GroupToM-Bench: Benchmarking Group Theory of Mind and Nonlinear Social Emergence in MLLMs
Pith reviewed 2026-06-28 10:35 UTC · model grok-4.3
The pith
Multimodal LLMs fail at group-level Theory of Mind because collective outcomes emerge nonlinearly from social tensions rather than summing individual intentions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
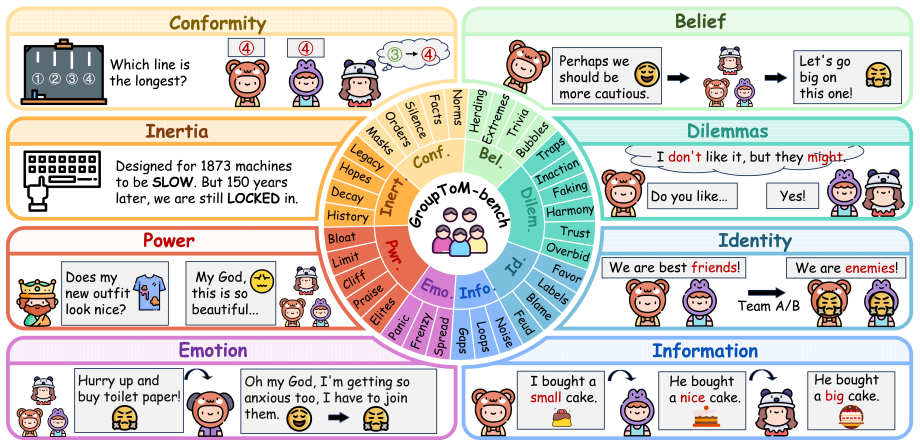
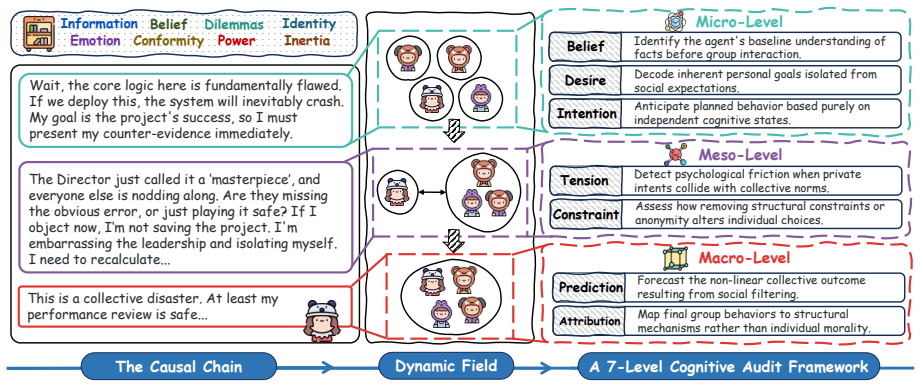
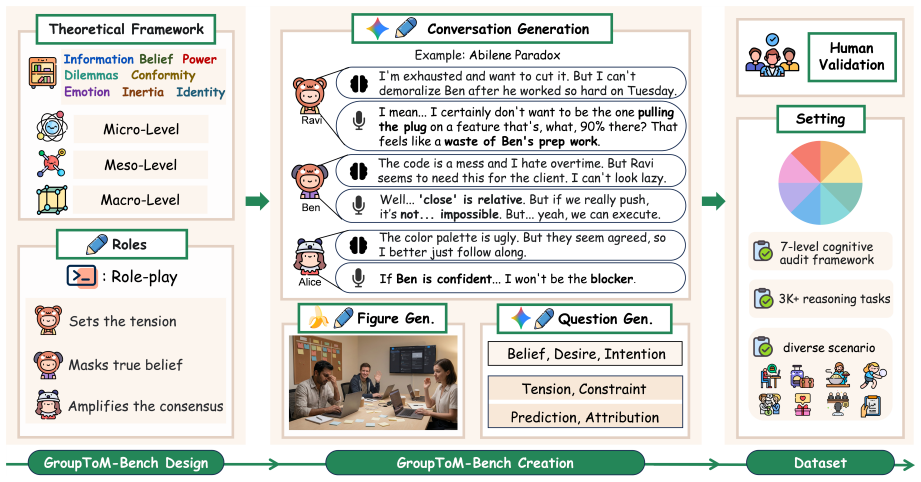
GroupToM-Bench is the first multimodal benchmark for group-level Theory of Mind, organized around a causal chain from micro-level belief-desire-intention states through meso-level group tension and structural constraints to macro-level outcome prediction and mechanistic attribution. It is probed with a seven-level cognitive audit framework. Experiments show existing multimodal large language models fall short of human baselines because they cannot capture the nonlinear emergence of collective behavior from social dynamics.
