ALINC: Active Learning for Inductive Node Classification via Graph Sampling
Pith reviewed 2026-06-28 07:05 UTC · model grok-4.3
The pith
ALINC selects entire graphs for annotation in inductive node classification by turning node utility scores into graph scores via aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
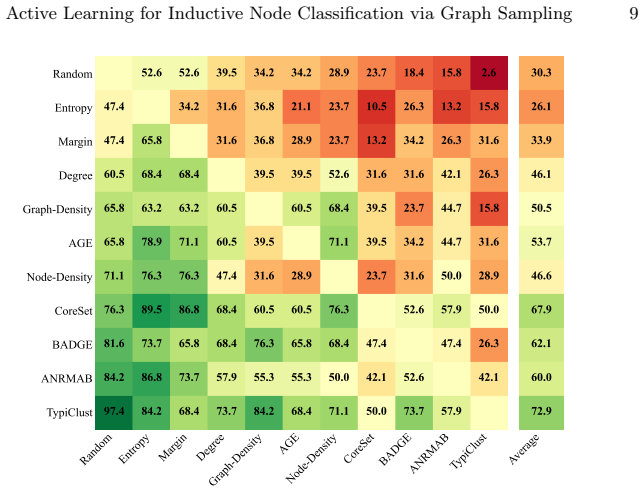
