When Offline Selectors Cannot Beat the Best Single Model: A Diagnostic Study on edX Dropout Prediction
Pith reviewed 2026-06-28 11:07 UTC · model grok-4.3
The pith
Offline selectors for edX dropout prediction match the best single model but miss a 9.7-point oracle gain due to local representational ambiguity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
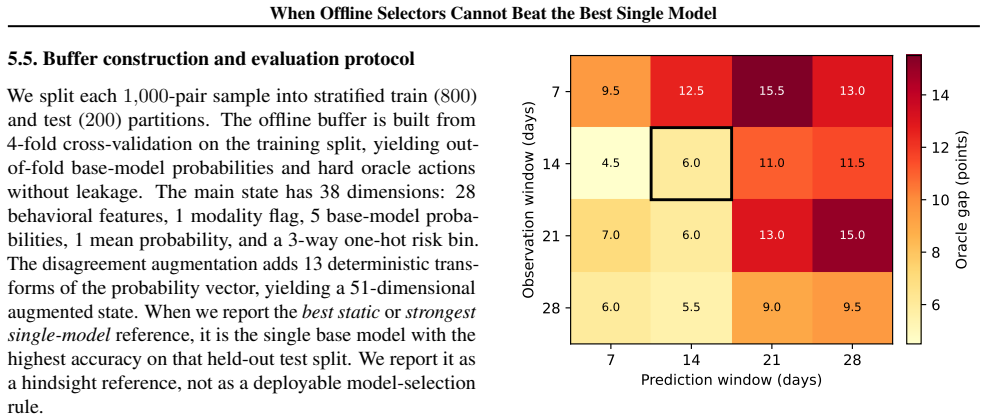
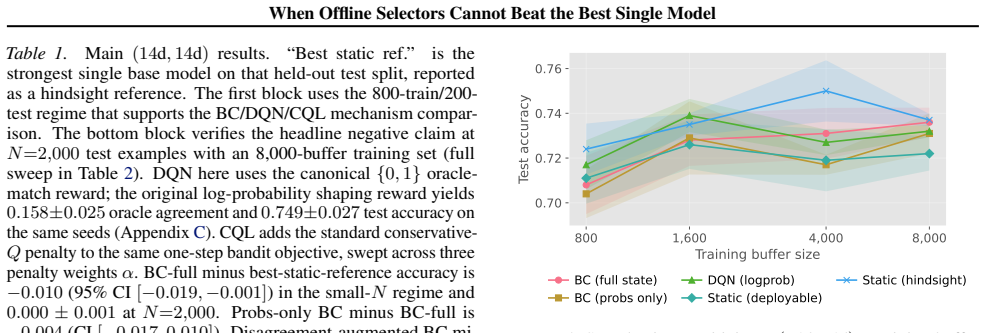
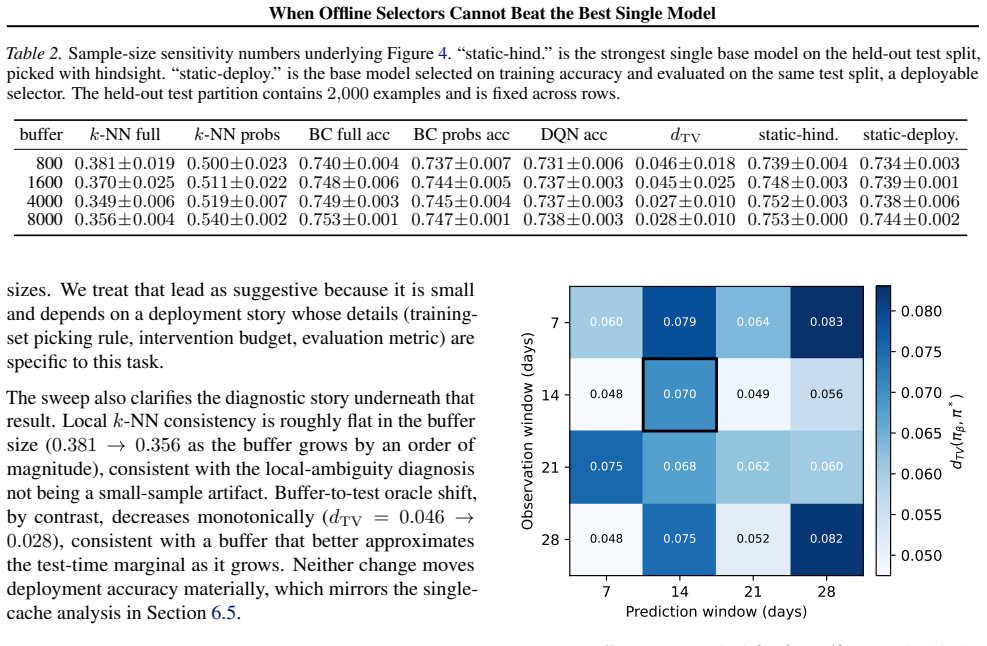
Across 16 windows, the oracle beats the strongest single base model by 9.7 accuracy points on average, yet BC, DQN, and CQL land in the same test-accuracy band below it. The bottleneck is local representational ambiguity: CQL closes the imitation gap without a deployment gain, regret clusters tightly across learners, and the three learners converge on test accuracy.