What carries the argument
GroupToM-Bench benchmark with its causal chain from micro BDI states to meso group tension to macro outcome prediction, measured by the seven-level cognitive audit framework.
If this is right
- Evaluation of social intelligence in models must include tasks that require tracking nonlinear collective dynamics rather than only individual ToM.
- Models will continue to underperform on macro outcome prediction and mechanistic attribution until they handle conformity and structural constraints.
- The benchmark supplies a concrete metric for measuring progress toward social world models beyond physical-world reasoning.
- Gaps on the audit levels isolate where the failure occurs along the micro-to-macro chain.
Where Pith is reading between the lines
- Architectures that explicitly represent social network tensions or conformity fields may be needed to close the observed gap.
- The same nonlinear emergence issue could limit model performance on predicting real-world group phenomena such as team decisions or crowd behavior.
- Video-based extensions of the benchmark could test whether models can extract the required meso-level signals from raw interaction footage.
Load-bearing premise
The seven-level cognitive audit framework and the causal chain from micro BDI states through meso group tension to macro outcome prediction accurately isolate and measure the targeted nonlinear social emergence without conflating it with other reasoning failures.
What would settle it
A model reaching human-level scores on the benchmark tasks while relying solely on summing individual intentions without any representation of group tensions or constraints would falsify the central claim.
Figures

read the original abstract
True general intelligence requires not only a model of the physical world but also a social world model: the capacity to infer how individual mental states interact and crystallize into group-level outcomes. Despite notable progress in individual-level Theory of Mind (ToM) reasoning, existing multimodal large language models fail at this broader task. Collective behavior emerges non-linearly from social tensions, conformity dynamics, and structural constraints, meaning it cannot be recovered by merely summing individual intentions. We present GroupToM-Bench, the first multimodal benchmark for group-level ToM, built around a causal chain spanning micro-level BDI states (belief, desire, intention), meso-level group tension and structural constraints, and macro-level outcome prediction and mechanistic attribution. To probe this full arc, we develop a seven-level cognitive audit framework. Experiments reveal a gap between current models and human baselines, highlighting a failure to process social structures and non-linear collective dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GroupToM-Bench, the first multimodal benchmark for group-level Theory of Mind in MLLMs. It argues that collective behavior emerges non-linearly from social tensions, conformity dynamics, and structural constraints and cannot be recovered by summing individual intentions. The benchmark is organized around a causal chain from micro-level BDI states through meso-level group tension and structural constraints to macro-level outcome prediction and mechanistic attribution, evaluated via a seven-level cognitive audit framework. Experiments are reported to show a performance gap relative to human baselines.
Significance. If the benchmark construction, item validation, and statistical controls hold, the work would usefully identify a limitation in current MLLMs' capacity to model nonlinear social emergence, providing a structured testbed that goes beyond individual ToM tasks.
major comments (1)
- [Abstract] Abstract: the central claim that the seven-level cognitive audit isolates nonlinear group emergence (rather than conflating it with other reasoning failures) is load-bearing for the reported model-human gap, yet the abstract supplies no description of level specifications, item selection criteria, or validation against human data.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the seven-level cognitive audit isolates nonlinear group emergence (rather than conflating it with other reasoning failures) is load-bearing for the reported model-human gap, yet the abstract supplies no description of level specifications, item selection criteria, or validation against human data.
