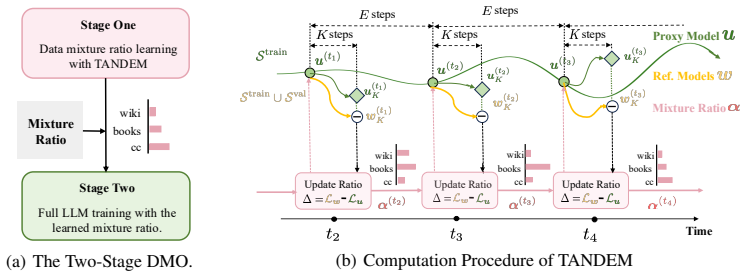
TANDEM: Bi-Level Data Mixture Optimization with Twin Networks
Pith reviewed 2026-06-28 07:38 UTC · model grok-4.3
The pith
TANDEM simplifies bi-level data mixture optimization to a penalized single-level form solved by twin networks that up-weight domains based on model differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
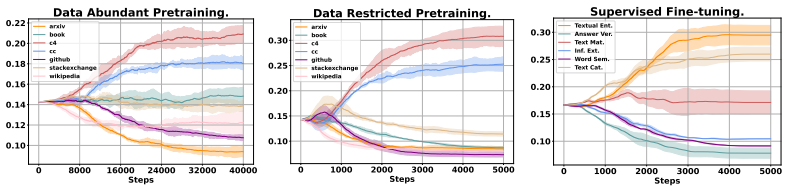
The central claim is that the difference between a proxy model trained only on primary data and a reference model trained with additional domain data serves as a reliable indicator of genuine data efficacy, allowing the mixture ratios to be optimized by up-weighting helpful domains within a simplified single-level optimization that preserves the original bi-level optimum.
What carries the argument
Twin networks (proxy model on primary data and dynamically updated reference model) whose output difference measures domain efficacy inside the simplified penalized objective derived from the original bi-level formulation.
