Online Learning with Gradient-Variation Interval Regret
Pith reviewed 2026-06-28 10:42 UTC · model grok-4.3
The pith
A two-layer ensemble is the first online algorithm whose interval regret scales with gradient variation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present the first online learning algorithm whose interval regret scales with gradient variation, achieved through a two-layer online ensemble structure. This bound simultaneously adapts to various problem-dependent quantities and preserves the minimax-optimal rate in the worst case. They further provide a Lipschitz- and smoothness-agnostic variant using a novel meta-algorithm, with implications for interval dynamic regret and stochastic optimization.
What carries the argument
The two-layer online ensemble structure that simultaneously adapts to gradient variation inside each interval and retains the minimax-optimal worst-case guarantee.
If this is right
- The same algorithm yields bounds on interval dynamic regret against changing comparators over arbitrary intervals.
- It supplies the first piecewise characterization of stochastic extended adversarial optimization.
- The Lipschitz- and smoothness-agnostic variant removes the need to tune to unknown constants while retaining the same scaling.
- The guarantees hold for both adversarial and stochastic settings through the gradient-variation measure.
Where Pith is reading between the lines
- The approach may simplify algorithm selection in environments whose gradient changes are moderate but unpredictable.
- It suggests that interval-based performance metrics can be handled by layering standard online methods rather than redesigning them from scratch.
- Similar two-layer constructions could be tested on other variation measures such as path length or comparator variation.
Load-bearing premise
It is possible to design and analyze a two-layer ensemble that adapts to gradient variation over intervals without sacrificing the minimax-optimal worst-case rate.
What would settle it
An explicit construction of an online problem in which every algorithm that achieves interval regret scaling with gradient variation must exceed the known minimax-optimal worst-case rate on some instance would falsify the claim.
Figures



read the original abstract
This paper investigates non-stationary online learning using the metric of interval regret, which requires an online algorithm to perform well over every time interval. We propose the first online learning algorithm that achieves an interval regret bound scaling with gradient variation, a fundamental measure of the cumulative change in online function gradients, which relates to various problem-dependent quantities and is closely connected to stochastic optimization and other problems. Our method employs a simple and efficient two-layer online ensemble structure that achieves strong theoretical guarantees. Specifically, it enjoys a regret bound that simultaneously adapts to various problem-dependent quantities while also preserving the minimax-optimal rate in the worst case. Moreover, recognizing the challenge of hyperparameter tuning, we introduce a Lipschitz- and smoothness-agnostic variant that automatically adapts to these potentially unknown constants. This is primarily enabled by a novel Lipschitz-adaptive meta algorithm, which may be of independent interest. Beyond interval regret, our method also yields broader implications: it provides versatile bounds for interval dynamic regret, a stronger measure that competes with changing comparators over any interval, and yields the first piecewise characterization for stochastic extended adversarial optimization. Theoretical findings are validated by experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the first online learning algorithm achieving interval regret bounds that scale with gradient variation, a measure of cumulative gradient change. It uses a two-layer online ensemble structure to simultaneously adapt to problem-dependent quantities while recovering the minimax-optimal worst-case rate. A novel Lipschitz- and smoothness-agnostic meta-algorithm enables automatic adaptation to unknown constants. The work also derives bounds for interval dynamic regret and provides the first piecewise characterization for stochastic extended adversarial optimization, with experimental validation.
Significance. If the central claims hold, this is a significant advance in non-stationary online learning by delivering the first explicit adaptation to gradient variation under the stronger interval-regret metric. The simple two-layer ensemble, the independent-interest meta-algorithm for Lipschitz adaptation, and the extensions to dynamic regret and stochastic settings are notable strengths. The absence of hidden assumptions or circular steps in the provided analysis further supports its value.
minor comments (3)
- [Abstract] Abstract: the phrase 'various problem-dependent quantities' is repeated without an early explicit list; a short enumeration (e.g., path length, variation, etc.) would improve readability.
- The description of the two-layer ensemble construction would benefit from an early high-level diagram or pseudocode block before the detailed regret analysis.
