UltraEP: Unleash MoE Training and Inference on Rack-Scale Nodes with Near-Optimal Load Balancing
Pith reviewed 2026-06-28 08:07 UTC · model grok-4.3
The pith
UltraEP rebalances MoE expert loads after every microbatch and layer on rack-scale nodes to reach 94.3 percent of ideal throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
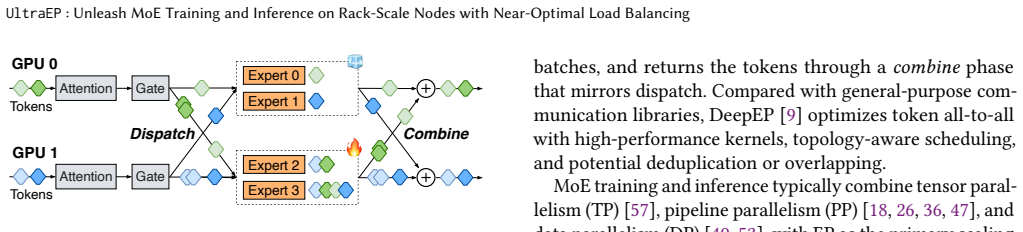
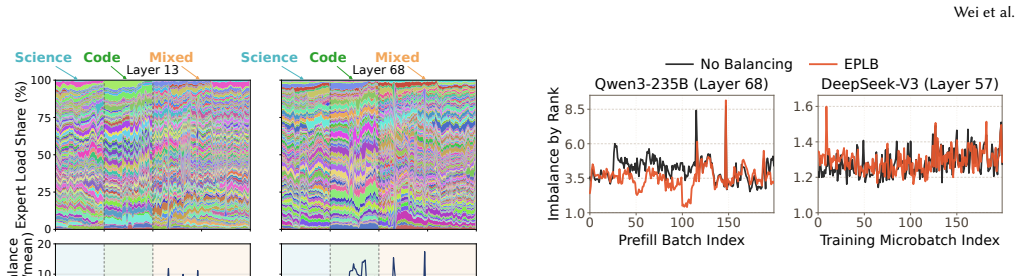
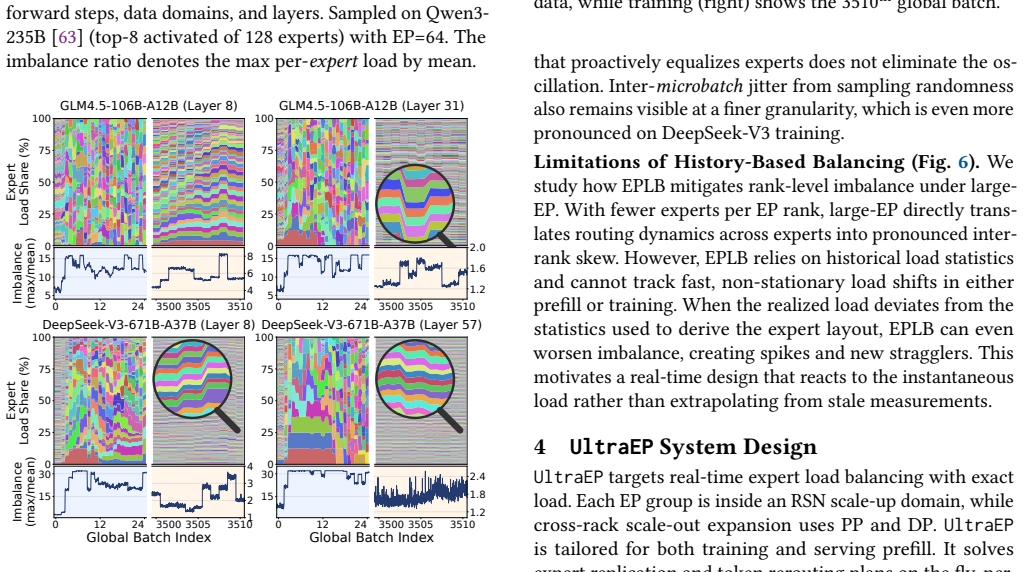
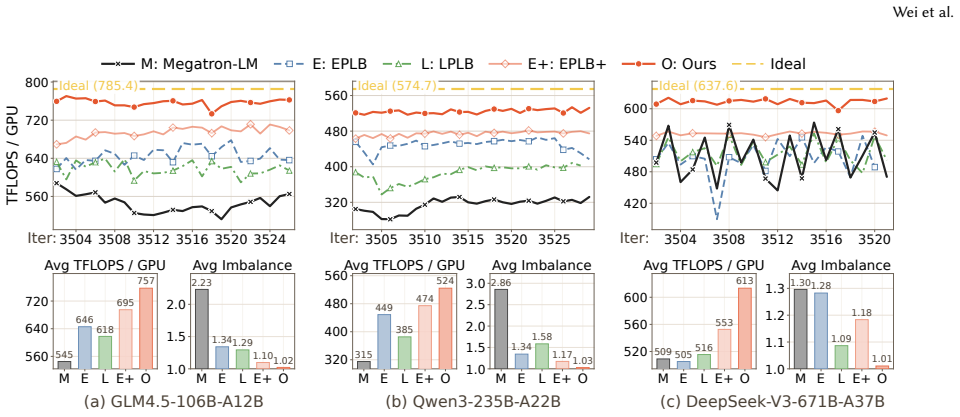
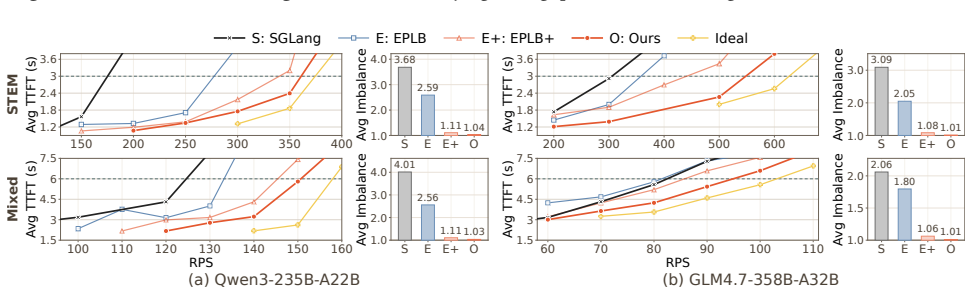
UltraEP is the first exact-load, real-time balancer for large-EP MoE training and serving prefill on rack-scale nodes. It rebalances experts every microbatch and layer by combining an efficient quota-driven planner that reacts to post-gating load with RSN-native persistent tile streaming and relay-based fan-out mitigation for the resulting irregular expert-state transfers, attaining 94.3 percent of the force-balanced ideal throughput, a 1.49 times improvement over no balancing, and a reduction of inter-rank imbalance from the range 1.30-4.01 down to 1.01-1.04.
What carries the argument
The quota-driven planner that produces an exact rebalancing assignment from current post-gating loads together with the persistent tile streaming and relay fan-out that execute the resulting irregular expert-state transfers over rack-scale connectivity.
If this is right
