Language Models Compare Quantities Using Number-specific and Unit-specific Heuristics
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
Language models compare quantities by applying separate heuristics to numerals and unit scales rather than converting both to a shared representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
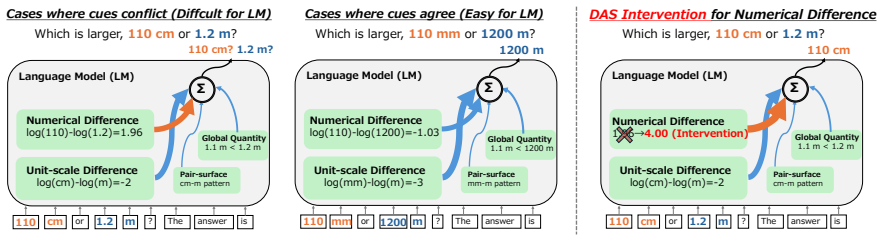
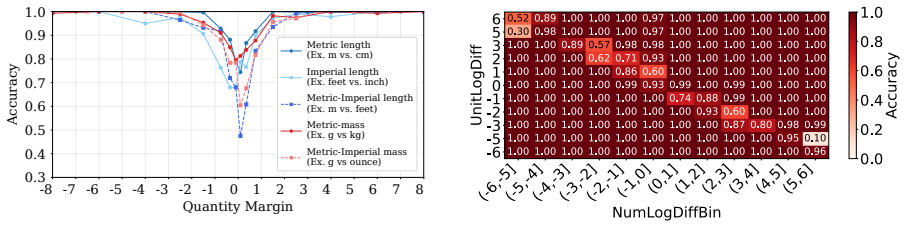
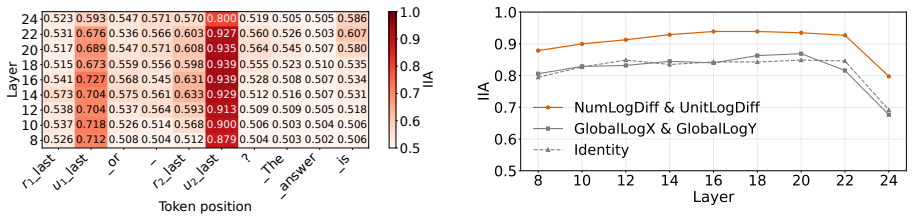
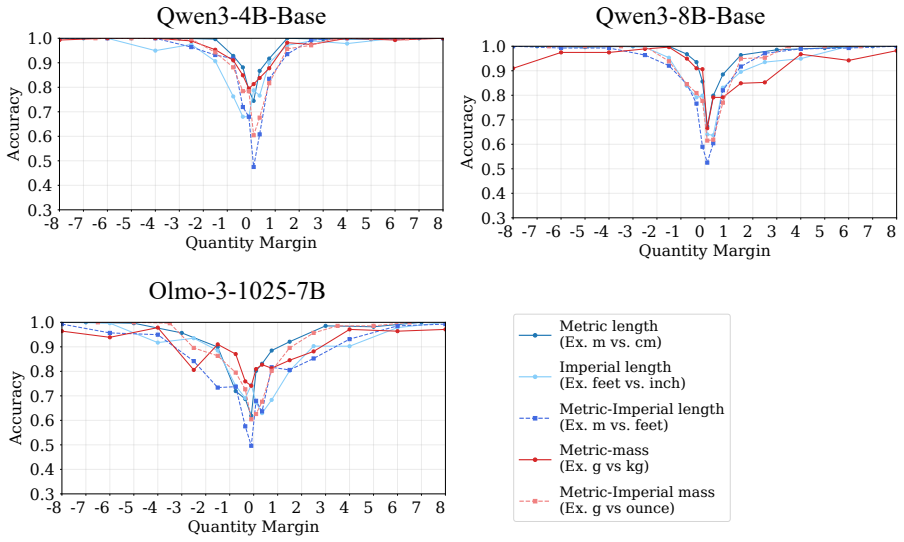
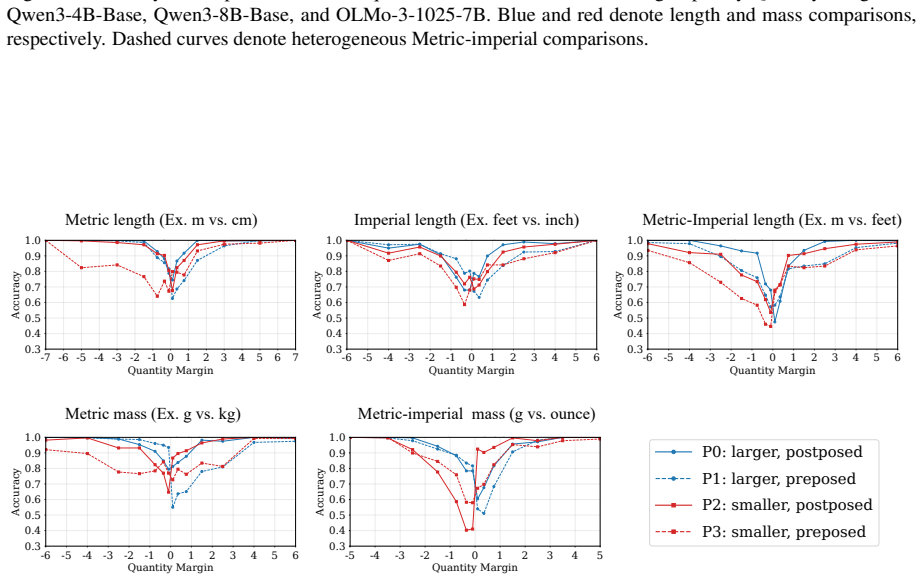
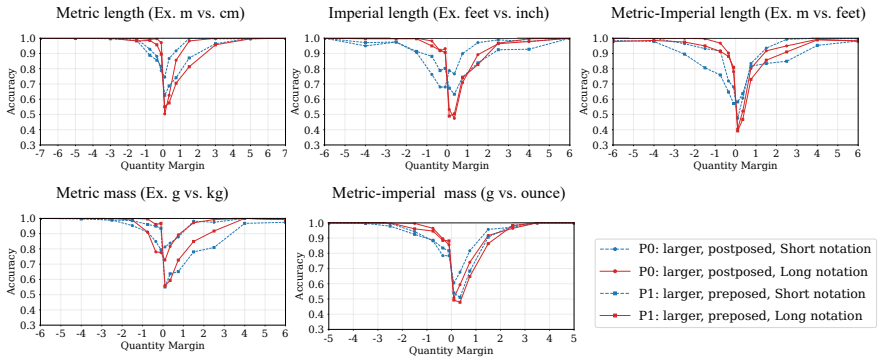
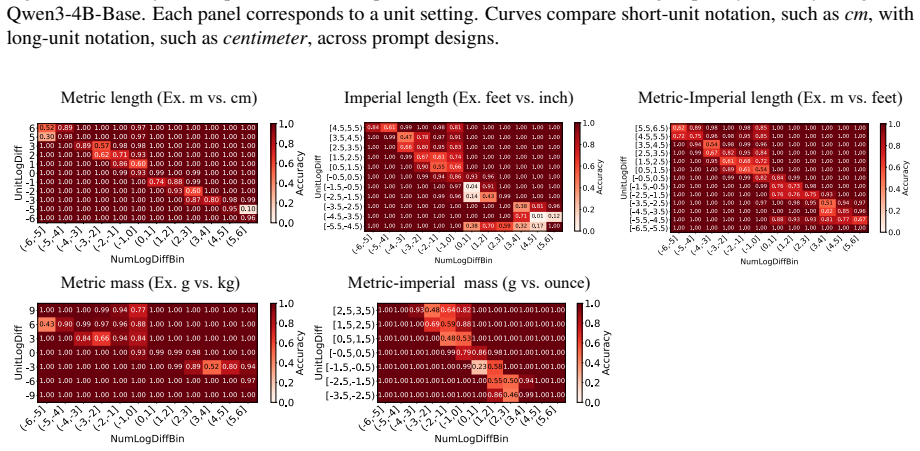
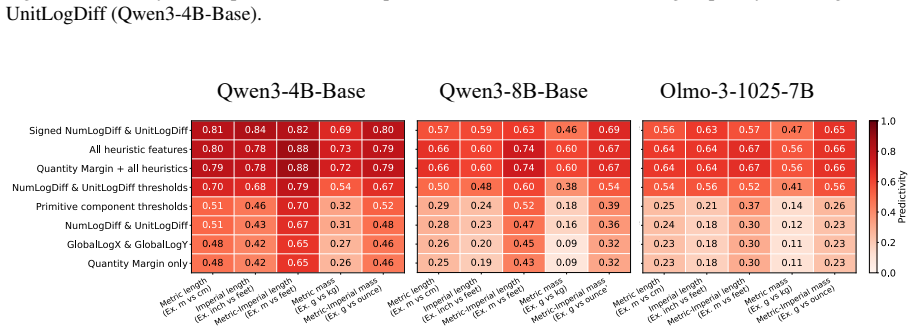
