Selectivity Estimation for Semantic Filters on Image Data
Pith reviewed 2026-06-28 04:04 UTC · model grok-4.3
The pith
Semantic Histograms estimate selectivity of semantic image filters by treating them as implicit range queries in shared embedding spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
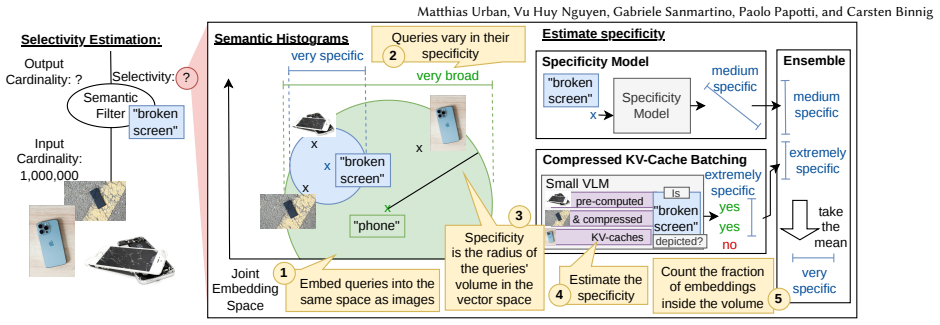
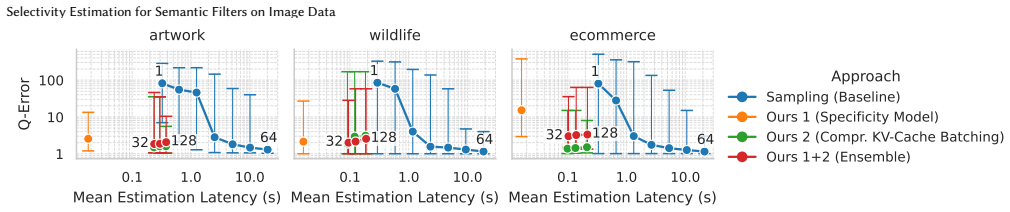
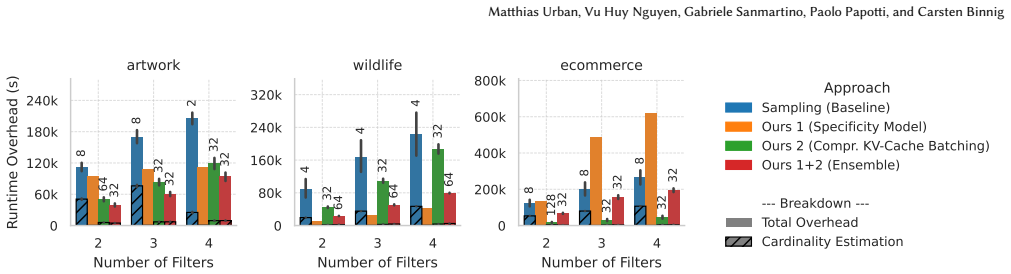
Semantic Histograms supply selectivity estimates for semantic filters on image data by quantifying the specificity of the implicit ranges those filters induce in shared embedding spaces. Two distinct estimation procedures are introduced, and an ensemble of the two produces the most accurate results, allowing query optimizers to bypass the latency of online sample-based profiling.
What carries the argument
Semantic Histograms, which model semantic filters as implicit range queries whose range widths are estimated from embedding-space geometry.
If this is right
- Query optimizers can determine execution orders for semantic filters without incurring sampling latency.
- Low-selectivity semantic filters become feasible to handle in interactive database workloads.
- An ensemble of the two range-width estimators outperforms either method used alone.
- Semantic data systems that embed LLMs and VLMs can reduce overall query runtime overhead.
Where Pith is reading between the lines
- The same embedding-space approach could be applied to semantic filters over text or video once suitable shared spaces exist.
- Precomputed histograms could be maintained incrementally as new images are added to a collection.
- Hybrid estimators that fall back to limited sampling only on uncertain predictions might further improve accuracy.
Load-bearing premise
Semantic filters correspond to well-behaved implicit ranges in the embedding space whose sizes can be estimated accurately without inspecting actual data samples or model internals at query time.