- MoE models up to 671 B parameters can run training and prefill serving on up to 256 GPUs while staying within 6 percent of theoretically perfect load balance.
- Periodic historical balancers are no longer required once exact per-microbatch decisions become feasible.
- Activation-memory spikes and token all-to-all contention are directly reduced by keeping expert counts nearly equal at every step.
- The same rebalancing mechanism applies uniformly to both training and inference prefill phases.
- Inter-rank imbalance can be driven from the 1.30-4.01 range down to 1.01-1.04 without changing model architecture or gating logic.
Where Pith is reading between the lines
- The same per-microbatch planning could be applied inside a single node when tensor or pipeline parallelism already exists, provided the intra-node fabric is comparable.
- Clusters that span multiple racks would need an additional slower inter-rack balancer layer to preserve the low-overhead property.
- Hardware designers could use the demonstrated tolerance for irregular transfers as a target when sizing rack-scale fabrics for future MoE accelerators.
- Production serving systems could drop conservative over-provisioning once load variation is handled at microbatch granularity rather than at epoch or hour granularity.
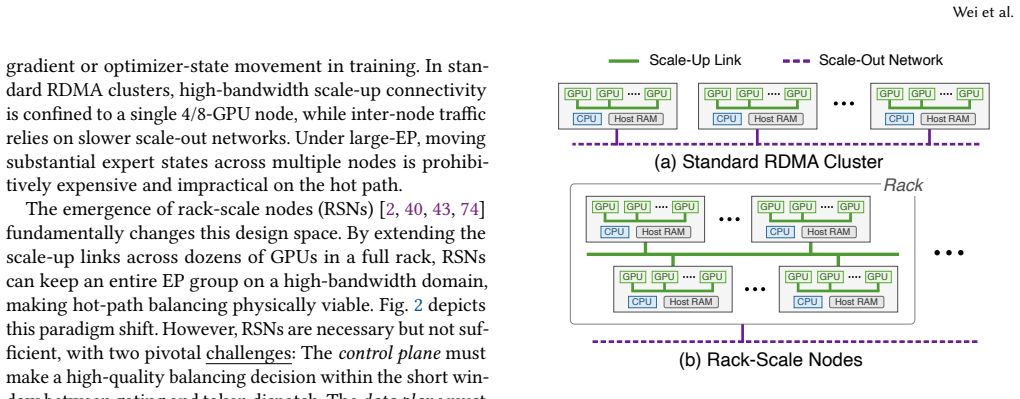
Load-bearing premise
Rack-scale nodes supply extended scale-up connectivity that permits low-overhead irregular expert-state transfers every microbatch and layer without exposing significant latency.
