MAD: Mapping-Aware World Models for Agile Quadrotor Flight
Pith reviewed 2026-06-28 06:21 UTC · model grok-4.3
The pith
A world model that reconstructs robocentric occupancy and visibility maps from depth images produces better collision-avoidance policies for agile quadrotor flight than image-reconstruction baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
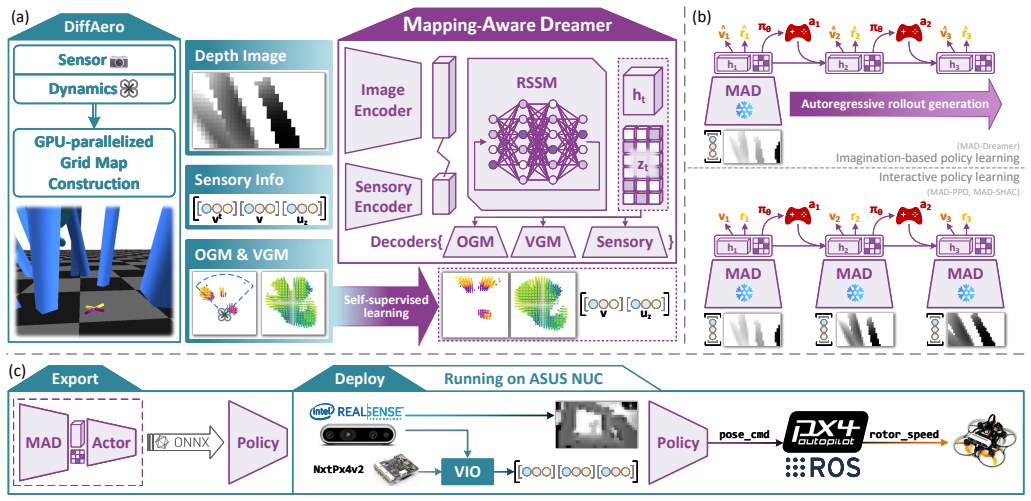
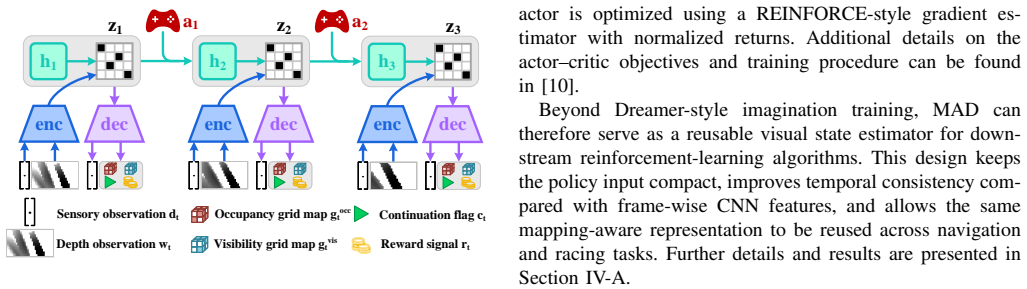
MAD learns recurrent latent dynamics that reconstruct robocentric occupancy and visibility grid maps together with proprioceptive states. This forces the latent state to encode local geometry, visibility history, and ego-motion in a form directly relevant to collision avoidance. The resulting representation supports imagination-based and feature-extractor policies that outperform vision-only baselines in success rate, speed, and cross-task transfer while also yielding interpretable map predictions and accurate ego-motion estimates.
What carries the argument
Mapping-Aware Dreamer (MAD), whose self-supervised objective reconstructs robocentric occupancy and visibility grid maps rather than raw images.