If this is right
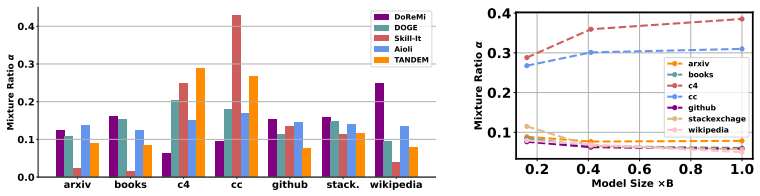
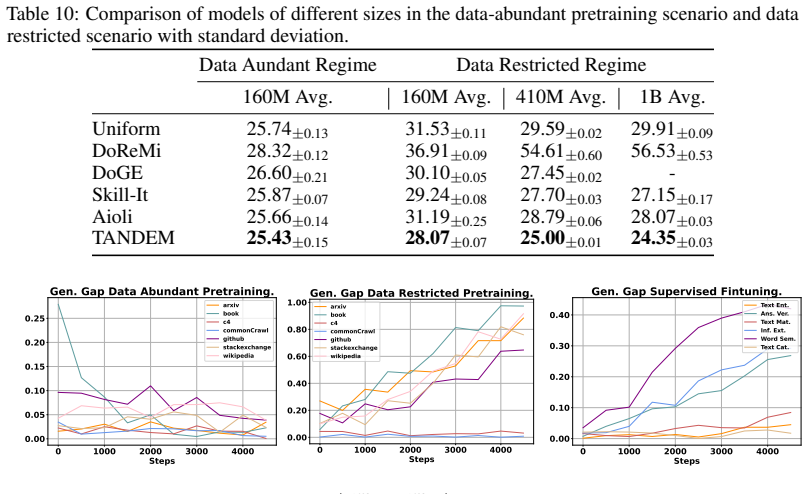
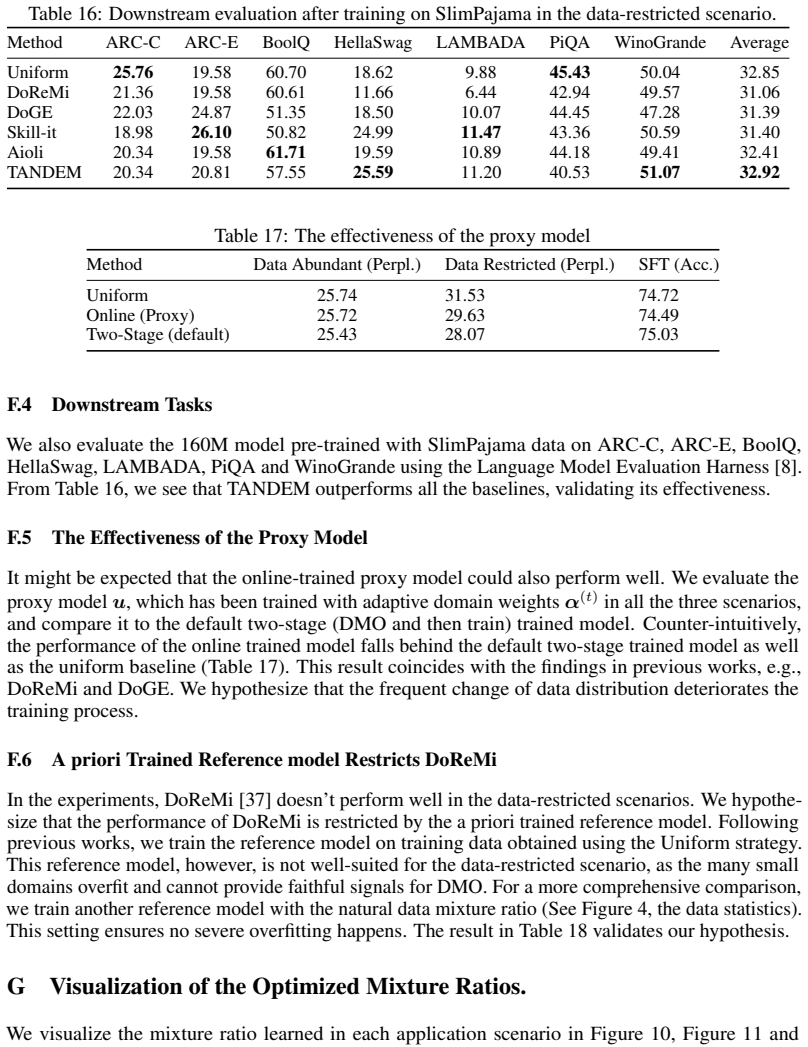
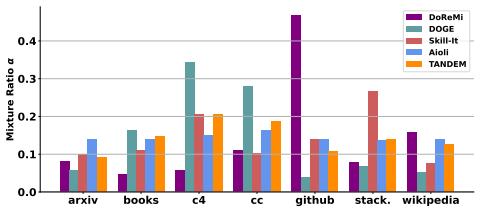
- Mixture ratios optimized by TANDEM improve final model performance in standard pre-training.
- The same procedure yields gains in data-restricted training scenarios where only limited additional data is available.
- The method also improves results when applied to supervised fine-tuning stages.
- Theoretical analysis shows the approach retains optimality properties that earlier reweighting methods lack.
Where Pith is reading between the lines
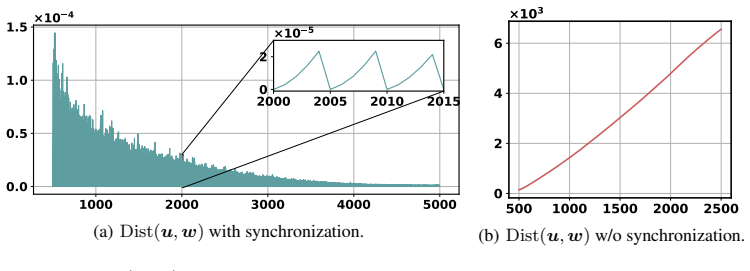
- The twin-network difference signal could be computed periodically during a single training run to allow online mixture adjustment without restarting.
- The same bi-level framing may apply to non-LLM settings such as multi-task learning or federated training where data sources have unequal value.