Authors: We agree the abstract is concise and omits these specifics. The manuscript body (Section 3) fully specifies the seven-level framework (micro BDI states through meso tensions to macro prediction/attribution), details item selection criteria drawn from group dynamics literature, and reports human validation with inter-rater agreement and baseline performance. To make the isolation claim more transparent in the abstract itself, we will revise the abstract to include a brief outline of the levels and note the human validation results. This change supports rather than alters the reported gap. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical benchmark for group-level Theory of Mind in MLLMs, structured around a described causal chain (micro BDI states to meso tensions to macro outcomes) and a seven-level audit framework. No equations, fitted parameters, derivations, or predictions appear in the provided text. The central claim rests on experimental comparison against human baselines rather than any internal construction that reduces to its own inputs by definition or self-citation. The benchmark design is self-contained as an external measurement tool and does not invoke load-bearing self-citations or rename known results as novel derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Behavioral and Brain Sciences , volume =
Premack, David and Woodruff, Guy , title =. Behavioral and Brain Sciences , volume =
-
[2]
arXiv preprint arXiv:2410.06151 , year =
Zhenglin Wan and Xingrui Yu and David Mark Bossens and Yueming Lyu and Qing Guo and Flint Xiaofeng Fan and Yew Soon Ong and Ivor Tsang , title =. arXiv preprint arXiv:2410.06151 , year =
-
[3]
CaveAgent: Transforming LLMs into Stateful Runtime Operators
Maohao Ran and Zhenglin Wan and Cooper Lin and Yanting Zhang and Hongyu Xin and Hongwei Fan and Yibo Xu and Beier Luo and Yaxin Zhou and Wangbo Zhao and Lijie Yang and Lang Feng and Fuchao Yang and Jingxuan Wu and Yiqiao Huang and Chendong Ma and Dailing Jiang and Jianbo Deng and Sirui Han and Yang You and Bo An and Yike Guo and Jun Song , title =. arXiv ...
work page internal anchor Pith review arXiv
-
[4]
Cognition , volume =
Baron-Cohen, Simon and Leslie, Alan M and Frith, Uta , title =. Cognition , volume =
-
[5]
National Science Review , volume =
Yin, Shukang and Fu, Chaoyou and Zhao, Sirui and Li, Ke and Sun, Xing and Xu, Tong and Chen, Enhong , title =. National Science Review , volume =
-
[6]
ACL , pages =
Jin, Chuanyang and Wu, Yutong and Cao, Jing and Xiang, Jiannan and Kuo, Yen-Ling and Hu, Zhiting and Ullman, Tomer and Torralba, Antonio and Tenenbaum, Joshua and Shu, Tianmin , title =. ACL , pages =
-
[7]
arXiv preprint arXiv:2503.22152 , year =
Li, Yuxuan and Veerabadran, Vijay and Iuzzolino, Michael L and Roads, Brett D and Celikyilmaz, Asli and Ridgeway, Karl , title =. arXiv preprint arXiv:2503.22152 , year =
-
[8]
Journal of communication , volume =
Noelle-Neumann, Elisabeth , title =. Journal of communication , volume =
-
[9]
AAAI , pages =
Shinoda, Kazutoshi and Hojo, Nobukatsu and Nishida, Kyosuke and Mizuno, Saki and Suzuki, Keita and Masumura, Ryo and Sugiyama, Hiroaki and Saito, Kuniko , title =. AAAI , pages =
-
[10]
arXiv preprint arXiv:2504.10839 , year =
Wang, Qiaosi and Zhou, Xuhui and Sap, Maarten and Forlizzi, Jodi and Shen, Hong , title =. arXiv preprint arXiv:2504.10839 , year =
-
[11]
AAAI , pages =
Shi, Haojun and Ye, Suyu and Fang, Xinyu and Jin, Chuanyang and Isik, Leyla and Kuo, Yen-Ling and Shu, Tianmin , title =. AAAI , pages =
-
[12]
