Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
Pith reviewed 2026-06-28 06:41 UTC · model grok-4.3
The pith
Web agents reuse skills more effectively by retrieving them dynamically to match both the task goal and the current webpage state instead of fixing a set at the outset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
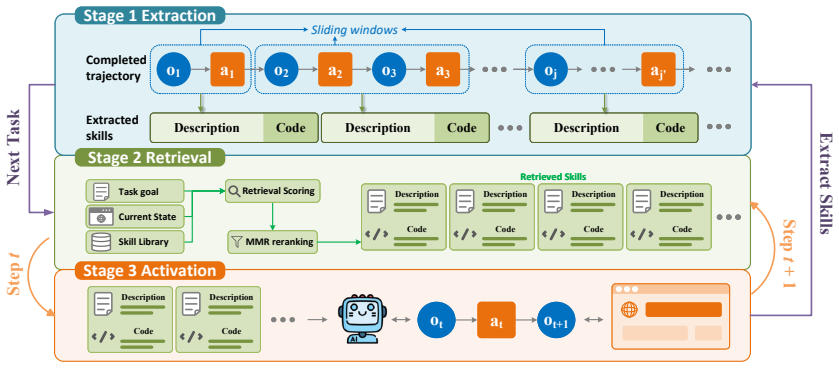
State-Grounded Dynamic Retrieval extracts reusable sub-procedures from trajectories via sliding-window segmentation, represents each in paired text and code, and performs dynamic retrieval at every step by jointly matching the task instruction and the current webpage state, thereby enabling stepwise skill reuse that static task-level methods cannot achieve.
What carries the argument
The state-grounded dynamic retrieval mechanism that selects sub-procedures by matching both task goal and current webpage state through dual text-code representations.
If this is right
- Skill reuse becomes possible at arbitrary intermediate points rather than only at task start.
- Agents can cover execution branches that diverge from the initial trajectory.
- Online learning no longer requires the initial skill set to anticipate every future state.
- Performance gains appear across both large and smaller language models on the same benchmarks.
Where Pith is reading between the lines
- The same sliding-window extraction plus state matching could be tested on non-web sequential domains such as robotic manipulation where states also evolve unpredictably.
- If the dual text-code representation proves essential, removing the code component should measurably degrade retrieval accuracy on state-matching tasks.
- Extending the method to retain only high-success sub-procedures after each episode could further reduce retrieval noise over long sessions.
Load-bearing premise
Sub-procedures cut from completed trajectories will correctly match and execute when retrieved at intermediate states in new tasks.
What would settle it
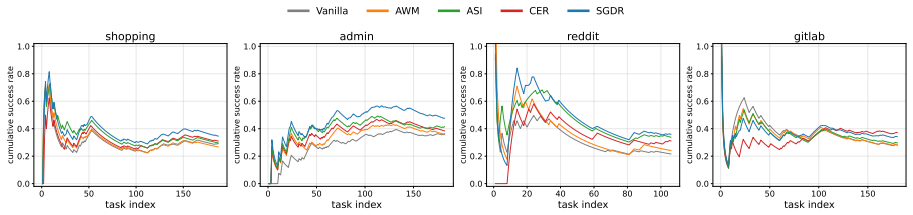
Running SGDR and the strongest static baseline on the same WebArena tasks and finding that SGDR produces equal or lower average success rates.
Figures


read the original abstract
Language agents increasingly rely on reusable skills to improve multi-step web automation across related tasks. A growing line of work studies online skill learning, where agents continually induce skills from previous task trajectories and reuse them in future tasks on the fly. However, existing methods mainly reuse skills at the task-level: a fixed set of skills is retrieved based on the initial task instruction and then held fixed throughout execution. This static strategy is misaligned with web execution, where the appropriate next action depends not only on the task goal but also on the current webpage state, which often transitions into situations that the initial skills fail to cover. To address this gap, we propose State-Grounded Dynamic Retrieval (SGDR), an online skill learning method that enables stepwise skill reuse for web agents. SGDR consists of three components: a sliding-window extraction process that turns completed trajectories into reusable sub-procedures invokable at intermediate execution states, a dual text-code representation that connects skill retrieval with executable action, and a state-grounded dynamic retrieval mechanism that matches skills to both the task goal and the current webpage state. Experiments on WebArena across five domains show that SGDR consistently outperforms strong baselines, achieving average success rates of 37.5% with GPT-4.1 and 24.3% with Qwen3-4B, corresponding to relative gains of 10.6% and 10.0% over the strongest baseline, respectively. The code is available at https://github.com/plusnli/skill-dynamic-retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes State-Grounded Dynamic Retrieval (SGDR) for online skill learning in web agents. It extracts reusable sub-procedures from completed trajectories via sliding-window, encodes them with a dual text-code representation, and retrieves them dynamically during execution by matching both the task goal and the current webpage state. Experiments on WebArena across five domains report that SGDR achieves average success rates of 37.5% (GPT-4.1) and 24.3% (Qwen3-4B), corresponding to relative gains of 10.6% and 10.0% over the strongest baseline; code is released.
