Bridging Short Videos and Live Streams: Reasoning-Guided Multimodal LLMs for Cross-Domain Representation Learning
Pith reviewed 2026-06-28 04:37 UTC · model grok-4.3
The pith
Reasoning from multimodal LLMs can be distilled to create transferable representations that bridge short video and live stream recommendation domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
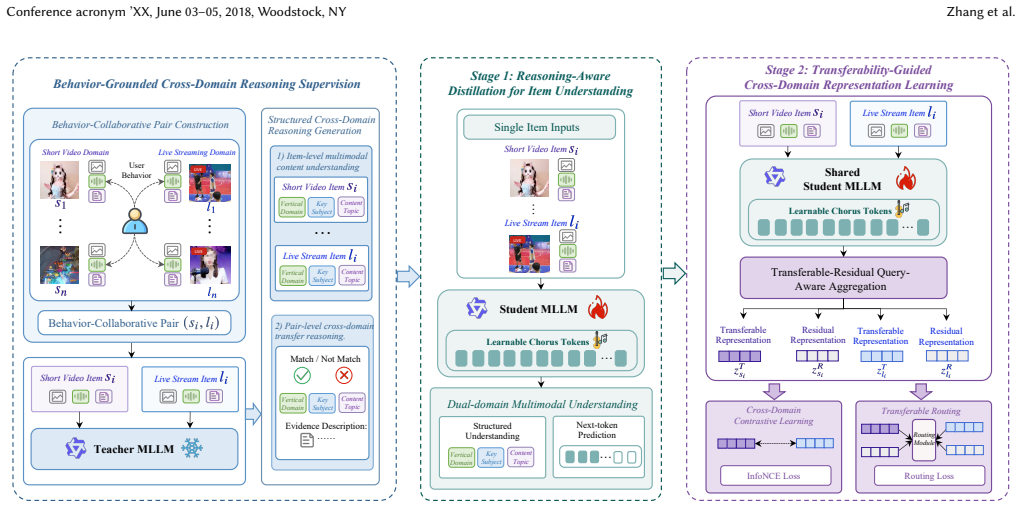
RGCD-Rep performs reasoning-aware distillation from a teacher MLLM into a student MLLM, then uses the student to supervise transferability-guided decomposition of item representations into transferable and domain-residual parts, enabling effective cross-domain recommendation from short videos to live streams with low deployment cost.
What carries the argument
Transferability-guided decomposition of item representations into transferable and domain-residual components, supervised by distilled MLLM cross-domain reasoning.
If this is right
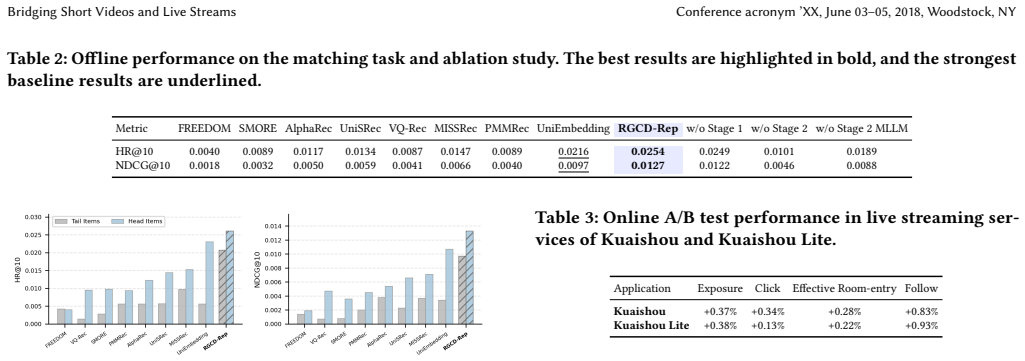
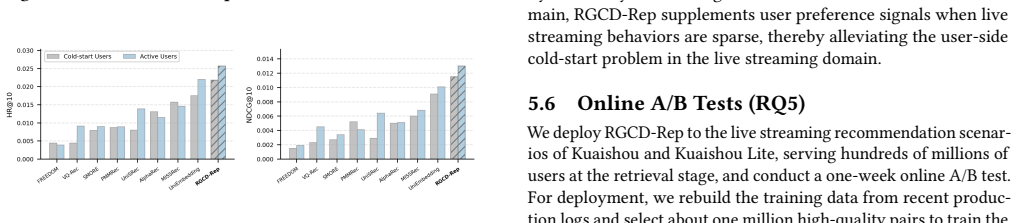
- Offline experiments demonstrate superiority over prior cross-domain methods.
