When Seeing Is Not Believing -- A Benchmark for Search-Grounded Video Misinformation Detection
Pith reviewed 2026-06-28 10:48 UTC · model grok-4.3
The pith
Frontier multimodal models reach only 61.43 percent point-level accuracy on a benchmark requiring web search to detect video misinformation undetectable by sight alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EVID-Bench comprises 222 videos across nine manipulation types that require cross-video comparison via open-web search because the misinformation cannot be verified from the input video alone; when nine frontier multimodal models are evaluated under a retrieval-augmented verification protocol, the best system attains 61.43 percent point-level accuracy and 43.24 percent video-level accuracy, with AI-generated manipulations remaining the hardest category.
What carries the argument
EVID-Bench, a collection of 222 videos spanning nine manipulation types that forces systems to retrieve and compare external videos to expose evidence-dependent falsehoods.
If this is right
- Systems must develop more reliable methods for locating and aligning evidence across multiple video sources.
- AI-generated manipulations require dedicated handling beyond standard editing detection.
- Search procedures need safeguards against premature termination and irrelevant focus.
- Performance gaps between point-level and video-level accuracy indicate that holistic narrative understanding remains weak.
Where Pith is reading between the lines
- Expanding the benchmark to include longer videos or additional languages could reveal whether the observed limitations scale.
- Integrating temporal alignment tools with retrieval might address the misattribution of synthetic content.
- The benchmark could serve as a testbed for hybrid human-AI verification pipelines in real misinformation pipelines.
Load-bearing premise
The chosen 222 videos and nine manipulation types form a representative sample of evidence-dependent video misinformation that cannot be solved by visual inspection alone.
What would settle it
A retrieval-augmented model that reaches above 85 percent video-level accuracy on EVID-Bench while preserving accuracy on standard visual video tasks would falsify the claim that current methods are insufficient.
Figures



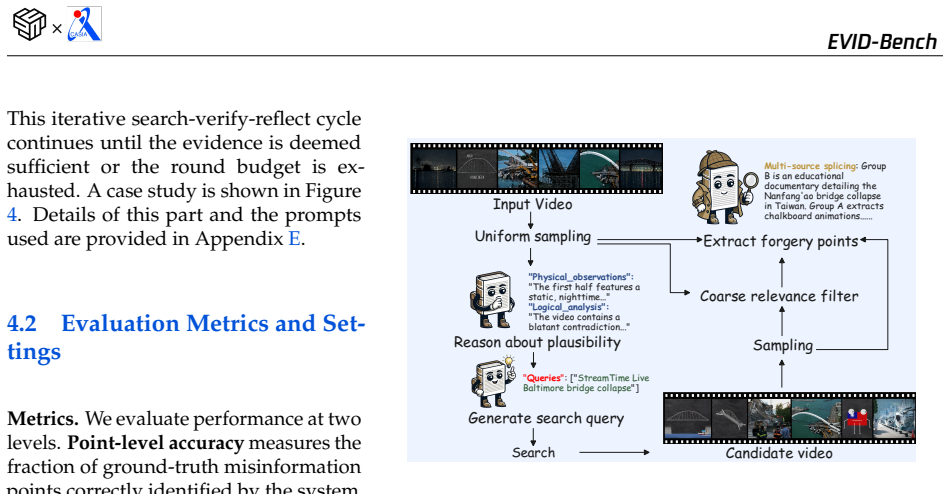
