Policy Gradient for Continuous-Time Robust Markov Decision Processes
Pith reviewed 2026-06-28 07:17 UTC · model grok-4.3
The pith
Policy gradients and adversarial gradients for continuous-time robust MDPs are derived from pathwise and adjoint formulas on differential equations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
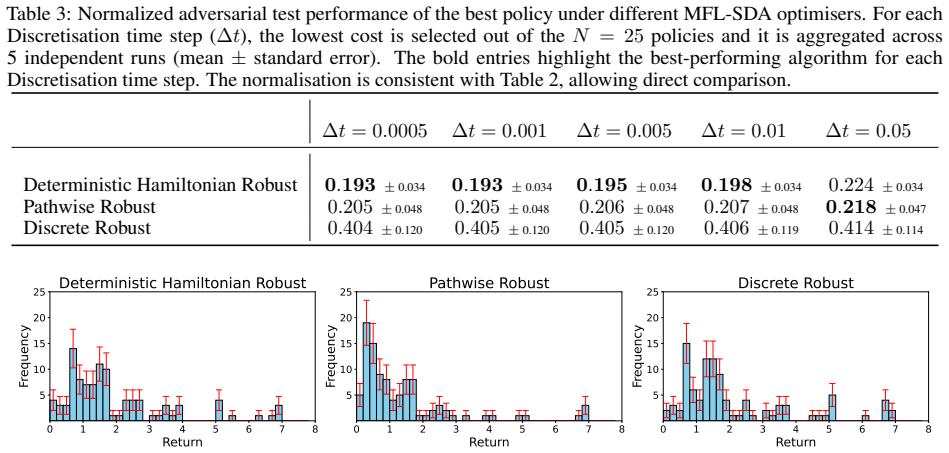
In the continuous-time RMDP framework, policy gradients and adversarial gradients are obtained through pathwise differentiation and adjoint methods applied to SDEs and ODEs. These gradients enable double-loop optimization algorithms that converge linearly in the oracle model and attain Õ(1/ε²) sample complexity in the sample-based model for undiscounted total-cost MDPs. Mean-field versions of the optimizers are shown to converge at Õ(1/K) in the oracle setting and Õ(N²/ε) under N-particle approximation. The methods are validated on continuous-time RMDPs whose dynamics are given by neural ODEs.
What carries the argument
Pathwise and adjoint-based gradient formulas for SDEs and ODEs within the continuous-time robust MDP model.
Load-bearing premise
The continuous-time RMDP framework allows derivation of policy and adversarial gradients via pathwise and adjoint methods for SDEs and ODEs, and that the proposed optimizers achieve the stated convergence rates under the undiscounted total cost MDP analysis.
What would settle it
Running the double-loop optimizer on a benchmark continuous-time RMDP and observing sublinear convergence instead of linear convergence would falsify the claimed rates.
Figures
read the original abstract
The framework of robust Markov decision processes (RMDPs) allows the design of reinforcement learning agents that satisfy performance guarantees under worst-case transition dynamics. Traditional RMDPs consider discrete-time dynamics and recently, sample-efficient policy gradient algorithms have been considered in this context. This paper investigates policy gradient algorithms within a continuous-time RMDP framework. Policy gradients and adversarial gradients are derived using pathwise and adjoint-based formulas for stochastic and ordinary differential equations. We propose double-loop optimisers to obtain linear convergence in the oracle-based setting and an $\tilde{\mathcal{O}}(\frac{1}{\epsilon^2})$ sample complexity in the sample-based setting in an analysis which also derives novel tools for the framework of undiscounted total cost MDPs. Additionally, we propose mean-field optimisers as distributional optimisers with an $\tilde{\mathcal{O}}(\frac{1}{K})$ oracle-based convergence rate and an $\tilde{\mathcal{O}}(\frac{N^2}{\epsilon})$ sample complexity under $N$-particle approximation. The effectiveness of continuous-time policy gradient algorithms is confirmed for both optimisers on continuous-time RMDPs with neural ordinary differential equation dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops policy gradient algorithms for continuous-time robust Markov decision processes (RMDPs). It derives policy and adversarial gradients via pathwise and adjoint-based formulas for SDEs and ODEs. Double-loop optimizers are proposed to achieve linear convergence in the oracle-based setting and Õ(1/ε²) sample complexity in the sample-based setting, supported by novel tools for undiscounted total-cost MDPs; mean-field optimizers are also introduced with Õ(1/K) oracle convergence and Õ(N²/ε) sample complexity under N-particle approximation. The methods are validated empirically on continuous-time RMDPs with neural ODE dynamics.
