Learning Admissible Heuristics via Cost Partitioning
Pith reviewed 2026-06-28 06:32 UTC · model grok-4.3
The pith
A neural network learns the first admissible heuristic guaranteed by construction through cost partitioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
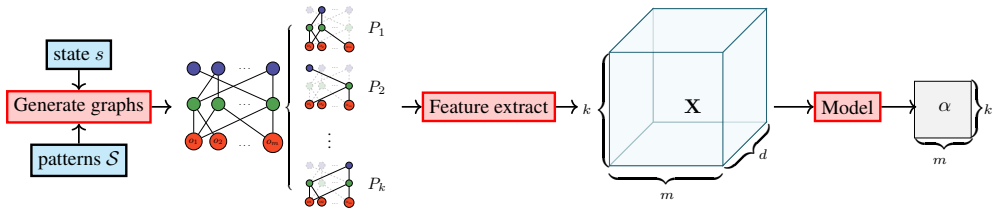
The paper establishes that admissible cost partitions can be learned by training a model to predict multipliers equivalent to optimal partitions under the Lagrangian dual. Planning states and patterns are represented as labelled graphs, structural features are extracted via an action-centric Weisfeiler-Leman algorithm, and a deep architecture with axial self-attention and softmax output layer maps these features to cost weights that satisfy the partition constraints by construction, ensuring the resulting heuristic is admissible for every state.
What carries the argument
The deep architecture with axial self-attention and softmax output layer that maps graph features to cost weights satisfying partition constraints by construction.
If this is right
- The learned heuristic can be used inside optimal planners such as A* without risking suboptimal solutions.
- Fewer nodes are expanded than when using suboptimal cost-partitioning baselines.
- Runtime cost of computing optimal partitions at each state is avoided.
- Admissibility is preserved even for states absent from the training set.
Where Pith is reading between the lines
- The same constraint-enforcing output layer could be reused to learn admissible combinations of other heuristic families.
- Graph encodings of states may transfer to learning admissible heuristics in related search or scheduling domains.
- Training on a wider variety of planning domains could test whether the admissibility guarantee scales beyond the evaluated instances.
Load-bearing premise
The Lagrangian dual equivalence between cost partitioning and multiplier prediction can be turned into a supervised learning target whose outputs remain admissible for unseen states.
What would settle it
A planning state where the learned heuristic returns a value strictly larger than the true optimal cost to the goal.
Figures

read the original abstract
Admissible heuristics are essential for optimal planning, yet learning them remains challenging due to the risk of overestimation. Cost partitioning combines multiple abstraction heuristics while preserving admissibility, but computing optimal partitions online is expensive. We propose a framework that learns to infer admissible cost partitions by leveraging the Lagrangian dual equivalence between cost partitioning and multiplier prediction. Planning states and patterns are encoded as labelled graphs, and an action-centric variant of the Weisfeiler-Leman algorithm extracts structural feature vectors. A deep architecture with axial self-attention and a softmax output layer maps these features to cost weights that satisfy the partition constraints by construction, ensuring admissibility. Experiments demonstrate reduced node expansions compared to suboptimal partitioning baselines while maintaining strict admissibility. To our knowledge, this is the first machine-learned heuristic guaranteed to be admissible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neural architecture for learning cost partitions in classical planning that maps state-pattern graph encodings (via an action-centric Weisfeiler-Leman variant and axial attention) to non-negative cost weights via a softmax output layer. Because the weights satisfy the partition constraints by construction for every input, cost-partitioning theory guarantees that the resulting heuristic remains admissible even for unseen states; the Lagrangian dual is used only to supply training targets. Experiments are reported to show fewer node expansions than suboptimal partitioning baselines while preserving strict admissibility, and the work claims to be the first machine-learned admissible heuristic with such a guarantee.
Significance. If the experimental results and the by-construction admissibility invariant hold, the contribution is significant: it removes the overestimation risk that has limited prior learned heuristics and supplies a scalable, offline-trained alternative to expensive online optimal cost partitioning. The explicit use of an invariant-preserving architecture is a methodological strength that could transfer to other constrained optimization settings in planning and beyond.
major comments (2)
- [§3] §3 (Method): the claim that the softmax layer enforces the partition constraints 'by construction' for unseen states is load-bearing for the admissibility guarantee, yet the manuscript provides no explicit verification that the axial-attention features remain well-defined and the output dimension matches the number of abstractions for arbitrary test instances.