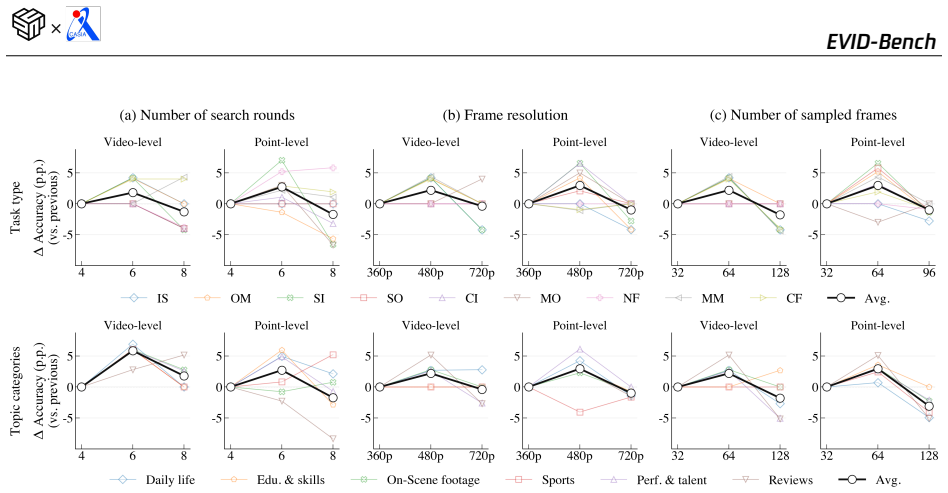
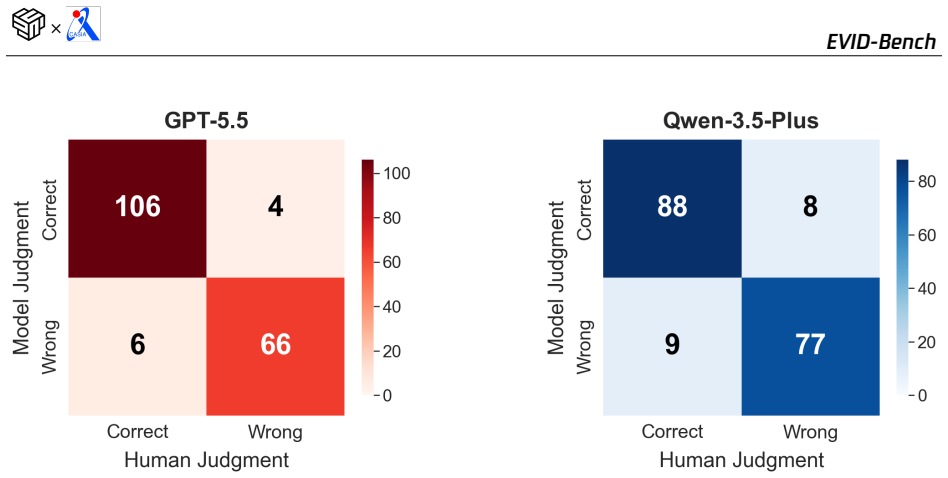
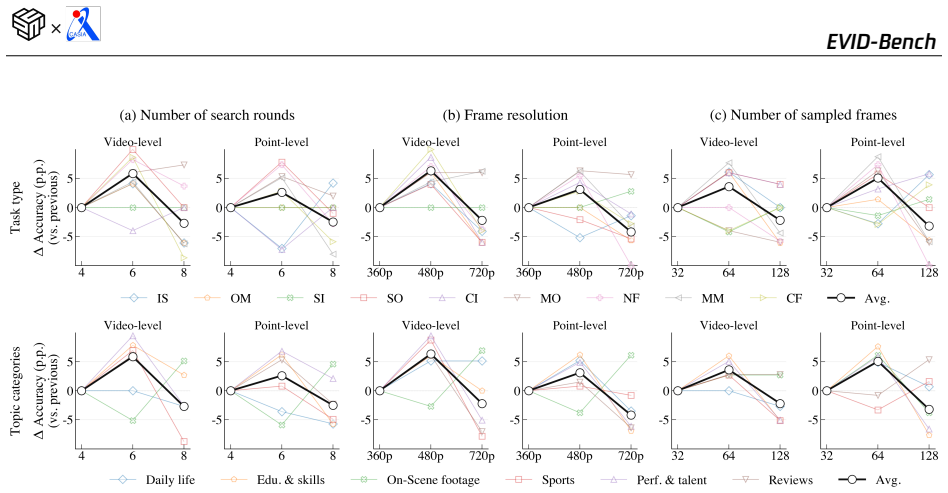
read the original abstract
Video misinformation increasingly operates at the semantic and evidential level: authentic footage may be selectively edited, temporally reordered, spliced across sources, or augmented with AI-generated content to construct false narratives. Such evidence-dependent manipulations cannot be reliably verified from the input video alone, because the missing, reordered, replaced, or recontextualized evidence lies outside the video itself. We introduce \textbf{EVID-Bench}, a benchmark for search-grounded video misinformation detection, where a system must search the open web for related videos and identify what information is false through cross-video comparison. EVID-Bench comprises 222 videos spanning 9 manipulation types across 3 categories: AI generation, single-source editing, and multi-source editing. All samples are verified to be undetectable by frontier models through visual inspection alone. We evaluate nine frontier multimodal models using a retrieval-augmented verification baseline. The best system achieves only 61.43\% point-level accuracy and 43.24\% video-level accuracy, while AI-generated manipulations remain especially challenging. Error analysis reveals recurring challenges: models fixate on irrelevant anchors, misattribute synthetic content to editorial splicing, and terminate search prematurely before fully explaining the manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EVID-Bench, a benchmark of 222 videos spanning 9 manipulation types in three categories (AI generation, single-source editing, multi-source editing) for search-grounded video misinformation detection. It asserts that all samples are verified to be undetectable by frontier models via visual inspection alone, evaluates nine multimodal models with a retrieval-augmented verification baseline, and reports that the best system reaches only 61.43% point-level accuracy and 43.24% video-level accuracy, with AI-generated manipulations remaining especially difficult. Error analysis identifies recurring issues including fixation on irrelevant anchors, misattribution of synthetic content to editorial splicing, and premature search termination.
