Gravity-Aware Hierarchical Routing for Lightweight SensorLLM on Human Activity Recognition
Pith reviewed 2026-06-28 13:25 UTC · model grok-4.3
The pith
A gravity-aware hierarchical routing head improves static class recognition in compact SensorLLM models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
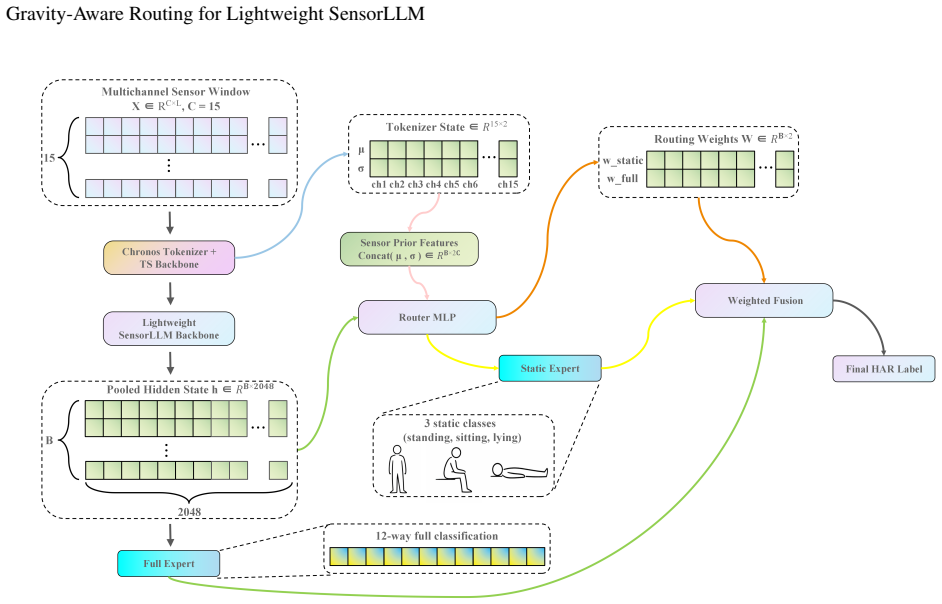
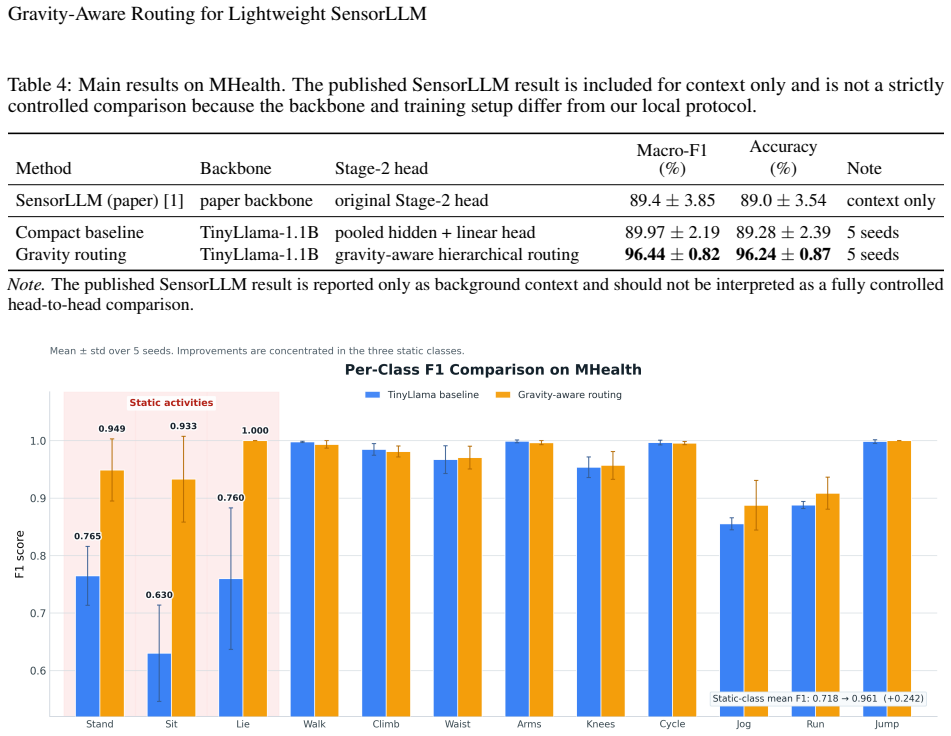
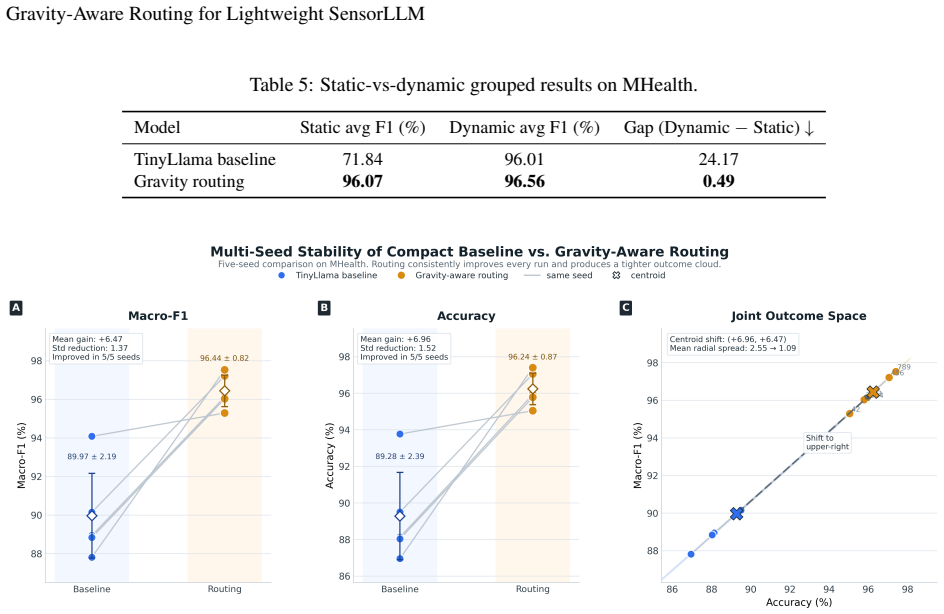
