Answer Self-Consistency with Margin-Triggered Question Re-Arbitration for the CVPR 2026 VidLLMs Challenge
Pith reviewed 2026-06-28 07:23 UTC · model grok-4.3
The pith
Multiple stochastic runs with answer-level self-consistency improve video question-answering accuracy over single-pass inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
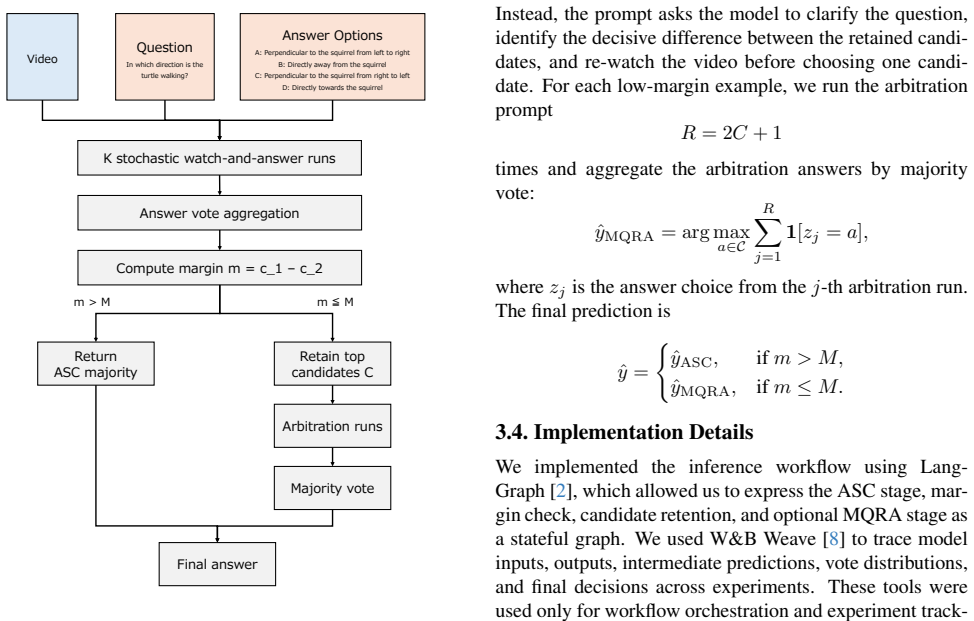
The core ASC component performs multiple stochastic video question-answering runs and aggregates their answer choices through answer-level self-consistency. This substantially improves over single-pass inference and forms our final test submission.
What carries the argument
Answer Self-Consistency (ASC), which counts identical answer choices across multiple independent stochastic runs of the same video-question pair.
If this is right
- ASC raises validation average accuracy to 72.73 and test average accuracy to 81.16.
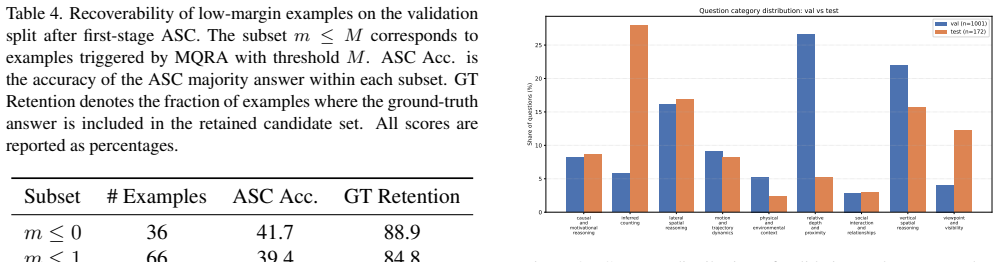
- Low-margin vote distributions frequently keep the ground-truth answer among the top few candidates.
- MQRA improves validation scores by narrowing candidates for uncertain cases but lowers test accuracy.
- The final submission therefore relies on ASC alone without re-arbitration.
Where Pith is reading between the lines
- The same vote-aggregation pattern may lift performance on other video or image reasoning benchmarks that use multiple-choice outputs.
- Margin signals could be combined with other uncertainty measures to reduce sensitivity to category distribution shifts.
- The method shows that test-time compute scaling via repeated inference can substitute for additional training in some multimodal settings.
Load-bearing premise
The base multimodal model must generate sufficiently varied and informative answers across stochastic runs for the vote aggregation to select the correct choice more often than a single run.