- A/B tests produce significant gains on core business metrics after deployment.
- The framework runs at production scale serving over 400 million users daily.
Where Pith is reading between the lines
- The same distillation-plus-decomposition pattern could reduce cold-start costs when moving data from any rich domain to a sparse one.
- Pre-computing the decomposed representations offline may generalize to other retrieval tasks that already store item embeddings.
- Measuring how much of the final lift comes from the reasoning step versus the decomposition step would clarify which part drives the transfer.
Load-bearing premise
Behavioral collaboration signals between short videos and live streams are sufficient to guide decomposition into transferable and domain-residual representations while the distilled student MLLM retains enough reasoning to improve retrieval.
What would settle it
An A/B test in which the student MLLM is replaced by a non-reasoning baseline and live-stream retrieval metrics show no lift would falsify the claim that the distilled reasoning is required for the observed gains.
Figures
read the original abstract
As live streaming services grow, many platforms offer short videos and live streams to meet diverse needs. Short videos carry substantial traffic and rich behavior signals, whereas live streaming is a core conversion scenario with sparse behavior data, making cold start severe. Transferring user interests from short videos to live streaming recommendation can alleviate these issues. Meanwhile, short videos and live streams are complex multimodal items, and integrating multimodal signals improves recommendation performance. Although Multimodal Large Language Models (MLLMs) show strong multimodal understanding and reasoning, their application to cross-domain recommendation remains underexplored. To this end, we propose Reasoning-Guided Cross-Domain Representation Learning (RGCD-Rep), a reasoning-guided framework for cross-domain recommendation from short videos to live streams. RGCD-Rep introduces MLLM reasoning resource-efficiently and learns transferable item representations guided by behavioral collaboration via two-stage training. First, reasoning-aware distillation lets a frozen teacher MLLM generate structured cross-domain reasoning knowledge and distills it into a lightweight student MLLM. Second, transferability-guided cross-domain representation learning decomposes item representations into transferable and domain residual representations. The resulting representations are computed offline and integrated into downstream retrieval tasks, enabling low-cost industrial deployment. Extensive offline experiments demonstrate RGCD-Rep's superiority. After deployment in Kuaishou's live streaming recommendation system, A/B tests show significant gains across multiple core business metrics, confirming its effectiveness and practicality in real industrial scenarios. RGCD-Rep is fully deployed and serves over 400 million users daily.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reasoning-Guided Cross-Domain Representation Learning (RGCD-Rep) for transferring user interests from short videos to live streaming recommendation using Multimodal Large Language Models (MLLMs). It proposes a two-stage process: first, distilling reasoning knowledge from a frozen teacher MLLM to a lightweight student MLLM, and second, decomposing item representations into transferable and domain-residual parts guided by behavioral collaboration signals. The representations are used in downstream retrieval, with claims of superiority in offline experiments and significant improvements in A/B tests on Kuaishou's live streaming system, where it serves over 400 million users daily.
Significance. If the reported offline and online results hold, this work would demonstrate a practical way to leverage MLLM reasoning for cross-domain recommendation in industrial settings with sparse data in one domain, potentially improving cold-start performance in live streaming by transferring from rich short video data. The deployment at scale adds to its relevance for real-world applications.
major comments (2)
- [Abstract] Abstract: the abstract asserts superiority in offline experiments and significant A/B gains across core business metrics yet provides no quantitative results, error bars, baseline details, or description of how domain residual representations are learned or validated; the central claim therefore rests on uninspectable experimental outcomes.
- [Method] Method section (two-stage training): the description of reasoning-aware distillation and transferability-guided decomposition relies on external MLLM outputs and observed behavioral collaboration without any equations, pseudocode, or ablation metrics showing that the signals suffice to isolate transferable representations without leakage or loss of reasoning fidelity; this is load-bearing for the claim that the student MLLM preserves cross-domain reasoning.
minor comments (1)
- [Abstract] Abstract: the acronym RGCD-Rep is used without first spelling out 'Reasoning-Guided Cross-Domain Representation Learning'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts superiority in offline experiments and significant A/B gains across core business metrics yet provides no quantitative results, error bars, baseline details, or description of how domain residual representations are learned or validated; the central claim therefore rests on uninspectable experimental outcomes.
