Intra-Modal Neighbors Never Lie: Rectifying Inter-Modal Noisy Correspondence via Graph-Based Intra-Modal Reasoning
Pith reviewed 2026-06-28 11:01 UTC · model grok-4.3
The pith
Intra-modal neighbor graphs synthesize continuous soft prototypes to rectify noisy cross-modal correspondences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
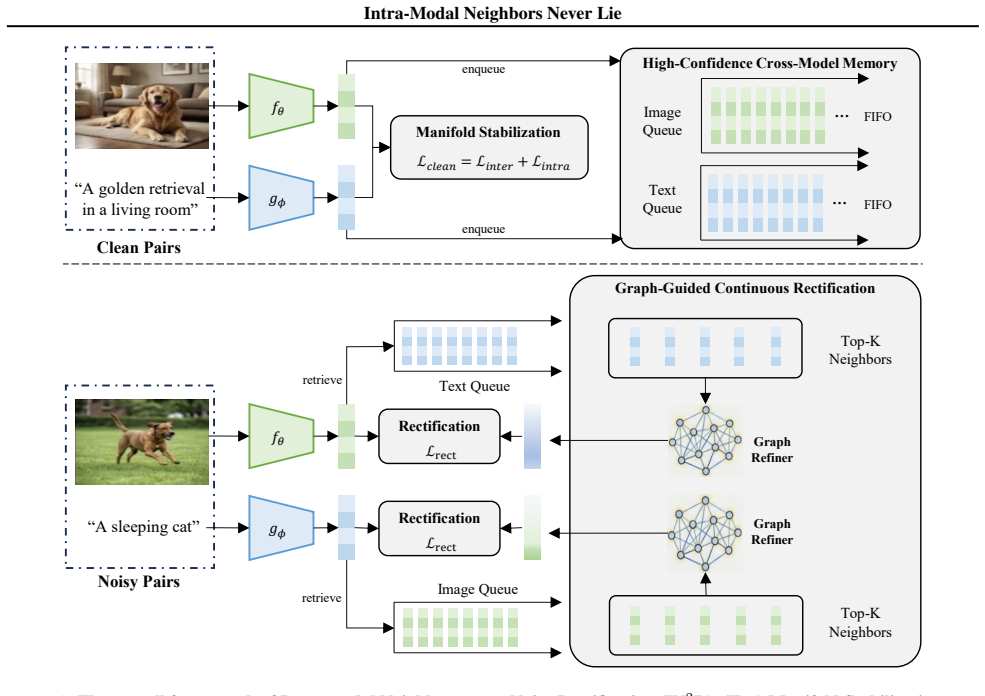
IN2R shifts the paradigm from searching for a substitute discrete label to synthesizing a reliable continuous soft prototype by performing relational reasoning over intra-modal neighbors retrieved from a dynamic Cross-Modal Memory, leveraging the intrinsic geometric stability of intra-modal data to reflect the consensus of the local semantic neighborhood and thereby rectifying inter-modal misalignment.
What carries the argument
The Graph Refiner, which performs relational reasoning over neighbors from a dynamic Cross-Modal Memory to synthesize a continuous soft prototype that reflects neighborhood consensus instead of propagating discrete labels.
If this is right
- Reduces single-point fragility by replacing any one proxy with neighborhood consensus.
- Avoids discretization error by supplying continuous rather than hard supervision targets.
- Outperforms prior methods on Flickr30K, MS-COCO, and CC152K retrieval benchmarks.
- Maintains performance gains by relying only on the geometric structure already present inside each modality.
Where Pith is reading between the lines
- The same neighbor-consensus mechanism could be tested on noisy audio-text or video-text pairs.
- If the geometric-stability premise holds across modalities, large-scale dataset cleaning pipelines might be simplified.
- An ablation that replaces the graph refiner with simple averaging of neighbors would isolate how much the relational reasoning step contributes.
Load-bearing premise
Intra-modal data possesses intrinsic geometric stability that enables reliable relational reasoning over neighbors to synthesize supervision targets without introducing new misalignment errors.
What would settle it
Construct a test set in which intra-modal neighbors are sampled to have deliberately low semantic agreement and measure whether the synthesized soft prototypes then degrade retrieval accuracy relative to discrete-selection baselines.