What would settle it
A throughput measurement on the same 256-GPU, 671 B model workload in which the rebalancing overhead exceeds the gains from reduced imbalance, causing overall performance to fall below the no-balancing baseline.
Figures




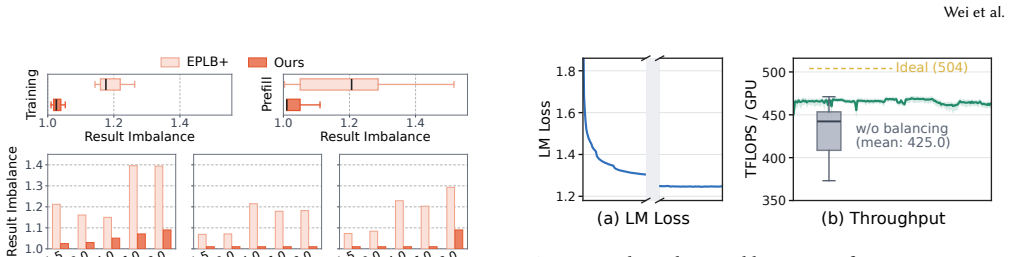
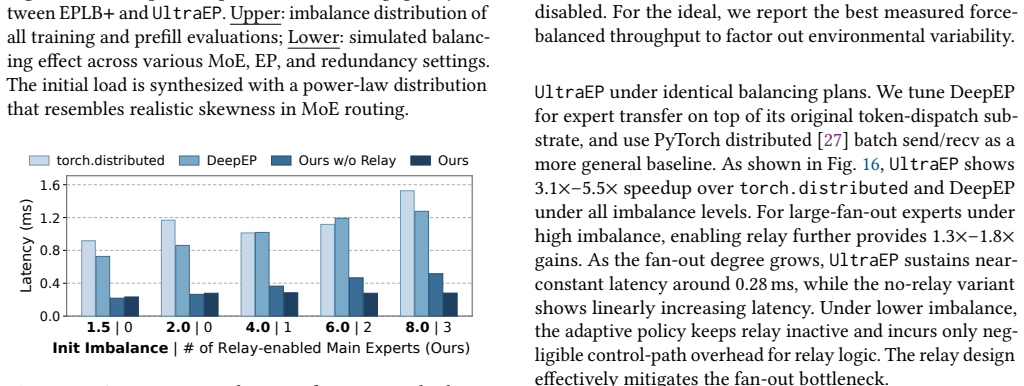
read the original abstract
Large-scale expert parallelism (EP) is becoming pivotal for training and serving frontier MoE models, but it also amplifies device-level expert load imbalance into compute stragglers, token all-to-all bottlenecks, and activation-memory spikes. Existing balancers redistribute experts periodically based on historical load, which becomes unreliable for production deployments with non-stationary load patterns. We present UltraEP, the first exact-load, real-time balancer for large-EP MoE training and serving prefill on rack-scale nodes (RSNs). Leveraging the extended scale-up connectivity among dozens of GPUs within RSNs, UltraEP rebalances every microbatch and layer on critical paths, which requires nontrivial co-design of plan solving and expert replication communication to minimize exposed overhead. To this end, UltraEP eagerly reacts to post-gating load with an efficient quota-driven planner, and executes the resulting irregular expert-state transfers with RSN-native persistent tile streaming and relay-based fan-out mitigation. We evaluate UltraEP in a multi-RSN deployment of up to 256 GPUs, using cutting-edge MoE models from 106B to 671B parameters. Averaged across training and serving, UltraEP achieves 94.3% of the force-balanced ideal throughput, delivering 1.49$\times$ improvement over no-balancing, while reducing the final inter-rank imbalance from 1.30$-$4.01 to 1.01$-$1.04.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UltraEP, the first exact-load real-time balancer for expert parallelism in large MoE models on rack-scale nodes. It uses a quota-driven planner reacting to post-gating loads and RSN-native persistent tile streaming with relay fan-out for irregular expert transfers every microbatch and layer. Evaluations on models from 106B to 671B parameters across up to 256 GPUs report that UltraEP reaches 94.3% of force-balanced ideal throughput (1.49× over no-balancing) while reducing inter-rank imbalance from 1.30-4.01 to 1.01-1.04.
