MLSkip: Data Skipping for ML Filters via Lightweight Metadata
Pith reviewed 2026-06-28 07:42 UTC · model grok-4.3
The pith
Parquet min-max metadata enables pruning of row groups for machine learning filter predicates via neural network verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that min-max metadata already stored in Parquet files can be fed into neural network verification procedures to decide whether an entire row group can be pruned for a ReLU neural network acting as a filter predicate. On tables from standard benchmarks this yields 27.4% average pruning for filters with selectivity under 0.1%. Replacing or augmenting the metadata with a size-bounded two-dimensional convex hull raises pruning effectiveness to 38.31% at a cost of no more than 45 bytes per row group and column pair.
What carries the argument
Neural network verification applied to Parquet min-max metadata (and an enhanced 2D convex hull) to determine row-group pruning for ML filters.
Load-bearing premise
The time required to run verification on the metadata must remain smaller than the time saved by avoiding model evaluations on pruned row groups.
What would settle it
Compare the wall-clock time of verification plus model evaluation on remaining groups against the time of model evaluation on all groups for the same query.
Figures

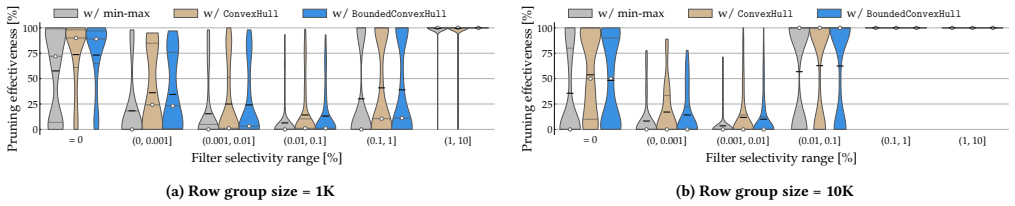
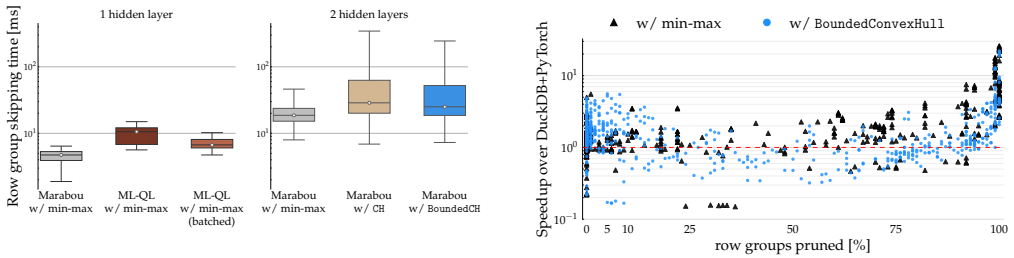
read the original abstract
Database vendors recently released AI functions that can be used in filter predicates. As such functions often rely on costly, black-box ML models, they unveil new data management challenges. Concretely, traditional data skipping techniques for integer and string data fail to be applicable to the new filter type. Indeed, there is no known mechanism for pruning non-qualifying row groups, e.g., when reading files from blob storage. In this work, we initiate the study of data skipping techniques for ML filters. We make the case that Parquet's default min-max metadata is enough to enable pruning. To this end, we draw connections to two lines of research: (i) the recently proposed query language for ML models and (ii) neural network verification. Our preliminary results on ReLU architectures show that on tables from TPC-H and TPC-DS, the average pruning effectiveness for filters of selectivity below 0.1% amounts to 27.4%. Finally, inspired by research on spatial joins, we propose an enhanced metadata structure: a size-bounded 2D convex hull that verification tools can make better use of, increasing the pruning effectiveness to 38.31%, while occupying at most 45 bytes per row group and column pair. We observe an end-to-end speedup of 1.07$\times$ over PyTorch in DuckDB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Parquet's default min-max metadata, combined with neural network verification techniques, suffices to prune row groups for ReLU-based ML filter predicates, achieving 27.4% average pruning effectiveness on TPC-H/TPC-DS tables for filters with selectivity below 0.1%; an enhanced size-bounded 2D convex hull metadata raises this to 38.31% at ≤45 bytes per row group and column pair, yielding a 1.07× end-to-end speedup in DuckDB.