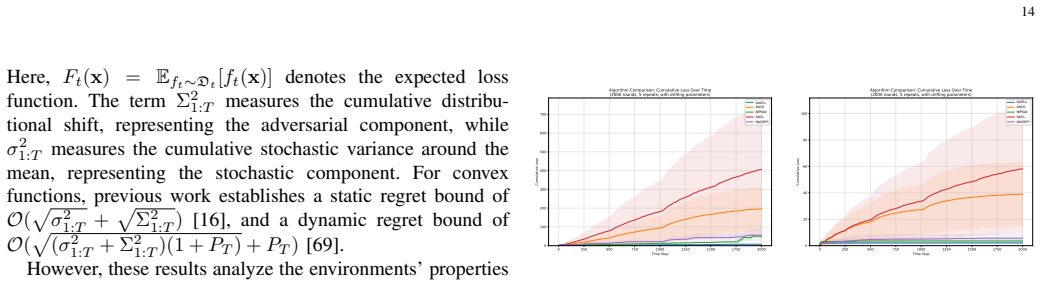
- Experiments: the baselines and hyperparameter ranges used for comparison could be stated more explicitly to facilitate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the recognition of its contributions, and the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces an explicit two-layer online ensemble construction together with a novel Lipschitz-adaptive meta-algorithm whose regret analysis directly yields the claimed interval-regret bound scaling with gradient variation while recovering the minimax rate. No equation reduces to a fitted input renamed as prediction, no load-bearing premise rests on a self-citation chain, and no ansatz is smuggled via prior work by the same authors. The central claims are therefore self-contained and externally falsifiable via the stated construction and analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Online convex programming and gener- alized infinitesimal gradient ascent,
M. Zinkevich, “Online convex programming and gener- alized infinitesimal gradient ascent,” inProceedings of the 20th International Conference on Machine Learning (ICML), 2003, pp. 928–936
2003
-
[2]
Introduction to Online Convex Optimization,
E. Hazan, “Introduction to Online Convex Optimization,” Foundations and Trends in Optimization, vol. 2, no. 3-4, pp. 157–325, 2016
2016
-
[3]
Strongly adaptive online learning,
A. Daniely, A. Gonen, and S. Shalev-Shwartz, “Strongly adaptive online learning,” inProceedings of the 32nd International Conference on Machine Learning (ICML), 2015, pp. 1405–1411
2015
-
[4]
Adaptive algorithms for online decision problems,
E. Hazan and C. Seshadhri, “Adaptive algorithms for online decision problems,”Electronic Colloquium on Computational Complexity (ECCC), vol. 14, no. 088, 2007
2007
-
[5]
Adaptive regret of convex and smooth functions,
L. Zhang, T.-Y . Liu, and Z.-H. Zhou, “Adaptive regret of convex and smooth functions,” inProceedings of the 36th International Conference on Machine Learning (ICML), 2019, pp. 7414–7423
2019
-
[6]
Parameter-free, dynamic, and strongly- adaptive online learning,
A. Cutkosky, “Parameter-free, dynamic, and strongly- adaptive online learning,” inProceedings of the 37th International Conference on Machine Learning (ICML), 2020, pp. 2250–2259
2020
-
[7]
Adap- tivity and non-stationarity: Problem-dependent dynamic regret for online convex optimization,
P. Zhao, Y .-J. Zhang, L. Zhang, and Z.-H. Zhou, “Adap- tivity and non-stationarity: Problem-dependent dynamic regret for online convex optimization,”Journal of Ma- chine Learning Research, vol. 25, no. 98, pp. 1 – 52, 2024
2024
-
[8]
Optimal stragies and minimax lower bounds for online convex games,
J. D. Abernethy, P. L. Bartlett, A. Rakhlin, and A. Tewari, “Optimal stragies and minimax lower bounds for online convex games,” inProceedings of the 21st Annual Con- ference on Learning Theory (COLT), 2008, pp. 415–424
2008
-
[9]
Smoothness, low noise and fast rates,
N. Srebro, K. Sridharan, and A. Tewari, “Smoothness, low noise and fast rates,” inAdvances in Neural Infor- mation Processing Systems 23 (NIPS), 2010, pp. 2199– 2207
2010
-
[10]
Beyond logarithmic bounds in online learning,
F. Orabona, N. Cesa-Bianchi, and C. Gentile, “Beyond logarithmic bounds in online learning,” inProceedings of the 15th International Conference on Artificial Intel- ligence and Statistics (AISTATS), 2012, pp. 823–831
2012
-
[11]
Online optimization with gradual variations,
C.-K. Chiang, T. Yang, C.-J. Lee, M. Mahdavi, C.-J. Lu, R. Jin, and S. Zhu, “Online optimization with gradual variations,” inProceedings of the 25th Conference On Learning Theory (COLT), 2012, pp. 6.1–6.20
2012
-
[12]
A simple yet universal strategy for online convex optimization,
L. Zhang, G. Wang, J. Yi, and T. Yang, “A simple yet universal strategy for online convex optimization,” inProceedings of the 39th International Conference on Machine Learning (ICML), 2022, pp. 26 605–26 623