Significance. If the dataset construction and verification hold, the benchmark would provide a useful, falsifiable testbed for systems that must integrate open-web search with video analysis to detect evidence-dependent misinformation, an area of growing practical importance. The explicit retrieval-augmented baseline and error analysis are strengths that could guide future model development.
major comments (2)
- [Abstract] Abstract: The claim that 'All samples are verified to be undetectable by frontier models through visual inspection alone' is load-bearing for the central argument that the benchmark requires search-grounded reasoning rather than visual inspection. No protocol details are supplied on which models were tested, inspection prompts or criteria, number of trials per video, or quantitative failure rates, leaving the low reported accuracies without clear evidence that they demonstrate the necessity of cross-video search.
- [Dataset Construction] Dataset section: The process by which the 222 videos were collected, how the nine manipulation types were chosen and balanced across the three categories, and any inter-annotator agreement metrics are not described. This directly affects assessment of whether the benchmark is representative of evidence-dependent video misinformation that cannot be solved visually.
minor comments (1)
- [Abstract] Abstract: The definitions and computation of 'point-level accuracy' versus 'video-level accuracy' are not stated, which would help readers interpret the headline numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the verification protocol and dataset construction details require expansion to strengthen the manuscript's claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'All samples are verified to be undetectable by frontier models through visual inspection alone' is load-bearing for the central argument that the benchmark requires search-grounded reasoning rather than visual inspection. No protocol details are supplied on which models were tested, inspection prompts or criteria, number of trials per video, or quantitative failure rates, leaving the low reported accuracies without clear evidence that they demonstrate the necessity of cross-video search.
Authors: We acknowledge that the verification protocol details were omitted from the manuscript. In the revised version we will insert a dedicated subsection in the Dataset section specifying the models tested for visual inspection (GPT-4o, Claude-3.5-Sonnet, Gemini-1.5-Pro), the inspection prompts and undetectability criteria, the number of trials per video, and the observed failure rates. This will directly support the necessity of search-grounded evaluation. revision: yes
-
Referee: [Dataset Construction] Dataset section: The process by which the 222 videos were collected, how the nine manipulation types were chosen and balanced across the three categories, and any inter-annotator agreement metrics are not described. This directly affects assessment of whether the benchmark is representative of evidence-dependent video misinformation that cannot be solved visually.
Authors: We agree the current description is insufficient. The revision will expand the Dataset section with the video collection sources and criteria, the rationale and balancing procedure for the nine manipulation types across the three categories, and inter-annotator agreement statistics for any annotation or verification steps. These additions will allow readers to assess representativeness. revision: yes
Circularity Check
Empirical benchmark with no derivations or self-referential reductions
full rationale
The paper introduces EVID-Bench as a new dataset and reports direct empirical accuracies from evaluating nine external frontier models on it. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. The central claim (low model performance) is an external evaluation result, not a quantity constructed from the paper's own definitions or prior author work. The verification statement about undetectability is an empirical dataset-construction assertion rather than a load-bearing derivation that reduces to itself by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The influence of content modality on perceptions of online misinformation
Suwani Gunasekara, Saumya Pareek, Ryan M Kelly, and Jorge Goncalves. The influence of content modality on perceptions of online misinformation. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–10, 2025
2025
-
[2]