If this is right
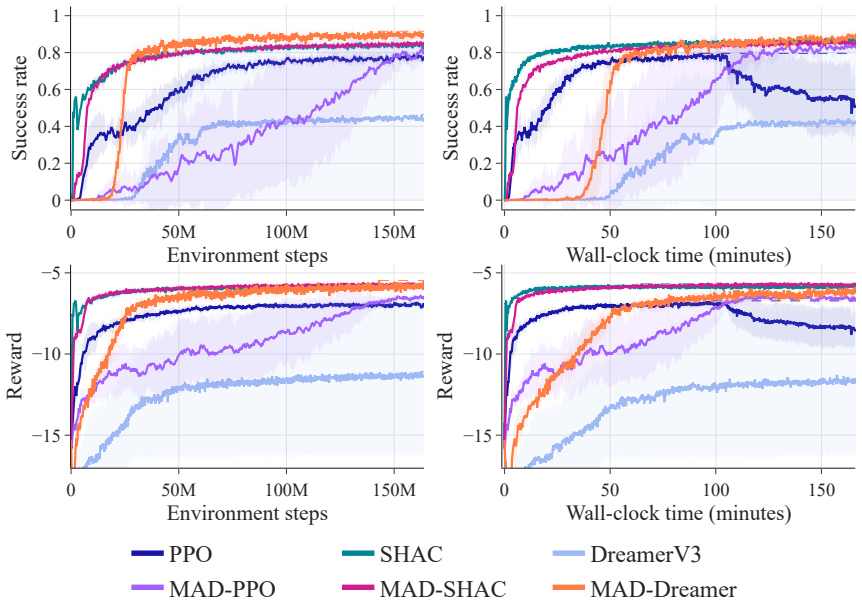
- MAD-based agents reach higher success rates and faster flight speeds than vision-only baselines in navigation and racing tasks.
- The learned representation transfers better across tasks than image-reconstruction baselines.
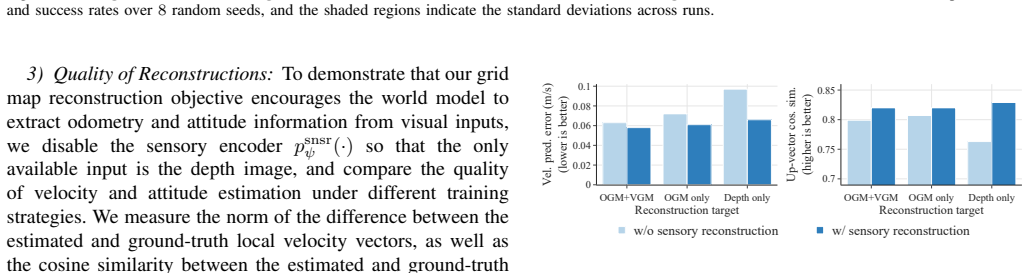
- The model generates interpretable occupancy and visibility predictions along with accurate ego-motion estimates from depth.
- The same policy deploys successfully on physical hardware, attaining 9.66 m/s in simulation and 5.05 m/s in real forest flights.
Where Pith is reading between the lines
- The map-reconstruction objective could be combined with explicit SLAM modules to improve robustness when depth sensing is noisy or sparse.
- Extending the grid reconstruction to include predicted future occupancy might allow longer-horizon planning without additional modules.
- The GPU-parallel map supervision used in training suggests the approach scales to larger environments if map resolution or field of view is increased.
Load-bearing premise
Reconstructing occupancy and visibility grid maps forces the latent state to encode information directly useful for collision avoidance.
What would settle it
Vision-only baselines achieving equal or higher success rates and speeds than MAD agents on the same visual navigation and racing tasks would falsify the claimed benefit of map reconstruction.