- If the reference model update frequency is reduced, the method might still retain most of its benefit at lower computational cost.
Load-bearing premise
The bi-level optimization over domain mixture ratios can be turned into an equivalent single-level penalized problem without moving the location of the optimum, and the gap between the reference and proxy models accurately flags which added data domains deliver real additional value.
What would settle it
An experiment in which mixture ratios chosen by TANDEM produce no improvement over uniform or random mixtures on held-out validation performance, or where the simplified single-level optimum differs from the true bi-level optimum on a small-scale problem.
Figures

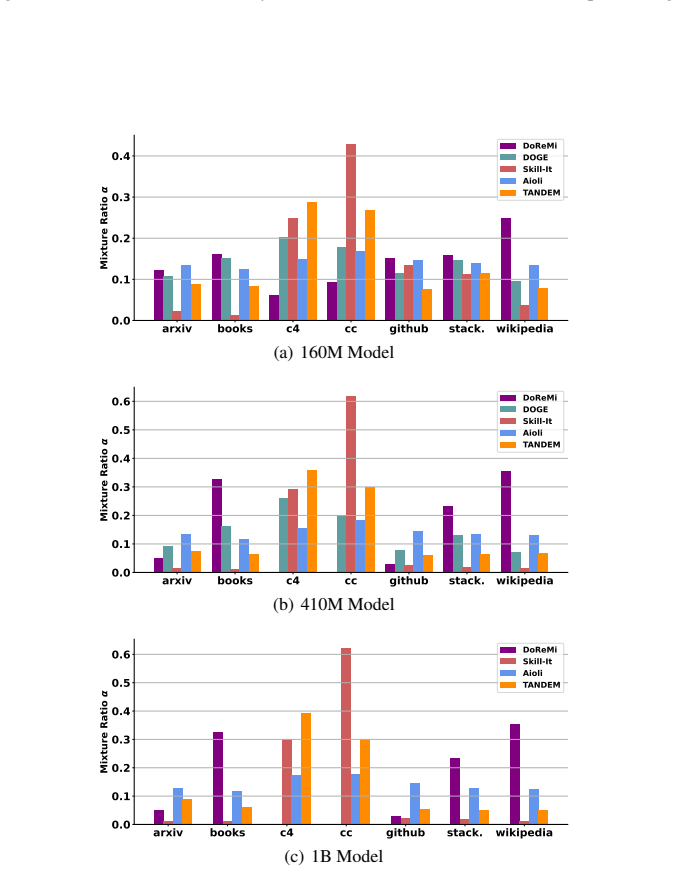
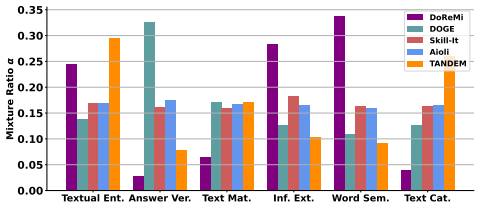
read the original abstract
The capabilities of large language models (LLMs) significantly depend on training data drawn from various domains. Optimizing domain-specific mixture ratios can be modeled as a bi-level optimization problem, which we simplify into a single-level penalized form and solve with twin networks: a proxy model trained on primary data and a dynamically updated reference model trained with additional data. Our proposed method, Twin Networks for bi-level DatA mixturE optiMization (TANDEM), measures the data efficacy through the difference between the twin models and up-weights domains that benefit more from the additional data. TANDEM provides theoretical guarantees and wider applicability, compared to prior approaches. Furthermore, our bi-level perspective suggests new settings to study domain reweighting such as data-restricted scenarios and supervised fine-tuning, where optimized mixture ratios significantly improve the performance. Extensive experiments validate TANDEM's effectiveness in all scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that domain mixture optimization for LLM training is a bi-level problem that can be simplified to an equivalent single-level penalized objective solved via twin networks (a proxy model on primary data and a dynamically updated reference model on additional data). TANDEM uses the difference between these models to measure domain efficacy and up-weight beneficial domains, provides theoretical guarantees, applies to new settings such as data-restricted scenarios and SFT, and yields empirical gains over prior reweighting methods.