What would settle it
Measure the actual fraction of images that satisfy each test filter on a held-out image collection and compare those ground-truth selectivities against the estimates produced by Semantic Histograms.
Figures

read the original abstract
Semantic data systems integrate Large Language Models (LLMs) and Vision-Language Models (VLMs) directly into database query execution, enabling expressive queries on multi-modal data. However, optimizing these queries requires accurate selectivity estimates to determine the most efficient operator execution order. Contemporary systems rely on online sample-based profiling, a process that incurs severe latency overheads and struggles with low-selectivity queries. In this paper, we introduce Semantic Histograms, a novel selectivity estimator for semantic filters on image data that leverages shared embedding spaces to bypass traditional profiling. We realize that all semantic filters are implicit range queries, as they match a range of different images. Some filter predicates are more general, yielding a wide range, while others are more specific, yielding a smaller range. To address the challenge of implicit ranges, we propose two approaches to estimate the queries' specificity, with an ensemble of the two performing best. The evaluation shows that Semantic Histograms can reduce the end-to-end runtime overhead of query optimization and execution by up to 86%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Semantic Histograms as a selectivity estimator for semantic filters on image data. It models every semantic filter as an implicit range query in a shared embedding space, proposes two (unnamed) methods to estimate query specificity without online sampling or data access, reports that an ensemble of the two performs best, and claims this reduces end-to-end runtime overhead of query optimization and execution by up to 86%.
Significance. If the estimators can be shown to be both cheap and sufficiently accurate (especially for low-selectivity predicates), the approach could meaningfully improve query planning in semantic data systems that integrate VLMs, by eliminating the latency of sample-based profiling.
major comments (2)
- [Abstract] Abstract: the central claim of an 86% end-to-end overhead reduction is stated without any description of the datasets, baselines, error metrics, implementation of the two specificity estimators, or how the ensemble is constructed. These details are load-bearing for assessing whether the estimates are accurate enough to avoid worse query plans.
- [Abstract] Abstract: the load-bearing assumption that semantic filters map to well-behaved, estimable implicit ranges in embedding space (whose specificity can be computed without inspecting data samples or model internals) is asserted but not supported by any definition of the two methods or any selectivity-error numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract is currently too concise and does not provide sufficient context for the central claims. We will revise the abstract to include high-level descriptions of the methods, ensemble construction, datasets, baselines, and key error metrics while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of an 86% end-to-end overhead reduction is stated without any description of the datasets, baselines, error metrics, implementation of the two specificity estimators, or how the ensemble is constructed. These details are load-bearing for assessing whether the estimates are accurate enough to avoid worse query plans.
Authors: We agree that the abstract would be strengthened by including these details. In the revised manuscript we will expand the abstract to briefly name and characterize the two specificity estimators, describe how the ensemble is formed, list the primary datasets and baselines, and report the selectivity error metrics that underpin the 86% end-to-end overhead reduction. These additions will allow readers to evaluate the claim without immediately consulting the body of the paper. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that semantic filters map to well-behaved, estimable implicit ranges in embedding space (whose specificity can be computed without inspecting data samples or model internals) is asserted but not supported by any definition of the two methods or any selectivity-error numbers.
Authors: We acknowledge the observation. The body of the manuscript defines the two methods (which operate solely on embedding-space statistics without data samples or model internals) and presents selectivity-error results. To address the concern directly in the abstract, the revision will incorporate a concise characterization of the methods together with representative selectivity-error figures, thereby supporting the implicit-range assumption at the abstract level. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via empirical proposal
full rationale
The paper introduces Semantic Histograms as a new selectivity estimator based on the observation that semantic filters act as implicit range queries in embedding spaces, with two proposed estimation methods and their ensemble. No equations, fitted parameters, or derivations are presented that reduce the claimed selectivity estimates or 86% overhead reduction to self-definitional constructs, renamed known results, or load-bearing self-citations. The approach is positioned as bypassing profiling through direct use of embeddings, with accuracy evaluated empirically rather than derived by construction from inputs. This is the common case of an independent proposal without circular reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
SemCEB: A Cardinality Estimation Benchmark for Semantic Operators
SemCEB is the first benchmark for cardinality estimation over semantic operators, evaluating sampling methods and Semantic Histograms on accuracy, cost, latency, and memory using 102 queries on a real-world dataset.
