NewtPhys: Do Foundation Models Understand Newtonian Physics?
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
A new dataset of real-world scenes with force annotations shows foundation models have limitations in low-level Newtonian physics reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
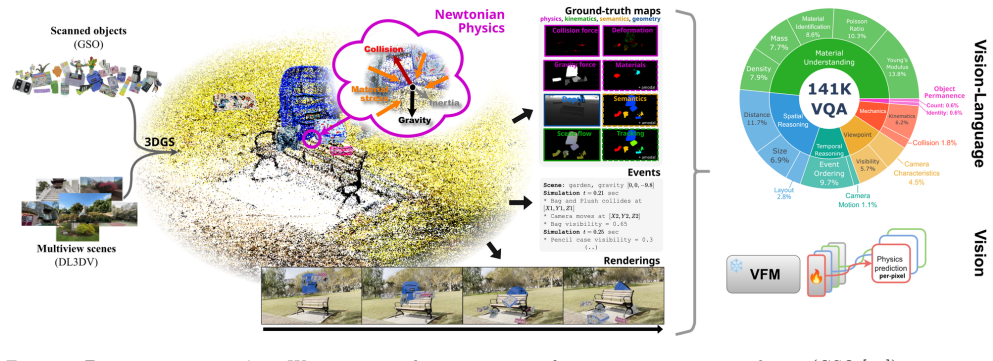
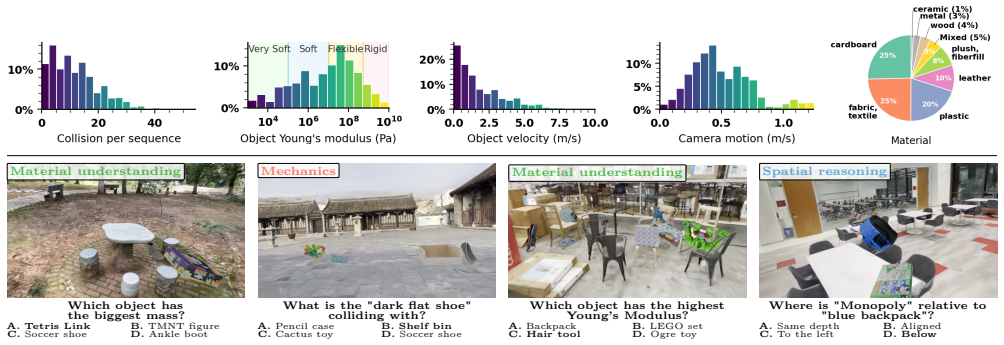
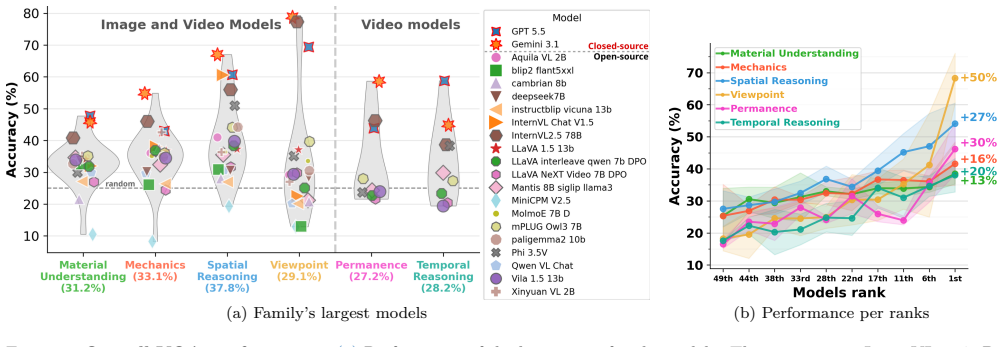
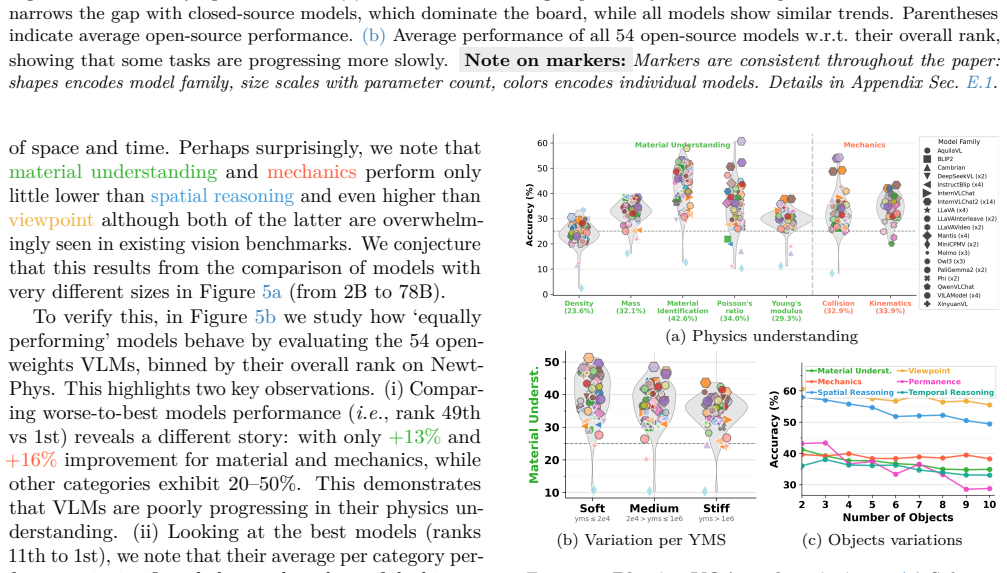
NewtPhys supplies dense annotations of 3D forces and amodal per-pixel physics, tracking, semantics and geometry quantities across timesteps on real multiview scenes, and evaluation of 56 VLMs plus 10 VFMs on it demonstrates limitations in low-level Newtonian physics reasoning.
What carries the argument
NewtPhys, a 4D dataset built from multiview real-world images and physics-grounded simulations that supplies 3D forces and per-pixel annotations.
If this is right
- High-level visual question answering benchmarks overestimate models' grasp of physics.
- Dense real-scene annotations become necessary for future physics reasoning tests.
- Vision foundation models require additional mechanisms to handle force prediction and temporal physical quantities.
- The dataset opens the way for training loops that incorporate explicit physics signals.
Where Pith is reading between the lines
- Failure on these tasks suggests models may also lack reliable intuition for embodied tasks such as manipulation or navigation.