Authors: We agree the abstract would benefit from greater transparency. In revision we will insert concise quantitative highlights (e.g., relative lifts on key offline metrics versus strong baselines and the observed A/B gains on CTR/CVR) while preserving length limits. revision: yes
-
Referee: [Method] Method section (two-stage training): the description of reasoning-aware distillation and transferability-guided decomposition relies on external MLLM outputs and observed behavioral collaboration without any equations, pseudocode, or ablation metrics showing that the signals suffice to isolate transferable representations without leakage or loss of reasoning fidelity; this is load-bearing for the claim that the student MLLM preserves cross-domain reasoning.
Authors: The current manuscript describes the two-stage process at a high level. To address the concern we will add (i) explicit loss equations for reasoning-aware distillation and transferability-guided decomposition, (ii) pseudocode for the overall algorithm, and (iii) targeted ablation results that quantify how behavioral collaboration signals separate transferable from domain-residual components without degrading reasoning fidelity. revision: yes
Circularity Check
No circularity: framework relies on external MLLM distillation and observed behavioral signals with independent A/B validation
full rationale
The paper describes a two-stage process (reasoning-aware distillation from a frozen teacher MLLM followed by transferability-guided decomposition) that takes external multimodal reasoning outputs and cross-domain behavioral collaboration signals as inputs. The claimed gains are tied to offline experiments and real-world A/B tests on Kuaishou's system rather than any fitted parameter or self-referential definition. No equations, self-citations as load-bearing premises, or renamings of known results appear in the provided text. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
transferable and domain residual representations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. 2024. The Revolution of Multimodal Large Language Models: A Survey. InFindings of the Association for Computational Linguistics: ACL 2024. doi:10.18653/v1/2024. findings-acl.807
-
[2]
Jiangxia Cao, Xin Cong, Jiawei Sheng, Tingwen Liu, and Bin Wang. 2022. Con- trastive Cross-Domain Sequential Recommendation. InProceedings of the 31st ACM International Conference on Information and Knowledge Management (CIKM ’22). ACM, 138–147. doi:10.1145/3511808.3557262
-
[3]
Jiangxia Cao, Ruochen Yang, Xiang Chen, Changxin Lao, Yueyang Liu, Yusheng Huang, Yuanhao Tian, Xiangyu Wu, Shuang Yang, Zhaojie Liu, and Guorui Zhou. 2026. Foresight Prediction Enhanced Live-Streaming Recommendation. In Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining (WSDM ’26). ACM. doi:10.1145/3773966.3779372
-
[4]
Jingyuan Chen, Hanwang Zhang, Xiangnan He, Liqiang Nie, Wei Liu, and Tat- Seng Chua. 2017. Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention. InProceedings of the 40th Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’17). Association for Computing Machiner...
-
[5]
Xu Chen, Hanxiong Chen, Hongteng Xu, Yongfeng Zhang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2019. Personalized Fashion Recommendation with Visual Explanations based on Multimodal Attention Network: Towards Visually Explainable Recommendation. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval...
arXiv 2019
-
[6]
Boqi Dai, Zhaocheng Du, Jieming Zhu, Jintao Xu, Deqing Zou, Quanyu Dai, Zhenhua Dong, Rui Zhang, and Hai-Tao Zheng. 2024. UniEmbedding: Learn- ing Universal Multi-Modal Multi-Domain Item Embeddings via User-View Contrastive Learning. InProceedings of the 33rd ACM International Confer- ence on Information and Knowledge Management (CIKM ’24). ACM, 4446–4453...
-
[7]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi. 2023. In- structBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. InAdvances in Neural Information Processing Systems, Vol. 36
2023
-
[8]
Jiaxin Deng, Shiyao Wang, Yuchen Wang, Jiansong Qi, Liqin Zhao, Guorui Zhou, and Gaofeng Meng. 2024. MMBee: Live Streaming Gift-Sending Recommenda- tions via Multi-Modal Fusion and Behaviour Expansion. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24). Association for Computing Machinery, New York, NY, USA, 4...
