Stationarity-Aware Retrieval-Augmented Time Series Forecasting
Pith reviewed 2026-06-28 11:16 UTC · model grok-4.3
The pith
SARAF augments forecasters by retrieving historical segments with stationarity-modulated balance of relevance and diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
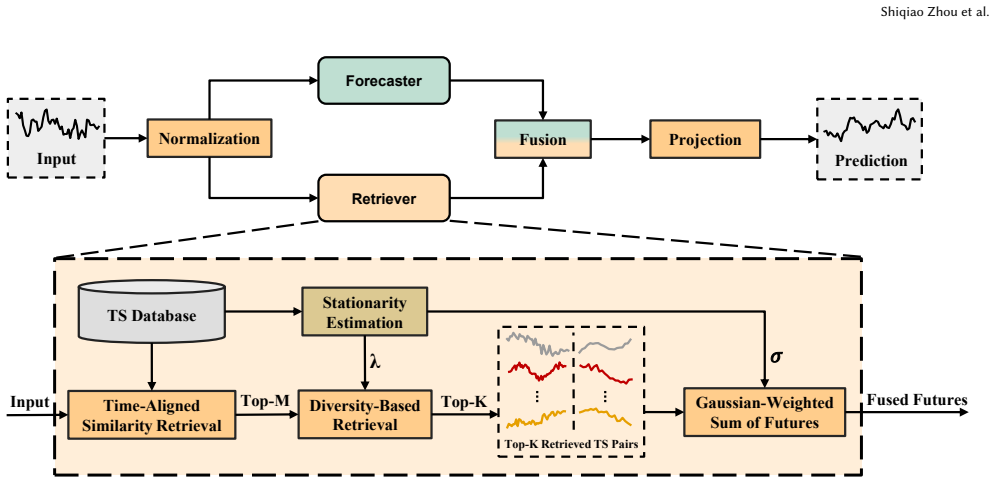
SARAF forms a candidate pool of historical segments using temporal similarity with time-aligned enhancement, then applies a diversity-aware selection whose strength is automatically scaled by a dataset-level stationarity measure; the selected segments are fused via stationarity-aware aggregation to produce the final forecast.
What carries the argument
Stationarity-modulated diversity-aware selection and aggregation that turns a similarity-based candidate pool into a regime-covering evidence set.
If this is right
- Forecasts remain accurate across regime changes without retraining the base model.
- The same retrieval pool can serve multiple forecast horizons by adjusting only the aggregation step.
- Datasets with different stationarity levels automatically receive different retrieval behaviors from the same code.
- The method adds no extra parameters to the underlying forecaster.
Where Pith is reading between the lines
- The stationarity signal could be replaced by a local, sliding-window version to handle series that become non-stationary only late in the record.
- The same modulated selection logic might improve retrieval-augmented methods in other sequential domains such as audio or video where distribution shift is common.
- Because the diversification is dataset-level, one could test whether per-series stationarity estimates further improve results on heterogeneous collections.
Load-bearing premise
That measuring overall dataset stationarity and using it to tune how much diversity to add will reliably produce a better mix of historical regimes than similarity alone.
What would settle it
On a collection of strongly non-stationary series, replacing SARAF's modulated selection and aggregation with plain top-k similarity retrieval yields equal or higher forecast accuracy.