Figures



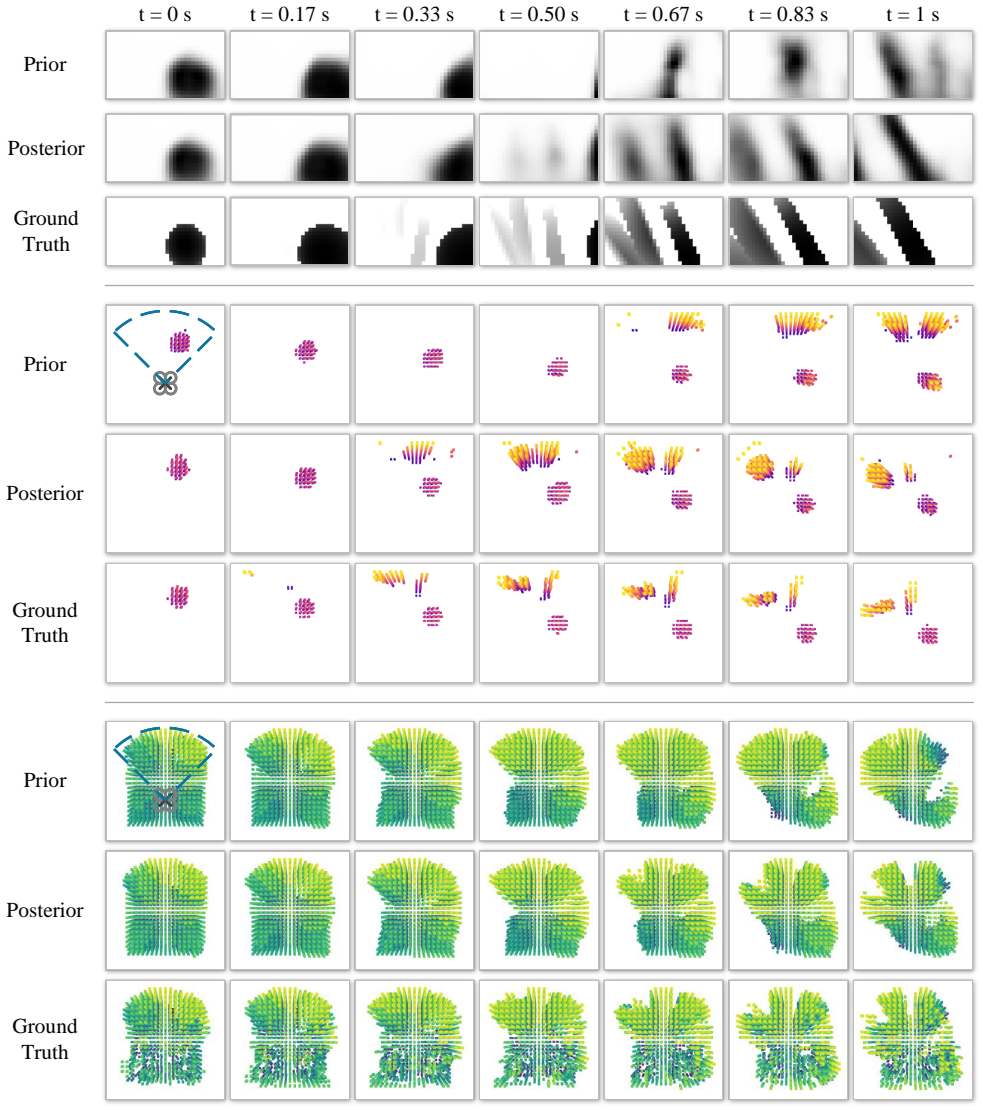
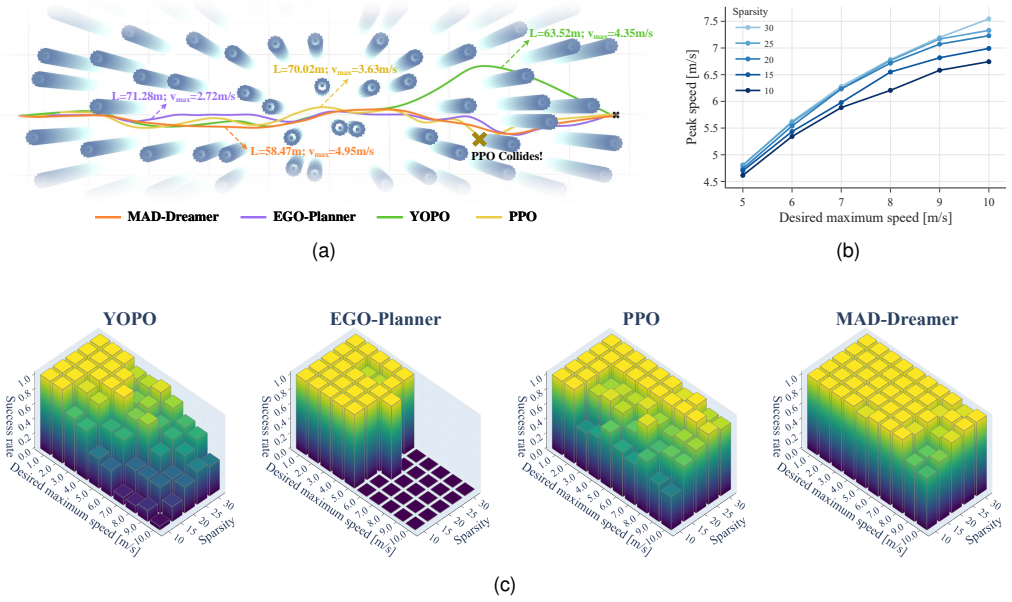
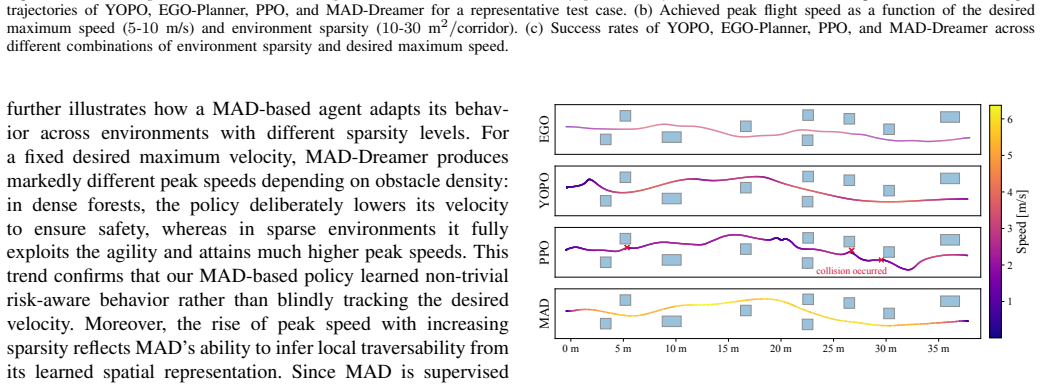


read the original abstract
Agile quadrotor flight in cluttered scenes requires more than a reactive mapping from a depth image to a control command: the vehicle must remember which regions have been observed, infer nearby occupied space, and act under partial visibility and tight latency. In this paper, we present Mapping-Aware Dreamer (MAD), a geometry-aware world model for vision-based quadrotor flight. Instead of using raw-image reconstruction as the main self-supervised objective, MAD learns recurrent latent dynamics that reconstruct robocentric occupancy and visibility grid maps together with proprioceptive states. This design forces the latent state to encode local geometry, visibility history, and ego-motion in a form that is directly relevant to collision avoidance. MAD is trained in DiffAero using a GPU-parallel map-construction module that provides high-throughput supervision for occupancy and visibility. The learned representation is used in three policy-learning modes: imagination-based MAD-Dreamer and feature-extractor variants based on PPO and SHAC. Across visual navigation and racing tasks, MAD-based agents achieve higher success rates, faster flight, and better cross-task transfer than corresponding vision-only baselines. The model also produces interpretable map predictions and accurate ego-motion estimates from depth observations. We further deploy the learned policy on a physical quadrotor with an Intel RealSense D435i and demonstrate safe indoor and outdoor flight under limited sensing, reaching 9.66 m/s in simulation and 5.05 m/s in real-world forest experiments. These results show that mapping-aware world models provide a practical middle ground between modular aerial navigation and end-to-end learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Mapping-Aware Dreamer (MAD), a recurrent world model for vision-based quadrotor flight that replaces raw-image reconstruction with self-supervised prediction of robocentric occupancy and visibility grid maps plus proprioceptive states. The learned latent dynamics are used for policy learning via imagination (MAD-Dreamer), PPO, and SHAC variants. Across visual navigation and racing tasks the MAD agents are reported to achieve higher success rates, faster flight, and better cross-task transfer than vision-only baselines; the model also yields interpretable map predictions and ego-motion estimates. Real-world deployment on a quadrotor with an Intel RealSense D435i is demonstrated in indoor and outdoor forest settings, reaching 9.66 m/s in simulation and 5.05 m/s in hardware experiments.