Significance. If the gradient derivations and convergence rates hold, the work extends robust RL to continuous time with explicit rates and novel analysis tools for undiscounted total-cost settings, which could enable more reliable policy optimization in control applications. The provision of both oracle and sample-based guarantees plus mean-field variants strengthens the contribution if the undiscounted analysis is complete.
major comments (1)
- [Analysis of undiscounted total-cost MDPs (referenced in abstract)] The central convergence claims (linear oracle convergence and Õ(1/ε²) sample complexity) rest on novel tools for undiscounted total-cost MDPs to justify derivative-expectation interchange and contraction arguments. The provided analysis must explicitly state global boundedness, uniform integrability, or absorbing-state conditions; local Lipschitz assumptions alone are insufficient to guarantee the rates outside a neighborhood of the optimum, as noted in the stress-test concern.
minor comments (2)
- Clarify the precise form of the pathwise and adjoint gradient formulas (e.g., any regularity conditions on the SDE/ODE coefficients) to allow direct verification of the derivations.
- The experimental section should report the specific neural ODE architectures, discretization schemes, and robustness parameters used in the validation to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our work extending policy gradients to continuous-time robust MDPs. We address the major comment below and will revise the manuscript accordingly to strengthen the theoretical foundations.
read point-by-point responses
-
Referee: [Analysis of undiscounted total-cost MDPs (referenced in abstract)] The central convergence claims (linear oracle convergence and Õ(1/ε²) sample complexity) rest on novel tools for undiscounted total-cost MDPs to justify derivative-expectation interchange and contraction arguments. The provided analysis must explicitly state global boundedness, uniform integrability, or absorbing-state conditions; local Lipschitz assumptions alone are insufficient to guarantee the rates outside a neighborhood of the optimum, as noted in the stress-test concern.
Authors: We agree that the convergence analysis for the undiscounted total-cost setting requires explicit global conditions to rigorously justify the interchange of derivative and expectation as well as the contraction mapping arguments. While the manuscript introduces novel tools under local Lipschitz continuity of the dynamics and running costs (standard for SDE/ODE control problems), these alone do not suffice for global rates. In the revised version we will augment the standing assumptions (currently in Section 3) with either (i) global boundedness of the value functions together with uniform integrability of the cost processes, or (ii) an absorbing-state condition ensuring almost-sure termination in finite time. The corresponding modifications will be inserted into the statements of Theorems 4.1 and 4.3 and their proofs, thereby extending the linear oracle convergence and Õ(1/ε²) sample-complexity guarantees from a neighborhood of the optimum to the full parameter space. We believe this clarification directly resolves the concern while preserving the novelty of the undiscounted analysis. revision: yes
Circularity Check
No circularity: derivations rely on standard SDE/ODE techniques and external MDP analysis
full rationale
