Stepwise Reasoning Enhancement for LLMs via External Subgraph Generation
Pith reviewed 2026-06-28 06:48 UTC · model grok-4.3
The pith
SGR improves LLM multi-step reasoning by retrieving compact subgraphs from knowledge graphs via schema-guided queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SGR establishes that dynamically generating query-relevant subgraphs from a knowledge graph, guided by an extracted schema, supplies explicit relational evidence that lets an LLM perform more accurate, consistent, and interpretable multi-step reasoning than it achieves through prompting alone or with static knowledge integration.
What carries the argument
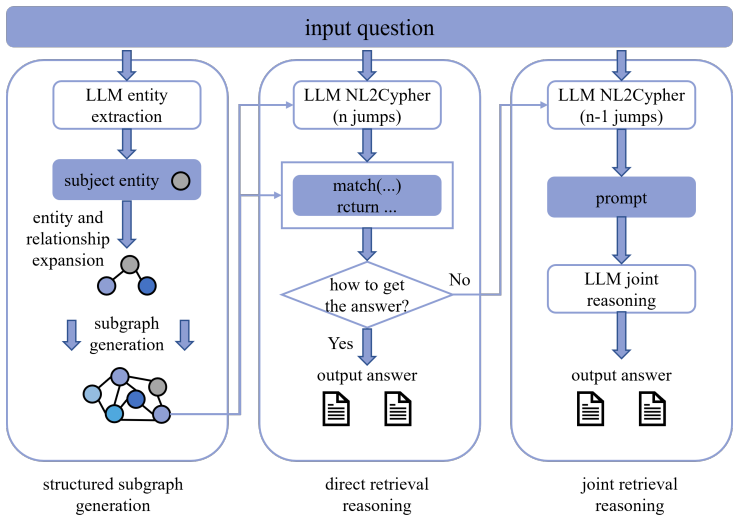
Schema-guided subgraph retrieval: a process that turns a question into a structured schema of entities, relations, and constraints, then queries a knowledge graph (via Neo4j) to return a compact, relevant subgraph used as explicit evidence during stepwise LLM reasoning.
If this is right
- LLM reasoning on multi-hop questions becomes more robust when the model is forced to consult an explicit external graph rather than relying solely on internalized patterns.
- Combining direct graph queries (Cypher) with LLM-generated paths and then aggregating by model confidence plus graph consistency raises answer reliability.
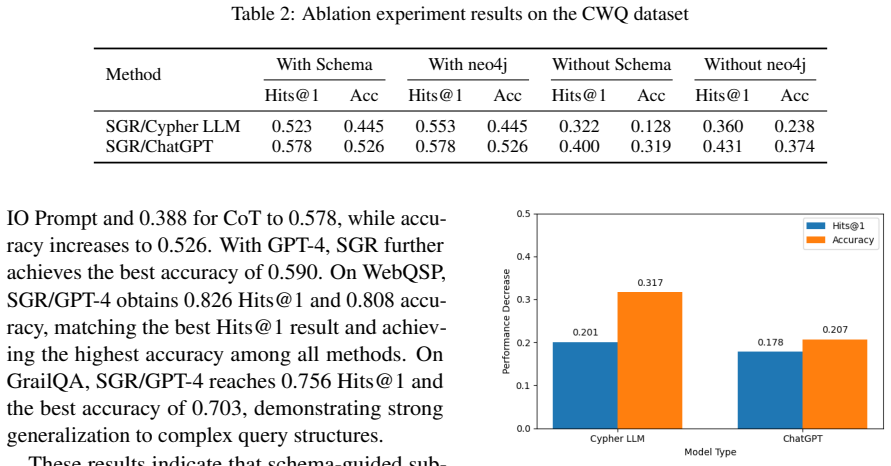
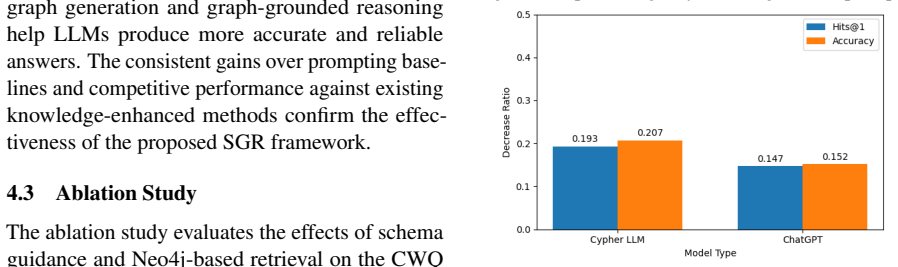
- Removing either the schema construction step or the Neo4j retrieval step measurably reduces performance, showing both components are load-bearing.