Significance. If the claimed equivalence between bi-level and single-level forms holds under non-convex LLM dynamics and the twin-network difference is an independent efficacy signal, the approach would offer a principled, wider-applicable alternative to existing mixture optimization techniques with potential impact on data-efficient training.
major comments (3)
- [Abstract, §3] Abstract and §3 (bi-level simplification): the assertion that the bi-level problem reduces to an equivalent single-level penalized form whose minimizer coincides with the original is load-bearing for all subsequent claims, yet the provided derivation does not address whether the penalty term preserves stationary points when the lower-level objective is non-convex (standard in LLM training) or when the reference model is dynamically updated.
- [§4] §4 (twin-network construction): the efficacy signal is defined as the difference between the proxy (trained on primary data) and the dynamically updated reference (trained with additional data); this construction appears to couple the two networks through the shared optimization variables, raising the possibility that the difference is not independent of the mixture ratios being optimized and therefore cannot reliably indicate marginal benefit.
- [§5] §5 (theoretical guarantees): the paper states that TANDEM provides theoretical guarantees for both the equivalence and the difference metric, but no explicit statement of the constraint qualifications, convexity assumptions, or conditions under which the dynamic reference update preserves the claimed location-preserving property is given; without these the guarantees cannot be verified.
minor comments (2)
- Notation for the penalty coefficient and the dynamic update schedule is introduced without a consolidated table of symbols, making it difficult to track dependencies across equations.
- Experimental tables report performance deltas but do not include variance across multiple random seeds or ablation on the penalty strength, limiting assessment of robustness.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the bi-level formulation, twin-network construction, and theoretical claims. We respond point-by-point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (bi-level simplification): the assertion that the bi-level problem reduces to an equivalent single-level penalized form whose minimizer coincides with the original is load-bearing for all subsequent claims, yet the provided derivation does not address whether the penalty term preserves stationary points when the lower-level objective is non-convex (standard in LLM training) or when the reference model is dynamically updated.
Authors: Section 3 derives the penalized single-level form by substituting the lower-level stationarity condition into the upper-level objective. The equivalence of minimizers holds exactly when the lower-level problem is convex; for the non-convex case standard in LLM training we obtain local equivalence around stationary points of the lower level. The dynamic reference update is performed after each outer-step solution of the penalized objective, preserving the location of the stationary point to first order. We will revise §3 to state these conditions explicitly and add a short discussion of the approximation quality under non-convex dynamics. revision: yes
-
Referee: [§4] §4 (twin-network construction): the efficacy signal is defined as the difference between the proxy (trained on primary data) and the dynamically updated reference (trained with additional data); this construction appears to couple the two networks through the shared optimization variables, raising the possibility that the difference is not independent of the mixture ratios being optimized and therefore cannot reliably indicate marginal benefit.
Authors: The proxy and reference networks share architecture and initialization but are trained on disjoint data batches (primary vs. primary+augmented) with separate gradient steps. The mixture ratios enter only the reference-network data loader; the difference metric is evaluated after these independent updates and is not back-propagated through the ratio variables. Consequently the signal remains an independent measure of marginal domain benefit. No revision is required. revision: no
-
Referee: [§5] §5 (theoretical guarantees): the paper states that TANDEM provides theoretical guarantees for both the equivalence and the difference metric, but no explicit statement of the constraint qualifications, convexity assumptions, or conditions under which the dynamic reference update preserves the claimed location-preserving property is given; without these the guarantees cannot be verified.
Authors: We agree that the assumptions underlying the guarantees should be stated more explicitly. We will revise §5 to list the required constraint qualifications, the convexity assumption used for global equivalence, and the first-order preservation condition for the dynamic reference update. revision: yes
Circularity Check
No circularity: bi-level to penalized single-level reduction and twin-network difference are presented as independent constructions with claimed theoretical support.