2022
-
[13]
A simple and optimal approach for universal online learning with gra- dient variations,
Y .-H. Yan, P. Zhao, and Z.-H. Zhou, “A simple and optimal approach for universal online learning with gra- dient variations,” inAdvances in Neural Information Processing Systems 37 (NeurIPS), 2024, pp. 11 132– 11 163
2024
-
[14]
On the generalization ability of on-line learning algorithms,
N. Cesa-Bianchi, A. Conconi, and C. Gentile, “On the generalization ability of on-line learning algorithms,” IEEE Transactions on Information Theory, vol. 50, no. 9, pp. 2050–2057, 2004
2050
-
[15]
Information-theoretic lower bounds on the oracle complexity of stochastic convex optimization,
A. Agarwal, P. L. Bartlett, P. Ravikumar, and M. J. Wainwright, “Information-theoretic lower bounds on the oracle complexity of stochastic convex optimization,” 16 IEEE Transactions on Information Theory, vol. 58, no. 5, pp. 3235–3249, 2012
2012
-
[16]
Between stochastic and adversarial online convex op- timization: Improved regret bounds via smoothness,
S. Sachs, H. Hadiji, T. van Erven, and C. Guzm ´an, “Between stochastic and adversarial online convex op- timization: Improved regret bounds via smoothness,” in Advances in Neural Information Processing Systems 34 (NeurIPS), vol. 35, 2022, pp. 691–702
2022
-
[17]
Data-dependent bounds for online portfolio selection without lipschitzness and smoothness,
C. Tsai, Y . Lin, and Y . Li, “Data-dependent bounds for online portfolio selection without lipschitzness and smoothness,” inAdvances in Neural Information Pro- cessing Systems 36 (NeurIPS), 2023, pp. 62 764–62 791
2023
-
[18]
Online bilevel optimization: Regret analysis of online alternating gradient methods,
D. Ataee Tarzanagh, P. Nazari, B. Hou, L. Shen, and L. Balzano, “Online bilevel optimization: Regret analysis of online alternating gradient methods,” inProceedings of The 27th International Conference on Artificial Intel- ligence and Statistics (AISTATS), 2024, pp. 2854–2862
2024
-
[19]
An optimistic algo- rithm for online convex optimization with adversarial constraints,
J. Lekeufack and M. I. Jordan, “An optimistic algo- rithm for online convex optimization with adversarial constraints,”arXiv preprint arXiv:2412.08060, 2024
-
[20]
Online learning for changing environments using coin betting,
K.-S. Jun, F. Orabona, S. Wright, and R. Willett, “Online learning for changing environments using coin betting,” Electronic Journal of Statistics, vol. 11, no. 2, pp. 5282– 5310, 2017
2017
-
[21]
Efficient methods for non-stationary online learning,
P. Zhao, Y .-F. Xie, L. Zhang, and Z.-H. Zhou, “Efficient methods for non-stationary online learning,” inAdvances in Neural Information Processing Systems 35 (NeurIPS), 2022, pp. 11 573–11 585
2022
-
[22]
Minimizing dynamic regret and adaptive regret simultaneously,
L. Zhang, S. Lu, and T. Yang, “Minimizing dynamic regret and adaptive regret simultaneously,” inProceed- ings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), 2020, pp. 309–319
2020
-
[23]
Efficient methods for non-stationary online learning,
P. Zhao, Y .-F. Xie, L. Zhang, and Z.-H. Zhou, “Efficient methods for non-stationary online learning,”Journal of Machine Learning Research, pp. 1 – 66, 2025
2025
-
[24]
The weighted major- ity algorithm,
N. Littlestone and M. K. Warmuth, “The weighted major- ity algorithm,”Information and Computation, vol. 108, no. 2, pp. 212–261, 1994
1994
-
[25]
A closer look at adaptive regret,
D. Adamskiy, W. M. Koolen, A. V . Chernov, and V . V ovk, “A closer look at adaptive regret,” inProceedings of the 23rd International Conference on Algorithmic Learning Theory (ALT), 2012, pp. 290–304
2012
-
[26]
Mirror descent meets fixed share (and feels no regret),
N. Cesa-Bianchi, P. Gaillard, G. Lugosi, and G. Stoltz, “Mirror descent meets fixed share (and feels no regret),” inAdvances in Neural Information Processing Systems 25 (NIPS), 2012, pp. 989–997