- Comparing NewtPhys annotations against direct real-world force measurements could quantify any remaining simulation gaps.
- Similar annotation pipelines could be applied to fluid or deformable-body scenarios to test broader physical understanding.
Load-bearing premise
The simulations that annotate the real scenes produce 3D forces and per-pixel quantities that match actual Newtonian dynamics without major gaps.
What would settle it
If a model achieves high accuracy on NewtPhys tasks that require predicting forces or per-pixel physics quantities across timesteps, that would indicate the claimed limitations do not hold.
Figures



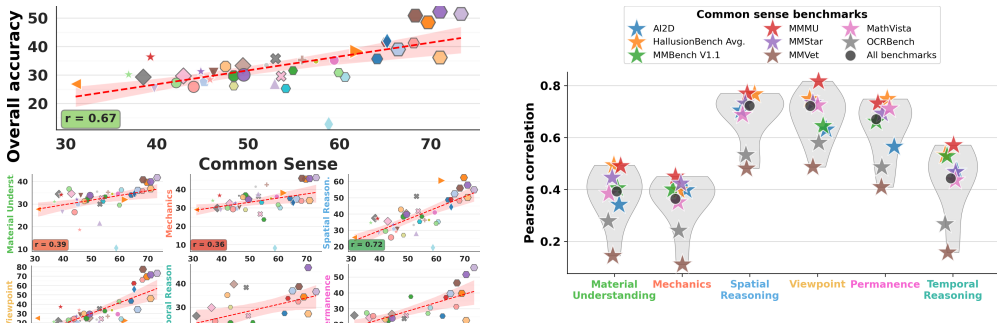
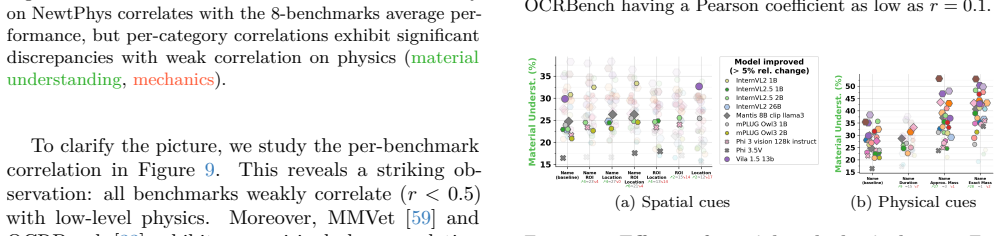
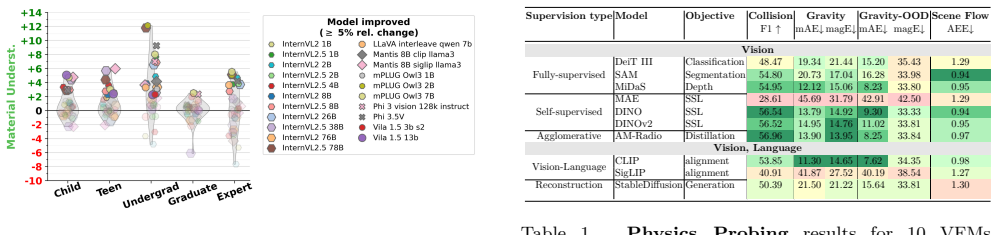
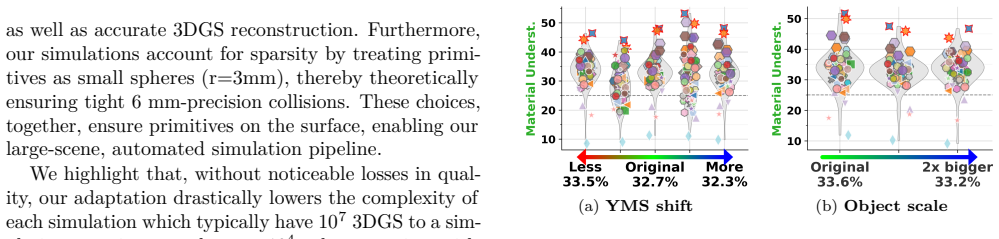
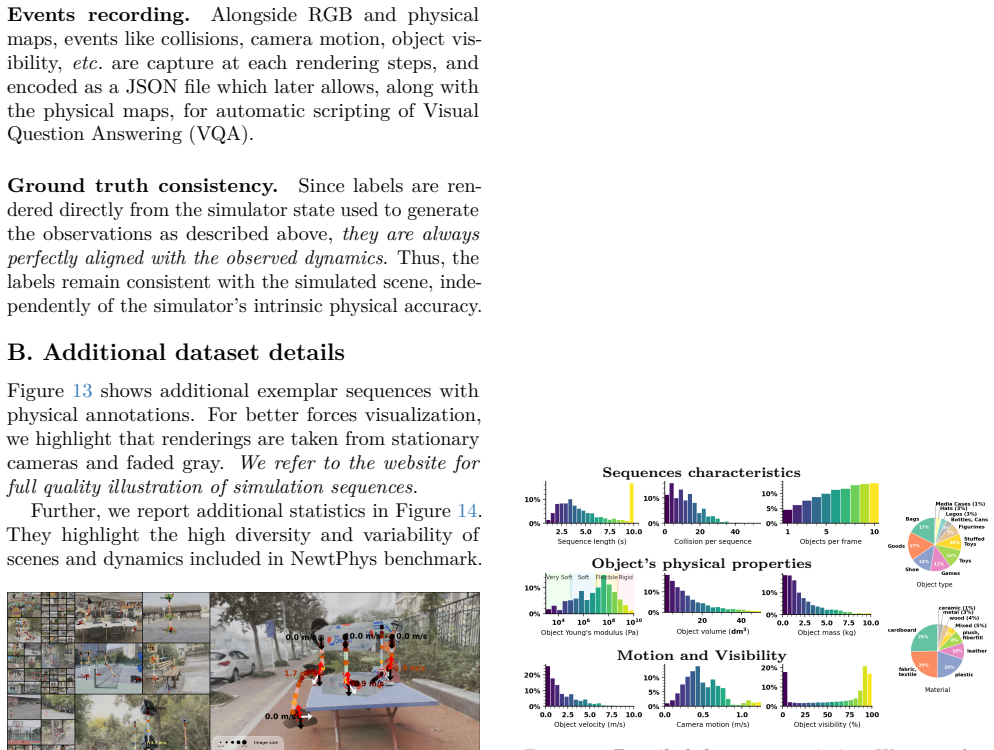

read the original abstract
Previous work has evaluated physics reasoning in foundation models using synthetic or semi-synthetic scenes and visual question-answering tasks. However, these benchmarks emphasize high-level events and lack the visual fidelity required to assess true low-level Newtonian understanding. We introduce NewtPhys, a 4D physically annotated dataset built from multiview images of real-world scenes with physics-grounded simulations. The dataset provides dense, fine-grained annotations across timesteps -- including 3D forces and amodal per-pixel quantities covering physics, tracking, semantics and geometry -- bridging the gap between simplistic synthetic setups and realistic visual complexity. Using NewtPhys, we