What carries the argument
Three-stage diagnostic that estimates an oracle ceiling via k-NN label consistency, tests whether BC and offline-RL learners reach that ceiling, then ablates the selector state to check whether richer features would raise performance.
If this is right
- The next step should be redesigning the selector state or collecting new data rather than tuning the offline learner.
- CQL closes the imitation gap without deployment gain, showing conservatism is not the limiting factor.
- Regret clusters tightly across learners, so the problem is not in tie-breaking.
- Learner convergence on test accuracy rules out buffer-to-deployment label shift.
Where Pith is reading between the lines
- Enriching the state with additional clickstream-derived features might allow selectors to distinguish winning models per instance.
- The same diagnostic could separate algorithm, representation, and data issues in other per-instance selection settings.
- Using smaller neighborhoods for the k-NN ceiling estimate could tighten the bound on local ambiguity.
Load-bearing premise
The k-NN label consistency measure gives a reliable estimate of the highest accuracy any selector could achieve on the observed data.
What would settle it
If selectors trained on the same data and learners but with substantially richer state features reach accuracy close to the oracle ceiling while the original state does not, the representational ambiguity diagnosis is supported.
Figures


read the original abstract
Different predictors often excel on different inputs, so picking the best one per instance promises higher accuracy than committing to a single model. In practice, selectors trained from logged data routinely fail to beat the strongest single predictor. Three causes typically go unseparated before more tuning is applied: a mismatched learner, a state that does not predict which model wins, or buffer-to-deployment label shift. A three-stage diagnostic rules them out on a shared buffer. Stage~1 estimates a local ceiling on oracle recovery from $k$-NN label consistency. Stage~2 asks whether paired BC and offline-RL learners (BC, DQN, and CQL across penalty weights) reach that ceiling. Stage~3 ablates the selector state to test whether richer features would raise it. The combined verdict points to the most promising next step: tuning the learner, redesigning the state, or collecting new data. We apply it to selecting among five dropout-prediction models on edX clickstream data. Across 16 windows, the oracle beats the strongest single base model by 9.7 accuracy points on average, yet BC, DQN, and CQL land in the same test-accuracy band below it (robust to a tenfold buffer sweep and $N{=}2{,}000$ held-out examples). The bottleneck is local representational ambiguity: CQL closes the imitation gap without a deployment gain (not conservatism), regret clusters tightly across learners (not tie-breaking), and the three learners converge on test accuracy (not shift). The next iteration should change the state or collect new data, not tune the offline learner further.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a three-stage diagnostic to isolate why offline selectors (BC, DQN, CQL) fail to beat the strongest single base model when choosing among five dropout predictors on edX clickstream data. Stage 1 uses k-NN label consistency on the selector state to estimate an oracle ceiling; Stage 2 trains multiple offline learners and compares them to this ceiling and to single-model baselines; Stage 3 ablates the state representation. Across 16 windows the oracle improves accuracy by 9.7 points on average, yet all selectors remain below it; the authors conclude the bottleneck is local representational ambiguity rather than learner mismatch or label shift, and recommend changing the state or collecting new data.