Significance. If the throughput and imbalance claims hold with demonstrated low overhead, the work would be significant for production MoE training and serving by enabling dynamic, near-optimal load balancing at microbatch granularity on rack-scale hardware, addressing a key scalability bottleneck in expert parallelism.
major comments (3)
- [Abstract] Abstract: The central claims of 94.3% of ideal throughput and 1.49× improvement are presented as direct measurements but without error bars, workload/dataset details, or methodology, making independent verification of the performance numbers impossible from the provided information.
- [Evaluation section] Evaluation section: No quantitative breakdown or bound is given for the exposed latency of the quota-driven planner plus irregular expert-state transfers (persistent tile streaming and relay fan-out) under non-stationary loads; this overhead must be shown to be negligible relative to balance gains for the 94.3% ideal and final imbalance numbers (1.01-1.04) to hold.
- [Communication Design / Evaluation] The manuscript's performance claims rest on the assumption that rack-scale scale-up connectivity permits exact post-gating rebalancing every microbatch and layer with low exposed latency, yet no sensitivity analysis or timing measurements are reported to confirm this under the evaluated conditions.
minor comments (1)
- [Abstract] The abstract refers to 'nontrivial co-design' of plan solving and communication without summarizing the key co-design elements or their measured impact.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to improve clarity and completeness of the performance claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 94.3% of ideal throughput and 1.49× improvement are presented as direct measurements but without error bars, workload/dataset details, or methodology, making independent verification of the performance numbers impossible from the provided information.
Authors: We agree that the abstract lacks sufficient context for independent verification. In the revision we will expand it to briefly note the workloads (training and serving of 106B–671B MoE models), hardware (multi-RSN deployment up to 256 GPUs), and that the reported figures are averages across runs; full methodology, error bars, and dataset details already appear in Section 4 and will be cross-referenced. revision: yes
-
Referee: [Evaluation section] Evaluation section: No quantitative breakdown or bound is given for the exposed latency of the quota-driven planner plus irregular expert-state transfers (persistent tile streaming and relay fan-out) under non-stationary loads; this overhead must be shown to be negligible relative to balance gains for the 94.3% ideal and final imbalance numbers (1.01-1.04) to hold.
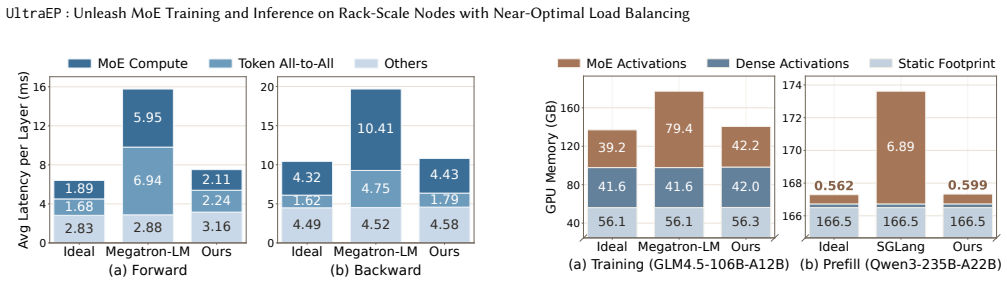
Authors: The current manuscript reports only end-to-end results. We will add a dedicated subsection with micro-benchmark timing of the quota-driven planner and the persistent-tile/relay communication primitives under the same non-stationary loads used in the main evaluation, showing that combined overhead remains below 6 % of per-layer compute time and is therefore negligible relative to the observed balance gains. revision: yes
-
Referee: [Communication Design / Evaluation] The manuscript's performance claims rest on the assumption that rack-scale scale-up connectivity permits exact post-gating rebalancing every microbatch and layer with low exposed latency, yet no sensitivity analysis or timing measurements are reported to confirm this under the evaluated conditions.