systematically evaluate 56 VLMs, including 54 open-weight models and 2 closed-source frontier models, and 10 VFMs and reveal limitations in low-level physics reasoning. Beyond benchmarking, our dataset enables future research in physics-grounded vision and the development of next-generation physics-aware evaluations. Code and datasets are available at https://astra-vision.github.io/NewtPhys.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NewtPhys, a 4D dataset constructed from multiview images of real-world scenes augmented via physics-grounded simulations. It supplies dense, fine-grained annotations across timesteps, including 3D forces and amodal per-pixel quantities for physics, tracking, semantics, and geometry. The work benchmarks 56 VLMs (54 open-weight plus 2 closed-source frontier models) and 10 VFMs on low-level Newtonian physics reasoning tasks, reports limitations in current models, and releases the dataset and code publicly to support future physics-grounded vision research.
Significance. If the annotations are shown to be faithful, NewtPhys would provide a useful bridge between synthetic physics benchmarks and real visual complexity, enabling more diagnostic evaluation of physical reasoning in foundation models. The public release of data and code is a clear strength for reproducibility.
major comments (1)
- [Abstract / Dataset Construction] Abstract and dataset construction section: the claim that NewtPhys reveals limitations in low-level physics reasoning depends on the simulations producing 3D forces and per-pixel quantities that faithfully match true Newtonian dynamics. The manuscript supplies no quantitative validation (error bounds, comparison to real measurements, or analysis of unmodeled effects such as friction or deformation), leaving open the possibility that observed model errors arise from annotation mismatch rather than reasoning failure. This is load-bearing for the central empirical conclusion.
minor comments (2)
- [Experiments] Evaluation protocol: specify the exact question formats, answer formats, and scoring metrics used for the VLM and VFM benchmarks so that the reported limitations can be directly reproduced.
- [Figures] Figure and table captions: ensure all annotation examples include explicit scale bars or units for the physics quantities shown.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on NewtPhys. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract / Dataset Construction] Abstract and dataset construction section: the claim that NewtPhys reveals limitations in low-level physics reasoning depends on the simulations producing 3D forces and per-pixel quantities that faithfully match true Newtonian dynamics. The manuscript supplies no quantitative validation (error bounds, comparison to real measurements, or analysis of unmodeled effects such as friction or deformation), leaving open the possibility that observed model errors arise from annotation mismatch rather than reasoning failure. This is load-bearing for the central empirical conclusion.