Significance. If the performance advantages are causally linked to the mapping-aware objective, the work supplies a concrete middle ground between modular mapping pipelines and pure end-to-end vision policies for agile flight under partial observability. The combination of GPU-parallel map supervision in DiffAero, real-world transfer at 5 m/s, and cross-task generalization would constitute a useful empirical contribution to learning-based aerial robotics.
major comments (2)
- [Abstract] Abstract: the design claim that reconstructing robocentric occupancy/visibility grids 'forces the latent state to encode local geometry, visibility history, and ego-motion in a form that is directly relevant to collision avoidance' is presented as a direct consequence of the loss but is not supported by any ablation that isolates the map-reconstruction terms from proprioceptive prediction or architecture scale, nor by any probing of whether the policy actually conditions on the predicted maps during imagined rollouts. Without such evidence the reported gains in success rate and speed cannot be attributed to the mapping-aware component.
- Experiments section (implied by abstract claims): quantitative success rates, baseline numbers, and statistical tests are absent from the abstract and the provided summary; only peak speeds are stated. This makes it impossible to judge the magnitude or reliability of the 'higher success rates' and 'better cross-task transfer' assertions that constitute the central empirical claim.
minor comments (1)
- [Abstract] The simulator name 'DiffAero' appears without citation or brief description in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical validation and attribution of results. We address each major comment below, agreeing where the manuscript requires strengthening and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the design claim that reconstructing robocentric occupancy/visibility grids 'forces the latent state to encode local geometry, visibility history, and ego-motion in a form that is directly relevant to collision avoidance' is presented as a direct consequence of the loss but is not supported by any ablation that isolates the map-reconstruction terms from proprioceptive prediction or architecture scale, nor by any probing of whether the policy actually conditions on the predicted maps during imagined rollouts. Without such evidence the reported gains in success rate and speed cannot be attributed to the mapping-aware component.
Authors: We agree that the abstract's design motivation would benefit from direct empirical support isolating the map-reconstruction objective. The manuscript compares full MAD agents against vision-only baselines, but does not include an ablation removing only the map terms while holding proprioceptive prediction and model scale fixed, nor explicit probing of map conditioning in imagined rollouts. In the revision we will add such an ablation (training a proprioception-only variant) and include analysis of policy dependence on predicted maps, e.g., via latent masking or rollout visualizations. These additions will allow clearer attribution of performance differences. revision: yes
-
Referee: [—] Experiments section (implied by abstract claims): quantitative success rates, baseline numbers, and statistical tests are absent from the abstract and the provided summary; only peak speeds are stated. This makes it impossible to judge the magnitude or reliability of the 'higher success rates' and 'better cross-task transfer' assertions that constitute the central empirical claim.