The paper's central claims derive policy/adversarial gradients via pathwise and adjoint formulas for SDEs/ODEs and obtain convergence rates for double-loop and mean-field optimizers in continuous-time RMDPs. These build on established differential equation methods and introduce novel tools for undiscounted total-cost MDPs without any quoted step reducing by construction to a fitted parameter, self-citation chain, or renamed input. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided abstract or description; the framework is self-contained against external stochastic control benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Regret based Robust Solutions for Uncertain Markov Decision Processes
Asrar Ahmed and Patrick Jaillet. Regret based Robust Solutions for Uncertain Markov Decision Processes. InAdvances in Neural Information Processing (NeurIPS 2013), pages 1–9,
2013
-
[2]
Faster Policy Learning with Continuous-Time Gradients
Samuel Ainsworth, Kendall Lowrey, John Thickstun, Zaid Harchaoui, and Siddhartha Srinivasa. Faster Policy Learning with Continuous-Time Gradients. InProceedings of the Conference on Learning for Dynamics and Control (L4DC 2021), pages 1054–1067,
2021
-
[3]
Maxim Balashov, Boris Polyak, and Andrey Tremba. Gradient projection and conditional gradient methods for constrained nonconvex minimization.arXiv preprint arXiv:1906.11580,
Pith/arXiv arXiv 1906
-
[4]
A Distributional Perspective on Reinforcement Learning
Marc G Bellemare, Will Dabney, and Rémi Munos. A Distributional Perspective on Reinforcement Learning. In International Conference on Machine Learning (ICML 2017), volume 70,
2017
-
[5]
Riccardo Bonalli and Benoît Bonnet
ISBN 9780691079516. Riccardo Bonalli and Benoît Bonnet. First-order pontryagin maximum principle for risk-averse stochastic optimal control problems.SIAM Journal on Control and Optimization, 61(3):1881–1909,
1909
-
[6]
David Mark Bossens and Atsushi Nitanda
doi: 10.1137/22M1489137. David Mark Bossens and Atsushi Nitanda. Mirror descent policy optimisation for robust constrained markov decision processes.Transactions on Machine Learning Research,
-
[7]
J2C Certification
ISSN 2835-8856. J2C Certification. Steven Bradtke and Michael Duff. Reinforcement learning methods for continuous-time markov decision problems. In Advances in Neural Information Processing Systems (NeurIPS 1994),
1994
-
[8]
ISSN 0246-0203. doi: 10.1214/24-aihp1499. Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems (NeurIPS 2018), volume 31,
-
[9]
Cohen, Jackson Hebner, Deqing Jiang, and Justin Sirignano
Samuel N. Cohen, Jackson Hebner, Deqing Jiang, and Justin Sirignano. Neural actor-critic methods for hamilton- jacobi-bellman pdes: Asymptotic analysis and numerical studies.arXiv preprint arXiv:2507.06428, pages 1–41,
-
[10]
How to Learn and Generalize From Three Minutes of Data: Physics- Constrained and Uncertainty-Aware Neural Stochastic Differential Equations
Franck Djeumou, Cyrus Neary, and Ufuk Topcu. How to Learn and Generalize From Three Minutes of Data: Physics- Constrained and Uncertainty-Aware Neural Stochastic Differential Equations. InConference on Robot Learning (CoRL 2023),
2023
-
[11]
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Lasse Espeholt, Hubert Soyer, Rémi Munos, Karen Simonyan, V olodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures. InInternational Conference on Machine Learning (ICML 2018),
2018
-
[12]
Mirror mean-field langevin dynamics.arXiv preprint arXiv:2505.02621,
Anming Gu and Juno Kim. Mirror mean-field langevin dynamics.arXiv preprint arXiv:2505.02621,
-
[13]
Finding mixed Nash equilibria of generative adversarial networks
Ya-Ping Hsieh, Chen Liu, and V olkan Cevher. Finding mixed Nash equilibria of generative adversarial networks. In International Conference on Machine Learning (ICML 2019), pages 2810–2819,
2019
-
[14]
Yanwei Jia and Xun Yu Zhou. Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms.arXiv preprint arXiv:2111.11232,
-
[15]