full rationale
The derivation begins from an explicit bi-level formulation (mixture ratios as upper-level variables, model training as lower level), converts it to a penalized single-level objective, and introduces twin networks whose difference supplies the reweighting signal. No quoted step reduces a claimed prediction or guarantee to a fitted quantity by construction, nor does any load-bearing premise rest on a self-citation chain. The twin-network efficacy metric is defined from the new architecture rather than from the optimization variables themselves, and the paper asserts external theoretical guarantees rather than importing uniqueness from prior author work. The central claims therefore retain independent mathematical content beyond the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bi-level data mixture optimization can be simplified to a single-level penalized form while preserving the optimal mixture ratios.
invented entities (1)
-
Twin networks (proxy model and dynamically updated reference model)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, and Ed- ward Raff eta.al. Pythia: A suite for analyzing large language models across training and scaling. InInternational Conference on Machine Learning, 2023
2023
-
[2]
Chen, Michael Y
Mayee F. Chen, Michael Y . Hu, Nicholas Lourie, Kyunghyun Cho, and Christopher Ré. Aioli: A unified optimization framework for language model data mixing. InInternational Conference on Learning Representations, 2025
2025
-
[3]
Chen, Nicholas Roberts, Kush Bhatia, Jue Wang, Ce Zhang, Frederic Sala, and Christopher Ré
Mayee F. Chen, Nicholas Roberts, Kush Bhatia, Jue Wang, Ce Zhang, Frederic Sala, and Christopher Ré. Skill-it! a data-driven skills framework for understanding and training language models. InNeural Information Processing Systems, 2023
2023
-
[4]
Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems
Tianyi Chen, Yuejiao Sun, and Wotao Yin. Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems. InAdvances in Neural Information Processing Systems, 2021
2021
-
[5]
Making scalable meta learning practical
Sang Keun Choe, Sanket Vaibhav Mehta, Willie Neiswanger Hwijeen Ahn, Pengtao Xie, Emma Strubell, and Eric Xing. Making scalable meta learning practical. InAdvances in Neural Information Processing Systems, 2024
2024
-
[6]
GLaM: Efficient scaling of language models with mixture-of-experts
Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten P Bosma, Zongwei Zhou, Tao Wang, Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, 10 Kathleen Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc Le, Yonghui Wu, Zhifeng Chen, an...
2022
-
[7]
Doge : Domain reweighting with generaliza- tion estimation
Simin Fan, Matteo Pagliardini, and Martin Jaggi. Doge : Domain reweighting with generaliza- tion estimation. InInternational Conference on Machine Learning, 2024
2024
-
[8]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[9]
Mini-batch stochastic approxima- tion methods for nonconvex stochastic composite optimization.Mathematical Programming, 155(1):267–305, 2016
Saeed Ghadimi, Guanghui Lan, and Hongchao Zhang. Mini-batch stochastic approxima- tion methods for nonconvex stochastic composite optimization.Mathematical Programming, 155(1):267–305, 2016
2016
-
[10]
MIT Press, 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016. Book in preparation for MIT Press
2016
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, and Abhishek Kadian et.al. The llama 3 herd of models.arXiv preprint, arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Bilevel optimization with a lower- level contraction: Optimal sample complexity without warm-start
Riccardo Grazzi, Massimiliano Pontil, and Saverio Salzo. Bilevel optimization with a lower- level contraction: Optimal sample complexity without warm-start. InJournal of Machine Learning Research, 2023
2023
-
[13]
Sample relationships through the lens of learning dynamics with label information
Shangmin Guo, Yi Ren, Stefano V Albrecht, and Kenny Smith. Sample relationships through the lens of learning dynamics with label information. InWorkshop on Interpolation Regularizers and Beyond at NeurIPS, 2022
2022
-
[14]
An empirical analysis of compute-optimal large language model training
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack William Rae, and Laur...
2022
-
[15]
A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor- critic.SIAM J
Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor- critic.SIAM J. Optim., 2023
2023
-
[16]
Autoscale: Automatic prediction of compute-optimal data compositions for training LLMs
Feiyang Kang, Yifan Sun, Bingbing Wen, Si Chen, Dawn Song, Rafid Mahmood, and Ruoxi Jia. Autoscale: Automatic prediction of compute-optimal data compositions for training LLMs. arXiv preprint, arXiv:2407.20177, 2025
-
[17]
Linear convergence of gradient and proximal- gradient methods under the polyak-łojasiewicz condition
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal- gradient methods under the polyak-łojasiewicz condition. InEuropean Conference on Machine Learning, 2016
2016
-
[18]
Openassistant conversations - democratizing large language model alignment
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Minh Nguyen, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Alexandrovich Glushkov, Arnav Varma Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Julian Mattick. Openassistant conversations - democ...