Authors: The abstract reports qualitative improvements without numerical success rates, baseline values, or statistical details. While the full manuscript contains tables with these metrics and comparisons, the abstract itself does not. We will revise the abstract to incorporate key quantitative results (success rates, mean speeds, transfer metrics) and note the statistical tests performed in the experiments section, making the central claims more precise and verifiable from the abstract alone. revision: yes
Circularity Check
No significant circularity; design claim is an assumption, not a self-referential derivation
full rationale
The paper's central claims rest on empirical outcomes from training in DiffAero and real-world deployment, with no equations, derivations, or fitted parameters presented in the provided text. The statement that the reconstruction objective 'forces the latent state to encode local geometry...' is a design assumption rather than a reduction of a prediction to its inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. Performance gains are reported as experimental results compared to baselines, without any renaming of known results or fitted-input predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Minimum snap trajectory generation and control for quadrotors,
D. Mellinger and V . Kumar, “Minimum snap trajectory generation and control for quadrotors,” inProc. IEEE Int. Conf. Robot. Autom., Shanghai, China, Aug. 2011, pp. 2520–2525
2011
-
[2]
Safety-assured high-speed navigation for MA Vs,
Y . Ren, F. Zhu, G. Lu, Y . Cai, L. Yin, F. Kong, J. Lin, N. Chen, and F. Zhang, “Safety-assured high-speed navigation for MA Vs,”Sci. Robot., vol. 10, no. 98, p. eado6187, 2025
2025
-
[3]
NavRL: Learning safe flight in dynamic environments,
Z. Xu, X. Han, H. Shen, H. Jin, and K. Shimada, “NavRL: Learning safe flight in dynamic environments,”IEEE Robot. Autom. Lett., vol. 10, no. 4, pp. 3668–3675, 2025
2025
-
[4]
Learning vision-based agile flight via differentiable physics,
Y . Zhang, Y . Hu, Y . Song, D. Zou, and W. Lin, “Learning vision-based agile flight via differentiable physics,”Nat. Mach. Intell., vol. 7, no. 6, pp. 954–966, Jun. 2025
2025
-
[5]
You only plan once: A learning-based one-stage planner with guidance learning,
J. Lu, X. Zhang, H. Shen, L. Xu, and B. Tian, “You only plan once: A learning-based one-stage planner with guidance learning,”IEEE Robot. Autom. Lett., vol. 9, no. 7, pp. 6083–6090, 2024
2024
-
[6]
Champion-level drone racing using deep reinforcement learn- ing,
A. Loquercio, E. Kaufmann, S. Ramakrishnan, M. M ¨uller, and D. Scara- muzza, “Champion-level drone racing using deep reinforcement learn- ing,”Nature, vol. 620, no. 7976, pp. 982–987, 2023
2023
-
[7]
Reach- ing the limit in autonomous racing: Optimal control versus reinforcement learning,
Y . Song, A. Romero, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Reach- ing the limit in autonomous racing: Optimal control versus reinforcement learning,”Sci. Robot., vol. 8, no. 82, p. eadg1462, 2023
2023
-
[8]
Dream to control: Learning behaviors by latent imagination,
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learning behaviors by latent imagination,” inProc. Int. Conf. Learn. Represent., 2020
2020
-
[9]
Mastering Atari with discrete world models,
D. Hafner, T. P. Lillicrap, M. Norouzi, and J. Ba, “Mastering Atari with discrete world models,” inProc. Int. Conf. Learn. Represent., 2021
2021
-
[10]
Mastering diverse control tasks through world models,
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering diverse control tasks through world models,”Nature, pp. 1–7, 2025
2025
-
[11]