2012
-
[27]
Coin betting and parameter- free online learning,
F. Orabona and D. P ´al, “Coin betting and parameter- free online learning,” inAdvances in Neural Information Processing Systems 29 (NIPS), 2016, pp. 577–585
2016
-
[28]
Non-stationary stochastic optimization,
O. Besbes, Y . Gur, and A. J. Zeevi, “Non-stationary stochastic optimization,”Operations Research, vol. 63, no. 5, pp. 1227–1244, 2015
2015
-
[29]
Online optimization: Competing with dynamic comparators,
A. Jadbabaie, A. Rakhlin, S. Shahrampour, and K. Srid- haran, “Online optimization: Competing with dynamic comparators,” inProceedings of the 18th International Conference on Artificial Intelligence and Statistics (AIS- TATS), 2015, pp. 398–406
2015
-
[30]
Efficient tracking of large classes of experts,
A. Gy ¨orgy, T. Linder, and G. Lugosi, “Efficient tracking of large classes of experts,”IEEE Transactions on Infor- mation Theory, vol. 58, no. 11, pp. 6709–6725, 2012
2012
-
[31]
Shifting regret, mirror descent, and matrices,
A. Gy ¨orgy and C. Szepesv ´ari, “Shifting regret, mirror descent, and matrices,” inProceedings of the 33nd Inter- national Conference on Machine Learning (ICML), 2016, pp. 2943–2951
2016
-
[32]
Adaptive online learn- ing in dynamic environments,
L. Zhang, S. Lu, and Z.-H. Zhou, “Adaptive online learn- ing in dynamic environments,” inAdvances in Neural Information Processing Systems 31 (NeurIPS), 2018, pp. 1330–1340
2018
-
[34]
Dy- namic regret via discounted-to-dynamic reduction with applications to curved losses and adam optimizer,
Y .-F. Xie, Y .-J. Zhang, P. Zhao, and Z.-H. Zhou, “Dy- namic regret via discounted-to-dynamic reduction with applications to curved losses and adam optimizer,” in Proceedings of the 43rd International Conference on Machine Learning (ICML), 2026, p. to appear
2026
-
[35]
Scale-free online learning,
F. Orabona and D. P ´al, “Scale-free online learning,” Theoretical Computer Science, vol. 716, pp. 50–69, 2018
2018
-
[36]
Dy- namic regret of convex and smooth functions,
P. Zhao, Y .-J. Zhang, L. Zhang, and Z.-H. Zhou, “Dy- namic regret of convex and smooth functions,” inAd- vances in Neural Information Processing Systems 33 (NeurIPS), 2020, pp. 12 510–12 520
2020
-
[37]
Universal online learning with gradient variations: A multi-layer online ensemble approach,
Y .-H. Yan, P. Zhao, and Z.-H. Zhou, “Universal online learning with gradient variations: A multi-layer online ensemble approach,” inAdvances in Neural Information Processing Systems 36 (NeurIPS), 2023, pp. 37 682– 37 715
2023
-
[38]
Gradient-variation online learning under generalized smoothness,
Y .-F. Xie, P. Zhao, and Z.-H. Zhou, “Gradient-variation online learning under generalized smoothness,” inAd- vances in Neural Information Processing Systems 37 (NeurIPS), 2024, pp. 37 865–37 899
2024
-
[39]
Improved dimension dependence for bandit convex optimization with gradient variations,
H. Yu, Y .-H. Yan, and P. Zhao, “Improved dimension dependence for bandit convex optimization with gradient variations,” inProceedings of the 43rd International Conference on Machine Learning (ICML), 2026, p. to appear
2026
-
[40]
Gradient-variation regret bounds for unconstrained on- line learning,
Y . Zhao, A. Jacobsen, N. Cesa-Bianchi, and P. Zhao, “Gradient-variation regret bounds for unconstrained on- line learning,” inProceedings of the 39th Annual Con- ference on Learning Theory (COLT), 2026, p. to appear
2026
-
[41]
Fast convergence of regularized learning in games,
V . Syrgkanis, A. Agarwal, H. Luo, and R. E. Schapire, “Fast convergence of regularized learning in games,” in Advances in Neural Information Processing Systems 28 (NIPS), 2015, pp. 2989–2997
2015
-
[42]
No-regret learning in time-varying zero-sum games,
M. Zhang, P. Zhao, H. Luo, and Z.-H. Zhou, “No-regret learning in time-varying zero-sum games,” inProceed- ings of the 39th International Conference on Machine Learning (ICML), 2022, pp. 26 772–26 808