Significance. If the diagnostic is sound, the work supplies a practical, reusable procedure for diagnosing offline selection failures that can steer practitioners away from unproductive hyper-parameter tuning. The explicit robustness checks (tenfold buffer sweep, N=2000 held-out examples) and the use of multiple learners (BC/DQN/CQL) with regret and imitation-gap analysis are concrete strengths that increase the result's actionability.
major comments (1)
- [Stage 1] Stage 1 (abstract): the k-NN label-consistency ceiling is computed in the identical state representation whose sufficiency is under test. This creates a potential circularity: low consistency may simply reflect the representational deficiency rather than an independent upper bound on what any selector could achieve. Stage 3 ablation is intended to isolate the issue, yet the manuscript does not report a control that recomputes the k-NN ceiling under an enriched state before ablation, leaving the central attribution to "local representational ambiguity" dependent on an unverified independence assumption.
minor comments (2)
- The abstract states that exact data-processing steps and feature definitions are not visible; the full manuscript should include a concise table or appendix listing the clickstream features, any preprocessing (e.g., windowing, normalization), and the precise definition of the selector state vector.
- Table or figure reporting per-window oracle vs. best-single gaps would make the 9.7-point average claim easier to verify and would allow readers to assess variance across the 16 windows.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our diagnostic framework. We address the single major comment below and will revise the manuscript to incorporate an additional control as suggested.
read point-by-point responses
-
Referee: [Stage 1] Stage 1 (abstract): the k-NN label-consistency ceiling is computed in the identical state representation whose sufficiency is under test. This creates a potential circularity: low consistency may simply reflect the representational deficiency rather than an independent upper bound on what any selector could achieve. Stage 3 ablation is intended to isolate the issue, yet the manuscript does not report a control that recomputes the k-NN ceiling under an enriched state before ablation, leaving the central attribution to "local representational ambiguity" dependent on an unverified independence assumption.
Authors: We acknowledge the concern about potential circularity. The k-NN ceiling is intentionally computed in the tested state representation to quantify the maximum performance any selector could achieve given exactly those features, thereby measuring local representational ambiguity as the gap between this conditional ceiling and single-model baselines. It is not presented as a state-independent oracle. Stage 3 then tests whether state changes improve selector performance. To directly verify the independence assumption and strengthen the attribution, we will add a control experiment recomputing the k-NN ceiling on an enriched state (e.g., augmented clickstream features) before the ablation. This will be reported in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical diagnostic rests on external comparisons and standard algorithms
full rationale
The paper's three-stage diagnostic estimates an oracle ceiling via k-NN label consistency on the shared buffer, compares BC/DQN/CQL performance against it and single-model baselines, and performs state ablations. These steps rely on standard implementations and held-out test accuracy measurements rather than any equation that reduces the output to a fitted input or self-referential definition. No self-citations are invoked as load-bearing uniqueness theorems, and the conclusion that the bottleneck is representational ambiguity follows directly from the observed gaps without renaming known results or smuggling ansatzes. The framework is self-contained against the reported edX experiments.
Axiom & Free-Parameter Ledger
free parameters (1)
- k for k-NN ceiling
axioms (1)
- domain assumption k-NN label consistency in the buffer estimates the achievable oracle recovery ceiling
Reference graph
Works this paper leans on
-
[1]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author =. arXiv preprint arXiv:2005.01643 , year =. doi:10.48550/arXiv.2005.01643 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.01643 2005
-
[2]
Advances in Computers , volume =
The algorithm selection problem , author =. Advances in Computers , volume =. 1976 , publisher =. doi:10.1016/S0065-2458(08)60520-3 , url =
-
[3]
Information Fusion , volume =
Dynamic classifier selection: Recent advances and perspectives , author =. Information Fusion , volume =. 2018 , doi =
2018
-
[4]
Pattern Recognition , volume =