Bekzhan Kerimkulov, James-Michael Leahy, David Siska, Lukasz Szpruch, and Yufei Zhang. A fisher-rao gradient flow for entropy-regularised markov decision processes in polish spaces.arXiv preprint arXiv:2310.02951,
-
[16]
Toshinori Kitamura, Arnob Ghosh, Alex Ayoub, Thang D. Chu, and Csaba Szepesvári. Revisiting subgradient dominance in robust mdps: Counterexamples, hardness, and sufficient conditions.arXiv preprint arXiv:2604.21177,
-
[17]
Towards Faster Global Convergence of Robust Policy Gradient Methods
31 Navdeep Kumar and Kfir Levy. Towards Faster Global Convergence of Robust Policy Gradient Methods. InEuropean Workshop on Reinforcement Learning (EWRL 2023), pages 1–13,
2023
-
[18]
Jongmin Lee and Ernest Ryu. Why Policy Gradient Algorithms Work for Undiscounted Total-Reward MDPs.arXiv preprint arXiv:2510.18340,
-
[19]
Robust Markov Decision Processes on Continuous State Spaces
Mengmeng Li, Yifan Hu, Daniel Kuhn, and Yan Li. Robust markov decision processes on continuous state spaces. arXiv preprint arXiv:2605.28706, 2026a. Mengmeng Li, Tobias Sutter, and Daniel Kuhn. Policy gradient algorithms for robust mdps with non-rectangular uncertainty sets. 36(1):120–151, 2026b. ISSN 1052-6234. doi: 10.1137/24M1631250. Qianxiao Li, Long ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1137/24m1631250
-
[20]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR 2019),
2019
-
[21]
Q-learning and pontryagin’s minimum principle
Prashant Mehta and Sean Meyn. Q-learning and pontryagin’s minimum principle. InProceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference, pages 3598– 3605,
2009
-
[22]
Jincheng Mei, Chenjun Xiao, Csaba Szepesvári, and Dale Schuurmans
doi: 10.1109/CDC.2009.5399753. Jincheng Mei, Chenjun Xiao, Csaba Szepesvári, and Dale Schuurmans. On the global convergence rates of softmax policy gradient methods. InInternational Conference on Machine Learning (ICML 2020),
-
[23]
Johannes Müller, Semih Çaycı, and Guido Montúfar
ISSN 15337928. Johannes Müller, Semih Çaycı, and Guido Montúfar. Fisher-rao gradient flows of linear programs and state-action natural policy gradients.arXiv preprint arXiv:2403.19448,
-
[24]
ISSN 0030364X. doi: 10.1287/opre.1050.0216. Félix Otto and Cédric Villani. Generalization of an inequality by talagrand and links with the logarithmic sobolev inequality.Journal of Functional Analysis, 173(2):361–400,
-
[25]
David Pfau, Ian Davies, Diana Borsa, Joao G
ISSN 0022-1236. David Pfau, Ian Davies, Diana Borsa, Joao G. M. Araujo, Brendan Tracey, and Hado van Hasselt. Wasserstein policy optimization.arXiv preprint arXiv:2505.00663,
-
[26]
DPPO : Diffusion Policy Policy Optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. DPPO : Diffusion Policy Policy Optimization. InInternational Conference on Learning Representations (ICLR 2025), pages 1–42,
2025
-
[27]
doi: 10.1007/s13373-017-0101-1
ISSN 1664-3615. doi: 10.1007/s13373-017-0101-1. David Silver, Guy Lever, Nicholas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic Policy Gradient Algorithms. InInternational Conference on Machine Learning (ICML 2014), Bejing, China,
-
[28]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
doi: 10.1137/17M1126825. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR 2021),
-
[29]
Policy Optimization for Robust Average Cost MDPs
Zhongchang Sun. Policy Optimization for Robust Average Cost MDPs. InAdvances in Neural Information Processing (NeurIPS 2024),
2024
-
[30]
Convergence of mean-field langevin dynamics: time-space discretization, stochastic gradient, and variance reduction
Taiji Suzuki, Denny Wu, and Atsushi Nitanda. Convergence of mean-field langevin dynamics: time-space discretization, stochastic gradient, and variance reduction. InAdvances in Neural Information Processing Systems (NeurIPS 2023), volume 36, pages 15545–15577,