Figures

read the original abstract
Large-scale web-harvested datasets have fueled the progress of cross-modal retrieval but inevitably suffer from noisy correspondence, which severely degrades model generalization. Existing methods primarily address this by filtering out noise or seeking a substitute label, yet they predominantly remain bound by a "Discrete Selection" paradigm. We argue that relying on a single discrete proxy induces Single-Point Fragility and Discretization Error. To overcome these limitations, we propose a novel framework, Intra-modal Neighbor-aware Noise Rectification (IN2R), which shifts the paradigm from searching for a substitute to synthesizing a reliable supervision target. Leveraging the intrinsic geometric stability of intra-modal data, IN2R employs a Graph Refiner to perform relational reasoning over neighbors retrieved from a dynamic Cross-Model Memory. Instead of propagating discrete labels, our method synthesizes a continuous, soft prototype that reflects the consensus of the local semantic neighborhood, effectively rectifying inter-modal misalignment. Extensive experiments on Flickr30K, MS-COCO, and CC152K demonstrate that IN2R significantly outperforms state-of-the-art methods. Our code and pre-trained models are publicly available at https://github.com/liuyyy111/IN2R.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that noisy correspondences in web-harvested cross-modal datasets degrade retrieval performance, and that prior methods are limited by a discrete selection paradigm causing single-point fragility and discretization error. It proposes IN2R, which uses a Graph Refiner to perform relational reasoning over neighbors retrieved from a dynamic Cross-Model Memory, synthesizing continuous soft prototypes that reflect the consensus of the local intra-modal semantic neighborhood. The approach relies on the intrinsic geometric stability of intra-modal data to rectify inter-modal misalignment without propagating discrete labels. Experiments on Flickr30K, MS-COCO, and CC152K report significant gains over state-of-the-art methods, with code and models released publicly.
Significance. If the central claim holds, the shift from discrete selection to continuous prototype synthesis could meaningfully improve robustness in noisy multimodal retrieval, particularly for web-scale data. The public code release is a clear strength for reproducibility.
major comments (2)
- [§3.2] §3.2 (Graph Refiner and Cross-Model Memory): The claim that intra-modal geometric stability enables reliable neighbor-based prototype synthesis is load-bearing, yet the manuscript provides no analysis showing that the intra-modal embeddings remain undistorted when the entire pipeline (including the feature extractor) is trained end-to-end on noisy inter-modal pairs. If neighbors reflect the same misalignment the method aims to correct, the soft prototype can propagate rather than rectify errors.
- [§4.2, Table 2] §4.2, Table 2 (noise robustness experiments): The performance gains are presented as robust across noise ratios, but the evaluation does not include controls that isolate whether the Graph Refiner's relational reasoning improves neighbor reliability independently of the memory update schedule; without such an ablation the attribution of gains to the continuous prototype remains under-supported.
minor comments (3)
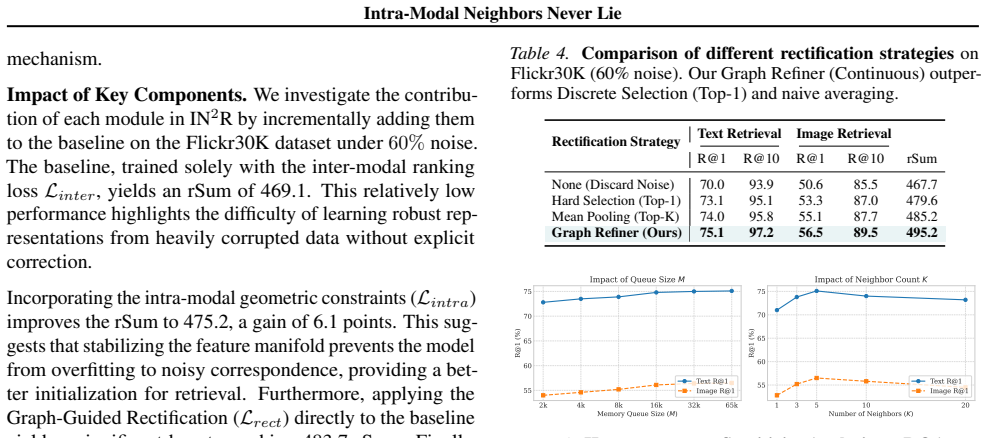
- [§2] §2 (Related Work): Several recent graph-based noisy-label papers in multimodal settings are not cited; adding them would better situate the contribution.