- The same subgraph-generation approach can be applied to other structured knowledge sources beyond the tested benchmarks.
Where Pith is reading between the lines
- If subgraph retrieval can be made faster and cheaper, the method could extend to real-time question answering on very large graphs where full-graph access is impractical.
- The framework's reliance on an external store suggests a route to updating LLM knowledge without retraining, by swapping in new subgraphs when the underlying knowledge graph changes.
- Because the subgraphs are human-readable, the approach may offer a practical path toward verifiable reasoning traces that can be inspected or edited by users.
Load-bearing premise
Schema-guided querying will consistently return compact, relevant subgraphs that contain accurate relational evidence and introduce no misleading noise or retrieval errors.
What would settle it
A controlled test in which SGR is run on the same benchmarks but with the retrieved subgraphs deliberately replaced by random or noisy subgraphs of similar size; if accuracy and Hits@1 drop to or below the level of standard prompting, the claim that the subgraphs provide useful guidance is falsified.
Figures
read the original abstract
Large language models have shown strong performance in natural language generation and downstream reasoning tasks, but they still struggle with logical consistency, factual grounding, and interpretability in complex multi-step reasoning. To address these limitations, this paper proposes SGR, a stepwise reasoning enhancement framework that integrates large language models with external knowledge graphs through query-relevant subgraph generation. Given an input question, SGR first extracts key entities, relations, and constraints to construct a structured schema, then retrieves compact subgraphs from a knowledge graph using schema-guided querying. The generated subgraphs provide explicit relational evidence that guides the language model through step-by-step reasoning. In addition, SGR combines direct Cypher-based reasoning with collaborative reasoning integration, allowing candidate answers from multiple reasoning paths to be validated and aggregated according to both model confidence and graph consistency. Experiments on benchmark datasets including CWQ, WebQSP, GrailQA, and KQA Pro demonstrate that SGR improves reasoning accuracy and Hits@1 performance over standard prompting and several knowledge-enhanced baselines. Ablation studies further show that schema guidance and Neo4j-based retrieval are both crucial to the effectiveness of the framework. These results indicate that dynamically generated external subgraphs can improve the accuracy, robustness, and interpretability of LLM-based reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SGR, a stepwise reasoning enhancement framework for LLMs that extracts entities, relations, and constraints from an input question to build a schema, retrieves compact subgraphs from a knowledge graph via schema-guided (Neo4j/Cypher) querying, and integrates direct Cypher reasoning with collaborative reasoning paths to aggregate answers by model confidence and graph consistency. Experiments on CWQ, WebQSP, GrailQA, and KQA Pro are stated to show gains in reasoning accuracy and Hits@1 over standard prompting and knowledge-enhanced baselines, with ablations indicating that schema guidance and Neo4j retrieval are crucial.
Significance. If the empirical claims hold with supporting retrieval-quality evidence, the work would demonstrate a concrete mechanism for dynamically grounding LLM multi-step reasoning in external structured knowledge, potentially improving factual consistency and interpretability without requiring full KG traversal.
major comments (2)
- [Abstract and Experiments] Abstract / Experiments section: The central claim of improved accuracy and Hits@1 on CWQ, WebQSP, GrailQA, and KQA Pro is asserted without any reported numerical results, baseline values, error bars, ablation numbers, or statistical details. This is load-bearing because the contribution rests entirely on these unquantified gains.
- [Experiments] Experiments section: No quantitative retrieval metrics (precision/recall of extracted entities/relations, subgraph coverage of gold paths, or error rates on multi-hop questions) are provided for the schema-guided querying step on any of the four benchmarks. This directly affects the weakest assumption that the retrieved subgraphs supply accurate relational evidence without noise or omissions that could mislead the LLM.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested quantitative details.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract / Experiments section: The central claim of improved accuracy and Hits@1 on CWQ, WebQSP, GrailQA, and KQA Pro is asserted without any reported numerical results, baseline values, error bars, ablation numbers, or statistical details. This is load-bearing because the contribution rests entirely on these unquantified gains.
