Knowledge Editing in Masked Diffusion Language Models
Pith reviewed 2026-06-28 09:49 UTC · model grok-4.3
The pith
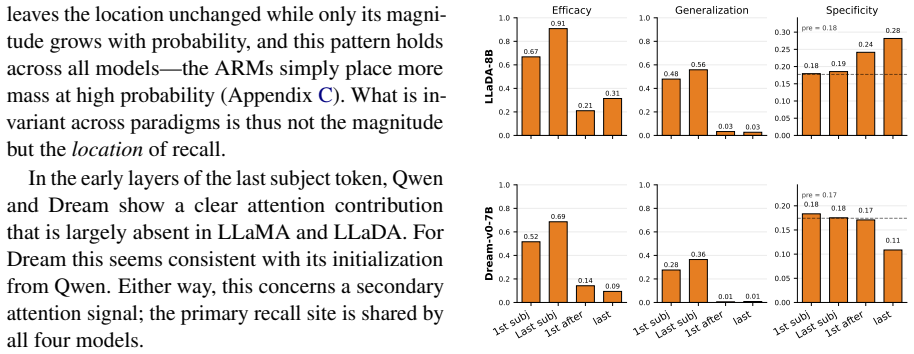
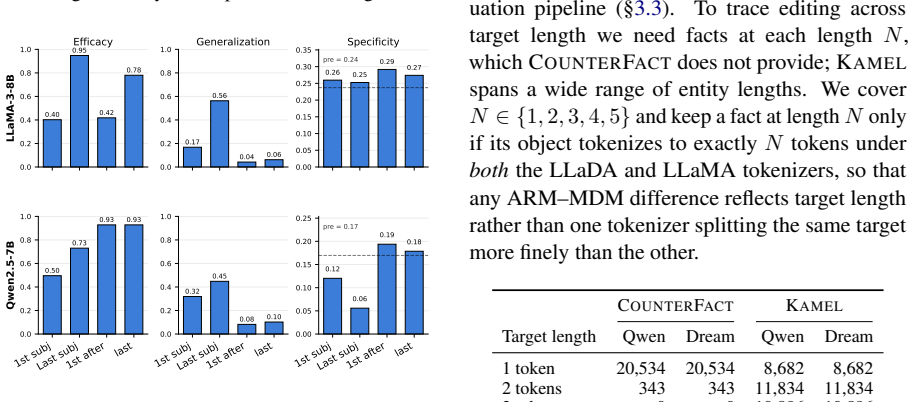
The same early-to-mid MLP at the last subject token is the best edit site for facts in both masked diffusion and autoregressive language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
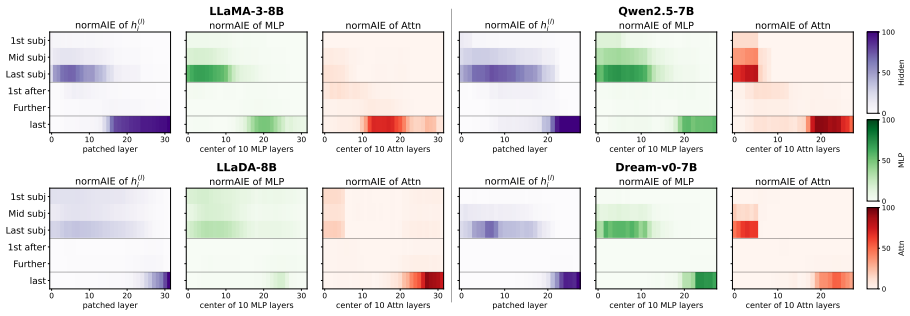
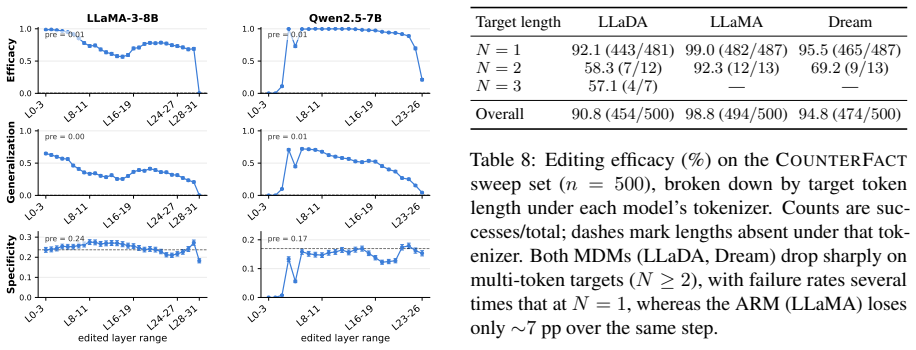
Causal tracing identifies the same early-to-mid-layer MLP at the last subject token as the most effective edit site in both MDMs and ARMs. Single-token edits succeed equally in the two families, yet multi-token targets degrade in MDMs because generation requires the model to produce the target through partially unmasked intermediate states for which the edit was never optimized. Optimizing the edit directly over those states restores most of the lost performance.