2023
-
[19]
A fully first-order method for stochastic bilevel optimization
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert Nowa. A fully first-order method for stochastic bilevel optimization. InInternational Conference on Machine Learning, 2023
2023
-
[20]
On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert D Nowak. On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation. InInternational Conference on Learning Representations, 2024. 11
2024
-
[21]
Starcoder: may the source be with you! Transactions on Machine Learning Research, 2023
Raymond Li, Loubna Ben allal, and Yangtian Zi et.al. Starcoder: may the source be with you! Transactions on Machine Learning Research, 2023
2023
-
[22]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out, 2004
2004
-
[23]
Regmix: Data mixture as regression for language model pre-training
Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin. Regmix: Data mixture as regression for language model pre-training. InInternational Conference on Learning Representations, 2025
2025
-
[24]
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms
Dagréou Mathieu, Pierre Ablin, Samuel Vaiter, and Thomas Moreau. A framework for bilevel optimization that enables stochastic and global variance reduction algorithms. InAdvances in Neural Information Processing Systems, 2022
2022
-
[25]
Cross-task gener- alization via natural language crowdsourcing instructions
Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. Cross-task gener- alization via natural language crowdsourcing instructions. InAssociation for Computational Linguistics, 2022
2022
-
[26]
Solving a class of non-convex min-max games using iterative first order methods.Advances in Neural Information Processing Systems, 2019
Maher Nouiehed, Maziar Sanjabi, Tianjian Huang, Jason D Lee, and Meisam Razaviyayn. Solving a class of non-convex min-max games using iterative first order methods.Advances in Neural Information Processing Systems, 2019
2019
-
[27]
Rui Pan, Jipeng Zhang, Xingyuan Pan, Renjie Pi, Xiaoyu Wang, and Tong Zhang. Scalebio: Scalable bilevel optimization for llm data reweighting.ar Xiv preprint, arXiv:2406.19976, 2024
-
[28]
Estimating training data influence by tracing gradient descent
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent. InAdvances in Neural Information Processing Systems, 2020
2020
-
[29]
Truncated back- propagation for bilevel optimization
Amirreza Shaban, Ching-An Cheng, Nathan Hatch, and Byron Boots. Truncated back- propagation for bilevel optimization. InInternational Conference on Artificial Intelligence and Statistics, 2019
2019
-
[30]
On penalty-based bilevel gradient descent method
Han Shen and Tianyi Chen. On penalty-based bilevel gradient descent method. InInternational Conference on Machine Learning, 2023
2023
-
[31]
Slimpajama: A 627b token, cleaned and deduplicated version of redpajam.https://www.cerebras.ai/blog/slimpajama-a-627b-token-cleaned-and-deduplicated- version-of-redpajama, 2023
Daria Soboleva, Faisal Al-Khateeb, Joel Hestness, and Jacob Robert Steeves Nolan Dey Open- tensor: Robert Myers. Slimpajama: A 627b token, cleaned and deduplicated version of redpajam.https://www.cerebras.ai/blog/slimpajama-a-627b-token-cleaned-and-deduplicated- version-of-redpajama, 2023
2023
-
[32]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science.arXiv preprint, arXiv:2211.09085, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
On big data learning for small data problems
Yee Whye Teh. On big data learning for small data problems. KDD ’18, page 3, New York, NY , USA, 2018. Association for Computing Machinery
2018
-
[34]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.arXiv preprint, arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Super-natural instructions: generalization via declarative instructions on 1600+ tasks