- [§4] §4 (Experiments): the abstract states that the learned heuristic 'demonstrate[s] reduced node expansions compared to suboptimal partitioning baselines,' but no table, domain list, or quantitative deltas (e.g., expansions or coverage) are referenced; without these data the empirical support for the central claim cannot be assessed.
minor comments (2)
- [Abstract] The abstract asserts 'to our knowledge, this is the first machine-learned heuristic guaranteed to be admissible' without citing the closest prior learned-heuristic papers that attempted (but did not guarantee) admissibility; a short related-work paragraph would strengthen the novelty claim.
- [§3] Notation for the graph encoding (nodes, edge labels, pattern identifiers) is introduced in §3 but never summarized in a single table or figure caption, making it difficult to trace how a concrete planning state is turned into the input tensor.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Method): the claim that the softmax layer enforces the partition constraints 'by construction' for unseen states is load-bearing for the admissibility guarantee, yet the manuscript provides no explicit verification that the axial-attention features remain well-defined and the output dimension matches the number of abstractions for arbitrary test instances.
Authors: We agree that an explicit clarification strengthens the presentation. The input to the network is a state-pattern graph whose nodes explicitly encode the full set of abstractions for the given planning task; the final linear layer therefore has output dimension exactly equal to the number of abstractions present in that graph, after which a per-abstraction softmax is applied. Because the Weisfeiler-Leman feature extraction and axial attention operate on any graph of this form, the construction holds for arbitrary test instances by design. In the revision we will add a short paragraph in §3 together with a one-sentence formal statement confirming that the output dimension is determined by the input graph cardinality. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract states that the learned heuristic 'demonstrate[s] reduced node expansions compared to suboptimal partitioning baselines,' but no table, domain list, or quantitative deltas (e.g., expansions or coverage) are referenced; without these data the empirical support for the central claim cannot be assessed.
Authors: The referee is correct that the abstract would benefit from explicit pointers to the supporting evidence. The full experimental section (§4) already contains the domain list (ten IPC domains), tables reporting node expansions and coverage, and quantitative comparisons against the baselines. We will revise the abstract to include a parenthetical reference such as “(Tables 1–3, ten IPC domains)” so that readers can immediately locate the data. revision: yes
Circularity Check
No significant circularity identified
full rationale
The derivation is self-contained: admissibility follows directly from the softmax output layer (which enforces non-negativity and summation constraints by construction for all inputs, seen or unseen) together with standard cost-partitioning theory. The Lagrangian dual supplies only the supervised training targets; it is not required for the admissibility invariant, which holds independently of how closely the learned weights match an optimal partition. No self-definitional steps, fitted-input predictions, load-bearing self-citations, or imported uniqueness theorems appear in the chain. The central claim therefore rests on architectural enforcement plus external theory rather than reducing to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
Ahmed Abbas and Paul Swoboda , title =. Proc. 38th
-
[13]
Learning Valid Dual Bounds in Constraint Programming: Boosted Lagrangian Decomposition with Self-Supervised Learning , booktitle =
Swann Bessa and Darius Dabert and Max Bourgeat and Louis. Learning Valid Dual Bounds in Constraint Programming: Boosted Lagrangian Decomposition with Self-Supervised Learning , booktitle =
-
[14]
Learning Domain-Independent Heuristics for Grounded and Lifted Planning , booktitle =
Dillon Ze Chen and Sylvie Thi. Learning Domain-Independent Heuristics for Grounded and Lifted Planning , booktitle =
-
[15]
Chen and Felipe W
Dillon Z. Chen and Felipe W. Trevizan and Sylvie Thi. Return to Tradition: Learning Reliable Heuristics with Classical Machine Learning , booktitle =
-
[16]
Chen and Johannes Zenn and Tristan Cinquin and Sheila A
Dillon Z. Chen and Johannes Zenn and Tristan Cinquin and Sheila A. McIlraith , title =. Proc. 18th European Workshop on Reinforcement Learning (
-
[17]
Corrêa and André G
Augusto B. Corrêa and André G. Pereira and Jendrik Seipp , title=. proc. 38th Annual Conference on Neural Information Processing Systems (
-
[18]