Significance. If a concrete, low-overhead verification procedure can be shown to produce the reported pruning rates without verification cost exceeding I/O savings, the work would usefully connect database metadata structures to NN verification for a new class of predicates. The lightweight convex-hull proposal and the use of existing Parquet metadata are pragmatic strengths, but the preliminary status and missing algorithmic details reduce immediate impact.
major comments (2)
- [Abstract] Abstract: the central claim that 'Parquet's default min-max metadata is enough to enable pruning' is stated without any description of the decision procedure, bound-propagation rules, or algorithm that maps min-max intervals (or the convex hull) to a pruning verdict via NN verification.
- [Results] Results and evaluation sections: the reported 27.4% and 38.31% pruning rates and 1.07× DuckDB speedup are aggregate numbers only; no per-row-group timing, verification runtime measurements, or comparison against I/O savings is provided, leaving the skeptic concern about verification cost unaddressed.
minor comments (1)
- The manuscript repeatedly labels the results 'preliminary'; a clearer statement of the exact scope of the experiments (network architectures, column pairs, row-group sizes) would help readers assess generalizability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our preliminary work. We address each major comment below and will revise the manuscript to improve clarity on the decision procedure and evaluation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Parquet's default min-max metadata is enough to enable pruning' is stated without any description of the decision procedure, bound-propagation rules, or algorithm that maps min-max intervals (or the convex hull) to a pruning verdict via NN verification.
Authors: We agree the abstract would benefit from additional context on the approach. In the revision we will update the abstract to briefly describe the use of bound-propagation rules from neural network verification to derive pruning verdicts from min-max intervals (and the convex-hull variant) for ReLU networks. The body of the paper already contains the algorithmic mapping, but we will ensure the abstract makes the connection explicit without exceeding length limits. revision: yes
-
Referee: [Results] Results and evaluation sections: the reported 27.4% and 38.31% pruning rates and 1.07× DuckDB speedup are aggregate numbers only; no per-row-group timing, verification runtime measurements, or comparison against I/O savings is provided, leaving the skeptic concern about verification cost unaddressed.
Authors: The current evaluation focuses on aggregate pruning effectiveness and end-to-end speedup, which already incorporates verification overhead in the DuckDB measurements. We acknowledge that explicit per-row-group verification timings and a direct I/O-savings comparison would better address potential skepticism. In the revised version we will add a table or subsection with verification runtime breakdowns and show that they remain below the I/O savings for the reported selectivity range, using the observed 1.07× net speedup as supporting evidence. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper's central claims consist of measured pruning rates (27.4% and 38.31%) obtained by applying neural-network verification techniques to Parquet min-max metadata and a proposed convex-hull structure on TPC-H and TPC-DS tables. These percentages are produced by direct experimentation rather than any derivation that reduces to fitted parameters, self-citations, or definitional equivalence. No equations or load-bearing steps in the provided text equate a reported result to its own inputs by construction. The work therefore receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- convex hull size bound =
45 bytes
axioms (1)
- domain assumption ReLU architectures permit pruning decisions via neural network verification on min-max metadata
invented entities (1)
-
size-bounded 2D convex hull metadata
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Paritosh Aggarwal, Bowei Chen, Anupam Datta, Benjamin Han, Boxin Jiang, Nitish Jindal, Zihan Li, Aaron Lin, Pawel Liskowski, Jay Tayade, et al . 2025. Cortex AISQL: A Production SQL Engine for Unstructured Data.arXiv preprint arXiv:2511.07663(2025). 4
Pith/arXiv arXiv 2025
-
[2]
2021.Introduction to Neural Network Verification
Aws Albarghouthi. 2021.Introduction to Neural Network Verification. verified- deeplearning.com. arXiv:2109.10317 [cs.LG] http://verifieddeeplearning.com
arXiv 2021
-
[3]
2026.Amazon Redshift ML
Amazon Web Services. 2026.Amazon Redshift ML. https://docs.aws.amazon. com/redshift/latest/dg/machine_learning.html
2026
-
[4]
2026.Metadata
Apache Parquet. 2026.Metadata. https://parquet.apache.org/docs/file-format/ metadata/
2026
-
[5]
Thomas Brinkhoff, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger. 1994. Multi-Step Processing of Spatial Joins. InProceedings of the 1994 ACM SIGMOD International Conference on Management of Data, Minneapolis, Minnesota, USA, May 24-27, 1994, Richard T. Snodgrass and Marianne Winslett (Eds.). ACM Press, 197–208. https://doi.org/10.1145/191839.191880
-
[6]
Bergman, Vittorio Castelli, Chung-Sheng Li, Ming- Ling Lo, and John R
Yuan-Chi Chang, Lawrence D. Bergman, Vittorio Castelli, Chung-Sheng Li, Ming- Ling Lo, and John R. Smith. 2000. The Onion Technique: Indexing for Linear Optimization Queries. InProceedings of the 2000 ACM SIGMOD International Conference on Management of Data, May 16-18, 2000, Dallas, Texas, USA, Weidong Chen, Jeffrey F. Naughton, and Philip A. Bernstein (...