Authors: Section 3 describes the RSN-native mechanisms, but we acknowledge the absence of sensitivity data. We will add experiments that vary microbatch size and load non-stationarity while measuring exposed rebalancing latency, confirming that the scale-up fabric keeps latency low enough to support per-microbatch/layer rebalancing in the evaluated regimes. revision: yes
Circularity Check
No circularity; performance results are direct empirical measurements against explicit baselines.
full rationale
The paper describes an engineering system (UltraEP) for real-time expert rebalancing on rack-scale nodes and reports throughput and imbalance metrics from multi-GPU evaluations. These are presented as measured outcomes (94.3% of force-balanced ideal, 1.49× over no-balancing) without any claimed derivation, first-principles equations, fitted parameters renamed as predictions, or load-bearing self-citations. The evaluation section benchmarks against an external ideal and a no-balancing baseline; no step reduces the reported gains to inputs defined by the same experiment.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rack-scale nodes provide extended scale-up connectivity among dozens of GPUs enabling low-overhead irregular transfers every microbatch
- domain assumption Production MoE deployments exhibit non-stationary load patterns that render periodic historical balancers unreliable
Reference graph
Works this paper leans on
-
[1]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). 117–134
2024
-
[2]
2025.AMD Helios: Advancing Openness in AI Infrastructure Built on Meta’s 2025 OCP Open Rack for AI Design
AMD. 2025.AMD Helios: Advancing Openness in AI Infrastructure Built on Meta’s 2025 OCP Open Rack for AI Design. Technical Report. Advanced Micro Devices, Inc.https://www.amd.com/en/blogs/2025/ amd-helios-ai-rack-built-on-metas-2025-ocp-design.html
2025
-
[3]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 3119–3137. doi:10....
-
[4]
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training Deep Nets with Sublinear Memory Cost.arXiv preprint arXiv:1604.06174(2016). doi:10.48550/arXiv.1604.06174
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1604.06174 2016
-
[5]
Codeforces. 2026. Codeforces.https://codeforces.com/. Official website
2026
-
[6]
Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y
Damai Dai, Chengqi Deng, Chenggang Zhao, R.X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, et al. 2024. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of- Experts Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 1280–1297
2024
-
[7]
Google DeepMind. 2025. Gemini 3 Pro Model Card.https://deepmind. google/models/model-cards/gemini-3-pro/
2025
-
[8]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report.arXiv preprint arXiv:2412.19437(2024)
Pith/arXiv arXiv 2024
-
[9]
DeepSeek-AI. 2025. DeepEP: A high-performance communication library for MoE training and inference.https://github.com/deepseek- ai/DeepEP
2025
-
[10]
DeepSeek-AI. 2025. DeepGEMM: Clean and Efficient FP8 GEMM Kernels with Fine-Grained Scaling.https://github.com/deepseek-ai/ DeepGEMM
2025
-
[11]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948 (2025)
Pith/arXiv arXiv 2025
-
[12]
DeepSeek-AI. 2025. EPLB: Expert Parallelism Load Balancer.https: //github.com/deepseek-ai/EPLB
2025
-
[13]
DeepSeek-AI. 2025. LPLB: An early research stage expert-parallel load balancer based on linear programming.https://github.com/deepseek- ai/LPLB
2025
-
[14]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Effi- cient Sparsity.Journal of Machine Learning Research (JMLR)23, 120 (2022), 1–40
2022
-
[15]
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. 2023. MegaBlocks: Efficient Sparse Training with Mixture-of-Experts. In Proceedings of the 6th MLSys Conference
2023
-
[16]
2026.GLM-4.7: Advanced Agentic and Reasoning Founda- tion Models
GLM Team. 2026.GLM-4.7: Advanced Agentic and Reasoning Founda- tion Models. Technical Report. Zhipu AI.https://docs.z.ai/guides/llm/ glm-4.7
2026
-
[17]
Jiaao He, Jidong Zhai, Tiago Antunes, Haojie Wang, Fuwen Luo, Shangfeng Shi, and Qin Li. 2022. FasterMoE: Modeling and Optimizing Training of Large-Scale Dynamic Pre-Trained Models. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP). 120–134. doi:10.1145/3503221.3508418
-