What carries the argument
Causal tracing to locate the edit site, followed by locate-then-edit weight updates adapted to the iterative denoising trajectory of masked diffusion models.
If this is right
- The same causal-tracing procedure can be used to locate edit sites across autoregressive and masked diffusion families.
- Single-token factual updates transfer directly once the shared location is used.
- Multi-token edits in diffusion models require an auxiliary optimization pass over the denoising trajectory.
- The location of stored facts is more stable across generation paradigms than the generation process itself.
Where Pith is reading between the lines
- Editing methods developed for next-token models may need trajectory-aware corrections whenever generation is iterative or bidirectional.
- The shared location suggests that fact storage is largely independent of whether a model predicts tokens sequentially or denoises masks.
- The same correction could be tested on other non-autoregressive generators that rely on intermediate partially observed states.
Load-bearing premise
The performance gap on multi-token targets is caused by the need to generate through partially unmasked states that were never seen during the edit, rather than by other differences between the model families.
What would settle it
If applying the extra optimization over intermediate denoising states still leaves a large multi-token performance gap between the MDMs and the matched ARMs, the claimed cause would be falsified.
Figures

read the original abstract
Knowledge editing aims to update or correct factual knowledge in a language model. A widely used approach, locate-then-edit, does this in two steps: it first localizes a fact within the model, then edits the weights there. To date, such methods have been developed exclusively on autoregressive models (ARMs). Whether their underlying assumptions hold for masked diffusion models (MDMs), which model text bidirectionally and generate by iterative denoising rather than next-token prediction, remains an open question. We address it by transferring locate-then-edit to MDMs and comparing two MDMs (LLaDA, Dream) with two ARMs (LLaMA, Qwen) at matched scale. Our central finding has two parts. First, where an edit is applied transfers across paradigms: causal tracing highlights the same early-to-mid-layer MLP at the last subject token in both, and editing is most effective there. Second, this shared location does not guarantee a shared outcome. Single-token edits succeed in both, but as targets grow longer, editing degrades systematically in the MDMs but not the ARMs. The failure stems from how the edited fact is generated: producing a multi-token target requires passing through partially unmasked intermediate states for which the edit was never optimized. Guided by this diagnosis, we introduce a simple correction that optimizes the edit for these states, substantially restoring multi-token performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether locate-then-edit knowledge editing, previously developed only for autoregressive models (ARMs), transfers to masked diffusion models (MDMs). Using causal tracing on matched-scale models (LLaDA/Dream vs. LLaMA/Qwen), it finds that the effective edit location (early-to-mid-layer MLP at the last subject token) is shared across paradigms. Single-token edits succeed in both, but multi-token targets degrade in MDMs because generation requires passing through partially unmasked intermediate states never seen during editing; a proposed correction optimizes the edit for these states and restores performance.
Significance. If the empirical results hold after addressing the noted gaps, the work would usefully extend locate-then-edit methods to the MDM paradigm and supply a concrete mechanistic account of why multi-token editing behaves differently under iterative denoising. The shared location finding and the practical correction are the most immediately actionable contributions.
major comments (2)
- [Abstract and experimental sections] Abstract and the experimental comparison (LLaDA/Dream vs. LLaMA/Qwen): the central diagnosis that multi-token degradation arises specifically because the edited fact must be generated through partially unmasked intermediate states is not isolated from other uncontrolled differences between the model families (bidirectional vs. unidirectional attention, pretraining objectives, data mixtures). No ablation holds architecture and training fixed while varying only the denoising schedule, so the hypothesized mechanism remains the least secured link in the argument.
- [Method / correction description] The introduced correction is reported to restore multi-token performance, yet the manuscript provides no direct test (e.g., an ablation that applies the correction only to the hypothesized states versus other interventions) showing that the improvement occurs via the claimed mechanism rather than by compensating for any of the other architectural mismatches.
minor comments (2)
- [Abstract] The abstract states clear empirical findings but supplies no quantitative numbers, error bars, dataset sizes, or ablation controls; readers must reach the full experimental sections to evaluate effect sizes.