-
[9]
Ke Guo, Changle Qu, Xiao Zhang, Liqin Zhao, Shijun Wang, Yanan Niu, and Jun Xu. 2026. Room Matters: Dynamic Room-level Collaboration Information Model- ing for Live Streaming Recommendation. InProceedings of The Web Conference
2026
-
[11]
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. 2023. Learn- ing Vector-Quantized Item Representation for Transferable Sequential Recom- menders. InProceedings of the ACM Web Conference 2023 (WWW ’23). Association for Computing Machinery, New York, NY, USA, 1162–1171. doi:10.1145/3543507. 3583434
-
[12]
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022. Towards Universal Sequence Representation Learning for Recom- mender Systems. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22). Association for Computing Machinery, New York, NY, USA, 585–593. doi:10.1145/3534678.3539381
-
[13]
Guangneng Hu, Yu Zhang, and Qiang Yang. 2018. CoNet: Collaborative Cross Networks for Cross-Domain Recommendation. InProceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM 2018). ACM, 667–676. doi:10.1145/3269206.3271684
-
[14]
Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. 2024. Enhancing Sequential Recommendation via LLM-based Semantic Embedding Learning. InProceedings of The Web Conference 2024 (WWW ’24). ACM, 103–111. doi:10.1145/3589335.3648307
-
[15]
Hanyu Li, Weizhi Ma, Peijie Sun, Jiayu Li, Cunxiang Yin, Yancheng He, Guoqiang Xu, Min Zhang, and Shaoping Ma. 2024. Aiming at the Target: Filter Collabora- tive Information for Cross-Domain Recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). ACM, 2081–2090. doi:10....
-
[16]
Hourun Li, Yifan Wang, Zhiping Xiao, Jia Yang, Changling Zhou, Ming Zhang, and Wei Ju. 2025. DisCo: graph-based disentangled contrastive learning for cold-start cross-domain recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12049–12057
2025
-
[17]
Xiaodong Li, Ruochen Yang, Shuang Wen, Shen Wang, Yueyang Liu, Guoquan Wang, Weisong Hu, Qiang Luo, Jiawei Sheng, Tingwen Liu, Jiangxia Cao, Shuang Yang, and Zhaojie Liu. 2025. FARM: Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation.CoRRabs/2502.09375 (2025). doi:10.48550/ arXiv.2502.09375 arXiv preprint
arXiv 2025
-
[18]
Youhua Li, Hanwen Du, Yongxin Ni, Pengpeng Zhao, Qi Guo, Fajie Yuan, and Xiaofang Zhou. 2024. Multi-Modality is All You Need for Transferable Recom- mender Systems. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 5008–5021. doi:10.1109/ICDE60146.2024.00380
-
[19]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruc- tion Tuning. InAdvances in Neural Information Processing Systems, Vol. 36
2023
-
[20]
Lihao Liu, Yan Wang, Biao Yang, Da Li, Jiangxia Cao, Yuxiao Luo, Xiang Chen, Xiangyu Wu, Wei Yuan, Fan Yang, Guiguang Ding, Tingting Gao, and Guorui Zhou. 2026. CREM: Compression-Driven Representation Enhancement for Mul- timodal Retrieval and Comprehension.arXiv preprint arXiv:2602.19091(2026). https://arxiv.org/abs/2602.19091 arXiv:2602.19091
arXiv 2026
-
[21]
Meng Liu, Jianjun Li, Guohui Li, and Peng Pan. 2020. Cross Domain Recommen- dation via Bi-directional Transfer Graph Collaborative Filtering Networks. In Proceedings of the 29th ACM International Conference on Information and Knowl- edge Management (CIKM ’20). ACM, 885–894. doi:10.1145/3340531.3412012
-
[22]
Haokai Ma, Ruobing Xie, Lei Meng, Xin Chen, Xu Zhang, Leyu Lin, and Jie Zhou. 2024. Triple Sequence Learning for Cross-domain Recommendation.ACM Transactions on Information Systems42, 4, Article 91 (2024), 91:1–91:29 pages. doi:10.1145/3638351
-
[23]
Tong Man, Huawei Shen, Xiaolong Jin, and Xueqi Cheng. 2017. Cross-Domain Recommendation: An Embedding and Mapping Approach. InProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17). IJCAI Organization, 2464–2470. doi:10.24963/ijcai.2017/343
-
[24]
Rongqing Kenneth Ong and Andy W. H. Khong. 2025. Spectrum-based Modality Representation Fusion Graph Convolutional Network for Multimodal Recom- mendation. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining (WSDM ’25). Association for Computing Machinery, New York, NY, USA, 773–781. doi:10.1145/3701551.3703561