2022
-
[43]
Unixgrad: A universal, adaptive algorithm with optimal guarantees for constrained optimization,
A. Kavis, K. Y . Levy, F. R. Bach, and V . Cevher, “Unixgrad: A universal, adaptive algorithm with optimal guarantees for constrained optimization,” inAdvances in Neural Information Processing Systems 32 (NeurIPS), 2019, pp. 6257–6266
2019
-
[44]
A simpler approach to accelerated optimization: iterative averaging meets optimism,
P. Joulani, A. Raj, A. Gy ¨orgy, and C. Szepesv ´ari, “A simpler approach to accelerated optimization: iterative averaging meets optimism,” inProceedings of the 37th 17 International Conference on Machine Learning (ICML), 2020, pp. 4984–4993
2020
-
[45]
Gradient- variation online adaptivity for accelerated optimization with H ¨older smoothness,
Y . Zhao, Y .-H. Yan, K. Y . Levy, and P. Zhao, “Gradient- variation online adaptivity for accelerated optimization with H ¨older smoothness,” inAdvances in Neural In- formation Processing Systems 38 (NeurIPS), 2025, pp. 3749–3779
2025
-
[46]
Black-box reductions for parameter-free online learning in banach spaces,
A. Cutkosky and F. Orabona, “Black-box reductions for parameter-free online learning in banach spaces,” in Proceedings of the 31st Conference on Learning Theory (COLT), 2018, pp. 1493–1529
2018
-
[47]
Implicit parameter-free online learning with truncated linear mod- els,
K. Chen, A. Cutkosky, and F. Orabona, “Implicit parameter-free online learning with truncated linear mod- els,” inProceedings of the 33rd International Conference on Algorithmic Learning Theory (ALT), 2022, pp. 148– 175
2022
-
[48]
Artificial constraints and hints for un- bounded online learning,
A. Cutkosky, “Artificial constraints and hints for un- bounded online learning,” inProceedings of the 32nd Annual Conference Computational Learning Theory (COLT), 2019, pp. 874–894
2019
-
[49]
Lip- schitz adaptivity with multiple learning rates in online learning,
Z. Mhammedi, W. M. Koolen, and T. van Erven, “Lip- schitz adaptivity with multiple learning rates in online learning,” inProceedings of the 32nd Annual Confer- ence Computational Learning Theory (COLT), 2019, pp. 2490–2511
2019
-
[50]
Parameter-free mirror descent,
A. Jacobsen and A. Cutkosky, “Parameter-free mirror descent,” inProceedings of the 35th Conference on Learning Theory (COLT), 2022, pp. 4160–4211
2022
-
[51]
Unconstrained online learning with unbounded losses,
——, “Unconstrained online learning with unbounded losses,” inProceedings of the 40th International Confer- ence on Machine Learning (ICML), 2023, pp. 14 590– 14 630
2023
-
[52]
Lipschitz and comparator-norm adaptivity in online learning,
Z. Mhammedi and W. M. Koolen, “Lipschitz and comparator-norm adaptivity in online learning,” inPro- ceedings of the 33th Conference on Learning Theory (COLT), 2020, pp. 2858–2887
2020
-
[53]
Impossible tuning made possible: A new expert algorithm and its applications,
L. Chen, H. Luo, and C. Wei, “Impossible tuning made possible: A new expert algorithm and its applications,” in Proceedings of the 34th Conference on Learning Theory (COLT), 2021, pp. 1216–1259
2021
-
[54]
Regret bounds for log-loss via bayesian algorithms,
C. Wu, M. Heidari, A. Grama, and W. Szpankowski, “Regret bounds for log-loss via bayesian algorithms,” IEEE Transactions on Information Theory, vol. 69, no. 9, pp. 5971–5989, 2023
2023
-
[55]
Parameter- free algorithms for the stochastically extended adversarial model,
S. Wang, A. Barik, P. Zhao, and V . Y . F. Tan, “Parameter- free algorithms for the stochastically extended adversarial model,” inAdvances in Neural Information Processing Systems 38 (NeurIPS), 2025, pp. 64 068–64 102
2025
-
[56]
Online Learning and Online Con- vex Optimization,
S. Shalev-Shwartz, “Online Learning and Online Con- vex Optimization,”Foundations and Trends in Machine Learning, vol. 4, no. 2, pp. 107–194, 2012