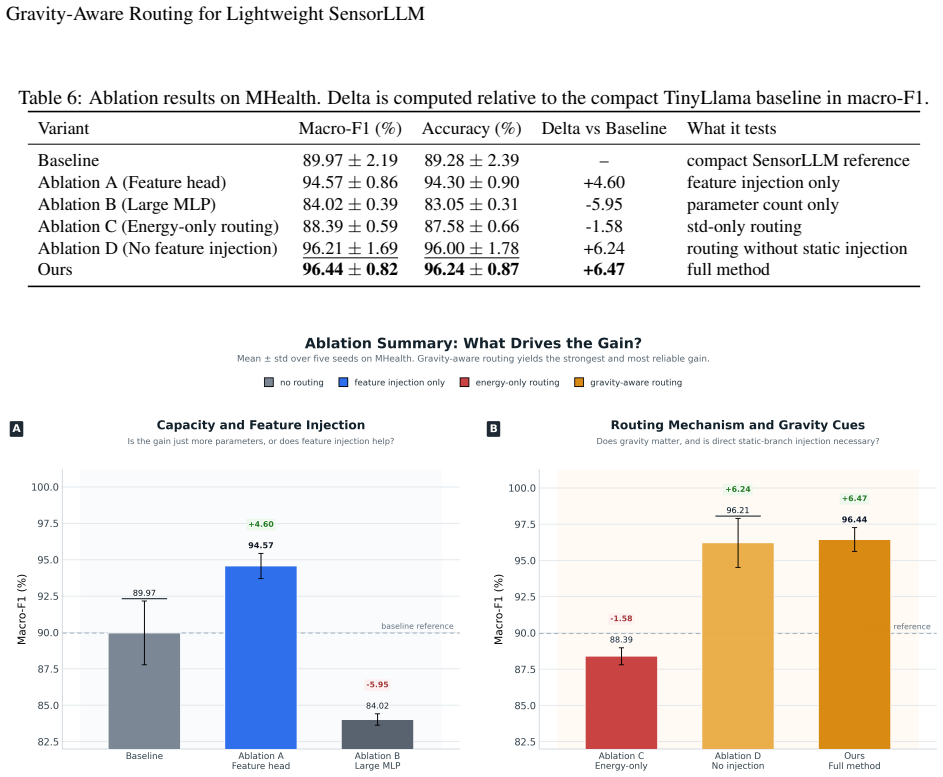
The gravity-aware hierarchical routing head uses per-channel mean and std from the Chronos tokenizer state to extract statistical cues related to posture and gravity direction, then adaptively combines a static expert and a full expert through soft routing together with a load-balancing loss, producing significant macro-F1 improvement on the MHealth dataset with minimal parameter overhead concentrated on static classes.