Figures
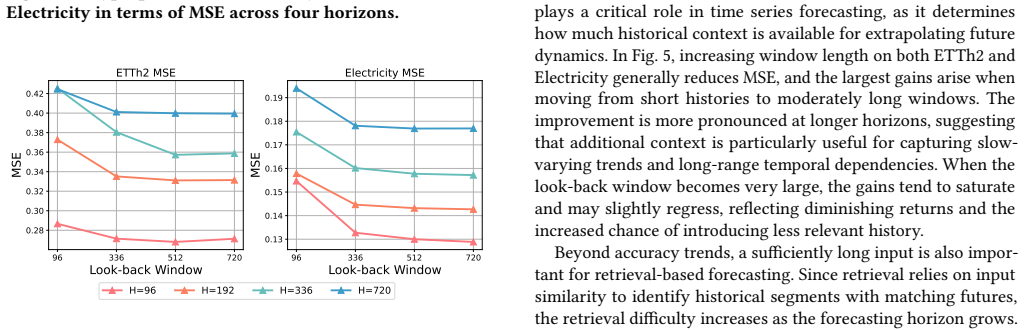
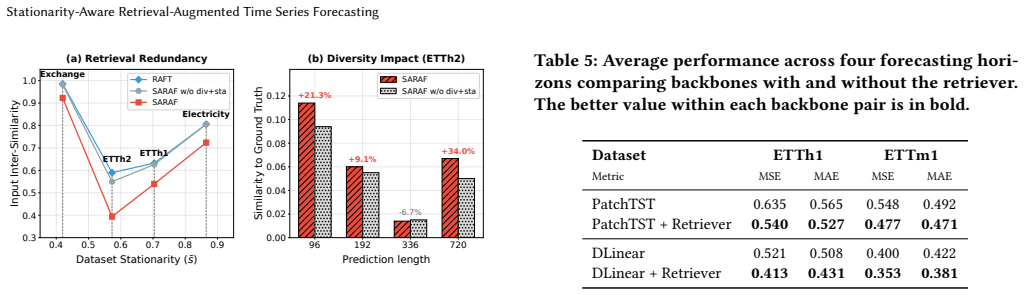
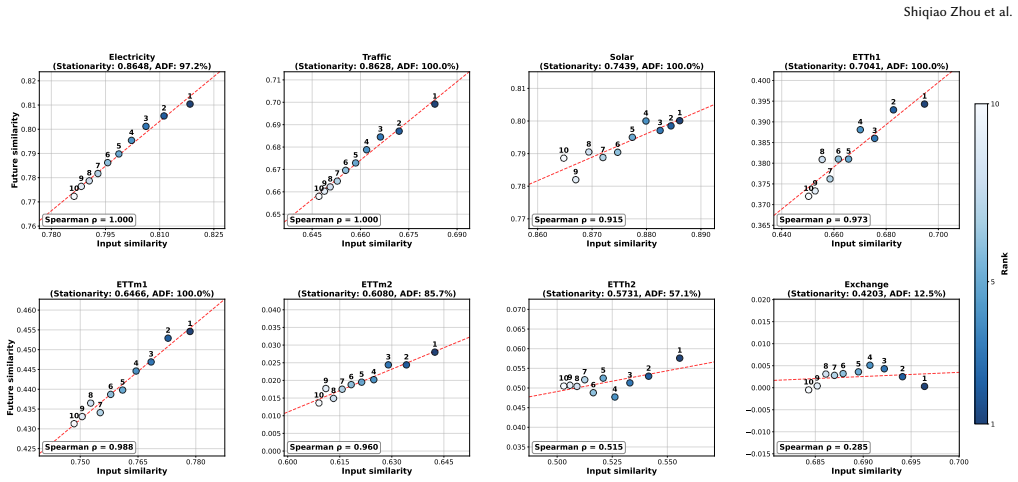
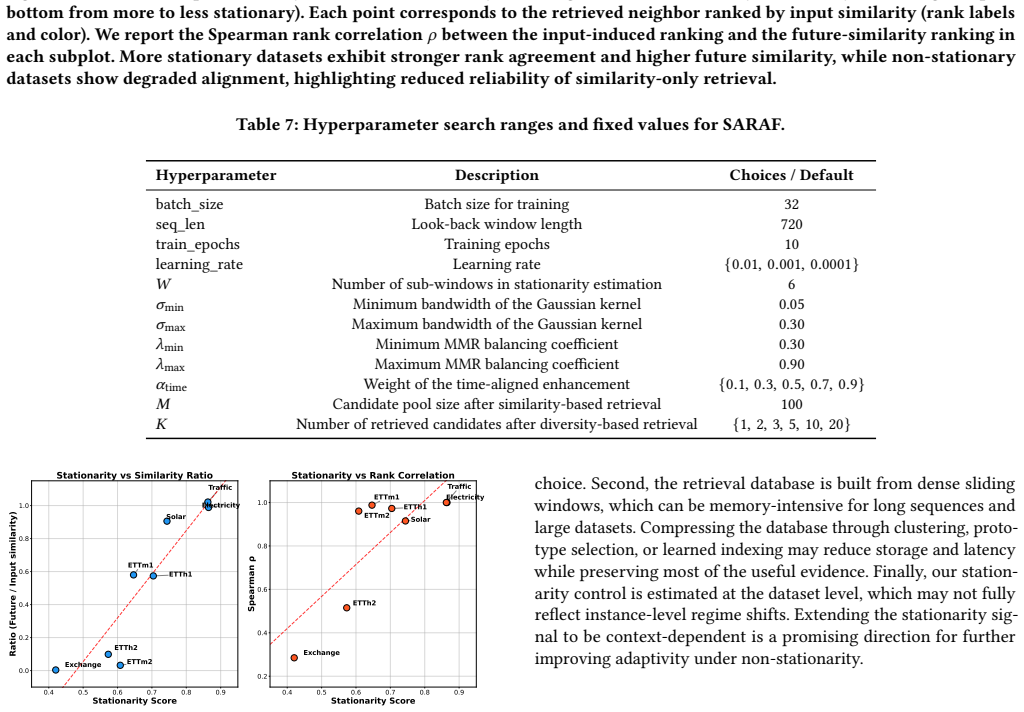
read the original abstract
Time series forecasting relies on historical patterns, but real-world series often exhibit non-stationarity and regime shifts that challenge fully parametric forecasters. Inspired by Retrieval-Augmented Generation (RAG), recent work augments forecasters by retrieving relevant historical segments and using them as external evidence at inference time. However, due to the intrinsic non-stationarity of real-world time series, a highly similar past segment does not necessarily imply a similar future, rendering similarity-only retrieval brittle and prone to redundancy. We propose Stationarity-Aware Retrieval-Augmented Time Series Forecasting (SARAF), a framework that adaptively balances relevance and diversity in retrieval. SARAF first forms a candidate pool via temporal similarity with time-aligned enhancement, then applies a diversity-aware selection strategy to cover heterogeneous historical regimes, with the diversification strength automatically modulated by dataset-level stationarity. Moreover, SARAF uses stationarity-aware aggregation to fuse the retrieved futures. Extensive experiments on eight real-world datasets show that SARAF achieves competitive forecasting performance and improves average accuracy and robustness over strong baselines, with particularly clear benefits under challenging non-stationary settings. Code: https://github.com/ShiqiaoZhou/SARAF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SARAF, a retrieval-augmented framework for time series forecasting that forms a candidate pool via temporal similarity, applies diversity-aware selection modulated by dataset-level stationarity, and uses stationarity-aware aggregation of retrieved futures. It claims competitive performance on eight real-world datasets with improved average accuracy and robustness over baselines, especially in non-stationary settings, and releases public code.
Significance. If the central claims hold, SARAF offers a practical extension of RAG-style retrieval to non-stationary time series by explicitly trading off relevance against diversity via stationarity modulation. The public code release is a clear strength that supports reproducibility and further testing of the relevance-diversity mechanism.