- [Figure 4] Figure 4: The t-SNE visualizations would benefit from explicit labeling of the synthesized prototypes versus original noisy pairs to illustrate the rectification effect.
- [Eq. (7)] Eq. (7): The definition of the soft prototype aggregation uses notation that overlaps with standard graph attention; a brief remark distinguishing the two would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, acknowledging where additional analysis or experiments would strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Graph Refiner and Cross-Model Memory): The claim that intra-modal geometric stability enables reliable neighbor-based prototype synthesis is load-bearing, yet the manuscript provides no analysis showing that the intra-modal embeddings remain undistorted when the entire pipeline (including the feature extractor) is trained end-to-end on noisy inter-modal pairs. If neighbors reflect the same misalignment the method aims to correct, the soft prototype can propagate rather than rectify errors.
Authors: We agree this is a load-bearing assumption and that the current manuscript lacks explicit analysis of intra-modal embedding stability under end-to-end training on noisy pairs. While the dynamic Cross-Modal Memory and graph-based consensus are intended to mitigate error propagation by synthesizing soft prototypes rather than propagating discrete labels, we do not provide quantitative evidence (e.g., neighbor consistency metrics or distortion measurements across training stages) to confirm that intra-modal geometry remains sufficiently stable. In the revision we will add a dedicated analysis subsection with such measurements on the training dynamics. revision: yes
-
Referee: [§4.2, Table 2] §4.2, Table 2 (noise robustness experiments): The performance gains are presented as robust across noise ratios, but the evaluation does not include controls that isolate whether the Graph Refiner's relational reasoning improves neighbor reliability independently of the memory update schedule; without such an ablation the attribution of gains to the continuous prototype remains under-supported.
Authors: We acknowledge that the existing experiments do not isolate the Graph Refiner's contribution from the memory update schedule. The reported gains are shown across noise ratios, but without an ablation that holds the memory schedule fixed while enabling/disabling the relational reasoning step, attribution to continuous prototype synthesis is indeed under-supported. We will add this controlled ablation (e.g., variants with and without the Graph Refiner under identical memory update rules) to the revised experimental section. revision: yes
Circularity Check
No circularity: derivation relies on independent geometric assumption and graph synthesis, not self-definition or fitted inputs
full rationale
The abstract and method description present IN2R as a shift from discrete selection to synthesizing continuous soft prototypes via graph reasoning on intra-modal neighbors, grounded in the stated assumption of intrinsic geometric stability. No equations are shown that reduce the output prototype or rectification to a fitted parameter or self-referential definition by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the central claim does not rename a known result or smuggle an ansatz. The pipeline is presented as adding independent relational reasoning content, making the derivation self-contained against external benchmarks like the reported experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Learning with noisy correspondence for cross-modal matching , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Proceedings of the 30th ACM International Conference on Multimedia , pages=
Deep evidential learning with noisy correspondence for cross-modal retrieval , author=. Proceedings of the 30th ACM International Conference on Multimedia , pages=
-
[3]
IEEE Transactions on Multimedia , volume=
Learning from noisy correspondence with tri-partition for cross-modal matching , author=. IEEE Transactions on Multimedia , volume=. 2023 , publisher=
2023
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Bicro: Noisy correspondence rectification for multi-modality data via bi-directional cross-modal similarity consistency , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
ReCon: Enhancing True Correspondence Discrimination through Relation Consistency for Robust Noisy Correspondence Learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating noisy correspondence by geometrical structure consistency learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Noisy correspondence learning with meta similarity correction , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
