Reasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
Pith reviewed 2026-06-28 10:14 UTC · model grok-4.3
The pith
Linguistic reasoning traces improve low-resource machine translation most effectively when supplied as inference-time guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
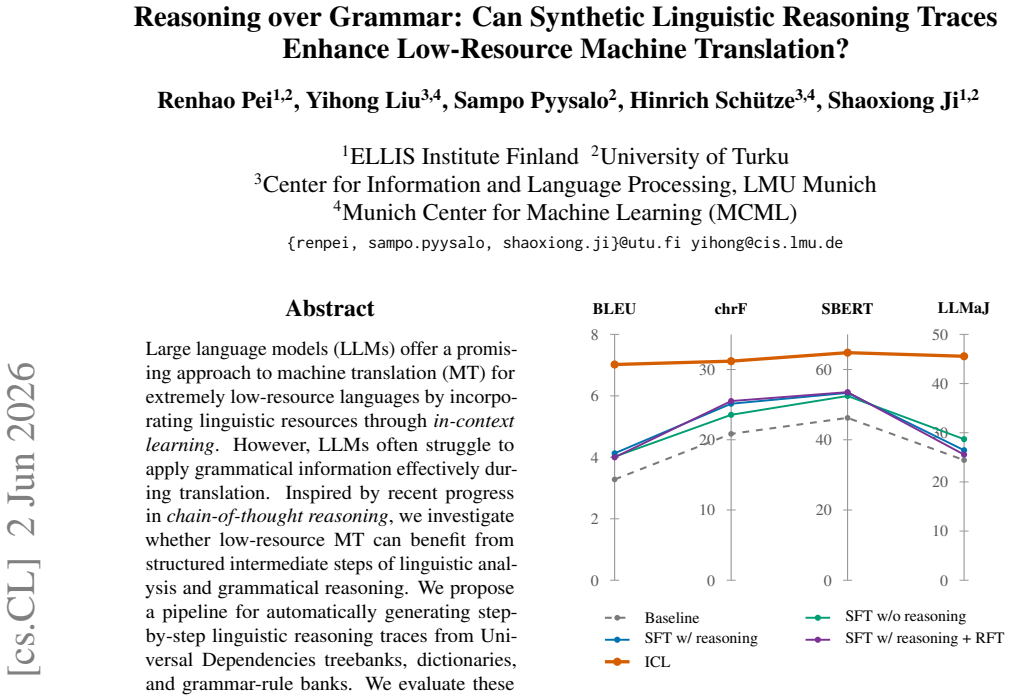
The central claim is that reliable sentence-specific linguistic reasoning traces substantially improve translation performance across most models, languages, and metrics when used in in-context learning, while the same traces produce smaller and less consistent gains when used as training data for supervised or reinforcement fine-tuning because models learn the trace format but frequently generate erroneous content.
What carries the argument
The automatic pipeline that produces step-by-step linguistic reasoning traces from Universal Dependencies treebanks, dictionaries, and grammar-rule banks.
If this is right
- Sentence-specific traces raise translation quality in in-context learning across most tested models, languages, and automatic metrics.
- The same traces produce smaller and less consistent gains when used to fine-tune models via supervised or reinforcement learning.
- Models trained on the traces tend to adopt the required format while still producing erroneous linguistic content.
- Large language models can apply grammatical information to low-resource translation once reliable analyses are supplied at inference time.
Where Pith is reading between the lines
- If the accuracy of the automatic trace generator were raised, the smaller gains seen in fine-tuning settings might become larger and more consistent.
- The same pipeline could be applied to other low-resource languages that already have Universal Dependencies resources available.
- Hybrid training that combines a small amount of fine-tuning with inference-time trace guidance might reduce the current performance gap between the two regimes.
Load-bearing premise
The automatic pipeline produces linguistic analyses accurate enough to serve as reliable ground truth for the in-context learning experiments.
What would settle it
A controlled test that swaps the generated traces for deliberately incorrect or random traces and measures whether the reported ICL gains disappear would show whether the improvements require accurate linguistic content.