Significance. If the empirical results hold under rigorous controls, SGDR would address a genuine limitation of static task-level skill reuse in web agents by enabling state-dependent retrieval. The code release and concrete reported gains on a standard benchmark are strengths that would support adoption and follow-up work.
major comments (2)
- [Abstract] Abstract: the reported success rates and relative gains are presented without any information on baseline definitions, number of runs, statistical significance, variance, or failure modes. This information is load-bearing for the central empirical claim that the dynamic mechanism, rather than prompting differences or task ordering, drives the 10.6%/10.0% improvements.
- [Method / Experiments] Method and Experiments sections: the claim that sliding-window sub-procedures extracted from completed trajectories will reliably match and execute correctly at intermediate states in unseen tasks rests on the untested assumption that cosine/embedding similarity on the dual representation selects skills whose preconditions hold and whose actions advance the trajectory. No retrieval-precision analysis, precondition checks, or ablation isolating the state-grounded component at arbitrary webpage states is described; if retrieval precision is low, the headline gains could be artifacts.
minor comments (2)
- [Abstract] Abstract: consider briefly defining the five WebArena domains and the strongest baseline for immediate context.
- [Method] Notation: the dual text-code representation is introduced without an explicit equation or pseudocode showing how the two modalities are combined for retrieval scoring.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the clarity and rigor of our empirical claims. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported success rates and relative gains are presented without any information on baseline definitions, number of runs, statistical significance, variance, or failure modes. This information is load-bearing for the central empirical claim that the dynamic mechanism, rather than prompting differences or task ordering, drives the 10.6%/10.0% improvements.
Authors: We agree that the abstract should be self-contained with respect to the key experimental controls. The full manuscript already details the baselines (Section 4.1), evaluation protocol (5 runs per task with reported means), and variance in the results tables, but these were omitted from the abstract for brevity. In the revision we will expand the abstract to explicitly name the strongest baseline, state the number of runs, and note that gains are consistent across domains with standard deviation reported in the main text. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: the claim that sliding-window sub-procedures extracted from completed trajectories will reliably match and execute correctly at intermediate states in unseen tasks rests on the untested assumption that cosine/embedding similarity on the dual representation selects skills whose preconditions hold and whose actions advance the trajectory. No retrieval-precision analysis, precondition checks, or ablation isolating the state-grounded component at arbitrary webpage states is described; if retrieval precision is low, the headline gains could be artifacts.
Authors: The referee correctly notes the absence of a dedicated retrieval-precision study. While end-to-end success rates on WebArena provide indirect evidence that retrieved skills are useful, we did not quantify precision@K or precondition satisfaction at arbitrary states. We will add (1) a new ablation that disables the state-grounded component while keeping the dual representation and sliding-window extraction fixed, and (2) a retrieval analysis reporting precision and precondition-match rates on held-out intermediate states. These additions will appear in a new subsection of the experiments. revision: yes
Circularity Check
Empirical method with no derivation chain
full rationale
The paper describes an algorithmic procedure (sliding-window extraction, dual text-code representation, state-grounded retrieval) and reports experimental success rates on WebArena. No equations, first-principles derivations, or predictions are presented that reduce by construction to quantities defined from the method's own fitted parameters or self-citations. The contribution is framed as an empirical engineering result with released code, consistent with the reader's assessment of score 2.0; the central claims rest on external benchmark comparisons rather than internal self-definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Webpage states encountered during execution can be effectively represented and matched to previously extracted sub-procedures via text and code embeddings.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems, 36:28091–28114
Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems, 36:28091–28114. Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. 2024. WorkArena: How capable are web agents at solving common knowledge work tasks? In Pr...