TD-MPC2: Scalable, robust world models for continuous control,
N. Hansen, H. Su, and X. Wang, “TD-MPC2: Scalable, robust world models for continuous control,” inProc. Int. Conf. Learn. Represent., 2024
2024
-
[12]
Day- Dreamer: World models for physical robot learning,
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and S. Levine, “Day- Dreamer: World models for physical robot learning,” inProc. Conf. Robot Learn., 2022
2022
-
[13]
CORB-Planner: Corridor as observations for rl planning in high-speed flight,
Y . Zhang, B. Gao, G. Wang, J. Sun, and Z. Li, “CORB-Planner: Corridor as observations for rl planning in high-speed flight,”IEEE/ASME Trans. Mechatron., 2025
2025
-
[14]
Learning agility adaptation for flight in clutter,
G. Zhao, T. Wu, Y . Chen, and F. Gao, “Learning agility adaptation for flight in clutter,”arXiv:2403.04586, 2024
arXiv 2024
-
[16]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[17]
Accelerated policy learning with parallel differentiable simulation,
J. Xu, V . Makoviychuk, Y . Narang, F. Ramos, W. Matusik, A. Garg, and M. Macklin, “Accelerated policy learning with parallel differentiable simulation,” inProc. Int. Conf. Learn. Represent., 2021
2021
-
[18]
Learning high-speed flight in the wild,
A. Loquercio, E. Kaufmann, R. Ranftl, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Learning high-speed flight in the wild,”Sci. Robot., vol. 6, no. 59, p. eabg5810, 2021
2021
-
[19]
Robust navigation for racing drones based on imitation learning and modularization,
T. Wang and D. Eui Chang, “Robust navigation for racing drones based on imitation learning and modularization,” inProc. IEEE Int. Conf. Robot. Autom., 2021, pp. 13 724–13 730
2021
-
[20]
Deep drone racing: From simulation to reality with domain randomization,
A. Loquercio, E. Kaufmann, R. Ranftl, A. Dosovitskiy, V . Koltun, and D. Scaramuzza, “Deep drone racing: From simulation to reality with domain randomization,”IEEE Trans. Robot., vol. 36, no. 1, pp. 1–14, 2020
2020
-
[21]
Learning vision- based flight in drone swarms by imitation,
F. Schilling, J. Lecoeur, F. Schiano, and D. Floreano, “Learning vision- based flight in drone swarms by imitation,”IEEE Robot. Autom. Lett., vol. 4, no. 4, pp. 4523–4530, 2019
2019
-
[22]
A hierarchical reinforcement learning algorithm based on attention mechanism for UA V autonomous navigation,
Z. Liu, Y . Cao, J. Chen, and J. Li, “A hierarchical reinforcement learning algorithm based on attention mechanism for UA V autonomous navigation,”IEEE Trans. Intell. Transp. Syst., vol. 24, no. 11, pp. 13 309– 13 320, 2023
2023
-
[23]
Depth transfer: Learning to see like a simulator for real-world drone navigation,
H. Yu, C. D. Wagter, and G. C. H. E. de Croon, “Depth transfer: Learning to see like a simulator for real-world drone navigation,” arXiv:2505.12428, 2025
arXiv 2025
-
[24]
Memory-based deep reinforcement learning for obstacle avoidance in UA V with limited environment knowledge,
A. Singla, S. Padakandla, and S. Bhatnagar, “Memory-based deep reinforcement learning for obstacle avoidance in UA V with limited environment knowledge,”IEEE Trans. Intell. Transp. Syst., vol. 22, no. 1, pp. 107–118, 2021
2021
-
[25]
Autonomous drone racing: A survey,
D. Hanover, A. Loquercio, L. Bauersfeld, A. Romero, R. Penicka, Y . Song, G. Cioffi, E. Kaufmann, and D. Scaramuzza, “Autonomous drone racing: A survey,”IEEE Trans. Robot., vol. 40, pp. 3044–3067, 2024
2024
-
[26]
Seeing through pixel motion: Learning obstacle avoidance from optical flow with one camera,
Y . Hu, Y . Zhang, Y . Song, Y . Deng, F. Yu, L. Zhang, W. Lin, D. Zou, and W. Yu, “Seeing through pixel motion: Learning obstacle avoidance from optical flow with one camera,”IEEE Robot. Autom. Lett., vol. 10, no. 6, pp. 5871–5878, 2025