Reference graph
Works this paper leans on
-
[1]
Paritosh Aggarwal, Bowei Chen, Anupam Datta, Benjamin Han, Boxin Jiang, Nitish Jindal, Zihan Li, Aaron Lin, Pawel Liskowski, Jay Tayade, Dimitris Tsirogiannis, Nathan Wiegand, and Weicheng Zhao. 2025. Cortex AISQL: A Production SQL Engine for Unstructured Data.CoRRabs/2511.07663 (2025). https://doi.org/10.48550/ARXIV.2511.07663 arXiv:2511.07663
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.07663 2025
-
[2]
Shah, Benjamin Sowell, Dan Tecuci, Vinayak Thapliyal, and Matt Welsh
Eric Anderson, Jonathan Fritz, Austin Lee, Bohou Li, Mark Lindblad, Henry Lindeman, Alex Meyer, Parth Parmar, Tanvi Ranade, Mehul A. Shah, Benjamin Sowell, Dan Tecuci, Vinayak Thapliyal, and Matt Welsh. 2025. The Design of an LLM-powered Unstructured Analytics System. In15th Conference on Innovative Data Systems Research, CIDR 2025, Amsterdam, The Netherl...
2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Ming-Hsuan Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[4]
Shu Chen, Deepti Raghavan, and Ugur Çetintemel. 2025. Continuous Prompts: LLM-Augmented Pipeline Processing over Unstructured Streams. CoRRabs/2512.03389 (2025). https://doi.org/10.48550/ARXIV.2512.03389 arXiv:2512.03389
-
[5]
Yeounoh Chung, Rushabh Desai, Jian He, Yu Xiao, Thibaud Hottelier, Yves- Laurent Kom Samo, Pushkar Khadilkar, Xianshun Chen, Sam Idicula, Fatma Özcan, Alon Y. Halevy, and Yannis Papakonstantinou. 2026. 100x Cost & Latency Reduction: Performance Analysis of AI Query Approximation using Lightweight Proxy Models.CoRRabs/2603.15970 (2026). https://doi.org/10....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[6]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Im- ageNet: A large-scale hierarchical image database. In2009 IEEE Computer So- ciety Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20- 25 June 2009, Miami, Florida, USA. IEEE Computer Society, 248–255. https: //doi.org/10.1109/CVPR.2009.5206848
-
[7]
Alessio Devoto, Maximilian Jeblick, and Simon Jégou. 2025. Expected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribu- tion.CoRRabs/2510.00636 (2025). https://doi.org/10.48550/ARXIV.2510.00636 arXiv:2510.00636
-
[8]
Anas Dorbani, Sunny Yasser, Jimmy Lin, and Amine Mhedhbi. 2025. Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB.Proc. VLDB Endow.18, 12 (2025), 5415–5418. https://doi.org/10.14778/3750601.3750685
-
[9]
Uélison Jean Lopes dos Santos, Alessandro Ferri, Szilard Nistor, Riccardo Tom- masini, Carsten Binnig, and Manisha Luthra. 2026. Towards Multimodal Stream Processing Systems. InProceedings 29th International Conference on Extending Database Technology, EDBT 2026, Tampere, Finland, March 24-27, 2026, Wolf- gang Lehner, Vanessa Braganholo, Kostas Stefanidis...
-
[10]
Philippe Flajolet, Éric Fusy, Olivier Gandouet, and Frédéric Meunier. 2007. Hyper- loglog: the analysis of a near-optimal cardinality estimation algorithm.Discrete mathematics & theoretical computer scienceProceedings (2007)
2007
-
[11]
Benjamin Hilprecht, Andreas Schmidt, Moritz Kulessa, Alejandro Molina, Kris- tian Kersting, and Carsten Binnig. 2019. DeepDB: Learn from Data, not from Queries!CoRRabs/1909.00607 (2019). arXiv:1909.00607 http://arxiv.org/abs/ 1909.00607
arXiv 2019
-
[12]
Addison Howard, Eunbyung Park, and Wendy Kan. 2018. ImageNet Ob- ject Localization Challenge. https://kaggle.com/competitions/imagenet-object- localization-challenge. Kaggle
2018
-
[13]
Saehan Jo and Immanuel Trummer. 2024. ThalamusDB: Approximate Query Processing on Multi-Modal Data.Proc. ACM Manag. Data2, 3 (2024), 186. https: //doi.org/10.1145/3654989
-
[14]
Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Al- fons Kemper. 2019. Learned Cardinalities: Estimating Correlated Joins with Deep Learning. In9th Biennial Conference on Innovative Data Systems Re- search, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org. https://vldb.org/cidrdb/2019/learned-c...