Seeing is believing: Is video modality more powerful in spreading fake news via online messaging apps?Journal of Computer-Mediated Communication, 26(6): 301–319, 2021
S Shyam Sundar, Maria D Molina, and Eugene Cho. Seeing is believing: Is video modality more powerful in spreading fake news via online messaging apps?Journal of Computer-Mediated Communication, 26(6): 301–319, 2021
2021
-
[3]
Systematic analysis of video tamper- ing and detection techniques.Cogent Engineering, 11(1):2424466, 2024
Anjali Diwan, Saurav Dixit, Ram Subbiah, and Rajesh Mahadeva. Systematic analysis of video tamper- ing and detection techniques.Cogent Engineering, 11(1):2424466, 2024
2024
-
[4]
Fmnv: A dataset of media-published news videos for fake news detection
Yihao Wang, Zhong Qian, and Peifeng Li. Fmnv: A dataset of media-published news videos for fake news detection. InInternational Conference on Intelligent Computing, pages 321–332. Springer, 2025
2025
-
[5]
Copy-move video forgery detection techniques: A systematic survey with comparisons, challenges and future directions.Wireless Personal Communications, 134(3): 1863–1913, 2024
Gurvinder Singh and Kulbir Singh. Copy-move video forgery detection techniques: A systematic survey with comparisons, challenges and future directions.Wireless Personal Communications, 134(3): 1863–1913, 2024
1913
-
[6]
Enhanced inter-frame video forgery detection using convolutional network and stacking ensemble.Multimedia Tools and Applications, 85(5): 497, 2026
Baheesa Fatima, Asim Dilawar Bakhshi, and Abdul Ghafoor. Enhanced inter-frame video forgery detection using convolutional network and stacking ensemble.Multimedia Tools and Applications, 85(5): 497, 2026
2026
-
[7]
Improving deepfake detection with reinforcement learning-based adaptive data augmentation
Yuxuan Chou, Tao Yu, Wen Huang, Tao Dai, Shu-Tao Xia, et al. Improving deepfake detection with reinforcement learning-based adaptive data augmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 3381–3389, 2026
2026
-
[8]
Thinking in frequency: Face forgery detection by mining frequency-aware clues, 2020
Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. Thinking in frequency: Face forgery detection by mining frequency-aware clues, 2020. URLhttps://arxiv.org/abs/2007.09355
-
[9]
Deepfakeson-phys: Deepfakes detection based on heart rate estimation, 2020
Javier Hernandez-Ortega, Ruben Tolosana, Julian Fierrez, and Aythami Morales. Deepfakeson-phys: Deepfakes detection based on heart rate estimation, 2020. URL https://arxiv.org/abs/2010. 00400
2020
-
[10]
Multi-modal misinformation detection: Approaches, challenges and opportunities, 2024
Sara Abdali, Sina shaham, and Bhaskar Krishnamachari. Multi-modal misinformation detection: Approaches, challenges and opportunities, 2024. URLhttps://arxiv.org/abs/2203.13883
-
[11]
Exposing cross-modal consistency for fake news detection in short-form videos, 2026
Chong Tian, Yu Wang, Chenxu Yang, Junyi Guan, Zheng Lin, Yuhan Liu, Xiuying Chen, and Qirong Ho. Exposing cross-modal consistency for fake news detection in short-form videos, 2026. URL https://arxiv.org/abs/2603.14992
-
[12]
MERIT: Modular Framework for Multimodal Misinformation Detection with Web-Grounded Reasoning
Mir Nafis Sharear Shopnil, Sharad Duwal, Abhishek Tyagi, and Adiba Mahbub Proma. Merit: Modular framework for multimodal misinformation detection with web-grounded reasoning, 2026. URL https: //arxiv.org/abs/2510.17590. 12 EVID-Bench
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Cosmos: Catching out-of-context misinformation with self-supervised learning, 2021
Shivangi Aneja, Chris Bregler, and Matthias Nießner. Cosmos: Catching out-of-context misinformation with self-supervised learning, 2021. URLhttps://arxiv.org/abs/2101.06278
-
[14]
Tao Yu, Haopeng Jin, Hao Wang, Shenghua Chai, Yujia Yang, Junhao Gong, Jiaming Guo, Minghui Zhang, Xinlong Chen, Zhenghao Zhang, et al. Shotfinder: Imagination-driven open-domain video shot retrieval via web search.arXiv preprint arXiv:2601.23232, 2026
-
[15]
Tao Yu, Yujia Yang, Haopeng Jin, Junhao Gong, Xinlong Chen, Yuxuan Zhou, Shanbin Zhang, Jiabing Yang, Xinming Wang, Hongzhu Yi, et al. Beyond closed-pool video retrieval: A benchmark and agent framework for real-world video search and moment localization.arXiv preprint arXiv:2602.10159, 2026
-
[16]
Faceforensics++: Learning to detect manipulated facial images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. Faceforensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF international conference on computer vision, pages 1–11, 2019
2019
-
[17]
Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[18]