[18]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Orhan, Prafulla Dhariwal, Mia Xu Chen, Yonghui Chen, Quoc V Lee, Jiquan Ngiam, and Quoc V Le. 2019. GPipe: Efficient Training of Giant Neural Net- works using Pipeline Parallelism. InAdvances in Neural Information Processing Systems (NeurIPS). 13 Wei et al
2019
-
[19]
Changho Hwang, Yongqiang Xiong, Mao Yang, Fan Yang, Peng Cheng, Joe Chau, Prabhat Ram, Jithin Jose, Rafael Salas, Zilong Wang, et al
-
[20]
InProceedings of the 6th MLSys Conference
Tutel: Adaptive Mixture-of-Experts at Scale. InProceedings of the 6th MLSys Conference
-
[21]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al . 2024. Mixtral of Experts.arXiv preprint arXiv:2401.04088(2024)
Pith/arXiv arXiv 2024
-
[22]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world GitHub Issues?. InInternational Conference on Learning Representations (ICLR).https://openreview. net/forum?id=VTF8yNQM66
2024
-
[23]
Chao Jin, Ziheng Jiang, Zhihao Bai, Zheng Zhong, Juncai Liu, Xiang Li, Ningxin Zheng, Xi Wang, Cong Xie, Qi Huang, et al. 2025. Megascale- moe: Large-scale communication-efficient training of mixture-of- experts models in production.arXiv preprint arXiv:2505.11432(2025)
arXiv 2025
-
[24]
kvcache-ai. 2026. Mooncake EP and Mooncake Backend.https:// github.com/kvcache-ai/Mooncake
2026
-
[25]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[26]
Gonzalez, Hao Zhang, and Ion Stoica
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP). 611–626. doi:10.1145/3600006. 3613165
-
[27]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. InInternational Conference on Learning Representations (ICLR)
2021
-
[28]
Shigang Li and Torsten Hoefler. 2021. Chimera: Efficiently Training Large-Scale Neural Networks with Bidirectional Pipelines. InProceed- ings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). ACM. doi:10.1145/3458817. 3476145
-
[29]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. 2020. PyTorch distributed: experiences on accelerating data parallel training.Proceedings of the VLDB Endowment13, 12 (2020), 3005–3018
2020
-
[30]
Xingyi Li, Yadong Liu, Xiaojie Huang, Yiran Zhang, Shuai Wang, Shangguang Wang, Zhehao Lin, Yinben Xia, Chang Yu, Qihang Liu, et al. 2026. {SwiftEP}: Accelerating {MoE} Inference with Buffer Fu- sion and {TMA} Offloading. In23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26). 1073–1089
2026
-
[31]
Heng Liao, Bingyang Liu, Xianping Chen, Zhigang Guo, Chuanning Cheng, Jianbing Wang, Xiangyu Chen, Peng Dong, Rui Meng, Wen- jie Liu, et al. 2025. Ub-mesh: a hierarchically localized nd-fullmesh datacenter network architecture.IEEE Micro(2025)
2025
-
[32]
Dennis Liu, Zijie Yan, Xin Yao, et al . 2025. MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core.arXiv preprint arXiv:2504.14960 (2025). doi:10.48550/arXiv.2504.14960
-
[33]
Juncai Liu, Jessie Hui Wang, and Yimin Jiang. 2023. Janus: A Unified Distributed Training Framework for Sparse Mixture-of-Experts Mod- els. InProceedings of the ACM SIGCOMM 2023 Conference. 486–498. doi:10.1145/3603269.3604869
-
[34]
Xinyi Liu, Yujie Wang, Fangcheng Fu, et al. 2026. LAER-MoE: Load- Adaptive Expert Re-Layout for Efficient Mixture-of-Experts Training. InProceedings of the 31st International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). doi:10.1145/3779212.3790180
-
[35]
Ziming Mao, Yihan Zhang, Chihan Cui, Kaichao You, Zhongjie Chen, Zhiying Xu, Scott Shenker, Costin Raiciu, Yang Zhou, and Ion Stoica. 2026. UCCL-EP: Portable Expert-Parallel Communication. arXiv:2512.19849 [cs.DC] doi:10.48550/arXiv.2512.19849
-
[36]
Meta. 2025. Llama 4 Model Card.http://llama.meta.com/docs/model- cards-and-prompt-formats/llama4/
2025
-
[37]
2026.Driving vLLM WideEP and Large- Scale Serving Toward Maturity on Blackwell (Part I)
Meta and NVIDIA Team. 2026.Driving vLLM WideEP and Large- Scale Serving Toward Maturity on Blackwell (Part I). Technical Report. https://vllm.ai/blog/dsr1-gb200-part1
2026
-
[38]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized Pipeline Parallelism for DNN Training. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP). 1–15. doi:10.1145/3341301.3359490
-
[39]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. 2021. Efficient large-scale language model training on gpu clusters using megatron- lm. InProceedings of the international conference for high performance computing, netwo...
