SANE Schema-aware Natural-language Evaluation of Biological Data
Pith reviewed 2026-06-28 06:32 UTC · model grok-4.3
The pith
Few-shot LLMs generate accurate SQL for biological microscopy data using schema-aware prompting and guardrails without any training or fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
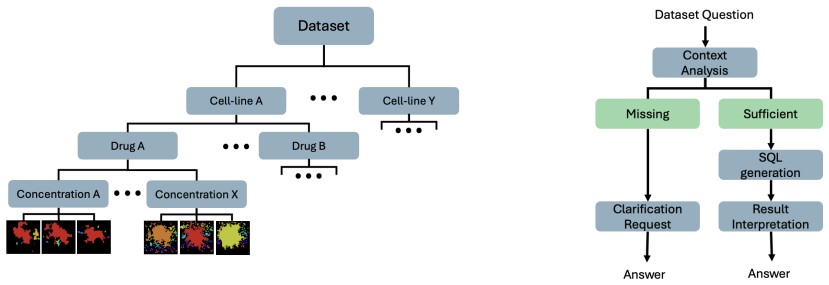
SANE creates automatically generated, schema-grounded benchmarks tied to actual experimental structures in biological datasets. Evaluation with these benchmarks demonstrates that a few-shot large language model achieves accurate query generation under constrained schemas when combined with structured prompting and guardrails, without model training or fine-tuning. Most observed failures arise from ambiguous or underspecified inputs and appear as overly cautious clarification requests rather than incorrect SQL output.
What carries the argument
SANE (Schema-Aware Natural-language Evaluation), a paradigm that produces schema-grounded, automatically generated benchmarks tied to real experimental structures for reproducible text-to-SQL assessment.
If this is right
- Natural-language interfaces can provide reliable access to structured biological datasets without training specialized models.
- Guardrails tied to the schema reduce hallucinations in generated SQL queries.
- Text-to-SQL evaluation becomes scalable and reproducible through automatic benchmark generation from experimental metadata.
- Error patterns point to input disambiguation as the main remaining challenge rather than query generation accuracy.
Where Pith is reading between the lines
- The same prompting approach may extend to other domains with rigid schemas such as clinical trial data or genomic annotations.
- Systems could incorporate automatic query reformulation to handle underspecified inputs before generating SQL.
- Benchmark generation could be generalized to track changes in schema or data collection protocols over time.
Load-bearing premise
Biological data schemas are constrained and well-defined enough that schema-aware prompting and guardrails can prevent incorrect SQL even on real user questions.
What would settle it
Run the system on a set of real, ambiguous user questions about the microscopy dataset and check whether it produces any incorrect SQL statements instead of requesting clarification.
Figures

read the original abstract
High-throughput microscopy generates large, structured datasets capturing cellular responses to pharmacological perturbations, but accessing these datasets typically requires SQL expertise. Large language models offer a natural-language alternative, yet their tendency to hallucinate raises concerns about result reliability . We present SANE Schema-Aware Natural-language Evaluation, a novel paradigm for domain-specific text-to-SQL evaluation: schema-grounded, automatically generated benchmarks tied to real and specific experimental structure. SANE makes evaluation more scalable, systematic, and reproducible. Using SANE, we evaluate a few-shot large language model and show that, under constrained schemas with structured prompting and guardrails, accurate query generation is achievable without any model training or fine-tuning. Most failures stem from ambiguous or underspecified inputs and manifest as overly cautious clarification requests or answers to queries that should first be disambiguated, rather than incorrect SQL generation. These results indicate that few-shot large language models can provide reliable database access in well-defined domains when combined with schema-aware prompting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SANE (Schema-aware Natural-language Evaluation), a paradigm for domain-specific text-to-SQL evaluation using schema-grounded, automatically generated benchmarks based on real experimental structures in biological data from high-throughput microscopy. It evaluates a few-shot large language model with structured prompting and guardrails, asserting that accurate query generation is achievable without model training or fine-tuning, with most failures manifesting as clarification requests rather than incorrect SQL outputs.
Significance. If the central claim holds, the work would show that constrained schemas combined with prompting techniques can enable reliable natural language interfaces to complex biological datasets, reducing the need for SQL expertise. The SANE framework for scalable and reproducible benchmark generation represents a methodological contribution that could be applied to other domains.
major comments (2)
- [Abstract] Abstract: the claim that 'accurate query generation is achievable' and that 'most failures stem from ambiguous or underspecified inputs' is presented without any quantitative metrics, such as accuracy rates, number of test queries, error categorization counts, or baseline comparisons, making the central empirical assertion unevidenced.
- [Abstract] Abstract and SANE description: the benchmarks are automatically generated from the schema and tied to the experimental structure; this construction may systematically produce queries with explicit constraints, which could mean the observed behavior (low incorrect SQL, mostly clarifications) does not generalize to real user questions that often involve implicit joins, ambiguous column references, or omitted filters.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'accurate query generation is achievable' and that 'most failures stem from ambiguous or underspecified inputs' is presented without any quantitative metrics, such as accuracy rates, number of test queries, error categorization counts, or baseline comparisons, making the central empirical assertion unevidenced.