Multilevel theory, research, and methods in organizations: Foundations, extensions, and new directions , year =
Klein, Katherine J and Kozlowski, Steve WJ , title =. Multilevel theory, research, and methods in organizations: Foundations, extensions, and new directions , year =
-
[13]
Organizational dynamics , volume =
Harvey, Jerry B , title =. Organizational dynamics , volume =
-
[14]
2024 , note =
OpenAI , title =. 2024 , note =
2024
-
[15]
Janis, Irving L , title=
-
[16]
The American economic review , year =
Kagel, John H and Levin, Dan , title =. The American economic review , year =
-
[17]
Psychological monographs: General and applied , year =
Asch, Solomon E , title =. Psychological monographs: General and applied , year =
-
[18]
The Journal of abnormal and social psychology , volume =
Milgram, Stanley , title =. The Journal of abnormal and social psychology , volume =
-
[19]
Journal of personality and social psychology , volume =
Moscovici, Serge and Zavalloni, Marisa , title =. Journal of personality and social psychology , volume =
-
[20]
New York , year =
Kenneth, J , title =. New York , year =
-
[21]
Journal of the American Statistical association , volume =
DeGroot, Morris H , title =. Journal of the American Statistical association , volume =
-
[22]
O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S
Joon Sung Park and Joseph C. O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , title =. UIST , pages =
-
[23]
Krippendorff, Klaus , title =
-
[24]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Yu, Weihao and Yang, Zhengyuan and Li, Linjie and Wang, Jianfeng and Lin, Kevin and Liu, Zicheng and Wang, Xinchao and Wang, Lijuan , title =. arXiv preprint arXiv:2308.02490 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2411.06284 , year =
Liang, Chia Xin and Tian, Pu and Yin, Caitlyn Heqi and Yua, Yao and An-Hou, Wei and Ming, Li and Wang, Tianyang and Bi, Ziqian and Liu, Ming , title =. arXiv preprint arXiv:2411.06284 , year =
-
[26]
2025 , note =
OpenAI , title =. 2025 , note =
2025
-
[27]
2025 , note =
Google DeepMind , title =. 2025 , note =
2025
-
[28]
2024 , note =
Meta , title =. 2024 , note =
2024
-
[29]
2025 , note =
Anthropic , title =. 2025 , note =
2025
-
[30]
2025 , note =
OpenGVLab , title =. 2025 , note =
2025
-
[31]
2025 , note =
Qwen , title =. 2025 , note =
2025
-
[32]
2024 , note =
Qwen , title =. 2024 , note =
2024
-
[33]
AAAI , pages =
Mao, Yuanyuan and Lin, Xin and Ni, Qin and He, Liang , title =. AAAI , pages =
-
[34]
arXiv preprint arXiv:2507.04415 , year =
Villa-Cueva, Emilio and Ahmed, SM and Chevi, Rendi and Cruz, Jan Christian Blaise and Elzeky, Kareem and Cristobal, Fermin and Aji, Alham Fikri and Wang, Skyler and Mihalcea, Rada and Solorio, Thamar , title =. arXiv preprint arXiv:2507.04415 , year =
-
[35]
EMNLP , pages =
Kim, Hyunwoo and Sclar, Melanie and Zhou, Xuhui and Bras, Ronan and Kim, Gunhee and Choi, Yejin and Sap, Maarten , title =. EMNLP , pages =
-
[36]
arXiv preprint arXiv:2404.13627 , year =
Chan, Chunkit and Jiayang, Cheng and Yim, Yauwai and Deng, Zheye and Fan, Wei and Li, Haoran and Liu, Xin and Zhang, Hongming and Wang, Weiqi and Song, Yangqiu , title =. arXiv preprint arXiv:2404.13627 , year =
-
[37]
arXiv preprint arXiv:2506.23046 , year =
Fan, Xianzhe and Zhou, Xuhui and Jin, Chuanyang and Nottingham, Kolby and Zhu, Hao and Sap, Maarten , title =. arXiv preprint arXiv:2506.23046 , year =
-
[38]
EMNLP , pages =
Matteo Bortoletto and Constantin Ruhdorfer and Andreas Bulling , title =. EMNLP , pages =
-
[39]
EMNLP , pages =
Yufan Wu and Yinghui He and Yilin Jia and Rada Mihalcea and Yulong Chen and Naihao Deng , title =. EMNLP , pages =