What would settle it
On the same test videos and questions, a single deterministic forward pass matches or exceeds the accuracy obtained by aggregating five or more stochastic runs.
Figures
read the original abstract
In this report, we present our solution for Track 2 of the CVPR 2026 VidLLMs Challenge. This track evaluates visual relational reasoning in videos, where models must infer relations that are not always explicitly visible. We propose Answer Self-Consistency with Margin-Triggered Question Re-Arbitration (ASC-MQRA), a training-free test-time reasoning framework built on a multimodal reasoning model. The core ASC component performs multiple stochastic video question-answering runs and aggregates their answer choices through answer-level self-consistency. This substantially improves over single-pass inference and forms our final test submission. We further study MQRA, a conditional re-arbitration module for low-margin examples where the first-stage vote distribution indicates uncertainty. Our vote-margin analysis shows that low-margin examples often retain the ground-truth answer among the top candidates, motivating MQRA to narrow the candidate set and re-watch the video only over the retained candidates. On validation, MQRA further improves over ASC, indicating that low-margin vote distributions can provide a useful uncertainty signal. On test, however, MQRA slightly degrades performance relative to ASC, suggesting that re-arbitration is sensitive to the size and category distribution of the triggered subset. Our final test submission therefore uses ASC without re-arbitration, achieving 72.73 average accuracy and 78.34 category-wise macro average accuracy on validation, and 81.16 average accuracy and 80.91 category-wise macro average accuracy on test. This report details our prompting strategy, implementation setup, ablation studies, and diagnostic analyses. The code is available at https://github.com/data-analytics-labo/ASC-MQRA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Answer Self-Consistency with Margin-Triggered Question Re-Arbitration (ASC-MQRA), a training-free test-time framework for Track 2 of the CVPR 2026 VidLLMs Challenge on visual relational reasoning in videos. The core ASC component runs multiple stochastic video QA inferences and aggregates answer choices via answer-level self-consistency. MQRA is an optional conditional re-arbitration step for low-margin vote distributions. Validation ablations show MQRA improves over ASC alone, but test results show slight degradation, so the final submission uses ASC only, reporting 72.73 average / 78.34 macro accuracy on validation and 81.16 average / 80.91 macro accuracy on test. The report includes prompting strategy, implementation, ablations, vote-margin diagnostics, and a GitHub code link.
Significance. If the reported numbers hold, the work demonstrates that answer-level self-consistency provides a practical, training-free boost to multimodal video reasoning performance in a competition setting. The public code release and diagnostic analysis of vote margins as an uncertainty signal are explicit strengths that support reproducibility and future extensions. The honest reporting of MQRA's test-time degradation adds value by highlighting sensitivity to data distribution.
major comments (2)
- [Results and Ablations] The abstract and results claim that ASC 'substantially improves over single-pass inference,' but no quantitative single-pass baseline accuracy, number of stochastic runs, or variance across runs is provided in the reported metrics. This is load-bearing for assessing the magnitude and reliability of the central empirical claim (see Results section and Table of accuracies).
- [Implementation Setup] The base multimodal reasoning model (name, size, checkpoint) and exact prompting templates used to generate the stochastic outputs are referenced but not enumerated in the text. This limits evaluation of whether the stochastic diversity assumption holds and affects reproducibility of the ASC component, even with the code link.
minor comments (2)
- [Diagnostic Analyses] The vote-margin analysis is useful but would benefit from explicit counts or percentages of examples triggering MQRA on validation vs. test to quantify the distribution shift mentioned.
- [Results] Category-wise macro accuracy is reported alongside average accuracy; clarify whether the macro is over the same categories as the challenge or a subset.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation for minor revision, and the constructive comments on empirical quantification and reproducibility. We address each major comment below.
read point-by-point responses
-
Referee: [Results and Ablations] The abstract and results claim that ASC 'substantially improves over single-pass inference,' but no quantitative single-pass baseline accuracy, number of stochastic runs, or variance across runs is provided in the reported metrics. This is load-bearing for assessing the magnitude and reliability of the central empirical claim (see Results section and Table of accuracies).
Authors: We agree that the quantitative single-pass baseline, number of runs, and variance are necessary to substantiate the improvement claim. In the revised manuscript we will add these values (single-pass accuracy, run count, and run-wise variance) to the Results section and accuracy table. revision: yes
-
Referee: [Implementation Setup] The base multimodal reasoning model (name, size, checkpoint) and exact prompting templates used to generate the stochastic outputs are referenced but not enumerated in the text. This limits evaluation of whether the stochastic diversity assumption holds and affects reproducibility of the ASC component, even with the code link.