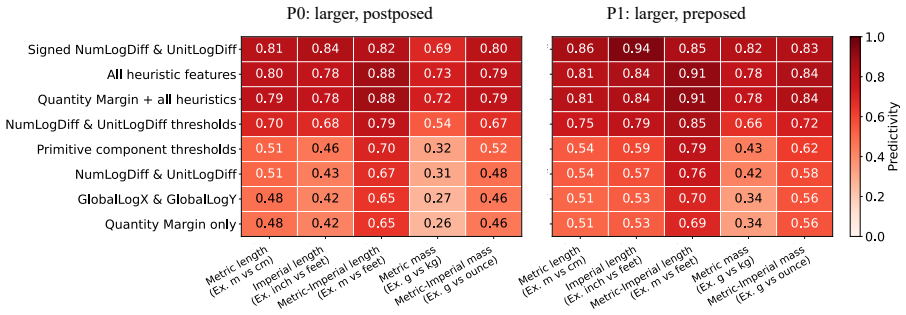
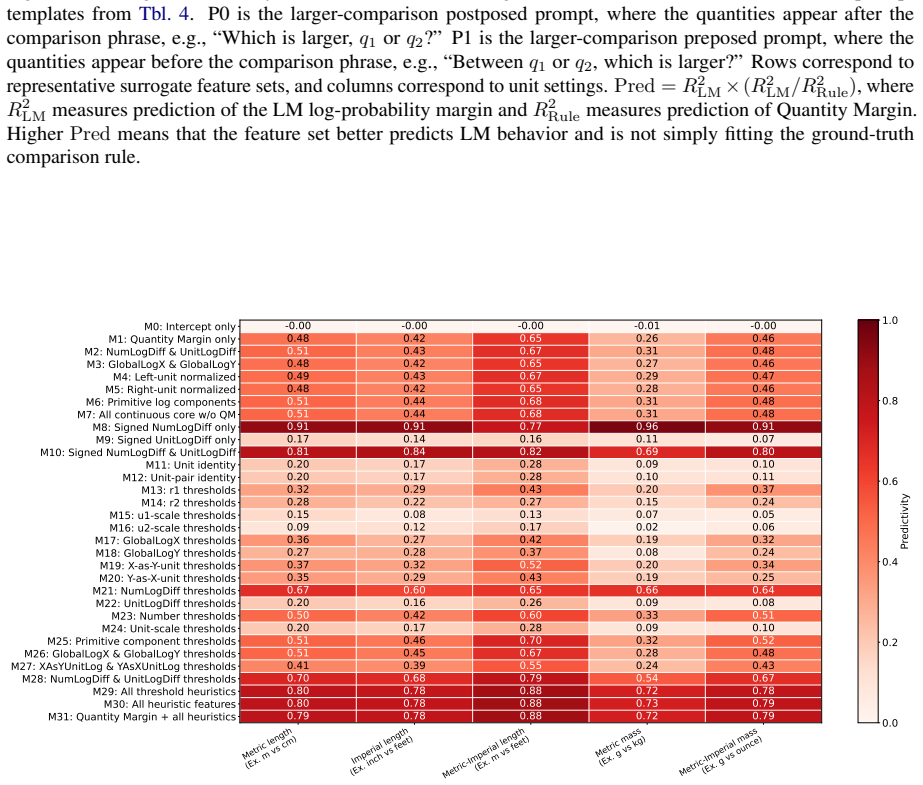
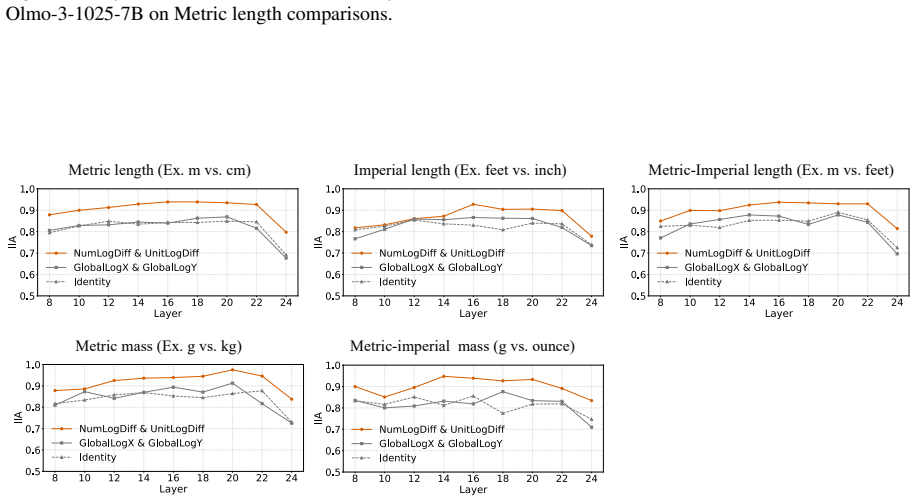
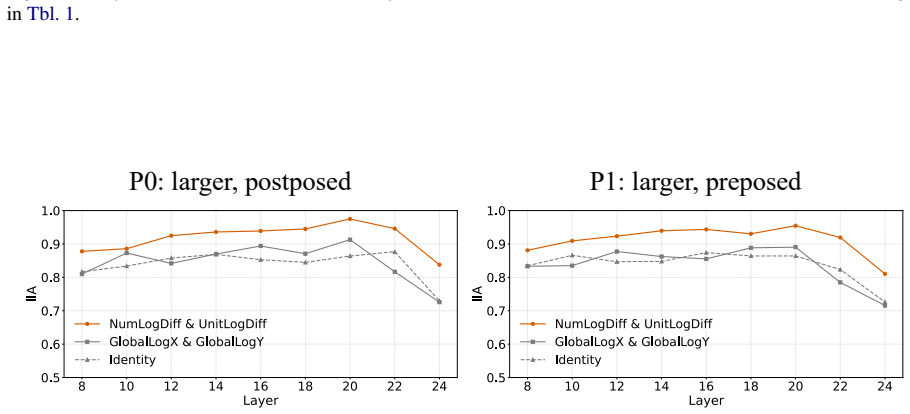
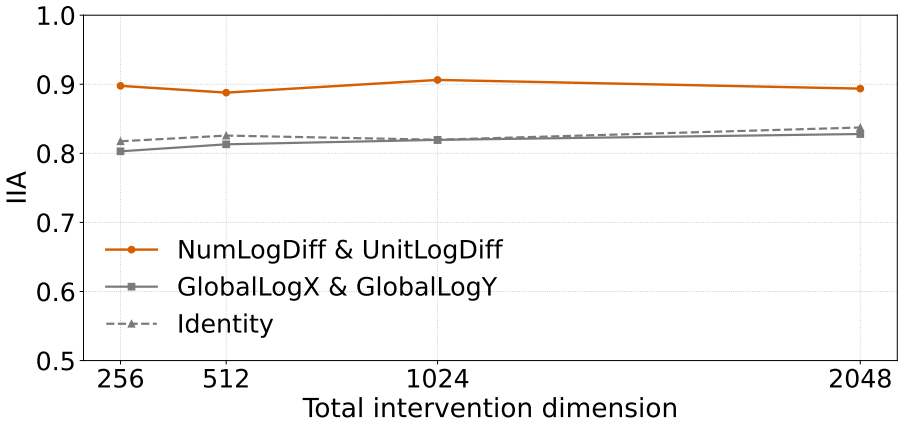
Language models compare quantities with measurement units through a bag of heuristics over numerals and units, rather than first converting both expressions to an exact shared-scale representation. Accuracy degrades near the comparison boundary, the resulting errors are systematic, linear surrogate models predict model preferences from numerical-difference and unit-scale-difference cues, and causal interventions on subspaces aligned with these variables shift the model's output.