What carries the argument
Gravity-aware hierarchical routing head that performs soft routing between a static expert and a full expert using per-channel mean and std from the Chronos tokenizer state.
If this is right
- Static activity classes receive accuracy gains without harming dynamic activity performance.
- The added parameter count stays minimal enough for compact device deployment.
- The head functions as a post-alignment adaptation on already-aligned models.
- The load-balancing loss supports stable training of the routing decisions.
Where Pith is reading between the lines
- The same statistical cue extraction could be tested on other sensor datasets to check whether gravity-related routing generalizes.
- The approach might reduce the need for larger backbones in other compressed multimodal sensor tasks that show static-dynamic imbalances.
- Device-level power savings could result if the small overhead permits fully on-edge inference without cloud offload.
- Extending the routing to additional expert types might address further failure modes observed in compact sensor models.
Load-bearing premise
The per-channel mean and standard deviation from the Chronos tokenizer state reliably extract statistical cues about posture and gravity direction that support effective soft routing.
What would settle it
Ablating the routing head or replacing its mean/std inputs with random values on the MHealth dataset produces no macro-F1 gain on the static classes.
Figures
read the original abstract
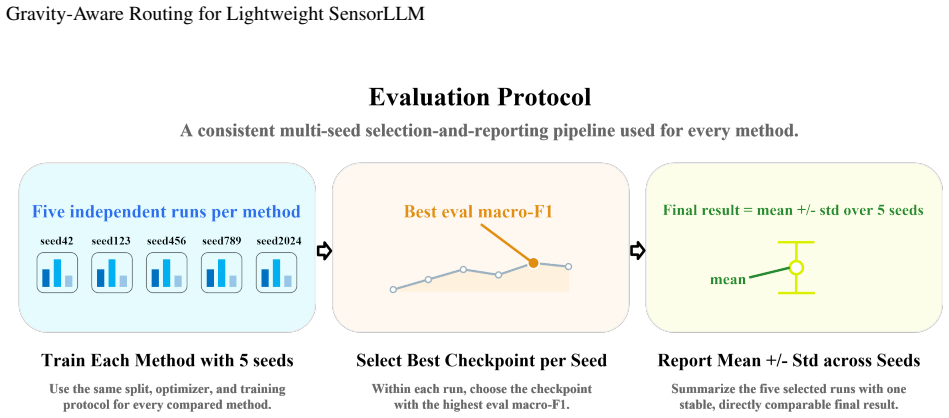
Recent studies on sensor-language alignment have shown that two-stage frameworks can improve the semantic modeling ability of wearable-sensor human activity recognition (HAR), where SensorLLM-style methods first perform motion-to-language alignment and then fine-tune the model for downstream tasks. However, our experiments reveal a consistent failure mode when the Stage 2 backbone is compressed to a compact model such as TinyLlama: recognition of dynamic activities remains relatively strong, while the discrimination of low-motion static classes such as standing, sitting, and lying degrades substantially. To address this issue, we propose a gravity-aware hierarchical routing head as a lightweight post-alignment adaptation built on top of an already aligned model, rather than a new large-scale pretraining framework. The method uses the per-channel mean and std from the Chronos tokenizer state to extract statistical cues related to posture and gravity direction, and adaptively combines a static expert and a full expert through soft routing, together with a load-balancing loss for stable training. On the MHealth dataset, this design significantly improves macro-F1 with minimal parameter overhead, and the gains are concentrated mainly on static classes while preserving strong performance on dynamic activities. As a first arXiv disclosure, the current paper reports results on a single dataset only, with the goal of highlighting the core method and laying the groundwork for broader evaluation in future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a gravity-aware hierarchical routing head as a lightweight post-alignment adaptation for compressed SensorLLM models (e.g., TinyLlama) in wearable-sensor human activity recognition. It extracts per-channel mean and standard deviation from the Chronos tokenizer state to drive soft routing between a static expert and a full expert, augmented by a load-balancing loss. The central empirical claim is that this yields significant macro-F1 gains on the MHealth dataset, concentrated on static classes (standing, sitting, lying) while preserving dynamic activity performance, at minimal parameter overhead. The work is presented as a first arXiv disclosure focused on a single dataset.