Authors: We agree that the submitted manuscript does not include specific numerical results, baseline comparisons, error bars, or statistical details in the abstract or experiments section. The experiments were performed and yielded the claimed improvements, but these values were omitted from the text. In the revised version we will add full result tables reporting accuracy and Hits@1 for SGR and all baselines across the four datasets, together with the ablation numbers and any available variance or significance measures. revision: yes
-
Referee: [Experiments] Experiments section: No quantitative retrieval metrics (precision/recall of extracted entities/relations, subgraph coverage of gold paths, or error rates on multi-hop questions) are provided for the schema-guided querying step on any of the four benchmarks. This directly affects the weakest assumption that the retrieved subgraphs supply accurate relational evidence without noise or omissions that could mislead the LLM.
Authors: We acknowledge that the current manuscript provides no quantitative retrieval metrics for the schema-guided step. We will add precision and recall figures for entity/relation extraction, subgraph coverage relative to gold paths (where annotations exist), and error rates on multi-hop questions for all four benchmarks. These metrics will be computed from the existing experimental logs and included in the revised experiments section to directly support the quality of the retrieved subgraphs. revision: yes
Circularity Check
No circularity: empirical framework with external benchmarks
full rationale
The paper presents an applied engineering framework (schema extraction → Neo4j subgraph retrieval → Cypher + collaborative LLM reasoning) evaluated on standard public benchmarks (CWQ, WebQSP, GrailQA, KQA Pro). No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the abstract or method description. Claims rest on reported accuracy/Hits@1 lifts and ablations rather than any derivation that reduces to its own inputs by construction. This is the normal non-circular outcome for an empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[3]
arXiv preprint arXiv:2004.03685 , year=
Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness? , author=. arXiv preprint arXiv:2004.03685 , year=
-
[4]
IEEE transactions on neural networks and learning systems , volume=
A survey on knowledge graphs: Representation, acquisition, and applications , author=. IEEE transactions on neural networks and learning systems , volume=. 2021 , publisher=
2021
-
[5]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[6]
Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Information extraction over structured data: Question answering with freebase , author=. Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[7]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the IEEE , volume=
A review of relational machine learning for knowledge graphs , author=. Proceedings of the IEEE , volume=. 2015 , publisher=
2015
-
[9]
ERNIE: Enhanced Representation through Knowledge Integration
Ernie: Enhanced representation through knowledge integration , author=. arXiv preprint arXiv:1904.09223 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[10]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey of knowledge enhanced pre-trained language models , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2023 , publisher=
2023
-
[11]
arXiv preprint arXiv:2305.09645 , year=
Structgpt: A general framework for large language model to reason over structured data , author=. arXiv preprint arXiv:2305.09645 , year=
-
[12]
arXiv preprint arXiv:2010.10439 , year=
Open question answering over tables and text , author=. arXiv preprint arXiv:2010.10439 , year=
-
[13]
Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
Leveraging passage retrieval with generative models for open domain question answering , author=. Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
-
[14]
arXiv preprint arXiv:2201.08860 , year=
Greaselm: Graph reasoning enhanced language models for question answering , author=. arXiv preprint arXiv:2201.08860 , year=
-
[15]
IEEE Transactions on Knowledge and Data Engineering , volume=
Unifying large language models and knowledge graphs: A roadmap , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2024 , publisher=
2024
-
[16]
arXiv preprint arXiv:2306.04136 , year=
Knowledge-augmented language model prompting for zero-shot knowledge graph question answering , author=. arXiv preprint arXiv:2306.04136 , year=
-
[17]
International conference on machine learning , pages=
Retrieval augmented language model pre-training , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[18]
Multi-step Retriever-Reader Interaction for Scalable Open-domain Question Answering
Multi-step retriever-reader interaction for scalable open-domain question answering , author=. arXiv preprint arXiv:1905.05733 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[19]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
KILT: a benchmark for knowledge intensive language tasks , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2021
-
[20]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Harnessing the power of large language models for natural language to first-order logic translation , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[22]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Large Language Models Can Learn Temporal Reasoning , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Can LLMs Reason in the Wild with Programs? , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deliberate reasoning in language models as structure-aware planning with an accurate world model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
TILP: Differentiable Learning of Temporal Logical Rules on Knowledge Graphs , author=
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Teilp: Time prediction over knowledge graphs via logical reasoning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.