What carries the argument
Bag of heuristics over numerals and units, recovered through linear surrogate models on numerical and unit differences together with subspace interventions that causally affect outputs.
If this is right
- Models do not perform an exact shared-scale conversion before deciding which quantity is larger.
- Comparison decisions can be approximated by simple additive cues from numeral size and unit scale size.
- Editing subspaces tied to those cues reliably alters the model's comparison outputs.
- Errors concentrate where the two quantities are close after unit scaling.
Where Pith is reading between the lines
- The same heuristic strategy may cause failures on quantitative tasks that require chaining multiple conversions.
- Training objectives that explicitly reward shared-scale representations could reduce the observed boundary errors.
- The pattern may extend to other symbolic comparisons that involve named scales or conversion factors.
Load-bearing premise
The linear surrogate models and subspace interventions correctly isolate the actual decision mechanisms used by the LM rather than capturing correlated but non-causal features.
What would settle it
An experiment in which the identified subspaces are edited yet the model's quantity-comparison choices remain unchanged, or in which accuracy stays high even when quantities lie near the decision boundary.
Figures

read the original abstract
Quantities with measurement units, such as 110 cm and 1.2 m, require language models (LMs) to combine a numeral with a symbolic unit scale. Here, we study how LMs compare such quantities in controlled settings spanning several unit systems. We find that accuracy degrades near the comparison boundary, where small changes in value determine the correct answer. The resulting errors are systematic: linear surrogate models predict LM preferences from numerical-difference and unit-scale-difference cues, and causal interventions on subspaces aligned with these variables shift model's output. The results suggest that LMs compare quantities through a bag of heuristics over numerals and units, rather than first converting both expressions to an exact shared-scale representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies how language models compare quantities with units (e.g., 110 cm vs. 1.2 m) across unit systems. It reports degraded accuracy near comparison boundaries, systematic errors predictable by linear surrogate models using numerical-difference and unit-scale-difference cues, and output shifts from causal interventions on subspaces aligned with those variables. The central claim is that LMs rely on a bag of number-specific and unit-specific heuristics rather than first converting expressions to an exact shared-scale representation.
Significance. If the mechanistic claims hold after proper validation, the work would provide evidence against precise internal quantity conversion in LMs and in favor of heuristic strategies, with implications for interpretability and numerical reasoning in language models. The combination of behavioral error analysis, surrogate modeling, and subspace interventions represents a constructive attempt to move beyond surface-level accuracy metrics.
major comments (1)
- [Abstract / Methods] Abstract and methods: the central claim that subspace interventions demonstrate heuristic use (rather than an internal conversion process sensitive to the same cues near boundaries) rests on the assumption that the subspaces isolate the decision mechanism. No details are provided on subspace identification (e.g., probes, patching, or clustering), validation against alternative subspaces, or counterfactual controls, which is load-bearing for the causal interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The point regarding insufficient methodological detail on subspace interventions is well-taken, and we address it directly below with a commitment to revision.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods: the central claim that subspace interventions demonstrate heuristic use (rather than an internal conversion process sensitive to the same cues near boundaries) rests on the assumption that the subspaces isolate the decision mechanism. No details are provided on subspace identification (e.g., probes, patching, or clustering), validation against alternative subspaces, or counterfactual controls, which is load-bearing for the causal interpretation.