Significance. If the reported gains hold under scrutiny, the method supplies a practical, low-overhead fix for a documented failure mode in two-stage sensor-language alignment when backbones are compressed. By reusing existing tokenizer statistics rather than introducing new pretraining or heavy modules, it could support more deployable SensorLLM variants on resource-limited hardware. The targeted focus on static vs. dynamic discrimination via gravity cues is a focused contribution within the HAR literature.
major comments (3)
- [Abstract] Abstract: the central claim states that the design 'significantly improves macro-F1' on MHealth with gains 'concentrated mainly on static classes,' yet supplies no numerical deltas, baseline models, ablation results, error bars, or statistical tests. This absence makes it impossible to evaluate the magnitude or reliability of the improvement that underpins the paper's contribution.
- [Method] Method description: the assumption that per-channel mean and std from the Chronos tokenizer state reliably encode posture/gravity cues sufficient for effective soft routing is load-bearing for the claimed gains, but the manuscript provides no supporting analysis, visualization, or sensitivity test of these statistics. Without this, it remains unclear whether the routing mechanism is doing the intended work or whether gains could arise from other factors.
- [Experiments] Experiments: results are confined to a single dataset (MHealth) despite the acknowledged limitation. Given that the failure mode is presented as consistent across compressed backbones, the absence of at least one additional dataset or cross-sensor validation weakens the generality of the conclusion that the routing head addresses the static-class degradation broadly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the three major comments, indicating revisions where appropriate while defending the manuscript's scope as an initial disclosure.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim states that the design 'significantly improves macro-F1' on MHealth with gains 'concentrated mainly on static classes,' yet supplies no numerical deltas, baseline models, ablation results, error bars, or statistical tests. This absence makes it impossible to evaluate the magnitude or reliability of the improvement that underpins the paper's contribution.
Authors: We agree that the abstract should be more self-contained. In the revised version we will insert the key quantitative results (macro-F1 deltas on static classes versus the compressed baseline, with reference to the models and ablations already reported in Section 4) while keeping the abstract concise. The full experimental tables, including error bars from multiple runs, remain in the body of the paper. revision: yes
-
Referee: [Method] Method description: the assumption that per-channel mean and std from the Chronos tokenizer state reliably encode posture/gravity cues sufficient for effective soft routing is load-bearing for the claimed gains, but the manuscript provides no supporting analysis, visualization, or sensitivity test of these statistics. Without this, it remains unclear whether the routing mechanism is doing the intended work or whether gains could arise from other factors.
Authors: We accept this observation. The revised manuscript will include a new subsection (or appendix) with (i) histograms and t-SNE visualizations of the per-channel mean/std statistics stratified by static versus dynamic activities, (ii) a sensitivity analysis showing how perturbations to these statistics affect routing weights, and (iii) an ablation that replaces the tokenizer statistics with random features to confirm that the gravity-related signal is necessary for the observed gains. revision: yes
-
Referee: [Experiments] Experiments: results are confined to a single dataset (MHealth) despite the acknowledged limitation. Given that the failure mode is presented as consistent across compressed backbones, the absence of at least one additional dataset or cross-sensor validation weakens the generality of the conclusion that the routing head addresses the static-class degradation broadly.