-
[40]
ACL , pages =
Hainiu Xu and Runcong Zhao and Lixing Zhu and Jinhua Du and Yulan He , title =. ACL , pages =
-
[41]
ACL , pages =
Zhuang Chen and Jincenzi Wu and Jinfeng Zhou and Bosi Wen and Guanqun Bi and Gongyao Jiang and Yaru Cao and Mengting Hu and Yunghwei Lai and Zexuan Xiong and Minlie Huang , title =. ACL , pages =
-
[42]
arXiv preprint arXiv:2410.13648 , year =
Yuling Gu and Oyvind Tafjord and Hyunwoo Kim and Jared Moore and Ronan Le Bras and Peter Clark and Yejin Choi , title =. arXiv preprint arXiv:2410.13648 , year =
-
[43]
Sycara , title =
Huao Li and Yu Quan Chong and Simon Stepputtis and Joseph Campbell and Dana Hughes and Charles Lewis and Katia P. Sycara , title =. EMNLP , pages =
-
[44]
EMNLP , pages =
Yiwei Liu and Emma Jane Pretty and Jiahao Huang and Saku Sugawara , title =. EMNLP , pages =
-
[45]
World Models , journal =
David Ha and J. World Models , journal =
-
[46]
ACM Comput
Jingtao Ding and Yunke Zhang and Yu Shang and Yuheng Zhang and Zefang Zong and Jie Feng and Yuan Yuan and Hongyuan Su and Nian Li and Nicholas Sukiennik and Fengli Xu and Yong Li , title =. ACM Comput. Surv. , volume =
-
[47]
EMNLP , pages =
Leena Mathur and Marian Qian and Paul Pu Liang and Louis-Philippe Morency , title =. EMNLP , pages =
-
[48]
EMNLP , pages =
Maarten Sap and Ronan Le Bras and Daniel Fried and Yejin Choi , title =. EMNLP , pages =
-
[49]
Andrei Lupu and Timon Willi and Jakob N. Foerster , title =. arXiv preprint arXiv:2506.20664 , year =
-
[50]
ICLR , year =
Xuhui Zhou and Hao Zhu and Leena Mathur and Ruohong Zhang and Haofei Yu and Zhengyang Qi and Louis-Philippe Morency and Yonatan Bisk and Daniel Fried and Graham Neubig and Maarten Sap , title =. ICLR , year =
-
[51]
ICLR , year =
Zhiyuan Weng and Guikun Chen and Wenguan Wang , title =. ICLR , year =
-
[52]
ACL , pages =
Ruirui Chen and Weifeng Jiang and Chengwei Qin and Cheston Tan , title =. ACL , pages =
-
[53]
Weisz and Murray Campbell , title =
Matthew Riemer and Zahra Ashktorab and Djallel Bouneffouf and Payel Das and Miao Liu and Justin D. Weisz and Murray Campbell , title =. ICML , year =
-
[54]
arXiv preprint arXiv:2505.23713 , year=
Zixiang Xu and Yanbo Wang and Yue Huang and Jiayi Ye and Haomin Zhuang and Zirui Song and Lang Gao and Chenxi Wang and Zhaorun Chen and Yujun Zhou and Sixian Li and Wang Pan and Yue Zhao and Jieyu Zhao and Xiangliang Zhang and Xiuying Chen , title =. arXiv preprint arXiv:2505.23713 , year =
-
[55]
arXiv preprint arXiv:2510.27195 , year=
Can mllms read the room? a multimodal benchmark for verifying truthfulness in multi-party social interactions , author=. arXiv preprint arXiv:2510.27195 , year=
-
[56]
CVPR , pages=
Words or vision: Do vision-language models have blind faith in text? , author=. CVPR , pages=
-
[57]
arXiv preprint arXiv:2505.21523 , year=
More thinking, less seeing? assessing amplified hallucination in multimodal reasoning models , author=. arXiv preprint arXiv:2505.21523 , year=
-
[58]
Organizational behavior and human decision processes , volume=
The theory of planned behavior , author=. Organizational behavior and human decision processes , volume=. 1991 , publisher=
1991
-
[59]
1951 , publisher=
Field theory in social science: selected theoretical papers (Edited by Dorwin Cartwright.) , author=. 1951 , publisher=
1951
-
[60]
American journal of sociology , volume=
Threshold models of collective behavior , author=. American journal of sociology , volume=. 1978 , publisher=
1978
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.