2023
-
[31]
Iancu, Ça˘gıl Koçyi˘git, and Daniel Kuhn
Bahar Taskesen, Dan A. Iancu, Ça˘gıl Koçyi˘git, and Daniel Kuhn. Distributionally robust linear quadratic control. In Advances in Neural Information Processing Systems (NeurIPS 2023),
2023
-
[32]
Belinda Tzen and Maxim Raginsky. Neural stochastic differential equations: Deep latent gaussian models in the diffusion limit.arXiv preprint arXiv:1905.09883,
arXiv 1905
-
[33]
International Conference on Design and Manufacturing (IConDM2013)
ISSN 1877-7058. International Conference on Design and Manufacturing (IConDM2013). Qiuhao Wang, Shaohang Xu, Chin Pang Ho, and Marek Petrik. Policy gradient for robust markov decision processes. arXiv preprint arXiv:2410.22114,
-
[34]
Provable Policy Gradient for Robust Average-Reward MDPs Beyond Rectangularity
Qiuhao Wang, Yuqi Zha, Chin Pang, and Ho Marek. Provable Policy Gradient for Robust Average-Reward MDPs Beyond Rectangularity. InInternational Conference on Machine Learning (ICML 2025),
2025
-
[35]
ISSN 0364765X. doi: 10.1287/moor.1120.0566. Guojian Zhan, Yuxuan Jiang, Jingliang Duan, Shengbo Eben Li, Bo Cheng, and Keqiang Li. Continuous-time policy optimization. In2023 American Control Conference (ACC), pages 3382–3388,
-
[36]
doi: 10.23919/ACC55779. 2023.10156372. Hanyang Zhao, Wenpin Tang, and David Yao. Policy optimization for continuous reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS 2023),
-
[37]
Xiangxin Zhou, Liang Wang, and Yichi Zhou
doi: 10.1137/23M1570739. Xiangxin Zhou, Liang Wang, and Yichi Zhou. Stabilizing policy gradients for stochastic differential equations via consistency with perturbation process,
-
[38]
Denis Zorba, David Šiška, and Lukasz Szpruch. Convergence of actor-critic for entropy regularised mdps in general action spaces.arXiv preprint arXiv:2510.14898,
-
[39]
Lemma 8 (Discrete-time policy gradient) Let h be the discretisation step size and tn :=nh
A Supporting lemmata A.1 General lemmata The discrete-time policy gradient can be derived for random ODEs according to the following lemma. Lemma 8 (Discrete-time policy gradient) Let h be the discretisation step size and tn :=nh . Recall that we work under a stochastic policy un ∼π θ(·|tn, xn) for the discrete cost Jh(θ, ξ) =E hPN−1 n=1 r(tn, xn, un)h+R(...
2024
-
[40]
Hence we can use the so-called transient performance difference lemma for our formulation. Lemma 11 (Transient performance difference lemma, Lee and Ryu (2026)) For a total cost MDP M= (x0,P, r,X,U) , where x0 is the starting state, P is the transition kernel, r is the cost function, and X and U are the state and action spaces. Let M have a finite value f...
2026
-
[41]
Lemma 12 (Transient performance difference lemma for transition kernels) Let θ∈Θ and let P,P ′ ∈ P
Using the above transient visitation measure also leads to recovering results from discounted MDPs, in particular the performance difference lemmas for transition kernels (Li et al., 2026b; Wang et al., 2024). Lemma 12 (Transient performance difference lemma for transition kernels) Let θ∈Θ and let P,P ′ ∈ P . Under the conditions and definitions of Lemma ...
2024
-
[42]
For deterministic policy gradient based algorithms, both optimizers worked well and so the SGD was chosen
is used for the stochastic policy gradient based optimizers (the discrete-time baseline and the stochastic policy gradient algorithm) as this improved the performance compared to SGD. For deterministic policy gradient based algorithms, both optimizers worked well and so the SGD was chosen. The policy learning rate was tuned separately for the different op...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.