Pith/arXiv arXiv 2024
-
[2]
Advances in Neural Information Processing Systems, 38:111259–111284
Mitigating hallucination through theory- consistent symmetric multimodal preference op- timization. Advances in Neural Information Processing Systems, 38:111259–111284. Yitao Liu, Chenglei Si, Karthik R Narasimhan, and Shunyu Yao. 2025. Contextual experience re- play for self-improvement of language agents. In Proceedings of the 63rd Annual Meeting of the...
2025
-
[3]
WebLINX: Real-world website navigation with multi-turn dialogue. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 33007–33056. PMLR. Zijian Lu, Yiping Zuo, Yupeng Nie, Xin He, Weibei Fan, and Chen Dai. 2026. Contractskill: Repairable contract-based skills for multimodal ...
Pith/arXiv arXiv 2026
-
[4]
Advances in Neural Information Processing Systems, 37:130109– 130135
Online adaptation of language models with 10 a memory of amortized contexts. Advances in Neural Information Processing Systems, 37:130109– 130135. Qitao Tan, Xiaoying Song, Arman Akbari, Arash Ak- bari, Yanzhi Wang, Xiaoming Zhai, Lingzi Hong, Zhen Xiang, Jin Lu, and Geng Yuan. 2026a. Palette: A modular, controllable, and efficient framework for on-demand...
Pith/arXiv arXiv 2025
-
[5]
Polyskill: Learning generalizable skills through polymorphic abstraction. arXiv preprint arXiv:2510.15863. Tao Yu, Zhengbo Zhang, Zhiheng Lyu, Junhao Gong, Hongzhu Yi, Xinming Wang, Yuxuan Zhou, Jiabing Yang, Ping Nie, Yan Huang, and Wenhu Chen. 2026. Browseragent: Building web agents with human- inspired web browsing actions. Transactions on Machine Lear...
arXiv 2026
-
[6]
The bot's response must contain the information the user wants, or explicitly state that the information is not available
Information seeking: The user wants to obtain certain information from the webpage, such as the information of a product, reviews, map info, comparison of map routes, etc. The bot's response must contain the information the user wants, or explicitly state that the information is not available. Otherwise, e.g. the bot encounters an exception and respond wi...
-
[7]
Carefully examine the bot's action history and the final state of the webpage to determine whether the bot successfully completes the task
Site navigation: The user wants to navigate to a specific page. Carefully examine the bot's action history and the final state of the webpage to determine whether the bot successfully completes the task. No need to consider the bot's response
-
[8]
Status:
Content modification: The user wants to modify the content of a webpage or configuration. Carefully examine the bot's action history and the final state of the webpage to determine whether the bot successfully completes the task. No need to consider the bot's response. *IMPORTANT* Format your response into two lines as shown below: Thoughts: <your thought...
-
[9]
fill title + fill body + click submit
Is the window a *reusable* sub-routine? A reusable window: - Performs a recognizable web operation that could occur on other tasks (e.g. searching a product, applying a price filter, posting a comment, opening a user profile). - Is general enough to apply with different inputs: variable parts (search queries, usernames, element ids that obviously vary acr...
-
[10]
submit a forum post
If reusable, produce: - description: a single sentence that MUST contain both (a) a precise action verb + object (e.g. " submit a forum post", "apply a price filter ", "open a forum-selection combobox", "fill in the title and body"); and (b) the typical page context where this routine runs (e.g. "on a forum submission form", "on a product listing page", "...
-
[11]
Names the kind of page in operational terms ( e.g.'forum submission form','product listing page','opened forum-selection combobox','post-detail page with comment section')
-
[12]
Check if the social security admin- istration in pittsburgh can be reached in one hour by car from CMU
Lists the action verbs this page ENABLES right now - i.e. what sub-routines could plausibly run on this exact state. Use verb + object phrasing (e.g.'submit a post',' select a forum','fill in the title and body ','open the sort menu','apply a filter'). Do NOT enumerate every visible element, do NOT describe pure visuals (colors, layout), and do NOT mentio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.