2012
-
[57]
Online learning with predictable sequences,
A. Rakhlin and K. Sridharan, “Online learning with predictable sequences,” inProceedings of the 26th Con- ference On Learning Theory (COLT), 2013, pp. 993– 1019
2013
-
[58]
Using and combining predictors that specialize,
Y . Freund, R. E. Schapire, Y . Singer, and M. K. Warmuth, “Using and combining predictors that specialize,” in Proceedings of the 29th Annual ACM Symposium on the Theory of Computing (STOC), 1997, pp. 334–343
1997
-
[59]
Achieving all with no parameters: AdaNormalHedge,
H. Luo and R. E. Schapire, “Achieving all with no parameters: AdaNormalHedge,” inProceedings of the 28th Annual Conference Computational Learning Theory (COLT), 2015, pp. 1286–1304
2015
-
[60]
Tracking the best expert in non-stationary stochastic environments,
C.-Y . Wei, Y .-T. Hong, and C.-J. Lu, “Tracking the best expert in non-stationary stochastic environments,” inAdvances in Neural Information Processing Systems 29 (NIPS), 2016, pp. 3972–3980
2016
-
[61]
A second-order bound with excess losses,
P. Gaillard, G. Stoltz, and T. van Erven, “A second-order bound with excess losses,” inProceedings of the 27th Conference on Learning Theory (COLT), 2014, pp. 176– 196
2014
-
[62]
Nesterov,Lectures on Convex Optimization
Y . Nesterov,Lectures on Convex Optimization. Springer, 2018, vol. 137
2018
-
[63]
Improved second-order bounds for prediction with expert advice,
N. Cesa-Bianchi, Y . Mansour, and G. Stoltz, “Improved second-order bounds for prediction with expert advice,” inProceedings of the 18th Annual Conference on Learn- ing Theory (COLT), 2005, pp. 217–232
2005
-
[64]
Aggregating strategies,
V . G. V ovk, “Aggregating strategies,” inProceedings of the 3rd Annual Workshop on Computational Learning Theory (COLT), 1990, pp. 371–386
1990
-
[65]
Open-environment machine learning,
Z.-H. Zhou, “Open-environment machine learning,”Na- tional Science Review, vol. 9, no. 8, p. nwac123, 2022
2022
-
[66]
On the encryption for graph foundation model inference of sparse graph,
M.-J. Yuan, X.-T. Bai, K.-R. Zhang, and W. Gao, “On the encryption for graph foundation model inference of sparse graph,”Science China: Information Sciences, vol. 68, p. 160104, 2025
2025
-
[67]
Dynamic regret of strongly adaptive methods,
L. Zhang, T. Yang, R. Jin, and Z.-H. Zhou, “Dynamic regret of strongly adaptive methods,” inProceedings of the 35th International Conference on Machine Learning (ICML), 2018, pp. 5877–5886
2018
-
[68]
Online convex optimisation: The optimal switching re- gret for all segmentations simultaneously,
S. Pasteris, C. Hicks, V . Mavroudis, and M. Herbster, “Online convex optimisation: The optimal switching re- gret for all segmentations simultaneously,” inAdvances in Neural Information Processing Systems 36 (NeurIPS), 2024
2024
-
[69]
Optimistic online mirror descent for bridging stochastic and adversarial online convex optimization,
S. Chen, Y .-J. Zhang, W.-W. Tu, P. Zhao, and L. Zhang, “Optimistic online mirror descent for bridging stochastic and adversarial online convex optimization,”Journal of Machine Learning Research, vol. 25, no. 178, pp. 1 – 62, 2024
2024
-
[70]
The mnist database of handwritten digit im- ages for machine learning research,
L. Deng, “The mnist database of handwritten digit im- ages for machine learning research,”IEEE Signal Pro- cessing Magazine, vol. 29, no. 6, pp. 141–142, 2012
2012
-
[71]
Adaptive and self-confident on-line learning algorithms,
P. Auer, N. Cesa-Bianchi, and C. Gentile, “Adaptive and self-confident on-line learning algorithms,”Journal of Computer and System Sciences, vol. 64, no. 1, pp. 48–75, 2002. 18 APPENDIXA PROOF OFSECTIONIV This section proves the main results stated in Section IV. The central step is to establish the gradient-variation interval regret bound in Theorem 1 un...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.