Marco Ernandes and Marco Gori , title =. Proc. 16th Euroopean Conference on Artificial Intelligence (
-
[19]
Ehsan Futuhi and Nathan Sturtevant , title=. Proc. 14th International Conference on Learning Representations (
-
[20]
Learning to Rank for Synthesizing Planning Heuristics , booktitle =
Caelan Reed Garrett and Leslie Pack Kaelbling and Tom. Learning to Rank for Synthesizing Planning Heuristics , booktitle =
-
[21]
Patrik Haslum and Blai Bonet and Hector Geffner , title =. Proc. 20th American National Conference on Artificial Intelligence (
-
[22]
The Fast Downward Planning System , volume=
Malte Helmert , year=. The Fast Downward Planning System , volume=. Journal of Artificial Intelligence Research , publisher=
-
[23]
Malte Helmert , title =. Artif. Intell. , volume =
-
[24]
Chen and Felipe W
Mingyu Hao and Dillon Z. Chen and Felipe W. Trevizan and Sylvie Thi. Effective Data Generation and Feature Selection in Learning for Planning , booktitle =
-
[25]
2019 , eprint=
Axial Attention in Multidimensional Transformers , author=. 2019 , eprint=
2019
-
[26]
State Encodings for GNN-Based Lifted Planners , booktitle =
Rostislav Horc. State Encodings for GNN-Based Lifted Planners , booktitle =
-
[27]
Erez Karpas and Carmel Domshlak , title =. Proc. 21st International Joint Conference on Artificial Intelligence (
-
[28]
Michael Katz and Carmel Domshlak , title =. Proc. 18th International Conference on Automated Planning and Scheduling (
-
[29]
Michael Katz and Carmel Domshlak , title =. Artif. Intell. , volume =
-
[30]
Kullback and R
S. Kullback and R. A. Leibler , journal =. On Information and Sufficiency , urldate =
-
[31]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[32]
Ofir Marom, Ofir and Benjamin Rosman , title=. Proc. 30th International Conference on Automated Planning and Scheduling (
-
[33]
Farid Musayev and Dominik Drexler and Daniel Gnad and Jendrik Seipp , title =. Proc. 28th European Conference on Artificial Intelligence (
-
[34]
30th International Conference on Principles and Practice of Constraint Programming (CP 2024) , pages=
Learning Lagrangian Multipliers for the Travelling Salesman Problem , author=. 30th International Conference on Principles and Practice of Constraint Programming (CP 2024) , pages=. 2024 , organization=
2024
-
[35]
Getting the Most Out of Pattern Databases for Classical Planning , booktitle =
Florian Pommerening and Gabriele R. Getting the Most Out of Pattern Databases for Classical Planning , booktitle =
-
[36]
Pommerening, Florian and Röger, Gabriele and Helmert, Malte and Bonet, Blai , title=. 2014 , pages=. doi:10.1609/icaps.v24i1.13621 , journal=
-
[37]
From Non-Negative to General Operator Cost Partitioning , booktitle =
Florian Pommerening and Malte Helmert and Gabriele R. From Non-Negative to General Operator Cost Partitioning , booktitle =
-
[38]
Lagrangian Decomposition for Optimal Cost Partitioning , booktitle =
Florian Pommerening and Gabriele R. Lagrangian Decomposition for Optimal Cost Partitioning , booktitle =
-
[39]
Jendrik Seipp and Thomas Keller and Malte Helmert , title =. Proc. 27th International Conference on Automated Planning and Scheduling (
-
[40]
Jendrik Seipp and Thomas Keller and Malte Helmert , title =. J. Artif. Intell. Res. , volume =
-
[41]
Jendrik Seipp , title =. Proc. 31st International Conference on Automated Planning and Scheduling (
-
[42]
Trevizan and Sylvie Thi
William Shen and Felipe W. Trevizan and Sylvie Thi. Learning Domain-Independent Planning Heuristics with Hypergraph Networks , booktitle =
-
[43]
, title =
Shervashidze, Nino and Schweitzer, Pascal and van Leeuwen, Erik an and Mehlhorn, Kurt and Borgwardt, Karsten M. , title =. J. Mach. Learn. Res. , pages =. 2011 , issue_date =
2011
-
[44]
Tenenbaum and Leslie Pack Kaelbling and Michael Katz , title =
Tom Silver and Soham Dan and Kavitha Srinivas and Joshua B. Tenenbaum and Leslie Pack Kaelbling and Michael Katz , title =. Proc. 38th
-
[45]
Learning General Optimal Policies with Graph Neural Networks: Expressive Power, Transparency, and Limits , booktitle =
Simon St. Learning General Optimal Policies with Graph Neural Networks: Expressive Power, Transparency, and Limits , booktitle =
-
[46]
Learning Generalized Policies without Supervision Using GNNs , booktitle =
Simon St. Learning Generalized Policies without Supervision Using GNNs , booktitle =
-
[47]
ASNets: Deep Learning for Generalised Planning , journal =
Sam Toyer and Sylvie Thi. ASNets: Deep Learning for Generalised Planning , journal =
-
[48]
Attention is all you need , author=. Proc. 38th Annual Conference on Neural Information Processing Systems (
-
[49]
Leveraging Action Relational Structures for Integrated Learning and Planning , author=. Proc. 35th International Conference on Automated Planning and Scheduling (
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.