-
[25]
Chung Park, Taesan Kim, Taekyoon Choi, Junui Hong, Yelim Yu, Mincheol Cho, Kyunam Lee, Sungil Ryu, Hyungjun Yoon, Minsung Choi, and Jaegul Choo
-
[26]
InProceedings of the 32nd ACM International Conference on Information and Knowledge Management
Cracking the Code of Negative Transfer: A Cooperative Game Theoretic Approach for Cross-Domain Sequential Recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 2024–2033. doi:10.1145/3583780.3614828
-
[27]
Changle Qu, Liqin Zhao, Yanan Niu, Xiao Zhang, and Jun Xu. 2025. Bridging Short Videos and Streamers with Multi-Graph Contrastive Learning for Live Streaming Recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). ACM, 2059–2069. doi:10.1145/3726302.3729914
-
[28]
Qwen Team. 2026. Qwen3.6-35B-A3B: Agentic Coding Power, Now Open to All. https://qwen.ai/blog?id=qwen3.6-35b-a3b
2026
-
[29]
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, and Tat-Seng Chua
-
[30]
InThe Thirteenth International Conference on Learning Representations
Language Representations Can be What Recommenders Need: Findings and Potentials. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=eIJfOIMN9z
-
[31]
Jinpeng Wang, Ziyun Zeng, Yunxiao Wang, Yuting Wang, Xingyu Lu, Tianxiang Li, Jun Yuan, Rui Zhang, Hai-Tao Zheng, and Shu-Tao Xia. 2023. MISSRec: Pre- training and Transferring Multi-modal Interest-aware Sequence Representation for Recommendation. InProceedings of the 31st ACM International Conference on Multimedia (MM ’23). Association for Computing Mach...
-
[32]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191(2024)
Pith/arXiv arXiv 2024
-
[33]
Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, and Tat-Seng Chua. 2020. GRCN: Graph-Refined Convolutional Network for Multimedia Recommendation with Implicit Feedback. InProceedings of the 28th ACM International Conference on Multimedia (MM ’20). Association for Computing Machinery, New York, NY, USA, 3541–3549. doi:10.1145/3394171.3413556
-
[34]
Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. 2019. MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video. InProceedings of the 27th ACM International Conference on Multimedia (MM ’19). Association for Computing Machinery, New York, NY, USA, 1437–1445. doi:10.1145/3343031.3351034
-
[35]
Ruobing Xie, Qi Liu, Liangdong Wang, Shukai Liu, Bo Zhang, and Leyu Lin. 2022. Contrastive Cross-Domain Recommendation in Matching. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22). ACM, 4226–4236. doi:10.1145/3534678.3539125
-
[36]
Wei Yang, Jie Yang, and Yuan Liu. 2023. Multimodal Optimal Transport Knowl- edge Distillation for Cross-domain Recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM ’23). ACM, 2959–2968. doi:10.1145/3583780.3614983 Bridging Short Videos and Live Streams Conference acronym ’XX, June 03–05, 2018...
-
[37]
Yuyang Ye, Zhi Zheng, Yishan Shen, Tianshu Wang, Hengruo Zhang, Peijun Zhu, Runlong Yu, Kai Zhang, and Hui Xiong. 2025. Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 13069–13077. doi:10.1609/ aaai.v39i12.33426
2025
-
[38]
Chuang Zhao, Hongke Zhao, Ming He, Jian Zhang, and Jianping Fan. 2023. Cross-domain recommendation via user interest alignment. InProceedings of The Web Conference 2023 (WWW ’23). ACM, 887–896. doi:10.1145/3543507.3583263
-
[39]
Xin Zhou and Zhiqi Shen. 2023. A Tale of Two Graphs: Freezing and Denoising Graph Structures for Multimodal Recommendation. InProceedings of the 31st ACM International Conference on Multimedia (MM ’23). Association for Computing Machinery, New York, NY, USA, 935–943. doi:10.1145/3581783.3611943
-
[40]
Yongchun Zhu, Kaikai Ge, Fuzhen Zhuang, Ruobing Xie, Dongbo Xi, Xu Zhang, Leyu Lin, and Qing He. 2022. Personalized Transfer of User Preferences for Cross-domain Recommendation. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 1507–1515. doi:10.1145/3488560. 3498388
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.