2019
-
[15]
Jiale Lao, Andreas Zimmerer, Olga Ovcharenko, Tianji Cong, Matthew Russo, Gerardo Vitagliano, Michael Cochez, Fatma Özcan, Gautam Gupta, Thibaud Hot- telier, H. V. Jagadish, Kris Kissel, Sebastian Schelter, Andreas Kipf, and Immanuel Trummer. 2025. SemBench: A Benchmark for Semantic Query Processing En- gines.CoRRabs/2511.01716 (2025). https://doi.org/10....
-
[16]
Evergreen: Efficient Claim Verification for Semantic Aggregates
Alexander W. Lee, Benjamin Han, Shayak Sen, Samuel Yeom, Ugur Çetintemel, and Anupam Datta. 2026. Evergreen: Efficient Claim Verification for Semantic Aggregates.CoRRabs/2604.26180 (2026). https://doi.org/10.48550/ARXIV.2604. 26180 arXiv:2604.26180
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604 2026
-
[17]
Bo Li, Kaichen Zhang, Hao Zhang, Dong Guo, Renrui Zhang, Feng Li, Yuanhan Zhang, Ziwei Liu, and Chunyuan Li. 2024. LLaVA-NeXT: Stronger LLMs Super- charge Multimodal Capabilities in the Wild. https://llava-vl.github.io/blog/2024- 05-10-llava-next-stronger-llms/
2024
-
[18]
Zequn Li, Yuanhao Zhong, Chengliang Chai, Zhaoze Sun, Yuhao Deng, Ye Yuan, Guoren Wang, and Lei Cao. 2025. DocDB: A Database for Unstructured Document Analysis.Proc. VLDB Endow.18, 12 (2025), 5387–5390. https://doi.org/10.14778/ 3750601.3750678
arXiv 2025
-
[19]
Yiming Lin, Madelon Hulsebos, Ruiying Ma, Shreya Shankar, Sepanta Zeighami, Aditya G. Parameswaran, and Eugene Wu. 2024. Towards Accurate and Efficient Document Analytics with Large Language Models.CoRRabs/2405.04674 (2024). https://doi.org/10.48550/ARXIV.2405.04674 arXiv:2405.04674
-
[20]
Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael J
Chunwei Liu, Matthew Russo, Michael J. Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael J. Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. 2025. Palimpzest: Optimizing AI-Powered Analyt- ics with Declarative Query Processing. In15th Conference on Innovative Data Systems Research, CIDR 2025, Amsterdam, The Netherlands, Jan...
2025
-
[21]
https://vldb.org/cidrdb/2025/palimpzest-optimizing-ai- powered-analytics-with-declarative-query-processing.html
www.cidrdb.org. https://vldb.org/cidrdb/2025/palimpzest-optimizing-ai- powered-analytics-with-declarative-query-processing.html
2025
-
[22]
George A. Miller. 1995. WordNet: A Lexical Database for English.Commun. ACM38, 11 (1995), 39–41. https://doi.org/10.1145/219717.219748
-
[23]
Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia
Liana Patel, Siddharth Jha, Melissa Z. Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Towards AI-Based Data Analytics with Accuracy Guarantees.Proc. VLDB Endow. 18, 11 (2025), 4171–4184. https://doi.org/10.14778/3749646.3749685
-
[24]
Ioannidis, Peter J
Viswanath Poosala, Yannis E. Ioannidis, Peter J. Haas, and Eugene J. Shekita
-
[25]
Improved Histograms for Selectivity Estimation of Range Predicates. In Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data, Montreal, Quebec, Canada, June 4-6, 1996, H. V. Jagadish and Inderpal Singh Mumick (Eds.). ACM Press, 294–305. https://doi.org/10.1145/233269.233342
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Mod- els From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 Jul...