- [Method] Notation for the locate-then-edit procedure and the new correction should be introduced with explicit equations or pseudocode to make the optimization over intermediate states fully reproducible from the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to better isolate the proposed mechanism. We respond point-by-point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and experimental sections] Abstract and the experimental comparison (LLaDA/Dream vs. LLaMA/Qwen): the central diagnosis that multi-token degradation arises specifically because the edited fact must be generated through partially unmasked intermediate states is not isolated from other uncontrolled differences between the model families (bidirectional vs. unidirectional attention, pretraining objectives, data mixtures). No ablation holds architecture and training fixed while varying only the denoising schedule, so the hypothesized mechanism remains the least secured link in the argument.
Authors: We agree that the comparison across model families leaves the denoising schedule confounded with attention directionality, pretraining objectives, and data. The shared early-to-mid MLP location is nevertheless observed despite these differences. Fully isolating the iterative denoising effect would require training otherwise identical models that differ only in generation procedure, which exceeds the scope of the present study. In the revision we will add an explicit limitations paragraph qualifying the mechanistic claim and noting the absence of such a controlled ablation. revision: partial
-
Referee: [Method / correction description] The introduced correction is reported to restore multi-token performance, yet the manuscript provides no direct test (e.g., an ablation that applies the correction only to the hypothesized states versus other interventions) showing that the improvement occurs via the claimed mechanism rather than by compensating for any of the other architectural mismatches.
Authors: The correction is derived directly from the partial-mask states that arise only under MDM generation; its benefit is confined to multi-token targets in the MDM setting. We acknowledge, however, that the manuscript lacks an explicit ablation pitting the correction against generic interventions that do not target those states. In revision we will expand the method description to clarify the motivation and, space permitting, add a supplementary comparison in the appendix. revision: partial
Circularity Check
No significant circularity; claims rest on empirical transfer and comparisons
full rationale
The paper transfers causal tracing and locate-then-edit from prior external work, performs cross-paradigm experiments on matched-scale models, and diagnoses multi-token degradation via observed generation process in MDMs. No equations, fitted parameters, or self-citations are shown to reduce the central claims (location transfer or state-specific degradation) to inputs by construction. The derivation chain is self-contained against external benchmarks and does not invoke any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal tracing identifies the causal site of factual knowledge storage in the model weights
Reference graph
Works this paper leans on
-
[1]
On Faithfulness and Factuality in Abstractive Summarization
Maynez, Joshua and Narayan, Shashi and Bohnet, Bernd and McDonald, Ryan. On Faithfulness and Factuality in Abstractive Summarization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.173
-
[4]
2024 , eprint=
A Comprehensive Study of Knowledge Editing for Large Language Models , author=. 2024 , eprint=
2024
-
[5]
2025 , eprint=
Scaling Laws for Forgetting during Finetuning with Pretraining Data Injection , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning , author=. 2025 , eprint=
2025
-
[8]
2024 , eprint=
Knowledge Editing for Large Language Models: A Survey , author=. 2024 , eprint=
2024
-
[9]
Automated Knowledge Base Construction , year=
KAMEL: Knowledge Analysis with Multitoken Entities in Language Models , author=. Automated Knowledge Base Construction , year=
-
[10]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[11]
The Eleventh International Conference on Learning Representations (ICLR) , year=
Mass Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations (ICLR) , year=
-
[12]
The Thirteenth International Conference on Learning Representations , year=
AlphaEdit: Null-Space Constrained Model Editing for Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[14]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[17]