Authors: We agree that the manuscript currently lacks sufficient detail on subspace identification and validation, which weakens the causal claims. In the revised manuscript we will expand the Methods section to specify: (1) subspace identification via linear probes trained to predict the numerical-difference and unit-scale-difference features from residual stream activations, followed by selection of the top principal components aligned with these features; (2) patching experiments that replace activations in the identified subspaces while holding other components fixed; and (3) explicit validation including comparison to randomly sampled subspaces of equal dimensionality, subspaces aligned with unrelated features (e.g., token frequency), and additional counterfactual controls that intervene on the same subspaces but with inverted feature signs. These additions will directly test whether the observed output shifts are specific to the heuristic cues rather than reflecting a general sensitivity near boundaries. revision: yes
Circularity Check
Empirical behavioral study with no derivations reducing to inputs
full rationale
The paper reports controlled experiments on LM quantity comparison, accuracy degradation near boundaries, linear surrogate models fitted to predict preferences from numerical/unit cues, and subspace interventions. These are observational and interventional analyses on model outputs, not a derivation chain with equations or self-citations that reduce the central claim to its own fitted inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided text. The claim rests on external experimental observations rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hilal AlQuabeh, Velibor Bojkovic, Munachiso S Nwadike, Ahmed Oumar El-Shangiti, Tatsuya Hiraoka, and Kentaro Inui. 2026. https://openreview.net/forum?id=yhEi1aeWCQ Number representations in LLMs : A computational parallel to human perception
2026
-
[2]
Minh Duc Bui, Kyung Eun Park, Goran Glava s , Fabian David Schmidt, and Katharina Von Der Wense. 2025. https://doi.org/10.18653/v1/2025.acl-long.1032 On generalization across measurement systems: LLM s entail more test-time compute for underrepresented cultures . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V...
-
[3]
Xiaoman Delores Ding, Zifan Carl Guo, Eric J Michaud, Ziming Liu, and Max Tegmark. 2024. https://openreview.net/forum?id=2WfiYQlZDa Survival of the fittest representation: A case study with modular addition . In ICML 2024 Workshop on Mechanistic Interpretability
2024
-
[4]
Ahmed Oumar El-Shangiti, Tatsuya Hiraoka, Hilal AlQuabeh, Benjamin Heinzerling, and Kentaro Inui. 2025. https://doi.org/10.18653/v1/2025.naacl-short.47 The geometry of numerical reasoning: Language models compare numeric properties in linear subspaces . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com...
-
[5]
Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. 2024. https://proceedings.mlr.press/v236/geiger24a.html Finding alignments between interpretable causal variables and distributed neural representations . In Proceedings of the Third Conference on Causal Learning and Reasoning, volume 236 of Proceedings of Machine Learning Re...
2024
-
[6]
Jan G \"o pfert, Patrick Kuckertz, Jann Weinand, Leander Kotzur, and Detlef Stolten. 2022. https://doi.org/10.18653/v1/2022.findings-emnlp.161 Measurement extraction with natural language processing: A review . In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2191--2215
-
[7]
Michael Hanna, Ollie Liu, and Alexandre Variengien. 2023. https://openreview.net/forum?id=p4PckNQR8k How does GPT -2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model . In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[8]
Benjamin Heinzerling and Kentaro Inui. 2024. https://doi.org/10.18653/v1/2024.acl-short.18 Monotonic representation of numeric attributes in language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 175--195
-
[9]
Yuncheng Huang, Qianyu He, Jiaqing Liang, Sihang Jiang, Yanghua Xiao, and Yunwen Chen. 2024. https://doi.org/10.1109/ICDE60146.2024.00066 Enhancing Quantitative Reasoning Skills of Large Language Models through Dimension Perception . In 2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 789--802, Los Alamitos, CA, USA
-
[10]
Subhash Kantamneni and Max Tegmark. 2025. https://openreview.net/forum?id=CqViN4dQJk Language models use trigonometry to do addition . In ICLR 2025 Workshop on Building Trust in Language Models and Applications
2025
-
[11]
Amit Arnold Levy and Mor Geva. 2025. https://doi.org/10.18653/v1/2025.naacl-short.33 Language models encode numbers using digit representations in base 10 . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 385--395, Alb...
