL: https://arxiv.org/abs/2305.14627.arXiv:2305.14627
- [6]
-
[7]
L. Monteiro Paes, D. Wei, H. J. Do, Others, Multi-level explanations for generative language mod- els, 2025. URL: https://aclanthology.org/2025.acl-long.1553/. doi:10.18653/v1/2025.acl-long. 1553
-
[8]
R. Nogueira, K. Cho, Passage re-ranking with bert, 2020. URL: https://arxiv.org/abs/1901.04085. arXiv:1901.04085
Pith/arXiv arXiv 2020
-
[9]
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, P. Liang, Lost in the middle: How language models use long contexts, 2023. URL: https://arxiv.org/abs/2307.03172. arXiv:2307.03172
Pith/arXiv arXiv 2023
- [10]
-
[11]
Nogueira, Z
R. Nogueira, Z. Jiang, J. Lin, Document ranking with a pretrained sequence-to-sequence model,
-
[12]
URL: https://arxiv.org/abs/2003.06713.arXiv:2003.06713
arXiv 2003
- [13]
-
[14]
X. Ma, L. Wang, N. Yang, F. Wei, J. Lin, Fine-tuning llama for multi-stage text retrieval, 2023. URL: https://arxiv.org/abs/2310.08319.arXiv:2310.08319
arXiv 2023
-
[15]
R. Pradeep, S. Sharifymoghaddam, J. Lin, Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze!, 2023. URL: https://arxiv.org/abs/2312.02724.arXiv:2312.02724
Pith/arXiv arXiv 2023
-
[16]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, H. Wang, Retrieval-augmented generation for large language models: A survey, 2024. URL: https://arxiv.org/abs/2312.10997. arXiv:2312.10997
Pith/arXiv arXiv 2024
-
[17]
W. Sun, L. Yan, X. Ma, S. Wang, P. Ren, Z. Chen, D. Yin, Z. Ren, Is chatgpt good at search? investigating large language models as re-ranking agents, 2024. URL: https://arxiv.org/abs/2304. 09542.arXiv:2304.09542
arXiv 2024
-
[18]
P. Jia, D. Xu, X. Li, Z. Du, X. Li, Y. Wang, Y. Wang, Q. Liu, M. Wang, H. Guo, R. Tang, X. Zhao, Bridging relevance and reasoning: Rationale distillation in retrieval-augmented generation, 2025. URL: https://arxiv.org/abs/2412.08519.arXiv:2412.08519
arXiv 2025
-
[19]
H. Rashkin, V. Nikolaev, M. Lamm, L. Aroyo, M. Collins, D. Das, S. Petrov, G. S. Tomar, I. Turc, D. Reitter, Measuring attribution in natural language generation models, 2022. URL: https://arxiv. org/abs/2112.12870.arXiv:2112.12870
arXiv 2022
-
[20]
Z. Gekhman, J. Herzig, R. Aharoni, C. Elkind, I. Szpektor, Trueteacher: Learning factual con- sistency evaluation with large language models, 2023. URL: https://arxiv.org/abs/2305.11171. arXiv:2305.11171
arXiv 2023
-
[21]
N. Pipitone, G. H. Alami, Legalbench-rag: A benchmark for retrieval-augmented generation in the legal domain, 2024. URL: https://arxiv.org/abs/2408.10343.arXiv:2408.10343
arXiv 2024
-
[22]
I. Chalkidis, M. Fergadiotis, D. Tsarapatsanis, N. Aletras, I. Androutsopoulos, P. Malakasiotis, Paragraph-level rationale extraction through regularization: A case study on european court of human rights cases, 2021. URL: https://arxiv.org/abs/2103.13084.arXiv:2103.13084
arXiv 2021
-
[23]
Y. Xu, J. Gao, X. Yu, Y. Xue, B. Bi, H. Shen, X. Cheng, Training a utility-based retriever through shared context attribution for retrieval-augmented language models, 2026. URL: https://arxiv.org/ abs/2504.00573.arXiv:2504.00573
arXiv 2026
-
[24]
J. Ni, C. Qu, J. Lu, Z. Dai, G. H. Ábrego, J. Ma, V. Y. Zhao, Y. Luan, K. B. Hall, M.-W. Chang, Y. Yang, Large dual encoders are generalizable retrievers, 2021. URL: https://arxiv.org/abs/2112.07899. arXiv:2112.07899
arXiv 2021
-
[25]
N. Reimers, I. Gurevych, Sentence-bert: Sentence embeddings using siamese bert-networks, 2019. URL: https://arxiv.org/abs/1908.10084.arXiv:1908.10084
Pith/arXiv arXiv 2019
-
[26]
Lin, ROUGE: A package for automatic evaluation of summaries, 2004
C.-Y. Lin, ROUGE: A package for automatic evaluation of summaries, 2004. URL: https:// aclanthology.org/W04-1013/. Table 5 Key passage rank changes under re-ranking (Mistral pointwise). GTR = original retriever rank within top-50. RR = re-ranked position in selected top-10. Passages marked with ⋆ appear in the gold citation or target answer. “– ” indicate...
2004
-
[27]
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, P. J. Liu, Exploring the limits of transfer learning with a unified text-to-text transformer, 2023. URL: https://arxiv.org/ abs/1910.10683.arXiv:1910.10683. A. Qualitative Examples This appendix presents two representative questions contrasting baseline (GTR top-10) and re-ra...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.