Correlation Matrix Memories , year=
Kohonen, Teuvo , journal=. Correlation Matrix Memories , year=
-
[19]
Knowledge Editing in Language Models , author=
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models , author=. 2023 , eprint=
2023
-
[20]
2024 , eprint=
Is Bigger Edit Batch Size Always Better? -- An Empirical Study on Model Editing with Llama-3 , author=. 2024 , eprint=
2024
-
[21]
2023 , eprint=
Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors , author=. 2023 , eprint=
2023
-
[22]
2024 , eprint=
PMET: Precise Model Editing in a Transformer , author=. 2024 , eprint=
2024
-
[23]
2026 , eprint=
Diffusion-Inspired Masked Fine-Tuning for Knowledge Injection in Autoregressive LLMs , author=. 2026 , eprint=
2026
-
[24]
2025 , eprint=
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Masks Can Be Distracting: On Context Comprehension in Diffusion Language Models , author=. 2025 , eprint=
2025
-
[26]
2026 , eprint=
DLM-Scope: Mechanistic Interpretability of Diffusion Language Models via Sparse Autoencoders , author=. 2026 , eprint=
2026
-
[27]
International Conference on Learning Representations , year=
Towards Continual Knowledge Learning of Language Models , author=. International Conference on Learning Representations , year=
-
[28]
2020 , eprint=
Modifying Memories in Transformer Models , author=. 2020 , eprint=
2020
-
[29]
2025 , eprint=
LLaDA-MoE: A Sparse MoE Diffusion Language Model , author=. 2025 , eprint=
2025
-
[31]
International Conference on Learning Representations , year=
Fast Model Editing at Scale , author=. International Conference on Learning Representations , year=
-
[32]
2022 , eprint=
Memory-Based Model Editing at Scale , author=. 2022 , eprint=
2022
-
[34]
2026 , url=
Haewon Park and Sangwoo Kim and Yohan Jo , booktitle=. 2026 , url=
2026
-
[35]
2024 , eprint=
A Unified Framework for Model Editing , author=. 2024 , eprint=
2024
-
[36]
James A. Anderson. 1972. https://doi.org/10.1016/0025-5564(72)90075-2 A simple neural network generating an interactive memory . Mathematical Biosciences, 14(3):197--220
-
[37]
Louis Bethune, David Grangier, Dan Busbridge, Eleonora Gualdoni, Marco Cuturi, and Pierre Ablin. 2025. https://arxiv.org/abs/2502.06042 Scaling laws for forgetting during finetuning with pretraining data injection . Preprint, arXiv:2502.06042
arXiv 2025
-
[38]
Nicola De Cao, Wilker Aziz, and Ivan Titov. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.522 Editing factual knowledge in language models . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6491--6506, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics
-
[39]
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Jie Shi, Xiang Wang, Xiangnan He, and Tat-Seng Chua. 2025. https://openreview.net/forum?id=HvSytvg3Jh Alphaedit: Null-space constrained model editing for language models . In The Thirteenth International Conference on Learning Representations
2025
-
[40]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 31 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3 ...
Pith/arXiv arXiv 2024
-
[41]
Akshat Gupta, Dev Sajnani, and Gopala Anumanchipalli. 2024. https://arxiv.org/abs/2403.14236 A unified framework for model editing . Preprint, arXiv:2403.14236
arXiv 2024
-
[42]
Thomas Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Yoon Kim, and Marzyeh Ghassemi. 2023. https://arxiv.org/abs/2211.11031 Aging with grace: Lifelong model editing with discrete key-value adaptors . Preprint, arXiv:2211.11031
arXiv 2023
-
[43]
Peter Hase, Mohit Bansal, Been Kim, and Asma Ghandeharioun. 2023. https://arxiv.org/abs/2301.04213 Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models . Preprint, arXiv:2301.04213
arXiv 2023
-
[44]
Joel Jang, Seonghyeon Ye, Sohee Yang, Joongbo Shin, Janghoon Han, Gyeonghun KIM, Stanley Jungkyu Choi, and Minjoon Seo. 2022. https://openreview.net/forum?id=vfsRB5MImo9 Towards continual knowledge learning of language models . In International Conference on Learning Representations
2022
-
[45]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. https://doi.org/10.1145/3571730 Survey of hallucination in natural language generation . ACM Comput. Surv., 55(12)
-
[46]
Jan-Christoph Kalo and Leandra Fichtel. 2022. Kamel: Knowledge analysis with multitoken entities in language models. In Automated Knowledge Base Construction
2022
-
[47]
Teuvo Kohonen. 1972. https://doi.org/10.1109/TC.1972.5008975 Correlation matrix memories . IEEE Transactions on Computers, C-21(4):353--359
-
[48]