major comments (3)
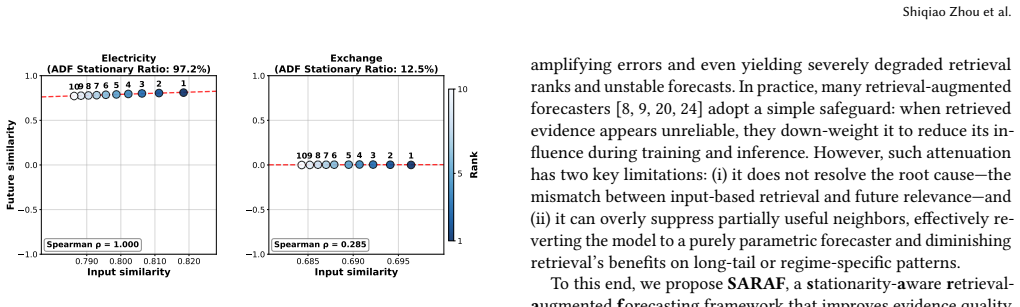
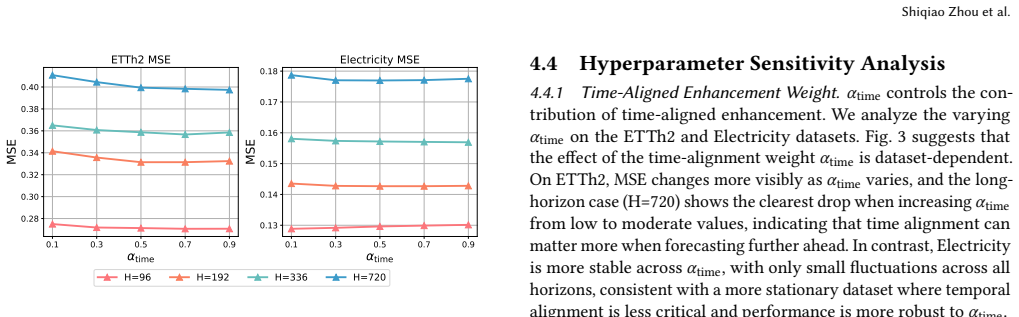
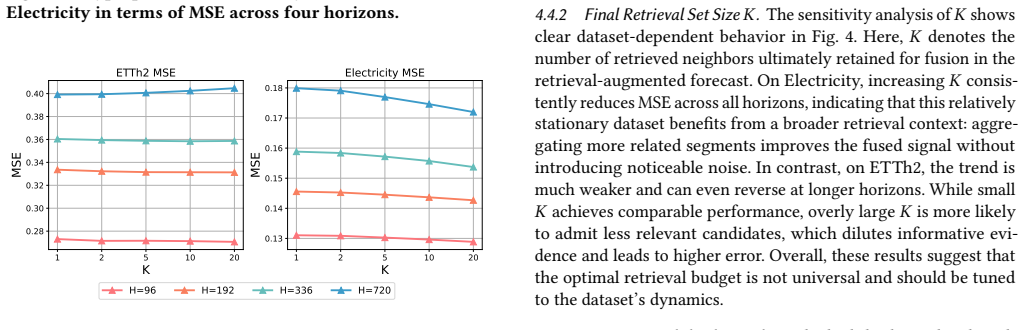
- [Abstract and §3] Abstract and §3 (method description): the diversification strength is modulated by a single dataset-level stationarity statistic. For the claim of improved robustness under non-stationarity to hold, this global scalar must produce suitable relevance-diversity trade-offs across heterogeneous local regimes; if the statistic aggregates over sub-period differences, the selection step risks systematic under-diversification in high-shift windows or over-diversification in stable ones, directly affecting the reported gains on non-stationary data.
- [§4] §4 (experiments): the abstract reports competitive results and benefits in non-stationary cases, but without reported details on how non-stationarity is quantified per dataset, the exact baselines, evaluation metrics, or statistical significance tests, it is not possible to verify that the gains are attributable to the stationarity-aware components rather than other design choices.
- [§3.2] §3.2 (diversity-aware selection): the paper presents the modulation as automatic and dataset-level, yet provides no ablation isolating the effect of the stationarity scalar versus a fixed diversification strength; without this, the load-bearing assumption that adaptive modulation reliably covers regime heterogeneity remains untested.
minor comments (2)
- [Abstract] Abstract: the phrase 'time-aligned enhancement' is introduced without a brief definition or pointer to the relevant equation or subsection.
- The manuscript would benefit from a short table summarizing the eight datasets, their lengths, and a stationarity measure (e.g., ADF statistic) to ground the non-stationary setting claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, clarifying our design choices and proposing targeted revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the diversification strength is modulated by a single dataset-level stationarity statistic. For the claim of improved robustness under non-stationarity to hold, this global scalar must produce suitable relevance-diversity trade-offs across heterogeneous local regimes; if the statistic aggregates over sub-period differences, the selection step risks systematic under-diversification in high-shift windows or over-diversification in stable ones, directly affecting the reported gains on non-stationary data.