NAC: Mitigating Noisy Correspondence in Cross-Modal Matching Via Neighbor Auxiliary Corrector , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning to rematch mismatched pairs for robust cross-modal retrieval , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , year=
Seeking proxy point via stable feature space for noisy correspondence learning , author=. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , year=
-
[11]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Noise Self-Correction via Relation Propagation for Robust Cross-Modal Retrieval , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[12]
CVPR , pages=
Improving Cross-Modal Retrieval with Set of Diverse Embeddings , author=. CVPR , pages=
-
[13]
TNNLS , year=
BCAN: Bidirectional correct attention network for cross-modal retrieval , author=. TNNLS , year=
-
[14]
ACMMM , pages=
Context-aware multi-view summarization network for image-text matching , author=. ACMMM , pages=
-
[15]
CVPR , pages=
Probabilistic embeddings for cross-modal retrieval , author=. CVPR , pages=
-
[16]
FirstName LastName , title =
-
[17]
FirstName Alpher , title =
-
[18]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[19]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[20]
CVPR , pages =
FirstName Alpher and FirstName Gamow , title =. CVPR , pages =
-
[21]
ECCV , pages=
Stacked cross attention for image-text matching , author=. ECCV , pages=
-
[22]
ICLR , year=
Order-embeddings of images and language , author=. ICLR , year=
-
[23]
CVPR , pages=
Improving referring expression grounding with cross-modal attention-guided erasing , author=. CVPR , pages=
-
[24]
CVPR , pages=
Learning to evaluate image captioning , author=. CVPR , pages=
-
[25]
CVPR , pages=
Dual attention networks for multimodal reasoning and matching , author=. CVPR , pages=
-
[26]
CVPR , pages=
Scene graph generation with external knowledge and image reconstruction , author=. CVPR , pages=
-
[27]
CVPR , pages=
Knowledge aided consistency for weakly supervised phrase grounding , author=. CVPR , pages=
-
[28]
IJCAI , pages=
Position Focused Attention Network for Image-Text Matching , author=. IJCAI , pages=
-
[29]
CVPR , pages=
IMRAM: Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval , author=. CVPR , pages=
-
[30]
ACMMM , pages=
Focus your attention: A bidirectional focal attention network for image-text matching , author=. ACMMM , pages=
-
[31]
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models
Unifying visual-semantic embeddings with multimodal neural language models , author=. arXiv preprint arXiv:1411.2539 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
BMVC , year=
Vse++: Improving visual-semantic embeddings with hard negatives , author=. BMVC , year=
-
[33]
CVPR , pages=
Deep visual-semantic alignments for generating image descriptions , author=. CVPR , pages=
-
[34]
CVPR , pages=
Bottom-up and top-down attention for image captioning and visual question answering , author=. CVPR , pages=
-
[35]
TPAMI , volume=
Faster r-cnn: Towards real-time object detection with region proposal networks , author=. TPAMI , volume=. 2016 , publisher=
2016
-
[36]
Transactions of the Association for Computational Linguistics , volume=
Grounded compositional semantics for finding and describing images with sentences , author=. Transactions of the Association for Computational Linguistics , volume=. 2014 , publisher=
2014
-
[37]
ICCV , pages=
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models , author=. ICCV , pages=
-
[38]
ECCV , pages=
Microsoft coco: Common objects in context , author=. ECCV , pages=
-
[39]
, author=
Multi-Level Visual-Semantic Alignments with Relation-Wise Dual Attention Network for Image and Text Matching. , author=. IJCAI , pages=
-
[40]
ACM Transactions on Multimedia Computing, Communications, and Applications (ACM Trans
Dual-Path Convolutional Image-Text Embeddings with Instance Loss , author=. ACM Transactions on Multimedia Computing, Communications, and Applications (ACM Trans. Multim. Comput. Commun. Appl.) , volume=. 2020 , publisher=
2020
-
[41]
CVPR , pages=
Learning semantic concepts and order for image and sentence matching , author=. CVPR , pages=
-
[42]
ICCV , pages=
Visual semantic reasoning for image-text matching , author=. ICCV , pages=
-
[43]
NeurIPS , pages=
Devise: A deep visual-semantic embedding model , author=. NeurIPS , pages=
-
[44]
NeurIPS , volume=
Imagenet classification with deep convolutional neural networks , author=. NeurIPS , volume=
-
[45]
Efficient Estimation of Word Representations in Vector Space