-
[12]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. 2023. https://openreview.net/forum?id=9XFSbDPmdW Progress measures for grokking via mechanistic interpretability . In The Eleventh International Conference on Learning Representations
2023
-
[13]
Yaniv Nikankin, Anja Reusch, Aaron Mueller, and Yonatan Belinkov. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/file/8c5f30296296d2ae402ebbd09aaa9c12-Paper-Conference.pdf Arithmetic without algorithms: Language models solve math with a bag of heuristics . In International Conference on Learning Representations, volume 2025, pages 55939--55965
2025
-
[14]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, and 50 others. 2026. https://arxiv.org/abs/2512.13961 Olmo 3 . Preprint, arXiv:2512.13961
Pith/arXiv arXiv 2026
-
[15]
Sungjin Park, Seungwoo Ryu, and Edward Choi. 2022. https://doi.org/10.18653/v1/2022.findings-emnlp.128 Do language models understand measurements? In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 1782--1792
-
[16]
Philip Quirke and Fazl Barez. 2024. https://openreview.net/forum?id=rIx1YXVWZb Understanding addition in transformers . In The Twelfth International Conference on Learning Representations
2024
-
[17]
Philip Quirke, Clement Neo, and Fazl Barez. 2025. https://arxiv.org/abs/2402.02619 Understanding addition and subtraction in transformers . Preprint, arXiv:2402.02619. Preprint
arXiv 2025
-
[18]
Raj Shah, Vijay Marupudi, Reba Koenen, Khushi Bhardwaj, and Sashank Varma. 2023. https://doi.org/10.18653/v1/2023.findings-acl.383 Numeric magnitude comparison effects in large language models . In Findings of the Association for Computational Linguistics: ACL 2023, pages 6147--6161
-
[19]
Daniel Spokoyny, Ivan Lee, Zhao Jin, and Taylor Berg-Kirkpatrick. 2022. https://doi.org/10.18653/v1/2022.findings-naacl.2 Masked measurement prediction: Learning to jointly predict quantities and units from textual context . In Findings of the Association for Computational Linguistics: NAACL 2022, pages 17--29
-
[20]
Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.435 A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7035--7052
-
[21]
Ancheng Xu, Minghuan Tan, Lei Wang, Min Yang, and Ruifeng Xu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.848 NUMC o T : Numerals and units of measurement in chain-of-thought reasoning using large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 14268--14290
-
[22]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[23]
Fengting Yuchi, Li Du, and Jason Eisner. 2026. https://doi.org/10.18653/v1/2026.eacl-short.47 LLM s know more about numbers than they can say . In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 2: Short Papers) , pages 659--673, Rabat, Morocco
-
[24]
Wei Zhang, Chaoqun Wan, Yonggang Zhang, Yiu ming Cheung, Xinmei Tian, Xu Shen, and Jieping Ye. 2024. https://proceedings.mlr.press/v235/zhang24bk.html Interpreting and improving large language models in arithmetic calculation . In Forty-first International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 59932-...
2024
-
[25]
Ziqian Zhong, Ziming Liu, Max Tegmark, and Jacob Andreas. 2023. https://openreview.net/forum?id=S5wmbQc1We The clock and the pizza: Two stories in mechanistic explanation of neural networks . In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[26]
Tianyi Zhou, Deqing Fu, Vatsal Sharan, and Robin Jia. 2024. https://openreview.net/forum?id=i4MutM2TZb Pre-trained large language models use fourier features to compute addition . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[27]
Fangwei Zhu, Damai Dai, and Zhifang Sui. 2025. https://aclanthology.org/2025.coling-main.47/ Language models encode the value of numbers linearly . In Proceedings of the 31st International Conference on Computational Linguistics, pages 693--709
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.