Authors: We appreciate this observation on the global modulation. The dataset-level stationarity statistic is intentionally used as a single, automatic scalar to modulate diversification strength without introducing per-window hyperparameters, reflecting the overall non-stationarity of each dataset as a practical proxy. The diversity-aware selection step operates on the candidate pool to cover heterogeneous regimes even under this global setting. We will revise §3 to explicitly discuss this design rationale, its motivation from RAG-style retrieval, and acknowledge the limitation regarding fine-grained local regime shifts, including a brief analysis of sub-period performance variations where feasible. revision: partial
-
Referee: [§4] §4 (experiments): the abstract reports competitive results and benefits in non-stationary cases, but without reported details on how non-stationarity is quantified per dataset, the exact baselines, evaluation metrics, or statistical significance tests, it is not possible to verify that the gains are attributable to the stationarity-aware components rather than other design choices.
Authors: We agree that the current §4 lacks sufficient detail for full verification. In the revision we will expand the experimental section to specify: the non-stationarity quantification method (e.g., ADF test p-values or variance ratios per dataset), the complete list of baselines with hyperparameter settings, the precise evaluation metrics (MAE, RMSE, MAPE), and statistical significance results (e.g., paired t-tests or Diebold-Mariano tests) against baselines. These additions will directly support attribution of gains to the stationarity-aware retrieval and aggregation components. revision: yes
-
Referee: [§3.2] §3.2 (diversity-aware selection): the paper presents the modulation as automatic and dataset-level, yet provides no ablation isolating the effect of the stationarity scalar versus a fixed diversification strength; without this, the load-bearing assumption that adaptive modulation reliably covers regime heterogeneity remains untested.