Authors: The manuscript already states explicitly that it is a first arXiv disclosure focused on a single dataset to introduce the core method. Because the failure mode is documented across multiple compressed backbones on MHealth, the immediate contribution is the lightweight fix rather than a broad benchmark. We will strengthen the discussion section to emphasize this scope and to outline planned multi-dataset validation in follow-up work; adding new datasets at this stage would change the paper's stated purpose. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical lightweight adaptation method using per-channel mean/std statistics from an existing Chronos tokenizer to drive soft routing between static and full experts, plus a load-balancing loss. No derivation chain, equations, predictions, or self-citations are presented that reduce any claim to its inputs by construction. Performance gains on MHealth are reported as experimental outcomes with explicit acknowledgment of single-dataset scope. The method is internally consistent and does not rely on fitted parameters renamed as predictions or uniqueness theorems from prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Per-channel mean and std from Chronos tokenizer state provide usable cues for posture and gravity direction
invented entities (1)
-
gravity-aware hierarchical routing head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zechen Li, Shohreh Deldari, Linyao Chen, Hao Xue, and Flora D. Salim. Sensorllm: Aligning large language models with motion sensors for human activity recognition. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 354–379. Association for Computational Linguistics, 2025
2025
-
[2]
Mhealth dataset
Oresti Banos, Rafael García, and Alejandro Saez. Mhealth dataset. UCI Machine Learning Repository, 2014
2014
-
[3]
Human activity recognition using inertial sensors in a smartphone: An overview.Sensors, 19(14):3213, 2019
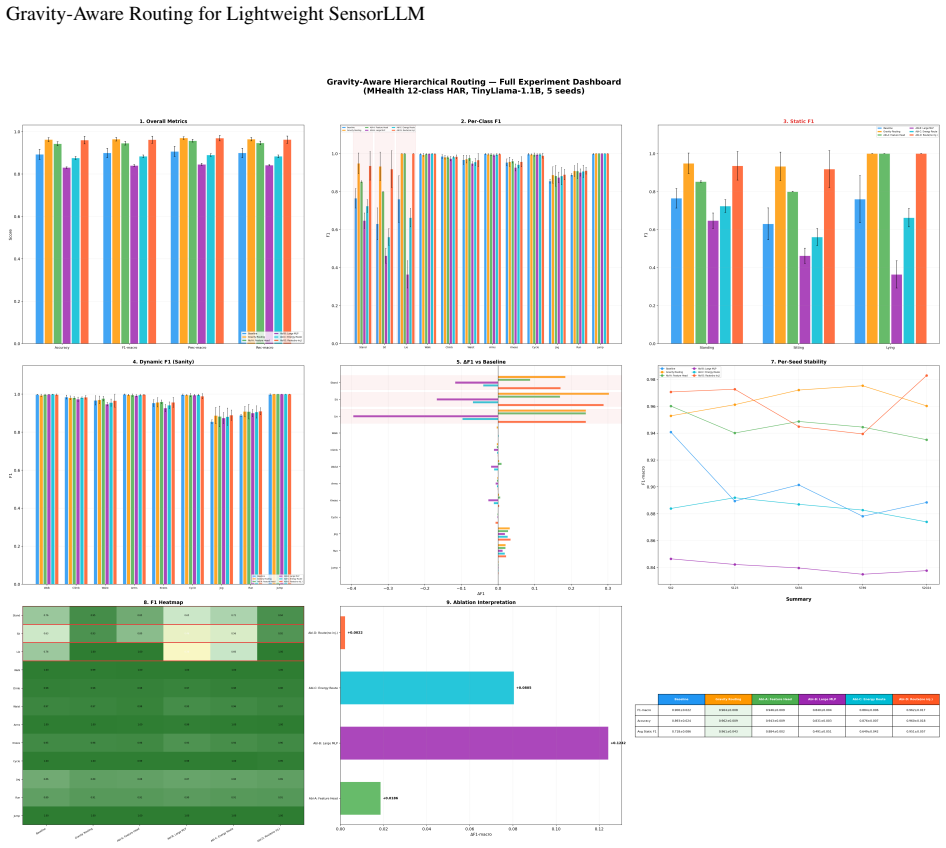
Wesllen Sousa Lima, Eduardo Souto, Khalil El-Khatib, Roozbeh Jalali, and Joao Gama. Human activity recognition using inertial sensors in a smartphone: An overview.Sensors, 19(14):3213, 2019. 15 Gravity-Aware Routing for Lightweight SensorLLM Figure 6: Comprehensive overview of the full experimental results on MHealth, summarizing overall metrics, per-clas...