Efficient estimation of word representations in vector space , author=. arXiv preprint arXiv:1301.3781 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[47]
EMNLP , year=
Learning phrase representations using RNN encoder-decoder for statistical machine translation , author=. EMNLP , year=
-
[48]
CVPR , pages=
Rich feature hierarchies for accurate object detection and semantic segmentation , author=. CVPR , pages=
-
[49]
Neural computation , volume=
Canonical correlation analysis: An overview with application to learning methods , author=. Neural computation , volume=. 2004 , publisher=
2004
-
[50]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv preprint arXiv:1810.04805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Improving language understanding by generative pre-training , author=
-
[52]
IEICE TRANSACTIONS on Information and Systems , volume=
Target-Oriented Deformation of Visual-Semantic Embedding Space , author=. IEICE TRANSACTIONS on Information and Systems , volume=. 2021 , publisher=
2021
-
[53]
ACM Trans
Fine-grained Visual Textual Alignment for Cross-Modal Retrieval using Transformer Encoders , author=. ACM Trans. Multim. Comput. Commun. Appl. , year=
-
[54]
ICPR , year=
Transformer reasoning network for image-text matching and retrieval , author=. ICPR , year=
-
[55]
ACMMM , pages=
Matching images and text with multi-modal tensor fusion and re-ranking , author=. ACMMM , pages=
-
[56]
ICCV , pages=
Saliency-guided attention network for image-sentence matching , author=. ICCV , pages=
-
[57]
IJCV , volume=
Visual genome: Connecting language and vision using crowdsourced dense image annotations , author=. IJCV , volume=. 2017 , publisher=
2017
-
[58]
ICLR , pages=
Adam: A method for stochastic gradient descent , author=. ICLR , pages=
-
[59]
CVPR , pages=
Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models , author=. CVPR , pages=
-
[60]
ICCV , pages=
Camp: Cross-modal adaptive message passing for text-image retrieval , author=. ICCV , pages=
-
[61]
CVPR , pages=
Context-aware attention network for image-text retrieval , author=. CVPR , pages=
-
[62]
AAAI , pages=
Expressing objects just like words: Recurrent visual embedding for image-text matching , author=. AAAI , pages=
-
[63]
ECCV , pages=
Consensus-aware visual-semantic embedding for image-text matching , author=. ECCV , pages=
-
[64]
ICCV , pages=
Adversarial representation learning for text-to-image matching , author=. ICCV , pages=
-
[65]
CVPR , pages=
Graph structured network for image-text matching , author=. CVPR , pages=
-
[66]
TPAMI , volume=
Discriminative learning and recognition of image set classes using canonical correlations , author=. TPAMI , volume=. 2007 , publisher=
2007
-
[67]
ACMMM , pages=
A new approach to cross-modal multimedia retrieval , author=. ACMMM , pages=
-
[68]
ICCV , pages=
Multi-label cross-modal retrieval , author=. ICCV , pages=
-
[69]
TIP , volume=
Cross-modal subspace learning via pairwise constraints , author=. TIP , volume=. 2015 , publisher=
2015
-
[70]
TIP , volume=
Multimodal discriminative binary embedding for large-scale cross-modal retrieval , author=. TIP , volume=. 2016 , publisher=
2016
-
[71]
TIP , volume=
Learning discriminative binary codes for large-scale cross-modal retrieval , author=. TIP , volume=. 2017 , publisher=
2017
-
[72]
TIP , volume=
Modality-specific cross-modal similarity measurement with recurrent attention network , author=. TIP , volume=. 2018 , publisher=
2018
-
[73]
TIP , volume=
Visual-textual joint relevance learning for tag-based social image search , author=. TIP , volume=. 2012 , publisher=
2012
-
[74]
TIP , volume=
Unifying the video and question attentions for open-ended video question answering , author=. TIP , volume=. 2017 , publisher=
2017
-
[75]
TIP , volume=
Deep Relation Embedding for Cross-Modal Retrieval , author=. TIP , volume=. 2020 , publisher=
2020
-
[76]
TIP , volume=
Learning Aligned Image-Text Representations Using Graph Attentive Relational Network , author=. TIP , volume=. 2021 , publisher=
2021
-
[77]
ACM Trans
CM-GANs: Cross-modal generative adversarial networks for common representation learning , author=. ACM Trans. Multim. Comput. Commun. Appl. , volume=. 2019 , publisher=
2019
-
[78]
CVPR , pages=
Instance-aware image and sentence matching with selective multimodal lstm , author=. CVPR , pages=
-
[79]
ICIP , pages=
Attend, Correct And Focus: A Bidirectional Correct Attention Network For Image-Text Matching , author=. ICIP , pages=
-
[80]
CVPR , pages=
Learning the best pooling strategy for visual semantic embedding , author=. CVPR , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.