Authors: The referee is correct that an explicit ablation isolating the stationarity scalar from a fixed diversification strength is not present. While existing comparisons to non-retrieval and similarity-only baselines provide indirect evidence, we will add a dedicated ablation study in the revised §4. This will compare SARAF against variants using fixed diversification strengths (e.g., constant λ values) across all eight datasets, quantifying the benefit of the adaptive, stationarity-modulated selection. revision: yes
Circularity Check
No circularity: derivation is self-contained with independent components
full rationale
The paper introduces SARAF as a retrieval-augmented framework with three explicit stages (temporal-similarity candidate pool, stationarity-modulated diversity selection, stationarity-aware aggregation). None of these stages are defined in terms of each other or reduced to a fitted parameter that is then relabeled as a prediction. No equations or self-citations are presented in the provided text that would make the central claim (improved robustness under non-stationarity) equivalent to its inputs by construction. The method is described as novel, with public code, and the performance claims rest on external experiments rather than internal re-labeling of fitted quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- diversification strength modulation
axioms (1)
- domain assumption Highly similar past segment does not necessarily imply similar future due to non-stationarity
Reference graph
Works this paper leans on
-
[1]
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebas- tian Pineda Arango, Shubham Kapoor, et al. 2024. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815(2024)
Pith/arXiv arXiv 2024
-
[2]
George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung. 2015. Time series analysis: forecasting and control. John Wiley & Sons
2015
-
[3]
Jaime Carbonell and Jade Goldstein. 1998. The use of MMR, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval. 335–336
1998
-
[4]
Jialin Chen, Ziyu Zhao, Gaukhar Nurbek, Aosong Feng, Ali Maatouk, Leandros Tassiulas, Yifeng Gao, and Rex Ying. 2025. TRACE: Grounding Time Series in Context for Multimodal Embedding and Retrieval.arXiv preprint arXiv:2506.09114 (2025)
arXiv 2025
-
[5]
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. 2024. A decoder- only foundation model for time-series forecasting. InForty-first International Conference on Machine Learning
2024
-
[6]
Mohammad Azhar Mat Daut, Mohammad Yusri Hassan, Hayati Abdullah, Hasimah Abdul Rahman, Md Pauzi Abdullah, and Faridah Hussin. 2017. Building electrical energy consumption forecasting analysis using conventional and arti- ficial intelligence methods: A review.Renewable and Sustainable Energy Reviews 70 (2017), 1108–1118
2017
-
[7]
David A Dickey and Wayne A Fuller. 1979. Distribution of the estimators for autoregressive time series with a unit root.Journal of the American statistical association74, 366a (1979), 427–431
1979
-
[8]
Dazhao Du, Tao Han, and Song Guo. 2025. Predicting the Future by Retrieving the Past.arXiv preprint arXiv:2511.05859(2025)
arXiv 2025
-
[9]
Sungwon Han, Seungeon Lee, Meeyoung Cha, Sercan O Arik, and Jinsung Yoon
-
[10]
InForty-second International Conference on Machine Learning
Retrieval Augmented Time Series Forecasting. InForty-second International Conference on Machine Learning
-
[11]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory.Neural computation9, 8 (1997), 1735–1780
1997
-
[12]
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. 2021. Reversible instance normalization for accurate time-series forecasting against distribution shift. InInternational conference on learning representations
2021
-
[13]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[14]
Zichao Li. 2025. Retrieval-augmented forecasting with tabular time series data. InProceedings of the 4th Table Representation Learning Workshop. 192–199
2025
-
[15]
Shengsheng Lin, Weiwei Lin, Xinyi Hu, Wentai Wu, Ruichao Mo, and Haocheng Zhong. 2024. Cyclenet: Enhancing time series forecasting through modeling periodic patterns.Advances in Neural Information Processing Systems37 (2024), 106315–106345
2024
-
[16]
Marco Lippi, Matteo Bertini, and Paolo Frasconi. 2013. Short-term traffic flow forecasting: An experimental comparison of time-series analysis and supervised learning.IEEE Transactions on Intelligent Transportation Systems14, 2 (2013), 871–882
2013
-
[17]
Peiyuan Liu, Beiliang Wu, Yifan Hu, Naiqi Li, Tao Dai, Jigang Bao, and Shu- tao Xia. 2024. Timebridge: Non-stationarity matters for long-term time series forecasting.arXiv preprint arXiv:2410.04442(2024)
arXiv 2024
-