2019
-
[4]
Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition.Sensors, 16(1):115, 2016
Francisco Javier Ordóñez and Daniel Roggen. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition.Sensors, 16(1):115, 2016
2016
-
[5]
TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Reliable recognition of lying, sitting, and standing with a hip-worn accelerometer.Scandinavian Journal of Medicine & Science in Sports, 28(3):1092–1102, 2018
Henri Vähä-Ypyä, Pauliina Husu, Jaana Suni, Tommi Vasankari, and Harri Sievänen. Reliable recognition of lying, sitting, and standing with a hip-worn accelerometer.Scandinavian Journal of Medicine & Science in Sports, 28(3):1092–1102, 2018
2018
-
[7]
Ali Heydari, Girish Narayanswamy, Maxwell A
Yuwei Zhang, Kumar Ayush, Siyuan Qiao, A. Ali Heydari, Girish Narayanswamy, Maxwell A. Xu, Ahmed A. Metwally, Shawn Xu, Jake Garrison, Xuhai Xu, Tim Althoff, Yun Liu, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Cecilia Mascolo, Xin Liu, Daniel McDuff, and Yuzhe Yang. Sensorlm: Learning the language of wearable sensors.arXiv preprint arXiv:...
-
[8]
Griffin, Lisa Marsch, Michael V
Yuliang Chen, Arvind Pillai, Yu Yvonne Wu, Tess Z. Griffin, Lisa Marsch, Michael V . Heinz, Nicholas C. Jacobson, and Andrew Campbell. Learning transferable sensor models via language-informed pretraining.arXiv preprint arXiv:2603.11950, 2026. 16 Gravity-Aware Routing for Lightweight SensorLLM
-
[9]
Arvind Pillai, Dimitris Spathis, Subigya Nepal, Amanda C. Collins, Daniel M. Mackin, Michael V . Heinz, Tess Z. Griffin, Nicholas C. Jacobson, and Andrew Campbell. Time2lang: Bridging time-series foundation models and large language models for health sensing beyond prompting.arXiv preprint arXiv:2502.07608, 2025
-
[10]
Zhe Xie, Zeyan Li, Xiao He, Longlong Xu, Xidao Wen, Tieying Zhang, Jianjun Chen, Rui Shi, and Dan Pei. Chatts: Aligning time series with llms via synthetic data for enhanced understanding and reasoning.arXiv preprint arXiv:2412.03104, 2024
-
[11]
Scaling wearable foundation models.arXiv preprint arXiv:2410.13638, 2024
Girish Narayanswamy, Xin Liu, Kumar Ayush, Yuzhe Yang, Xuhai Xu, Shun Liao, Jake Garrison, Shyam Tailor, Jake Sunshine, Yun Liu, Tim Althoff, Shrikanth Narayanan, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Samy Abdel-Ghaffar, and Daniel McDuff. Scaling wearable foundation models.arXiv preprint arXiv:2410.13638, 2024
-
[12]
Justin Cosentino, Anastasiya Belyaeva, Xin Liu, Nicholas A. Furlotte, Zhun Yang, Chace Lee, Erik Schenck, Yojan Patel, Jian Cui, Logan Douglas Schneider, Robby Bryant, Ryan G. Gomes, Allen Jiang, Roy Lee, Yun Liu, Javier Perez, Jameson K. Rogers, Cathy Speed, Shyam Tailor, Megan Walker, Jeffrey Yu, Tim Althoff, Conor Heneghan, John Hernandez, Mark Malhotr...
-
[13]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Out- rageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[15]
Holgado-Terriza, Miguel Damas, Hector Pomares, Ignacio Rojas, Alejandro Saez, and Claudia Villalonga
Oresti Banos, Rafael García, Juan A. Holgado-Terriza, Miguel Damas, Hector Pomares, Ignacio Rojas, Alejandro Saez, and Claudia Villalonga. mhealthdroid: A novel framework for agile development of mobile health applications. InInternational Work-Conference on Ambient Assisted Living, pages 91–98. Springer, 2014
2014
-
[16]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Yuyang Wang. Chronos: Learning the language ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Wearable sensor-based human activity recognition with transformer model.Sensors, 22(5):1911, 2022
Iveta Dirgová Luptáková, Martin Kubovˇcík, and Jiˇrí Pospíchal. Wearable sensor-based human activity recognition with transformer model.Sensors, 22(5):1911, 2022. 17
1911
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.