Authors: We agree that the fidelity of the physics annotations is central to our conclusions and that the initial manuscript provides no quantitative validation such as error bounds, real-measurement comparisons, or explicit discussion of unmodeled effects. The simulations apply Newtonian mechanics to real multiview geometry via established physics engines, but this does not substitute for direct validation. In the revised manuscript we will add a validation subsection in the dataset construction section that reports available trajectory and force consistency checks, quantifies simulation-to-observation discrepancies where measurable, and discusses limitations arising from friction, deformation, and other unmodeled phenomena. This will clarify whether model errors stem from reasoning shortfalls or annotation mismatch. revision: yes
Circularity Check
No circularity: empirical dataset creation and model evaluation with no derivation chain
full rationale
The paper presents NewtPhys as a 4D dataset constructed from multiview real-world images annotated via physics-grounded simulations, followed by empirical benchmarking of 56 VLMs and 10 VFMs. No mathematical derivation, first-principles prediction, parameter fitting, or uniqueness theorem is claimed or present. The central contribution is dataset release and evaluation results; the simulation-to-reality gap noted by the skeptic is a validity assumption, not a reduction of any result to its own inputs by construction. No self-citations, ansatzes, or renamings of known results appear in a load-bearing role for any derivation. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Physical reasoning in young infants: Seeking explanations for impossible events.British Journal of Developmental Psychology, 1994
Renée Baillargeon. Physical reasoning in young infants: Seeking explanations for impossible events.British Journal of Developmental Psychology, 1994. 1, 2, 9
1994
-
[2]
Battaglia, Jessica B
Peter W. Battaglia, Jessica B. Hamrick, and Joshua B. Tenenbaum. Simulation as an engine of physical scene understanding.Proceedings of the National Academy of Sciences, 2013. 2
2013
-
[3]
Relational inductive biases, deep learning, and graph networks
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive bi- ases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Physion: Evaluating physical prediction from vision in humans and machines
Daniel Bear, Elias Wang, Damian Mrowca, Felix Je- didja Binder, Hsiao-Yu Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin A Smith, Fan-Yun Sun, et al. Physion: Evaluating physical prediction from vision in humans and machines. InNeurIPS, 2021. 2
2021
-
[5]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. InAAAI, 2020. 5
2020
-
[7]
The origin of concepts.Journal of Cog- nition and Development, 2000
Susan Carey. The origin of concepts.Journal of Cog- nition and Development, 2000. 1, 2
2000
-
[8]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InICCV, 2021. 5, 10
2021
-
[9]
Are we on the right way for evaluating large vision-language models? In NIPS, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models? In NIPS, 2024. 7
2024
-
[10]
Internvl: Scaling up vi- sion foundation models and aligning for generic visual- linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vi- sion foundation models and aligning for generic visual- linguistic tasks. InCVPR, 2024. 5
2024
-
[11]
Categorization and representation of physics problems by experts and novices.Cognitive science, 1981
Michelene TH Chi, Paul J Feltovich, and Robert Glaser. Categorization and representation of physics problems by experts and novices.Cognitive science, 1981. 9
1981
-
[12]
Physbench: Benchmark- ing and enhancing vision-language models for physical world understanding
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmark- ing and enhancing vision-language models for physical world understanding. InICLR, 2025. 2, 5
2025
-
[13]
Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models. InCVPR, 2024. 5
2024
-
[14]
Pin: Positional insert unlocks object localisation abilities in vlms
Michael Dorkenwald, Nimrod Barazani, Cees GM Snoek, and Yuki M Asano. Pin: Positional insert unlocks object localisation abilities in vlms. InCVPR,
-
[15]
Google scanned objects: A high-quality dataset of 3d scanned household items
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kinman, Ryan Hickman, Krista Reymann, Thomas B McHugh, and Vincent Vanhoucke. Google scanned objects: A high-quality dataset of 3d scanned household items. InICRA, 2022. 3, 4, 12
2022
-
[16]
Probing the 3d awareness of visual foundation models
Mohamed El Banani, Amit Raj, Kevis-Kokitsi Mani- nis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, and Varun Jampani. Probing the 3d awareness of visual foundation models. InCVPR, 2024. 2
2024
-
[17]
Kaolin: A pytorch library for accelerating 3d deep learning research
Clement Fuji Tsang, Maria Shugrina, Jean Fran- cois Lafleche, Or Perel, Charles Loop, Towaki Takikawa, Vismay Modi, Alexander Zook, Jiehan Wang, Wenzheng Chen, Tianchang Shen, Jun Gao, Krishna Murthy Jatavallabhula, Edward Smith, Artem Rozantsev, Sanja Fidler, Gavriel State, Jason Gorski, Tommy Xiang, Jianing Li, Michael Li, and Rev Lebare- dian. Kaolin: ...