[18]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. 2024. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations
2024
-
[19]
Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. 2022. Non-stationary transformers: Exploring the stationarity in time series forecasting.Advances in neural information processing systems35 (2022), 9881–9893
2022
-
[20]
Zhiding Liu, Mingyue Cheng, Zhi Li, Zhenya Huang, Qi Liu, Yanhu Xie, and Enhong Chen. 2023. Adaptive normalization for non-stationary time series fore- casting: A temporal slice perspective.Advances in Neural Information Processing Systems36 (2023), 14273–14292
2023
-
[21]
Zhiding Liu, Mingyue Cheng, Guanhao Zhao, Jiqian Yang, Qi Liu, and Enhong Chen. 2025. Improving Time Series Forecasting via Instance-aware Post-hoc Revision.arXiv preprint arXiv:2505.23583(2025)
arXiv 2025
-
[22]
Jiaming Ma, Binwu Wang, Qihe Huang, Guanjun Wang, Pengkun Wang, Zhengyang Zhou, and Yang Wang. 2025. Mofo: Empowering long-term time series forecasting with periodic pattern modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[23]
Y Nie. 2022. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers.arXiv preprint arXiv:2211.14730(2022)
Pith/arXiv arXiv 2022
-
[24]
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2025. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. In The Eleventh International Conference on Learning Representations
2025
-
[25]
Kanghui Ning, Zijie Pan, Yu Liu, Yushan Jiang, James Y Zhang, Kashif Rasul, Anderson Schneider, Lintao Ma, Yuriy Nevmyvaka, and Dongjin Song. 2025. Ts-rag: Retrieval-augmented generation based time series foundation models are stronger zero-shot forecaster.arXiv preprint arXiv:2503.07649(2025)
arXiv 2025
-
[26]
Ser-Huang Poon and Clive W J Granger. 2003. Forecasting volatility in financial markets: A review.Journal of economic literature41, 2 (2003), 478–539
2003
-
[27]
Ilan Price, Alvaro Sanchez-Gonzalez, Ferran Alet, Tom R Andersson, Andrew El-Kadi, Dominic Masters, Timo Ewalds, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, et al. 2025. Probabilistic weather forecasting with machine learning. Nature637, 8044 (2025), 84–90
2025
-
[28]
Xiangfei Qiu, Xingjian Wu, Yan Lin, Chenjuan Guo, Jilin Hu, and Bin Yang
-
[29]
In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Duet: Dual clustering enhanced multivariate time series forecasting. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 1185–1196
-
[30]
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. 2020. DeepAR: Probabilistic forecasting with autoregressive recurrent networks.Inter- national journal of forecasting36, 3 (2020), 1181–1191
2020
-
[31]
Yongcheol Shin and Peter Schmidt. 1992. The KPSS stationarity test as a unit root test.Economics Letters38, 4 (1992), 387–392
1992
-
[32]
Kutay Tire, Ege Onur Taga, Muhammed Emrullah Ildiz, and Samet Oymak. 2024. Retrieval augmented time series forecasting.arXiv preprint arXiv:2411.08249 (2024)
Pith/arXiv arXiv 2024
-
[33]
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y Zhang, and Jun Zhou. 2024. Timemixer: Decomposable multiscale mixing for time series forecasting.arXiv preprint arXiv:2405.14616(2024)
arXiv 2024
-
[34]
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. 2024. Unified training of universal time series forecasting transformers. (2024)
2024
-
[35]
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. 2022. Timesnet: Temporal 2d-variation modeling for general time series analysis.arXiv preprint arXiv:2210.02186(2022)
Pith/arXiv arXiv 2022
-
[36]
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. 2023. TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis. InThe Eleventh International Conference on Learning Representations
2023
-
[37]
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: De- composition transformers with auto-correlation for long-term series forecasting. Advances in neural information processing systems34 (2021), 22419–22430
2021
-
[38]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. 2023. Are transformers effective for time series forecasting?. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 11121–11128
2023
-
[39]
Huanyu Zhang, Chang Xu, Yi-Fan Zhang, Zhang Zhang, Liang Wang, and Jiang Bian. 2025. Timeraf: Retrieval-augmented foundation model for zero-shot time series forecasting.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[40]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond efficient transformer for long se- quence time-series forecasting. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 11106–11115. Stationarity-Aware Retrieval-Augmented Time Series Forecasting Appendix A Dataset Sta...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.