2021
-
[40]
Xiaonan Nie, Xupeng Miao, Zilong Wang, et al. 2023. FlexMoE: Scaling Large-Scale Sparse Pre-Trained Model Training via Dynamic Device Placement.Proceedings of the ACM on Management of Data (SIGMOD) 1, 1 (2023), 1–19. doi:10.1145/3588964
-
[41]
NVIDIA. 2024. Advancing Performance with NVIDIA SHARP In- Network Computing.https://developer.nvidia.com/blog/advancing- performance-with-nvidia-sharp-in-network-computing/
2024
-
[42]
2024.NVIDIA Blackwell Architecture Technical Overview
NVIDIA. 2024.NVIDIA Blackwell Architecture Technical Overview. Technical Report. NVIDIA Corporation.https://www.nvidia.com/en- us/data-center/gb200-nvl72/
2024
-
[43]
2025.NVIDIA NVLink and NVLink Switch
NVIDIA. 2025.NVIDIA NVLink and NVLink Switch. Technical Report. NVIDIA Corporation.https://www.nvidia.com/en-us/data-center/ nvlink/
2025
-
[44]
NVIDIA. 2025. OpenScience.https://huggingface.co/datasets/nvidia/ OpenScience. Dataset card
2025
-
[45]
2026.NVIDIA Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer
NVIDIA. 2026.NVIDIA Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer. Technical Report. NVIDIA Corpora- tion.https://developer.nvidia.com/blog/nvidia-vera-rubin-pod-seven- chips-five-rack-scale-systems-one-ai-supercomputer/
2026
-
[46]
OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card.arXiv preprint arXiv:2508.10925(2025)
Pith/arXiv arXiv 2025
-
[47]
Xinglin Pan, Wenxiang Lin, Lin Zhang, Shaohuai Shi, Zhenheng Tang, Rui Wang, Bo Li, and Xiaowen Chu. 2025. FSMoE: A Flexible and Scalable Training System for Sparse Mixture-of-Experts Models. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). 524–539. doi:10.1145/36699...
-
[48]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. In51st ACM/IEEE Annual International Symposium on Computer Architecture (ISCA). 118– 132
2024
-
[49]
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. 2024. Zero Bubble (Almost) Pipeline Parallelism. InInternational Conference on Learning Representations (ICLR)
2024
-
[50]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yux- iong He. 2022. DeepSpeed-MoE: Advancing Mixture-of-Experts Infer- ence and Training to Power Next-Generation AI Scale. InInternational Conference on Machine Learning (ICML). PMLR, 18332–18346
2022
-
[51]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[52]
Generalized Slow Roll for Tensors
ZeRO: Memory optimizations toward training trillion param- eter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). 1–16. doi:10.1109/SC41405.2020.00024 14 UltraEP: Unleash MoE Training and Inference on Rack-Scale Nodes with Near-Optimal Load Balancing
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2020
-
[53]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2024. GPQA: A Graduate-Level Google-Proof Q&A Bench- mark. InConference on Language Modeling (COLM).https:// openreview.net/forum?id=Ti67584b98
2024
-
[54]
2025.Deploying DeepSeek with PD Disaggregation and Large- Scale Expert Parallelism on 96 H100 GPUs
SGLang. 2025.Deploying DeepSeek with PD Disaggregation and Large- Scale Expert Parallelism on 96 H100 GPUs. Technical Report. The SGLang Team.https://lmsys.org/blog/2025-05-05-large-scale-ep/
2025
-
[55]
SGLang. 2025. EPLB Deployment in SGLang.https://www.lmsys.org/ blog/2025-05-05-large-scale-ep/#expert-parallelism-load-balancer
2025
-
[56]
Christopher J Shallue, Jaehoon Lee, Joseph Antognini, Jascha Sohl- Dickstein, Roy Frostig, and George E Dahl. 2019. Measuring the effects of data parallelism on neural network training.Journal of Machine Learning Research (JMLR)20, 1 (2019), 1–49
2019
-
[57]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In International Conference on Learning Representations (ICLR)
2017
-
[58]
Shaohuai Shi, Xinglin Pan, Xiaowen Chu, and Bo Li. 2023. PipeMoE: Accelerating Mixture-of-Experts through Adaptive Pipelining. InIEEE Conference on Computer Communications (INFOCOM). 1–10. doi:10. 1109/INFOCOM53939.2023.10228874
arXiv 2023
-
[59]