-
[7]
Yeounoh Chung, Rushabh Desai, Jian He, Yu Xiao, Thibaud Hottelier, Yves- Laurent Kom Samo, Pushkar Kadilkar, Xianshun Chen, Sam Idicula, Fatma Özcan, et al. 2026. 100x Cost & Latency Reduction: Performance Analysis of AI Query Approximation using Lightweight Proxy Models.arXiv preprint arXiv:2603.15970 (2026)
Pith/arXiv arXiv 2026
-
[8]
G.E. Collins. 1975. Quantifier elimination for real closed fields by cylindrical algebraic decomposition.Lecture Notes in Computer Science33 (1975), 134–183
1975
-
[9]
2025.Demographia International Housing Affordability
Wendy Cox. 2025.Demographia International Housing Affordability. Technical Report. Frontier Centre for Public Policy, Canada. https://policycommons. net/artifacts/21033541/demographia-international-housing/21933951/ Re- trieved from https://coilink.org/20.500.12592/3hb8vjr on May 31, 2026. COI: 20.500.12592/3hb8vjr
arXiv 2025
-
[10]
Databricks. 2026. ai_query Function. https://docs.databricks.com/aws/en/sql/ language-manual/functions/ai_query
2026
-
[11]
Anas Dorbani, Sunny Yasser, Jimmy Lin, and Amine Mhedhbi. 2025. Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB.Proc. VLDB Endow.18, 12 (Sept. 2025), 5415–5418. https://doi.org/10.14778/3750601. 3750685
-
[12]
Philippe Flajolet, Éric Fusy, Olivier Gandouet, and Frédéric Meunier. 2007. Hyper- loglog: the analysis of a near-optimal cardinality estimation algorithm.Discrete mathematics & theoretical computer scienceProceedings (2007)
2007
-
[13]
Freitag and Thomas Neumann
Michael J. Freitag and Thomas Neumann. 2019. Every Row Counts: Combining Sketches and Sampling for Accurate Group-By Result Esti- mates. In9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org. https://vldb.org/cidrdb/2019/every-row-counts-combining- sketches-and-...
2019
-
[14]
Mark Gerarts, Juno Steegmans, and Jan Van den Bussche. 2025. SQL4NN: Valida- tion and expressive querying of models as data. InProceedings of the Workshop on Data Management for End-to-End Machine Learning. 1–5
2025
-
[15]
Google Cloud. 2026. ML.PREDICT Function. https://cloud.google.com/bigquery/ docs/reference/standard-sql/bigqueryml-syntax-predict. Google Cloud Docu- mentation, accessed 2026-05-31
2026
-
[16]
Martin Grohe, Christoph Standke, Juno Steegmans, and Jan Van den Bussche
-
[17]
Query Languages for Neural Networks. In28th International Conference on Database Theory, ICDT 2025, March 25–28, 2025, Barcelona, Spain (LIPIcs), Sudeepa Roy and Ahmet Kara (Eds.), Vol. 328. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 9:1–9:18. https://doi.org/10.4230/LIPICS.ICDT.2025.9
-
[18]
Yunyan Guo, Guoliang Li, Ruilin Hu, and Yong Wang. 2025. In-database query optimization on SQL with ML predicates.VLDB J.34, 1 (2025), 12