2024
-
[18]
Gemini 3.1
Google DeepMind. Gemini 3.1. https://deepmind. google, 2026. Proprietary model; no public technical report. 5
2026
-
[19]
Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InCVPR,
-
[20]
Sugar: Surface- aligned gaussian splatting for efficient 3d mesh recon- struction and high-quality mesh rendering.CVPR,
Antoine Guédon and Vincent Lepetit. Sugar: Surface- aligned gaussian splatting for efficient 3d mesh recon- struction and high-quality mesh rendering.CVPR,
-
[21]
Milo: Mesh-in-the-loop gaussian splatting for detailed and efficient surface reconstruction.TOG,
Antoine Guédon, Diego Gomez, Nissim Maruani, Bingchen Gong, George Drettakis, and Maks Ovs- janikov. Milo: Mesh-in-the-loop gaussian splatting for detailed and efficient surface reconstruction.TOG,
-
[22]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InCVPR, 2024. 45
2024
-
[23]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. InICML, 2024. 8
2024
-
[24]
Phillip Isola, Daniel Zoran, Dilip Krishnan, and Ed- ward H. Adelson. Learning visual groups from co- occurrences in space and time, 2015. 2
2015
-
[25]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Min- joon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InECCV, 2016. 7
2016
-
[26]
3d gaussian splatting for real-time radiance field rendering.ACM TG, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimküh- ler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM TG, 2023. 2, 4, 12
2023
-
[27]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. In ICCV, 2023. 10
2023
-
[28]
Pisa experiments: Ex- ploring physics post-training for video diffusion models by watching stuff drop
Chenyu Li, Oscar Michel, Xichen Pan, Sainan Liu, Mike Roberts, and Saining Xie. Pisa experiments: Ex- ploring physics post-training for video diffusion models by watching stuff drop. InICML, 2025. 2
2025
-
[29]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InCVPR, 2024. 3, 4
2024
-
[31]
Visual instruction tuning
HaotianLiu, ChunyuanLi, QingyangWu, andYongJae Lee. Visual instruction tuning. InNeurIPS, 2023. 5
2023
-
[32]
Mmbench: Is your multi-modal model an all- around player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all- around player? InECCV, 2024. 7
2024
-
[33]
Ocrbench: on the hidden mystery of ocr in large multimodal models
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models. SCIS, 2024. 7, 8
2024
-
[34]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhu- oshu Li, Hao Yang, et al. Deepseek-vl: towards real- world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Mathvista: Evaluating mathematical reasoning of foundation mod- els in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun- yuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation mod- els in visual contexts. InICLR, 2024. 7
2024
-
[36]
Intuitive physics: the straight-down belief and its origin.Journal of Experimental Psychology: Learning, Memory, and Cognition, 1983
Michael McCloskey, Allyson Washburn, and Linda Felch. Intuitive physics: the straight-down belief and its origin.Journal of Experimental Psychology: Learning, Memory, and Cognition, 1983. 1, 2
1983
-
[37]
Simplicits: Mesh-free, geometry- agnostic elastic simulation.ACM TOG, 2024
Vismay Modi, Nicholas Sharp, Or Perel, Shinjiro Sueda, and David IW Levin. Simplicits: Mesh-free, geometry- agnostic elastic simulation.ACM TOG, 2024. 3, 4, 11, 12
2024
-
[38]
Do generative video models understand physical principles?