Shaohuai Shi, Xinglin Pan, Qiang Wang, Chengjian Liu, Xiaozhe Ren, Zhongzhe Hu, Yu Yang, Bo Li, and Xiaowen Chu. 2024. ScheMoE: An Extensible Mixture-of-Experts Distributed Training System with Tasks Scheduling over Heterogeneous Networks. InProceedings of the Nineteenth European Conference on Computer Systems (EuroSys). 236–249. doi:10.1145/3627703.3650083
-
[60]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. doi:10.48550/arXiv.1909.08053
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1909.08053 2019
-
[61]
GLM-4.5 Team, Zhipu AI, and Tsinghua University. 2025. GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models.arXiv preprint arXiv:2508.06471(2025)
Pith/arXiv arXiv 2025
-
[62]
UALink Consortium
UALink Consortium 2025.UALink 200G 1.0 Specification. UALink Consortium. Open industry standard for scale-up accelerator inter- connects
2025
-
[63]
vLLM. 2025. EPLB Configuration in vLLM.https://docs.vllm.ai/en/ latest/serving/expert_parallel_deployment/#expert-parallel-load- balancer-eplb
2025
-
[64]
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai
-
[65]
Auxiliary-loss-free load balancing strategy for mixture-of- experts.arXiv preprint arXiv:2408.15664(2024)
Pith/arXiv arXiv 2024
-
[66]
Zijie Yan, Hongxiao Bai, Xin Yao, Dennis Liu, Tong Liu, Hongbin Liu, Pingtian Li, Evan Wu, Shiqing Fan, Li Tao, et al. 2026. Scalable Training of Mixture-of-Experts Models with Megatron Core.arXiv preprint arXiv:2603.07685(2026)
arXiv 2026
-
[67]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[68]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengqiang Li, Chengyuan Li, Dayihao Liu, Fei Huang, et al
-
[69]
Qwen2 Technical Report.arXiv preprint arXiv:2407.10671(2024)
Pith/arXiv arXiv 2024
-
[70]
Jaehoon Yang, Yushin Kim, Seokwon Moon, Yeonhong Park, and Jae W. Lee. 2026. LIBRA: EFFECTIVE YET EFFICIENT LOAD BALANCING FOR LARGE-SCALE MOE INFERENCE. InInternational Conference on Learning Representations (ICLR)
2026
-
[71]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, et al . 2025. DAPO: An Open- Source LLM Reinforcement Learning System at Scale.arXiv preprint arXiv:2503.14476(2025). doi:10.48550/arXiv.2503.14476
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[72]
Yan Zeng, Chengchuang Huang, Yipeng Mei, et al. 2025. EfficientMoE: Optimizing Mixture-of-Experts Model Training With Adaptive Load Balance.IEEE Transactions on Parallel and Distributed Systems (TPDS) 36, 4 (2025), 677–688. doi:10.1109/TPDS.2025.3539297
-
[73]
Mingshu Zhai, Jiaao He, Zixuan Ma, Zan Zong, Runqing Zhang, and Jidong Zhai. 2023. SmartMoE: Efficiently Training Sparsely-Activated Models through Combining Offline and Online Parallelization. In USENIX Annual Technical Conference (ATC). 961–975
2023
-
[74]
Junyi Zhang, Chuanhu Ma, Xiong Wang, and Yuntao Nie. 2025. PopFetcher: Towards Accelerated Mixture-of-Experts Training Via Popularity Based Expert-Wise Prefetch. InUSENIX Annual Technical Conference (ATC)
2025
-
[75]
Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, Wenlei Bao, Chengquan Jiang, Qi Hou, Weihao Cui, Size Zheng, Li-Wen Chang, et al. 2025. Comet: Fine-grained computation-communication over- lapping for mixture-of-experts.Proceedings of Machine Learning and Systems7 (2025)
2025
-
[76]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Effi- cient Execution of Structured Language Model Programs. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[77]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
-
[78]
Qianchao Zhu, Xucheng Ye, Yuliang Liu, Haodong Ouyang, and Chengru Song. 2026. PROBE: Co-Balancing Computation and Com- munication in MoE Inference via Real-Time Predictive Prefetching. arXiv:2602.00509 [cs.DC] doi:10.48550/arXiv.2602.00509
-
[79]
Pengfei Zuo, Huimin Lin, Junbo Deng, Nan Zou, Xingkun Yang, Yingyu Diao, Weifeng Gao, Ke Xu, Zhangyu Chen, Shirui Lu, et al . 2025. Serving large language models on huawei cloudmatrix384.arXiv preprint arXiv:2506.12708(2025). 15
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.