2025
-
[27]
Dream to fly: Model-based reinforcement learning for vision-based drone flight,
A. Romero, A. Shenai, I. Geles, E. Aljalbout, and D. Scaramuzza, “Dream to fly: Model-based reinforcement learning for vision-based drone flight,”arXiv:2501.14377, 2025
Pith/arXiv arXiv 2025
-
[28]
A. Verraest, S. Bahnam, R. Ferede, G. de Croon, and C. D. Wagter, “SkyDreamer: Interpretable end-to-end vision-based drone racing with model-based reinforcement learning,”arXiv:2510.14783, 2025
arXiv 2025
-
[29]
STORM: Efficient stochastic transformer based world models for reinforcement learning,
W. Zhang, G. Wang, J. Sun, Y . Yuan, and G. Huang, “STORM: Efficient stochastic transformer based world models for reinforcement learning,” inProc. Adv. Neural Inf. Process. Syst., 2023
2023
-
[30]
Mastering Atari, Go, Chess and Shogi by planning with a learned model,
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T. Graepelet al., “Mastering Atari, Go, Chess and Shogi by planning with a learned model,”Nature, vol. 588, no. 7839, pp. 604–609, 2020
2020
-
[31]
Mastering Atari games with limited data,
W. Ye, S. Liu, T. Kurutach, P. Abbeel, and Y . Gao, “Mastering Atari games with limited data,” inProc. Adv. Neural Inf. Process. Syst., A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021
2021
-
[32]
Temporal difference learning for model predictive control,
N. Hansen, X. Wang, and H. Su, “Temporal difference learning for model predictive control,” inProc. Int. Conf. Mach. Learn., 2022
2022
-
[33]
Diffusion for world modeling: Visual details matter in atari,
E. Alonso, A. Jelley, V . Micheli, A. Kanervisto, A. Storkey, T. Pearce, and F. Fleuret, “Diffusion for world modeling: Visual details matter in atari,” inProc. Adv. Neural Inf. Process. Syst., 2024
2024
-
[34]
V oxgraph: Globally consistent, volumetric mapping using signed distance function submaps,
V . Reijgwart, A. Millane, H. Oleynikova, R. Siegwart, C. Cadena, and J. Nieto, “V oxgraph: Globally consistent, volumetric mapping using signed distance function submaps,”IEEE Robot. Autom. Lett., vol. 5, no. 1, pp. 227–234, 2020
2020
-
[35]
Occupancy grid mapping without ray-casting for high-resolution LiDAR sensors,
Y . Cai, F. Kong, Y . Ren, F. Zhu, J. Lin, and F. Zhang, “Occupancy grid mapping without ray-casting for high-resolution LiDAR sensors,”IEEE Trans. Robot., vol. 40, pp. 172–192, 2024
2024
-
[36]
ROG-Map: An efficient robocentric occupancy grid map for large-scene and high-resolution LiDAR-based motion planning,
Y . Ren, Y . Cai, F. Zhu, S. Liang, and F. Zhang, “ROG-Map: An efficient robocentric occupancy grid map for large-scene and high-resolution LiDAR-based motion planning,” inProc. IEEE/RSJ Int. Conf. Intell. Robot. Syst., Abu Dhabi, United Arab Emirates, Oct. 2024, pp. 8119– 8125
2024
-
[37]
Slope inspection under dense vegetation using LiDAR-based quadrotors,
W. Liu, Y . Ren, R. Guo, V . W. Kong, A. S. Hung, F. Zhu, Y . Cai, H. Wu, Y . Zou, and F. Zhang, “Slope inspection under dense vegetation using LiDAR-based quadrotors,”Nat. Commun., vol. 16, no. 1, p. 7411, 2025
2025
-
[38]
Training agents inside of scalable world models,
D. Hafner, W. Yan, and T. Lillicrap, “Training agents inside of scalable world models,”arXiv:2509.10247, 2025
Pith/arXiv arXiv 2025
-
[39]
EGO-Planner: An ESDF- free gradient-based local planner for quadrotors,
X. Zhou, Z. Wang, H. Ye, C. Xu, and F. Gao, “EGO-Planner: An ESDF- free gradient-based local planner for quadrotors,”IEEE Robot. Autom. Lett., vol. 6, no. 2, pp. 478–485, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.