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video mod- els understand physical principles?arXiv preprint arXiv:2501.09038, 2025. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
OpenAI. Gpt-5.5. https://openai.com, 2026. Propri- etary model; no public technical report. 5
2026
-
[40]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InICLR,
-
[41]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021. 5, 10
2021
-
[42]
Towards robust monoc- ular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.TPAMI, 2022
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monoc- ular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.TPAMI, 2022. 10
2022
-
[43]
Am-radio: Agglomerative vision founda- tion model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Am-radio: Agglomerative vision founda- tion model reduce all domains into one. InCVPR, 2024. 10
2024
-
[44]
Intphys 2019: A benchmark for visual intuitive physics understanding.TPAMI,
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, Véronique Izard, and Emmanuel Dupoux. Intphys 2019: A benchmark for visual intuitive physics understanding.TPAMI,
2019
-
[45]
Structure-from-motion revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. InCVPR, 2016. 3
2016
-
[46]
What does clip know about a red circle? visual prompt engineering for vlms
Aleksandar Shtedritski, Christian Rupprecht, and An- drea Vedaldi. What does clip know about a red circle? visual prompt engineering for vlms. InICCV, 2023. 8
2023
-
[47]
Alpha-clip: A clip model focusing on wherever you want
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, and Jiaqi Wang. Alpha-clip: A clip model focusing on wherever you want. InCVPR, 2024. 8
2024
-
[48]
Tenenbaum, Charles Kemp, Thomas L
Joshua B. Tenenbaum, Charles Kemp, Thomas L. Grif- fiths, and Noah D. Goodman. How to grow a mind: Statistics, structure, and abstraction.Science, 2011. 2
2011
-
[49]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. InNeurIPS, 2024. 5
2024
-
[50]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Fran- cisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers & distillation through attention. InICML, 2021. 10
2021
-
[51]
Physion++: Evaluating physical scene understanding that requires online infer- ence of different physical properties
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Josh Tenenbaum, Dan Yamins, Ju- dith Fan, and Kevin Smith. Physion++: Evaluating physical scene understanding that requires online infer- ence of different physical properties. InNeurIPS, 2023. 2
2023
-
[52]
Least-squares estimation of trans- formation parameters between two point patterns
Shinji Umeyama. Least-squares estimation of trans- formation parameters between two point patterns. TPAMI, 2002. 3
2002
-
[53]
Vggt: Visualgeometrygroundedtransformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, An- drea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visualgeometrygroundedtransformer. InCVPR,
-
[54]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS, 2022. 7
2022
-
[55]
Galileo: Perceiving physical object properties by integrating a physics engine with deep learning
Jiajun Wu, Ilker Yildirim, Joseph J Lim, Bill Freeman, and Josh Tenenbaum. Galileo: Perceiving physical object properties by integrating a physics engine with deep learning. InNeuRIPS, 2015. 2
2015
-
[56]
Physics 101: Learning physical object properties from unlabeled videos
Jiajun Wu, Joseph J Lim, Hongyi Zhang, Joshua B Tenenbaum, and William T Freeman. Physics 101: Learning physical object properties from unlabeled videos. InBMVC, 2016. 2
2016
-
[57]
Haotian Xue, Yunhao Ge, Yu Zeng, Zhaoshuo Li, Ming- Yu Liu, Yongxin Chen, and Jiaojiao Fan. Point-it-out: Benchmarking embodied reasoning for vision language models in multi-stage visual grounding.arXiv preprint arXiv:2509.25794, 2025. 8
-
[58]
Clevrer: Collision events for video representation and reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Ji- ajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning. InICLR, 2020. 2
2020
-
[59]
Mm-vet: Evaluating large multimodal models for integrated capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. InICML, 2024. 7, 8
2024
- [60]
-
[61]
Mmmu: A massive multi- discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi- discipline multimodal understanding and reasoning benchmark for ex...
2024
-
[62]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InICCV, 2023. 10
2023
-
[63]
A general protocol to probe large vision models for 3d physical understanding
Guanqi Zhan, Chuanxia Zheng, Weidi Xie, and Andrew Zisserman. A general protocol to probe large vision models for 3d physical understanding. InNeurIPS,
-
[64]
Morpheus: Benchmarking physical reasoning of video generative models with real physical experiments.arXiv, 2025
Chenyu Zhang, Daniil Cherniavskii, Antonios Tragoudaras, Antonios Vozikis, Thijmen Nijdam, Derck WE Prinzhorn, Mark Bodracska, Nicu Sebe, Andrii Zadaianchuk, and Efstratios Gavves. Morpheus: Benchmarking physical reasoning of video generative models with real physical experiments.arXiv, 2025. 2
2025
-
[65]
Zixin Zhang, Kanghao Chen, Xingwang Lin, Lutao Jiang, Xu Zheng, Yuanhuiyi Lyu, Litao Guo, Yinchuan Li, and Ying-Cong Chen. Phystoolbench: Bench- marking physical tool understanding for mllms.arXiv preprint arXiv:2510.09507, 2025. 2
-
[66]
Under- standing tools: Task-oriented object modeling, learning and recognition
Yixin Zhu, Yibiao Zhao, and Song Chun Zhu. Under- standing tools: Task-oriented object modeling, learning and recognition. InCVPR, 2015. 2
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.