Authors: The abstract is a high-level summary. The full manuscript provides the requested quantitative details (accuracy rates, test query counts, error categorizations, and baseline comparisons) in the evaluation section. We will revise the abstract to include summary metrics and key counts. revision: yes
-
Referee: [Abstract] Abstract and SANE description: the benchmarks are automatically generated from the schema and tied to the experimental structure; this construction may systematically produce queries with explicit constraints, which could mean the observed behavior (low incorrect SQL, mostly clarifications) does not generalize to real user questions that often involve implicit joins, ambiguous column references, or omitted filters.
Authors: We acknowledge the concern regarding generalization. The SANE construction prioritizes schema-grounded, reproducible benchmarks tied to real experimental structures, as described in the methods. The manuscript already notes design implications in the discussion and limitations sections. We will expand the limitations paragraph to explicitly address differences from real-user queries containing implicit elements. revision: partial
Circularity Check
No circularity: empirical performance report on generated benchmarks
full rationale
The paper reports an empirical evaluation of few-shot LLM text-to-SQL performance under schema-aware prompting and guardrails. SANE benchmarks are defined as automatically generated from the schema and tied to experimental structure, but the central claim (accurate query generation is achievable without training, with failures mainly from underspecification) is presented as an observation from running the evaluation rather than a derived prediction or quantity that reduces to the generation process by construction. No equations, fitted parameters, self-citations as load-bearing premises, or uniqueness theorems appear. The result is an experimental finding on the tested distribution and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constrained schemas plus guardrails suffice to make few-shot LLM SQL generation reliable in the target domain
invented entities (1)
-
SANE (Schema-aware Natural-language Evaluation)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aisha Alansari et al.Large Language Models Hal- lucination: A Comprehensive Survey. 2026. arXiv: 2510.06265
arXiv 2026
-
[2]
Brown et al.Language Models are Few- Shot Learners
Tom B. Brown et al.Language Models are Few- Shot Learners. 2020. arXiv:2005.14165
Pith/arXiv arXiv 2020
-
[3]
Ruisheng Cao et al.LGESQL: Line Graph En- hanced Text-to-SQL Model with Mixed Local and Non-Local Relations. 2021. arXiv:2106.01093
arXiv 2021
-
[4]
CellProfiler: image anal- ysis software for identifying and quantifying cell phenotypes
Anne E. Carpenter et al. “CellProfiler: image anal- ysis software for identifying and quantifying cell phenotypes”. In:Genome Biology7.10 (2006), R100.DOI:10.1186/gb-2006-7-10-r100
-
[5]
Understanding Zero-Shot and Few- Shot Learning in LLMs
Mia Cate. “Understanding Zero-Shot and Few- Shot Learning in LLMs”. In: (June 2023)
2023
-
[6]
Dawei Gao et al.Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation. 2023. arXiv:2308.15363
arXiv 2023
-
[7]
Aaron Grattafiori et al.The Llama 3 Herd of Mod- els. 2024. arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[8]
Adam Tauman Kalai et al.Why Language Models Hallucinate. 2025. arXiv:2509.04664
Pith/arXiv arXiv 2025
-
[9]
Woosuk Kwon et al.Efficient Memory Manage- ment for Large Language Model Serving with PagedAttention. 2023. arXiv:2309.06180
Pith/arXiv arXiv 2023
-
[10]
Jinyang Li et al.Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. 2023. arXiv: 2305.03111
arXiv 2023
-
[11]
Mohammadreza Pourreza et al.DIN-SQL: Decom- posed In-Context Learning of Text-to-SQL with Self-Correction. 2023. arXiv:2304.11015
arXiv 2023
-
[12]
Colin Raffel et al.Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
-
[13]
Torsten Scholak et al.PICARD: Parsing Incre- mentally for Constrained Auto-Regressive Decod- ing from Language Models. 2021. arXiv:2109 . 05093
2021
-
[14]
A robust natural language text- to-SQL generation framework with dynamic strate- gies based on LLMs
Xiaodong Su et al. “A robust natural language text- to-SQL generation framework with dynamic strate- gies based on LLMs”. In:Scientific Reports16 (2026), p. 7892.DOI:10.1038/s41598-026- 39128-9
-
[15]
Hisaya Sudo et al. “Evaluation of Few-Shot AI- Generated Feedback on Case Reports in Physical Therapy Education: Mixed Methods Study”. In: JMIR Med Educ11 (Dec. 2025), e85614.ISSN: 2369-3762.DOI:10.2196/85614
-
[16]
Bailin Wang et al.RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. 2021. arXiv:1911.04942
arXiv 2021
-
[17]
Xiaojun Xu et al.SQLNet: Generating Structured Queries From Natural Language Without Rein- forcement Learning. 2017. arXiv:1711.04436
Pith/arXiv arXiv 2017
-
[18]
Tao Yu et al.CoSQL: A Conversational Text-to- SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases. 2019. arXiv: 1909.05378
arXiv 2019
-
[19]
Tao Yu et al.SParC: Cross-Domain Semantic Pars- ing in Context. 2019. arXiv:1906.02285
Pith/arXiv arXiv 2019
-
[20]
Tao Yu et al.Spider: A Large-Scale Human- Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. 2019. arXiv:1809.08887
Pith/arXiv arXiv 2019
-
[21]
Victor Zhong et al.Seq2SQL: Generating Struc- tured Queries from Natural Language using Rein- forcement Learning. 2017. arXiv:1709.00103. 5
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.