Df-net: The digital forensics network for image forgery detection
David Fischinger and Martin Boyer. Df-net: The digital forensics network for image forgery detection. arXiv preprint arXiv:2503.22398, 2025
-
[19]
Council of Europe Strasbourg, 2017
Claire Wardle and Hossein Derakhshan.Information disorder: Toward an interdisciplinary framework for research and policymaking, volume 27. Council of Europe Strasbourg, 2017
2017
-
[20]
Nareor: The narrative reordering problem
Varun Gangal, Steven Y Feng, Malihe Alikhani, Teruko Mitamura, and Eduard Hovy. Nareor: The narrative reordering problem. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 10645–10653, 2022
2022
-
[21]
Text-video multi-grained integration for video moment montage.arXiv preprint arXiv:2412.09276, 2024
Zhihui Yin, Ye Ma, Xipeng Cao, Bo Wang, Quan Chen, and Peng Jiang. Text-video multi-grained integration for video moment montage.arXiv preprint arXiv:2412.09276, 2024
-
[22]
Multi-view inconsistency analysis for video object-level splicing localization.International Journal of Emerging Technologies and Advanced Applications, 1(3):1–5, 2024
Pengfei Pei, Guoqing Liang, and Tao Luan. Multi-view inconsistency analysis for video object-level splicing localization.International Journal of Emerging Technologies and Advanced Applications, 1(3):1–5, 2024
2024
-
[23]
Combating online misin- formation videos: Characterization, detection, and future directions
Yuyan Bu, Qiang Sheng, Juan Cao, Peng Qi, Danding Wang, and Jintao Li. Combating online misin- formation videos: Characterization, detection, and future directions. InProceedings of the 31st ACM International Conference on Multimedia, pages 8770–8780, 2023
2023
-
[24]
Newsclippings: Automatic generation of out-of-context multimodal media
Grace Luo, Trevor Darrell, and Anna Rohrbach. Newsclippings: Automatic generation of out-of-context multimodal media. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6801–6817, 2021
2021
-
[25]
A corpus of debunked and verified user-generated videos.Online information review, 43(1):72–88, 2019
Olga Papadopoulou, Markos Zampoglou, Symeon Papadopoulos, and Ioannis Kompatsiaris. A corpus of debunked and verified user-generated videos.Online information review, 43(1):72–88, 2019
2019
-
[26]
Yihao Wang, Lizhi Chen, Zhong Qian, and Peifeng Li. Official-nv: An llm-generated news video dataset for multimodal fake news detection.arXiv preprint arXiv:2407.19493, 2024
-
[27]
Probing Multimodal Large Language Models on Cognitive Biases in Chinese Short-Video Misinformation
Jen-tse Huang, Chang Chen, Shiyang Lai, Wenxuan Wang, Michelle R Kaufman, and Mark Dredze. Probing multimodal large language models on cognitive biases in chinese short-video misinformation. arXiv preprint arXiv:2601.06600, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Product spam on youtube: A case study
Janek Bevendorff, Matti Wiegmann, Martin Potthast, and Benno Stein. Product spam on youtube: A case study. InProceedings of the 2024 conference on human information interaction and retrieval, pages 358–363, 2024. 13 EVID-Bench
2024
-
[29]
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, Mojie Chi, Xuyan Chi, Jian Cong, Qinpeng Cui, Fei Ding, Qide Dong, Yujiao Du, Haojie Duanmu, Junliang Fan, Jiarui Fang, Jing Fang, Zetao Fang, Chengjian Feng, Yu Gao, Diandian Gu, Dong Guo, Hanzhong Guo, Qiushan Guo, Boyang Hao, Hon...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Gemini 3.https://blog.google/products/gemini/gemini-3/, 2025
Google DeepMind. Gemini 3.https://blog.google/products/gemini/gemini-3/, 2025
2025
-
[31]
Openai gpt-5.5 system card
OpenAI. Openai gpt-5.5 system card. https://openai.com/index/gpt-5-5-system-card/ , 2026
2026
-
[32]
Openai gpt-5.4 system card
OpenAI. Openai gpt-5.4 system card. https://openai.com/index/ gpt-5-4-thinking-system-card/, 2026
2026
-
[33]
Claude opus 4.6.https://www.anthropic.com/news/claude-opus-4-6, 2026
Anthropic. Claude opus 4.6.https://www.anthropic.com/news/claude-opus-4-6, 2026
2026
-
[34]
Claude sonnet 4.6
Anthropic. Claude sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6 , 2026
2026
-
[35]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
content_summary
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5. 14 EVID-Bench Appendix A Verification Process Details 16 A.1 Prompt 1: Perceptual Quality Assessment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.2 Prompt 2: Temporal Coherence and Clip Insertion Detection . . . . . . . . . . . . ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.