From dynamic classifier selection to dynamic ensemble selection , author =. Pattern Recognition , volume =. 2008 , doi =
2008
-
[5]
Cruz, Rafael M. O. and Sabourin, Robert and Cavalcanti, George D. C. and Ren, Tsang Ing , journal =. 2015 , doi =
2015
-
[6]
Education Sciences , volume =
Predicting Student Performance Using Clickstream Data and Machine Learning , author =. Education Sciences , volume =. 2023 , doi =
2023
-
[7]
Likely to stop? Predicting Stopout in Massive Open Online Courses
Likely to Stop? Predicting Stopout in Massive Open Online Courses , author =. arXiv preprint arXiv:1408.3382 , year =. doi:10.48550/arXiv.1408.3382 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1408.3382
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Conservative Q-Learning for Offline Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2020 , url =
2020
-
[9]
Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning , author =. arXiv preprint arXiv:1312.5602 , year =. doi:10.48550/arXiv.1312.5602 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.5602
-
[10]
Offline Reinforcement Learning with Implicit
Kostrikov, Ilya and Nair, Ashvin and Levine, Sergey , journal =. Offline Reinforcement Learning with Implicit. 2021 , url =
2021
-
[11]
Proceedings of the 36th International Conference on Machine Learning , series =
Off-Policy Deep Reinforcement Learning without Exploration , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
2019
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2019 , url =
2019
-
[13]
arXiv preprint arXiv:1911.11361 , year =
Behavior Regularized Offline Reinforcement Learning , author =. arXiv preprint arXiv:1911.11361 , year =
Pith/arXiv arXiv 1911
-
[14]
Neural Networks , volume =
Stacked generalization , author =. Neural Networks , volume =. 1992 , doi =
1992
-
[15]
Applied Intelligence , volume =
Using Meta-Learning to predict student performance in virtual learning environments , author =. Applied Intelligence , volume =. 2022 , doi =
2022
-
[16]
2018 , doi =
Dalipi, Fisnik and Imran, Ali Shariq and Kastrati, Zenun , booktitle =. 2018 , doi =
2018
-
[17]
Proceedings of the 17th International Conference on Educational Data Mining (EDM) , pages =
Early Prediction of Student Dropout in Higher Education using Machine Learning Models , author =. Proceedings of the 17th International Conference on Educational Data Mining (EDM) , pages =. 2024 , url =
2024
-
[18]
Lu, Jie and Liu, Anjin and Dong, Fan and Gu, Feng and Gama, Jo. Learning under Concept Drift:. IEEE Transactions on Knowledge and Data Engineering , year =. doi:10.1109/TKDE.2018.2876857 , url =
-
[19]
Proceedings of the 9th International Conference on Educational Data Mining (EDM) , pages =
A Contextual Bandits Framework for Personalized Learning Action Selection , author =. Proceedings of the 9th International Conference on Educational Data Mining (EDM) , pages =. 2016 , url =
2016
-
[20]
Proceedings of the 13th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , pages =
Offline Policy Evaluation Across Representations with Applications to Educational Games , author =. Proceedings of the 13th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , pages =. 2014 , publisher =
2014
-
[21]
Proceedings of the 28th International Conference on Machine Learning (ICML) , pages =
Doubly Robust Policy Evaluation and Learning , author =. Proceedings of the 28th International Conference on Machine Learning (ICML) , pages =. 2011 , publisher =
2011
-
[22]
Proceedings of the 32nd International Conference on Machine Learning , series =
Counterfactual Risk Minimization: Learning from Logged Bandit Feedback , author =. Proceedings of the 32nd International Conference on Machine Learning , series =. 2015 , publisher =
2015
-
[23]
Predicting Student Dropout in Self-Paced
Dass, Sheran and Gary, Kevin and Cunningham, James , journal =. Predicting Student Dropout in Self-Paced. 2021 , doi =
2021
-
[24]
Predicting Student Achievement Based on Temporal Learning Behavior in
Qu, Shaojie and Li, Kan and Wu, Bo and Zhang, Shuhui and Wang, Yongchao , journal =. Predicting Student Achievement Based on Temporal Learning Behavior in. 2019 , doi =
2019
-
[25]
Temporal predication of dropouts in
Xing, Wanli and Chen, Xin and Stein, Jared and Marcinkowski, Michael , journal =. Temporal predication of dropouts in. 2016 , doi =
2016
-
[26]
and Gama, Jo
Krawczyk, Bartosz and Minku, Leandro L. and Gama, Jo. Ensemble learning for data stream analysis:. Information Fusion , volume =. 2017 , doi =
2017
-
[27]
Computers & Education , volume =
Dropout prediction in e-learning courses through the combination of machine learning techniques , author =. Computers & Education , volume =. 2009 , doi =
2009
-
[28]
Predicting Dropout Student:
Yukselturk, Erman and Ozekes, Serhat and Turel, Yalin Kilic , journal =. Predicting Dropout Student:. 2014 , doi =
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.