2021
-
[27]
Cafarella, Tim Kraska, and Samuel Madden
Matthew Russo, Chunwei Liu, Sivaprasad Sudhir, Gerardo Vitagliano, Michael J. Cafarella, Tim Kraska, and Samuel Madden. 2026. Abacus: A Cost-Based Opti- mizer for Semantic Operator Systems.Proc. VLDB Endow.19, 5 (2026), 1060–1073. https://www.vldb.org/pvldb/vol19/p1060-russo.pdf
2026
-
[28]
Gabriele Sanmartino, Matthias Urban, Paolo Papotti, and Carsten Binnig
-
[29]
The Stretto Execution Engine for LLM-Augmented Data Systems. CoRRabs/2602.04430 (2026). https://doi.org/10.48550/ARXIV.2602.04430 arXiv:2602.04430
-
[30]
Dario Satriani, Enzo Veltri, Donatello Santoro, Sara Rosato, Simone Varriale, and Paolo Papotti. 2025. Logical and Physical Optimizations for SQL Query Execution over Large Language Models.Proc. ACM Manag. Data3, 3 (2025), 181:1–181:28. https://doi.org/10.1145/3725411
-
[31]
Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, and Thomas G. Price. 1979. Access Path Selection in a Relational Database Management System. InProceedings of the 1979 ACM SIGMOD International Conference on Management of Data, Boston, Massachusetts, USA, May 30 - June 1, Philip A. Bernstein (Ed.). ACM, 23–34. https://doi.o...
-
[32]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9 (2025), 3035–3048. https: //doi.org/10.14778/3746405.3746426
-
[33]
Michael Tschannen, Alexey A. Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier J. Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. 2025. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.14786 2025
-
[34]
Matthias Urban and Carsten Binnig. 2024. CAESURA: Language Mod- els as Multi-Modal Query Planners. In14th Conference on Innovative Data Systems Research, CIDR 2024, Chaminade, HI, USA, January 14-17, 2024. www.cidrdb.org. https://vldb.org/cidrdb/2024/caesura-language-models-as- multi-modal-query-planners.html
2024
-
[35]
Jiayi Wang and Guoliang Li. 2025. AOP: Automated and Interactive LLM Pipeline Orchestration for Answering Complex Queries. In15th Conference on Innovative Data Systems Research, CIDR 2025, Amsterdam, The Netherlands, January 19- 22, 2025. www.cidrdb.org. https://vldb.org/cidrdb/2025/aop-automated-and- Matthias Urban, Vu Huy Nguyen, Gabriele Sanmartino, Pa...
2025
-
[36]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.CoRRabs/2409.12191 (2024). https:/...
Pith/arXiv arXiv 2024
-
[37]
Shihui Xu, Jiayi Wang, and Guoliang Li. 2026. Bridging the Gap: Cardinality Estimation for Semantic Queries on Unstructured Data.Proceedings of the ACM on Management of Data4, 3 (SIGMOD (2026), 1–26
2026
-
[38]
Hellerstein, Sanjay Krishnan, and Ion Stoica
Zongheng Yang, Eric Liang, Amog Kamsetty, Chenggang Wu, Yan Duan, Xi Chen, Pieter Abbeel, Joseph M. Hellerstein, Sanjay Krishnan, and Ion Stoica
-
[39]
VLDB Endow.13, 3 (2019), 279–292
Deep Unsupervised Cardinality Estimation.Proc. VLDB Endow.13, 3 (2019), 279–292. https://doi.org/10.14778/3368289.3368294
-
[40]
Sepanta Zeighami, Shreya Shankar, and Aditya G. Parameswaran. 2025. Cut Costs, Not Accuracy: LLM-Powered Data Processing with Guarantees.Proc. ACM Manag. Data3, 6 (2025), 1–26. https://doi.org/10.1145/3769776
-
[41]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid Loss for Language Image Pre-Training. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. IEEE, 11941–11952. https://doi.org/10.1109/ICCV51070.2023.01100
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.