2025
-
[19]
Dong He, Supun Chathuranga Nakandala, Dalitso Banda, Rathijit Sen, Karla Saur, Kwanghyun Park, Carlo Curino, Jesús Camacho-Rodríguez, Konstanti- nos Karanasos, and Matteo Interlandi. 2022. Query Processing on Tensor Computation Runtimes.Proc. VLDB Endow.15, 11 (2022), 2811–2825. https: //doi.org/10.14778/3551793.3551833
-
[20]
Saehan Jo and Immanuel Trummer. 2024. ThalamusDB: Approximate Query Processing on Multi-Modal Data.Proc. ACM Manag. Data2, 3 (2024), 186. https: //doi.org/10.1145/3654989
-
[21]
Michael Jungmair, André Kohn, and Jana Giceva. 2022. Designing an Open Framework for Query Optimization and Compilation.Proceedings of the VLDB Endowment15, 11 (2022), 2389–2401
2022
-
[22]
Gaurav Tarlok Kakkar, Jiashen Cao, Aubhro Sengupta, Joy Arulraj, and Hyesoon Kim. 2025. Aero: Adaptive Query Processing of ML Queries.Proc. ACM Manag. Data3, 3 (2025), 174:1–174:27
2025
-
[23]
Konstantinos Karanasos, Matteo Interlandi, Doris Xin, Fotis Psallidas, Rathijit Sen, Kwanghyun Park, Ivan Popivanov, Supun Nakandala, Subru Krishnan, Markus Weimer, Yuan Yu, Raghu Ramakrishnan, and Carlo Curino. 2019. Extending Relational Query Processing with ML Inference.CoRRabs/1911.00231 (2019)
arXiv 2019
-
[24]
Barrett, David L
Guy Katz, Clark W. Barrett, David L. Dill, Kyle Julian, and Mykel J. Kochenderfer
-
[25]
Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks. In Computer Aided Verification - 29th International Conference, CA V 2017, Heidelberg, Germany, July 24–28, 2017, Proceedings, Part I (Lecture Notes in Computer Science), Rupak Majumdar and Viktor Kuncak (Eds.), Vol. 10426. Springer, 97–117. https: //doi.org/10.1007/978-3-319-63387-9_5
-
[26]
Guy Katz, Derek A. Huang, Duligur Ibeling, Kyle Julian, Christopher Lazarus, Rachel Lim, Parth Shah, Shantanu Thakoor, Haoze Wu, Aleksandar Zeljic, David L. Dill, Mykel J. Kochenderfer, and Clark W. Barrett. 2019. The Marabou Framework for Verification and Analysis of Deep Neural Networks. InCom- puter Aided Verification - 31st International Conference, C...
-
[27]
Konstantin Kaulen, Tobias Ladner, Stanley Bak, Christopher Brix, Hai Duong, Thomas Flinkow, Taylor T. Johnson, Lukas Koller, Edoardo Manino, ThanhVu H. Nguyen, and Haoze Wu. 2025. The 6th International Verification of Neural Networks Competition (VNN-COMP 2025): Summary and Results. CoRRabs/2512.19007 (2025). https://doi.org/10.48550/ARXIV.2512.19007 arXi...
-
[28]
Zico Kolter, Krishnamurthy Dvijotham, and Huan Zhang
Suhas Kotha, Christopher Brix, J. Zico Kolter, Krishnamurthy Dvijotham, and Huan Zhang. 2023. Provably Bounding Neural Network Preimages. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Infor- mation Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Glob...