Figures

read the original abstract
Large language models (LLMs) offer a promising approach to machine translation (MT) for extremely low-resource languages by incorporating linguistic resources through in-context learning. However, LLMs often struggle to apply grammatical information effectively during translation. Inspired by recent progress in chain-of-thought reasoning, we investigate whether low-resource MT can benefit from structured intermediate steps of linguistic analysis and grammatical reasoning. We propose a pipeline for automatically generating step-by-step linguistic reasoning traces from Universal Dependencies treebanks, dictionaries, and grammar-rule banks. We evaluate these traces in three settings: in-context learning (ICL), supervised fine-tuning (SFT), and reinforcement fine-tuning (RFT), on Xibe and Chintang as test cases. Our results show that linguistic reasoning traces are most effective as inference-time guidance: in ICL, reliable sentence-specific traces substantially improve translation performance across most models, languages, and metrics. In contrast, using the linguistic reasoning traces as training data yields smaller and less consistent gains, as models learn the trace format but often generate erroneous content. These findings suggest that LLMs can leverage grammatical information for low-resource MT when given reliable linguistic analyses, while learning to generate such analyses remains a major bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an automatic pipeline that generates step-by-step linguistic reasoning traces from Universal Dependencies treebanks, dictionaries, and grammar-rule banks. These traces are evaluated for low-resource machine translation on Xibe and Chintang in three regimes: in-context learning (ICL), supervised fine-tuning (SFT), and reinforcement fine-tuning (RFT). The central claim is that reliable, sentence-specific traces produce substantial gains when supplied at inference time in ICL, whereas incorporating the same traces into training data yields smaller and less consistent improvements because models tend to reproduce the trace format while generating erroneous content.
Significance. If the reported ICL gains can be shown to arise from the grammatical content of the traces rather than surface artifacts, the work would provide concrete evidence that explicit linguistic analyses can be leveraged by LLMs for extremely low-resource MT when supplied reliably at inference time. The contrast between ICL and training regimes would also be a useful empirical observation for the design of hybrid linguistic-neural systems.
major comments (2)
- [Abstract and pipeline description] Abstract and pipeline description: the claim that the automatically generated traces are 'reliable' and 'sentence-specific' is presented without any reported human evaluation, inter-annotator agreement, or error analysis of the traces themselves. Because the headline ICL result attributes performance gains to the linguistic reasoning content, the absence of verification that the traces are faithful to the source sentences is load-bearing for the central empirical claim.
- [Results presentation] Results presentation (throughout experimental sections): the abstract states that reliable traces 'substantially improve translation performance across most models, languages, and metrics,' yet the provided text supplies no numerical scores, baseline systems, or statistical significance tests. Without these, it is impossible to assess the magnitude or reliability of the reported contrast between ICL and SFT/RFT.
minor comments (2)
- [Experimental setup] Ensure that the exact prompt templates, trace formatting, and model versions are documented in sufficient detail to allow reproduction of the ICL experiments.
- [Pipeline description] Clarify whether the grammar-rule banks and dictionaries are language-specific or shared, and how coverage gaps are handled for the two test languages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for verification of the traces and clearer results presentation. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core findings.
read point-by-point responses
-
Referee: [Abstract and pipeline description] Abstract and pipeline description: the claim that the automatically generated traces are 'reliable' and 'sentence-specific' is presented without any reported human evaluation, inter-annotator agreement, or error analysis of the traces themselves. Because the headline ICL result attributes performance gains to the linguistic reasoning content, the absence of verification that the traces are faithful to the source sentences is load-bearing for the central empirical claim.
Authors: We agree this is a substantive point. The traces are constructed automatically from gold-standard UD treebanks, dictionaries, and grammar-rule banks, making them sentence-specific by construction, and their practical reliability is evidenced by the ICL performance gains relative to trace-free baselines. However, we did not include a dedicated human validation or error analysis in the original submission. In the revision we will add an error analysis subsection that samples traces across both languages, reports the proportion of steps that are grammatically accurate and faithful to the source sentence, and discusses common error types. revision: yes
-
Referee: [Results presentation] Results presentation (throughout experimental sections): the abstract states that reliable traces 'substantially improve translation performance across most models, languages, and metrics,' yet the provided text supplies no numerical scores, baseline systems, or statistical significance tests. Without these, it is impossible to assess the magnitude or reliability of the reported contrast between ICL and SFT/RFT.
Authors: We acknowledge that the experimental sections must supply concrete numbers, baselines, and significance tests for readers to evaluate the ICL versus SFT/RFT contrast. The manuscript contains tables reporting BLEU, chrF, and COMET scores for all three regimes, languages, and models, together with comparisons against trace-free baselines. To ensure these are fully visible and the magnitude of gains is clear, we will revise the experimental sections to foreground key numerical deltas, explicitly list the baseline systems, and add statistical significance results (e.g., paired bootstrap tests) where they were previously summarized rather than tabulated. revision: yes
Circularity Check
Empirical evaluation with no derivations or self-referential reductions
full rationale
The paper conducts an empirical comparison of ICL, SFT, and RFT regimes using automatically generated linguistic traces from external resources (UD treebanks, dictionaries, grammar rules). No equations, parameters, or derivations are present that could reduce reported outcomes to inputs by construction. All performance claims rest on held-out translation metrics and model comparisons rather than any self-definition or fitted-input renaming. The pipeline is presented as a fixed preprocessing step whose accuracy is an external assumption, not a quantity derived from the results themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can follow and apply provided linguistic analyses when those analyses are supplied in the prompt.