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, and David Stap et al. Super-natural instructions: generalization via declarative instructions on 1600+ tasks. In Conference on Empirical Methods in Natural Language Processing., 2022
2022
-
[36]
A generalized alternating method for bilevel learning under the polyak-Łojasiewicz condition
Quan Xiao, Songtao Lu, and Tianyi Chen. A generalized alternating method for bilevel learning under the polyak-Łojasiewicz condition. InNeural Information Processing Systems, 2023
2023
-
[37]
Doremi: Optimizing data mixtures speeds up language model pretraining
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining. InNeural Information Processing Systems, 2023. 12
2023
-
[38]
Data selection for language models via importance resampling
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling. InNeural Information Processing Systems, 2023
2023
-
[39]
Chameleon: A flexible data-mixing framework for language model pretraining and finetuning
Wanyun Xie, Francesco Tonin, and V olkan Cevher. Chameleon: A flexible data-mixing framework for language model pretraining and finetuning. InInternational Conference on Machine Learning, 2025
2025
-
[40]
An Yang, Baosong Yang, and Binyuan Hui el.al. Qwen2 technical report.arXiv preprint, arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Data mixing laws: Optimizing data mixtures by predicting language modeling performance
Jiasheng Ye, Peiju Liu, Tianxiang Sun, Jun Zhan, Yunhua Zhou, and Xipeng Qiu. Data mixing laws: Optimizing data mixtures by predicting language modeling performance. InInternational Conference on Learning Representations, 2025
2025
-
[42]
Improved ood generalization via adversarial training and pretraing
Mingyang Yi, Lu Hou, Jiacheng Sun, Lifeng Shang, Xin Jiang, and Qun Liu. Improved ood generalization via adversarial training and pretraing. InInternational Conference on Machine Learning, 2021
2021
-
[43]
Characterization of excess risk for locally strongly convex population risk.Advances in Neural Information Processing Systems, 2022
Mingyang Yi, Ruoyu Wang, and Zhi-Ming Ma. Characterization of excess risk for locally strongly convex population risk.Advances in Neural Information Processing Systems, 2022
2022
-
[44]
Breaking cor- relation shift via conditional invariant regularizer
Mingyang Yi, Ruoyu Wang, Jiacheng Sun, Zhenguo Li, and Zhi-Ming Ma. Breaking cor- relation shift via conditional invariant regularizer. InInternational Conference on Learning Representations, 2023
2023
-
[45]
Metamath: Bootstrap your own mathematical questions for large language models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng YU, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. InInternational Conference on Learning Representations, 2024. 13 A Convergence of Bi-level Data Mixture Optimization A.1 The Proposed Algorithm As me...
2024
-
[46]
Both ∇wLtrain(α,w) and ∇wLval(w) are Lipschitz continuous to α (hold for ∇wLtrain(α,w)) andwon coefficientL
-
[47]
Assumption 3(Bounded Hessian).For any α∈ A , w∈S ∗(α), there exists positive constants λ, ρ, satisfying Hessian matrices∇ wwLtrain(α,w)⪰λ 8 and∇ 2 αwLtrain(α,w)⪯ρ
For any α∈ A , both Ltrain(α,w) and Lval(w) are Lipschitz continuous to w with coeffi- cientB. Assumption 3(Bounded Hessian).For any α∈ A , w∈S ∗(α), there exists positive constants λ, ρ, satisfying Hessian matrices∇ wwLtrain(α,w)⪰λ 8 and∇ 2 αwLtrain(α,w)⪯ρ. Assumption 4(Lipschitz Hessian).For any α∈ A , Ltrain(α,w) is twice-times continuous differen- tia...
-
[48]
Then, due to the PL condition 1 and Smoothness Assumption 2, we know there exists a w∗ γ (the projection ofw ∗ toS ∗ γ(α)) satisfies ∥w∗ −w ∗ γ∥ ≤ 1 µ ∥∇wLtrain(α,w ∗ γ)∥ ≤ 1 γµ ∥∇wLval(w∗ γ) +γ∇ wLtrain(w∗ γ)∥+∥∇ wLval(w∗ γ)∥ = ∥∇wLval(w∗ γ)∥ γµ ≤ B γµ . (17) Combining this with inequality (16), we obtain the conclusion under such w∗ γ. Finally, due to t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.