Authors: While the GitHub repository contains the complete implementation, we acknowledge that the main text should explicitly list the model details and prompts. In the revision we will add a concise enumeration of the base model (name, size, checkpoint) and the exact prompting templates in the Implementation Setup section. revision: yes
Circularity Check
No significant circularity; purely empirical competition report
full rationale
The manuscript is a technical report for a CVPR challenge track that describes an empirical test-time method (ASC-MQRA) consisting of repeated stochastic inference followed by vote aggregation and optional margin-based re-arbitration. All performance claims are backed by concrete accuracy numbers on held-out validation and test splits, with ablations and diagnostic vote-margin statistics. No equations, derivations, uniqueness theorems, or self-citations appear; the central results are direct measurements rather than reductions of fitted parameters or prior author work. The derivation chain is therefore empty and the report is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Moment sampling in video llms for long-form video qa.arXiv preprint arXiv:2507.00033, 2025
Mustafa Chasmai, Gauri Jagatap, Gouthaman KV , Grant Van Horn, Subhransu Maji, and Andrea Fanelli. Moment sam- pling in video llms for long-form video qa.arXiv preprint arXiv:2507.00033, 2025. 12
-
[2]
Langgraph.https://github.com/ langchain-ai/langgraph, 2026
LangChain AI. Langgraph.https://github.com/ langchain-ai/langgraph, 2026. Accessed: 2026-05-
2026
-
[3]
Sirnam Swetha, Rohit Gupta, Parth Parag Kulkarni, David G Shatwell, Jeffrey A Chan Santiago, Nyle Siddiqui, Joseph Fioresi, and Mubarak Shah. Vrr-qa: Visual relational rea- soning in videos beyond explicit cues.arXiv preprint arXiv:2506.21742, 2026. 1, 2
-
[4]
Confidence im- proves self-consistency in llms
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. Confidence im- proves self-consistency in llms. InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 20090– 20111, 2025. 12
2025
-
[5]
Implicitqa dataset.https : / / huggingface
UCF CRCV. Implicitqa dataset.https : / / huggingface . co / datasets / ucf - crcv / ImplicitQA, 2025. Accessed: 2026-05-29. 1, 2
2025
-
[6]
Cvpr 2026 vidllms work- shop challenges.https : / / www
VidLLMs Workshop Organizers. Cvpr 2026 vidllms work- shop challenges.https : / / www . crcv . ucf . edu / cvpr2026 - vidllms - workshop / challenges . html, 2026. Accessed: 2026-05-29. 1
2026
-
[7]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought rea- soning in language models. InThe Eleventh International Conference on Learning Representations, 2023. 1, 2
2023
-
[8]
Weave by weights & biases.https: //github.com/wandb/weave, 2026
Weights & Biases. Weave by weights & biases.https: //github.com/wandb/weave, 2026. Accessed: 2026- 05-31. 3
2026
-
[9]
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in Space: How Multi- modal Large Language Models See, Remember and Recall Spaces.arXiv preprint arXiv:2412.14171, 2024. 12 7 Appendix A. Prompts We provide the prompts used in the first-stage watch-and-answer runs and the margin-triggered re-arbitration stage. The...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
8 Restate what the question is asking in your own words
Understand the question correctly. 8 Restate what the question is asking in your own words. Be precise about what must be answered: a person/object, count, order, direction, spatial relation, viewpoint, cause/reason, outcome/result, identity, social relation, or physical state. Mention only the aspects that are relevant to this question. Do not add assump...
-
[11]
Identify what makes the candidate options different from each other
Clarify the difference between the remaining candidates. Identify what makes the candidate options different from each other. Focus on the decisive visual fact, relation, event, or inference that would make one candidate correct and the others wrong. Do not merely restate the original question
-
[12]
Verify what is actually visible or strongly implied by the video
Re-watch the video and judge. Verify what is actually visible or strongly implied by the video. Treat unsupported assumptions as unreliable. Do not use earlier vote counts or prior candidate preferences
-
[13]
question_understanding
Answer the question. Choose exactly one remaining candidate. Select the option that directly answers the question and is best supported by the video-grounded evidence. If evidence is still incomplete, choose the option that requires the fewest unsupported assumptions. Return JSON only: {{ "question_understanding": "...", "candidate_difference": "...", "an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.