Reference graph
Works this paper leans on
-
[1]
Nils Reimers and Iryna Gurevych
Unlocking reasoning capability on machine translation in large language models.Preprint, arXiv:2602.14763. Nils Reimers and Iryna Gurevych. 2019. Sentence- BERT: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics. Zhihong Shao...
-
[2]
He Zhou, Juyeon Chung, Sandra Kübler, and Francis Tyers
Hunyuan-mt technical report.Preprint, arXiv:2509.05209. He Zhou, Juyeon Chung, Sandra Kübler, and Francis Tyers. 2020. Universal Dependency treebank for Xibe. InProceedings of the Fourth Workshop on Uni- versal Dependencies (UDW 2020), pages 205–215, Barcelona, Spain (Online). Association for Computa- tional Linguistics. A Implementation Details Our exper...
-
[3]
The dictionary entry may contain mul- tiple possible meanings for a word; the specific lexical meaning in the context and its morphological features are al- ready explained in the reasoning steps
-
[4]
Based on the explanations of each word, and the final English translation of the whole sentence provided at the end of the reasoning steps, your task is to fill in each [Phrasal Translation] by combining the meanings of the words according to the syntactic relations ex- plained in the reasoning steps
-
[5]
Ensure consistency between the phrasal translation and the final English translation of the whole sentence
-
[6]
Preserve all original formatting, and keep all square brackets exactly as they appear
-
[7]
Do not add, remove, or modify any text outside of filling in the placeholders of [Phrasal Translation]
-
[8]
Do not include explanations, comments, or additional text
Return only the completed reasoning steps. Do not include explanations, comments, or additional text. Dictionary entries: {dictionary_entries} Reasoning steps with placeholders: {reasoning_steps_with_placeholders} Prompt for LLM to Fill in Placeholders (Lexical Meaning and Phrasal Translation) You are given dictionary entries for each individual word in a...
-
[9]
Use only the provided dictionary en- tries as your source of lexical mean- ings
-
[10]
If a dictionary entry contains multiple possible meanings, select the one that best fits the final English sentence pro- vided at the end of the reasoning steps
-
[11]
Ensure consistency between the cho- sen lexical meanings and the final sen- tence translation
-
[12]
Preserve all original formatting, and keep the square brackets after filling in the placeholders
-
[13]
Do not add, remove, or modify any text outside of filling in the placeholders
-
[14]
Do not include explanations, comments, or additional text
Return only the completed reasoning steps. Do not include explanations, comments, or additional text. Dictionary entries: {dictionary_entries} Reasoning steps with placeholders: {reasoning_steps_with_placeholders} 13 C.3 In-Context MT Prompts Baseline In-Context MT Prompt Please help me translate the following sen- tence from{source_lang}to English: {sour...
-
[15]
</think>
Step-by-step reasoning inside <think> ... </think>
-
[16]
</answer> Do not add any extra text outside these tags
The final English translation inside <answer> ... </answer> Do not add any extra text outside these tags. Remember your source sentence is: {source_sentence} +ReasoningIn-Context MT prompt Please help me translate the following sen- tence from{source_lang}to English: {source_sentence} Dictionary entries: {dictionary_entries} You are also given a linguisti...
-
[17]
Use the provided dictionary entries as the source of possible word meanings
-
[18]
Choose the meaning that best fits the local context
-
[19]
Use the word explanation immediately before the placeholder, including part of speech, lemma, morphology, case, tense, aspect, number, person, polarity, or other grammatical features
-
[20]
If the dictionary gives multiple mean- ings, prefer the one that is compatible with the morphological and syntactic explanation in the guide
-
[21]
In that case, try to guess the meaning based on the word form, the context, and the reasoning guide
Sometimes there is no dictionary entry for a word. In that case, try to guess the meaning based on the word form, the context, and the reasoning guide. It could be a proper noun, a loanword, a compound, or a typo. For each phrasal-translation placeholder, such as [Phrasal Translation 1]:
-
[22]
Combine meanings that have already been resolved in earlier placeholders
-
[23]
Use the syntactic relationship de- scribed in the guide to decide how the dependent combines with the head
-
[24]
Use word order, case marking, ad- positions, auxiliaries, modifiers, sub- jects, objects, clauses, and any pro- vided grammar notes. 14
-
[25]
Translate the whole subtree named in that line, not just the head word
-
[26]
Continue this bottom-up process until you reach [Final Translation]
Make the phrase meaning consistent with the meanings chosen for its com- ponent words. Continue this bottom-up process until you reach [Final Translation]. Important output requirements: Output first the completed linguistic rea- soning guide with all placeholders re- solved inside <completed_guide> ... </completed_guide>tags. Then output only the final E...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.