2023
-
[29]
Changliu Liu, Tomer Arnon, Christopher Lazarus, Christopher A. Strong, Clark W. Barrett, and Mykel J. Kochenderfer. 2021. Algorithms for Veri- fying Deep Neural Networks.Found. Trends Optim.4, 3-4 (2021), 244–404. https://doi.org/10.1561/2400000035
-
[30]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. 2025. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR). 2
2025
-
[31]
2026.PREDICT (Transact-SQL) - SQL Machine Learning
Microsoft. 2026.PREDICT (Transact-SQL) - SQL Machine Learning. https://learn.microsoft.com/en-us/sql/t-sql/queries/predict-transact- sql?view=sql-server-ver17
2026
-
[32]
2026.Oracle Machine Learning for SQL (OML4SQL)
Oracle. 2026.Oracle Machine Learning for SQL (OML4SQL). https://docs.oracle. com/en/database/oracle/machine-learning/oml4sql/index.html
2026
-
[33]
Liana Patel, Siddharth Jha, Carlos Guestrin, and Matei Zaharia. 2024. LOTUS: En- abling Semantic Queries with LLMs Over Tables of Unstructured and Structured Data.CoRRabs/2407.11418 (2024). https://doi.org/10.48550/ARXIV.2407.11418 arXiv:2407.11418
-
[34]
Maximilian Rieger, Moritz Sichert, and Thomas Neumann. 2022. Integrat- ing deep learning frameworks into main-memory databases. InProceedings of the VLDB 2022 Applied AI for Database Systems and Applications Workshop co-located with (VLDB 2022)(AIDB Workshop Proceedings). https://drive. google. com/file/d/1GfZH3Y1sQKgplnnpTEM_E4skWdhmyrfe/edit
2022
-
[35]
SciPy Developers. 2025. scipy.spatial.ConvexHull. https://docs.scipy.org/ doc/scipy/reference/generated/scipy.spatial.ConvexHull.html. Accessed: 2026- 05-31
2025
-
[36]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9 (Sept. 2025), 3035–3048. https: //doi.org/10.14778/3746405.3746426
-
[37]
2026.Snowflake Model Registry
Snowflake. 2026.Snowflake Model Registry. https://docs.snowflake.com/en/ developer-guide/snowflake-ml/model-registry/overview
2026
-
[38]
Transaction Processing Performance Council. [n.d.]. TPC Benchmark H (Decision Support) Standard Specification. https://www.tpc.org/tpch/. Version 3.0.1
-
[39]
Transaction Processing Performance Council. [n.d.]. TPC-DS Benchmark Stan- dard Specification. https://www.tpc.org/tpcds/. Version 4.0.0
-
[40]
Joseph A. Vincent and Mac Schwager. 2025. Reachable Polyhedral Marching (RPM): An Exact Analysis Tool for Deep-Learned Control Systems.IEEE Trans. Neural Networks Learn. Syst.36, 10 (2025), 19225–19239. https://doi.org/10.1109/ TNNLS.2025.3571720
arXiv 2025
-
[41]
Zico Kolter
Shiqi Wang, Huan Zhang, Kaidi Xu, Xue Lin, Suman Jana, Cho-Jui Hsieh, and J. Zico Kolter. 2021. Beta-CROWN: Efficient Bound Propagation with Per-neuron Split Constraints for Neural Network Robustness Verification. InAdvances in Neu- ral Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Decemb...
2021
-
[42]
Bowen Wu, Wei Cui, Carlo Curino, Matteo Interlandi, and Rathijit Sen. 2025. Terabyte-Scale Analytics in the Blink of an Eye.Proc. VLDB Endow.19, 2 (2025), 141–155. https://www.vldb.org/pvldb/vol19/p141-sen.pdf
2025
-
[43]
Haoze Wu, Omri Isac, Aleksandar Zeljic, Teruhiro Tagomori, Matthew L. Daggitt, Wen Kokke, Idan Refaeli, Guy Amir, Kyle Julian, Shahaf Bassan, Pei Huang, Ori Lahav, Min Wu, Min Zhang, Ekaterina Komendantskaya, Guy Katz, and Clark W. Barrett. 2024. Marabou 2.0: A Versatile Formal Analyzer of Neural 5 Networks. InComputer Aided Verification - 36th Internatio...
-
[44]
Weiming Xiang, Hoang-Dung Tran, and Taylor T. Johnson. 2017. Reachable Set Computation and Safety Verification for Neural Networks with ReLU Activations. CoRRabs/1712.08163 (2017). arXiv:1712.08163 http://arxiv.org/abs/1712.08163
Pith/arXiv arXiv 2017
-
[45]
[n.d.].Embedding User-Defined Indexes in Apache Parquet Files
Qi Zhu, Jigao Luo, and Andrew Lamb. [n.d.].Embedding User-Defined Indexes in Apache Parquet Files. https://datafusion.apache.org/blog/2025/07/14/user- defined-parquet-indexes/ Apache DataFusion Blog
2025
-
[46]
Andreas Zimmerer, Damien Dam, Jan Kossmann, Juliane Waack, Ismail Oukid, and Andreas Kipf. 2025. Pruning in Snowflake: Working Smarter, Not Harder. InCompanion of the 2025 International Conference on Management of Data, SIG- MOD/PODS 2025, Berlin, Germany, June 22-27, 2025, Volker Markl, Joseph M. Hellerstein, and Azza Abouzied (Eds.). ACM, 757–770. https...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.