Xiaopeng Li, Shasha Li, Shezheng Song, Jing Yang, Jun Ma, and Jie Yu. 2024. https://arxiv.org/abs/2308.08742 Pmet: Precise model editing in a transformer . Preprint, arXiv:2308.08742
arXiv 2024
-
[49]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://doi.org/10.18653/v1/2022.acl-long.229 T ruthful QA : Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
-
[50]
Xiaoran Liu, Yuerong Song, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. 2025. https://arxiv.org/abs/2506.14429 Longllada: Unlocking long context capabilities in diffusion llms . Preprint, arXiv:2506.14429
arXiv 2025
-
[51]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2025. https://arxiv.org/abs/2308.08747 An empirical study of catastrophic forgetting in large language models during continual fine-tuning . Preprint, arXiv:2308.08747
Pith/arXiv arXiv 2025
-
[52]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2023 a . https://arxiv.org/abs/2202.05262 Locating and editing factual associations in gpt . Preprint, arXiv:2202.05262
Pith/arXiv arXiv 2023
-
[53]
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. 2023 b . Mass editing memory in a transformer. The Eleventh International Conference on Learning Representations (ICLR)
2023
-
[54]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. 2022 a . https://openreview.net/forum?id=0DcZxeWfOPt Fast model editing at scale . In International Conference on Learning Representations
2022
-
[55]
Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D. Manning, and Chelsea Finn. 2022 b . https://arxiv.org/abs/2206.06520 Memory-based model editing at scale . Preprint, arXiv:2206.06520
arXiv 2022
-
[56]
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2025. https://arxiv.org/abs/2502.09992 Large language diffusion models . Preprint, arXiv:2502.09992
Pith/arXiv arXiv 2025
-
[57]
Xu Pan, Ely Hahami, Jingxuan Fan, Ziqian Xie, and Haim Sompolinsky. 2026. https://arxiv.org/abs/2510.09885 Diffusion-inspired masked fine-tuning for knowledge injection in autoregressive llms . Preprint, arXiv:2510.09885
Pith/arXiv arXiv 2026
-
[58]
Haewon Park, Sangwoo Kim, and Yohan Jo. 2026. https://openreview.net/forum?id=qz3BkyyHWJ SUIT : Knowledge editing with subspace-aware key-value mappings . In The Fourteenth International Conference on Learning Representations
2026
-
[59]
Julianna Piskorz, Cristina Pinneri, Alvaro Correia, Motasem Alfarra, Risheek Garrepalli, and Christos Louizos. 2025. https://arxiv.org/abs/2511.21338 Masks can be distracting: On context comprehension in diffusion language models . Preprint, arXiv:2511.21338
Pith/arXiv arXiv 2025
-
[60]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
Pith/arXiv arXiv 2025
-
[61]
Peng Wang, Ningyu Zhang, Bozhong Tian, Zekun Xi, Yunzhi Yao, Ziwen Xu, Mengru Wang, Shengyu Mao, Xiaohan Wang, Siyuan Cheng, Kangwei Liu, Yuansheng Ni, Guozhou Zheng, and Huajun Chen. 2024 a . https://doi.org/10.18653/v1/2024.acl-demos.9 E asy E dit: An easy-to-use knowledge editing framework for large language models . In Proceedings of the 62nd Annual M...
-
[62]
Song Wang, Yaochen Zhu, Haochen Liu, Zaiyi Zheng, Chen Chen, and Jundong Li. 2024 b . https://arxiv.org/abs/2310.16218 Knowledge editing for large language models: A survey . Preprint, arXiv:2310.16218
arXiv 2024
-
[63]
Xu Wang, Bingqing Jiang, Yu Wan, Baosong Yang, Lingpeng Kong, and Difan Zou. 2026. https://arxiv.org/abs/2602.05859 Dlm-scope: Mechanistic interpretability of diffusion language models via sparse autoencoders . Preprint, arXiv:2602.05859
arXiv 2026
-
[64]
Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.632 Editing large language models: Problems, methods, and opportunities . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10222--10240, Singapore. Assoc...
-
[65]
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2025. Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487
Pith/arXiv arXiv 2025
-
[66]
Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh Bhojanapalli, Daliang Li, Felix Yu, and Sanjiv Kumar. 2020. https://arxiv.org/abs/2012.00363 Modifying memories in transformer models . Preprint, arXiv:2012.00363
arXiv 2020
-
[67]
Fengqi Zhu, Zebin You, Yipeng Xing, Zenan Huang, Lin Liu, Yihong Zhuang, Guoshan Lu, Kangyu Wang, Xudong Wang, Lanning Wei, Hongrui Guo, Jiaqi Hu, Wentao Ye, Tieyuan Chen, Chenchen Li, Chengfu Tang, Haibo Feng, Jun Hu, Jun Zhou, and 7 others. 2025. https://arxiv.org/abs/2509.24389 Llada-moe: A sparse moe diffusion language model . Preprint, arXiv:2509.24389
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.