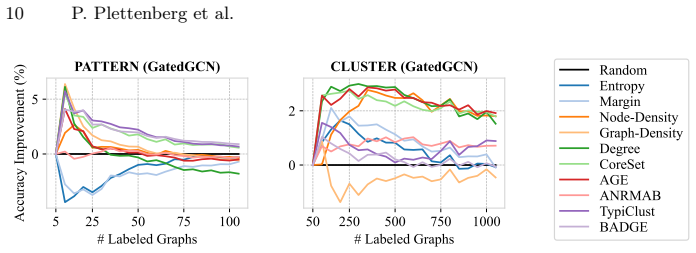
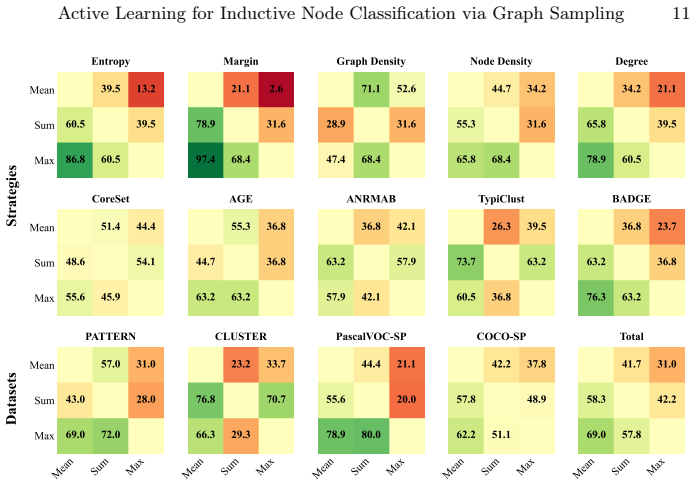
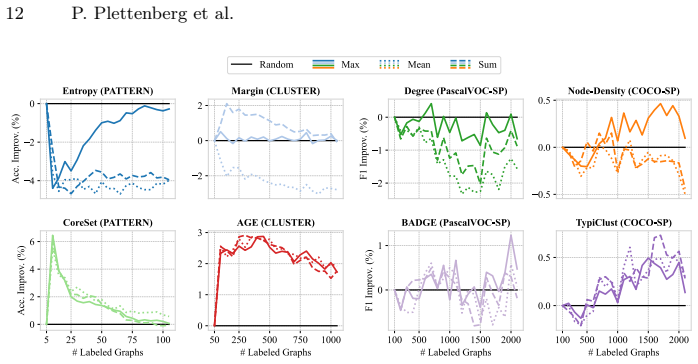
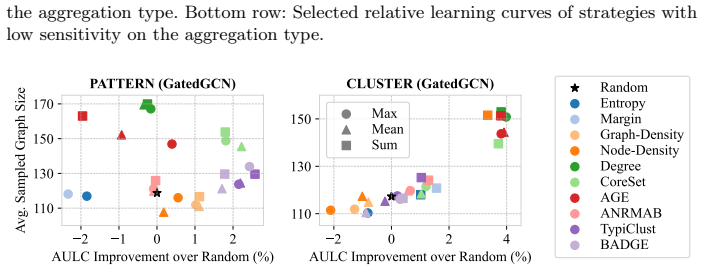
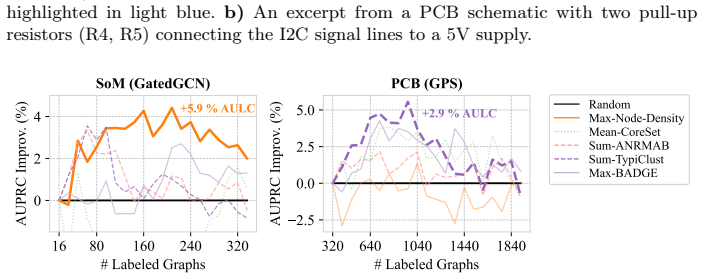
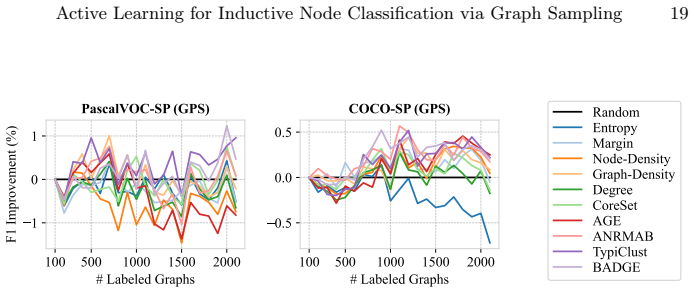
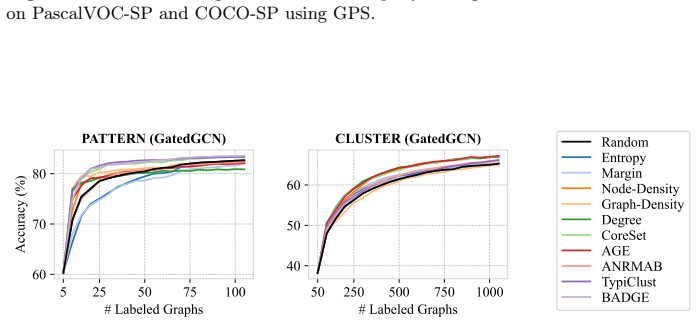
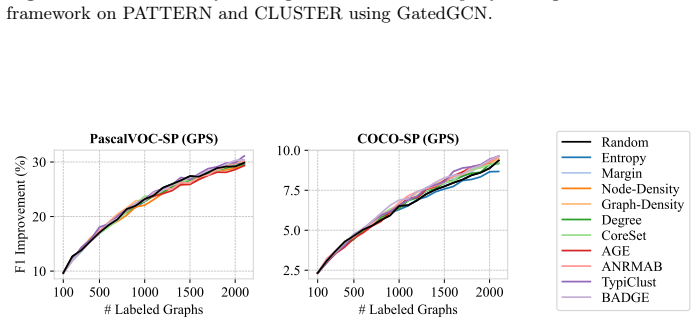
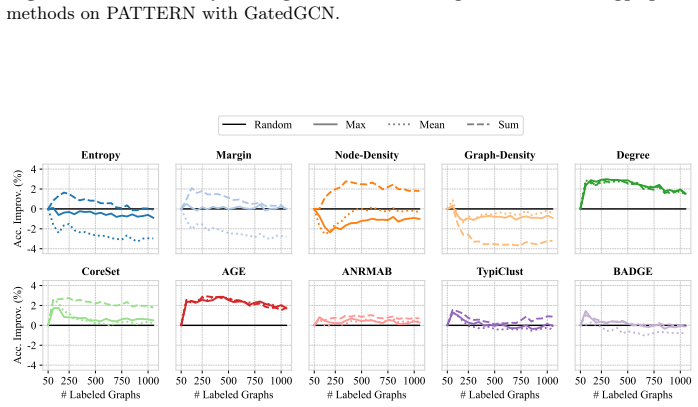
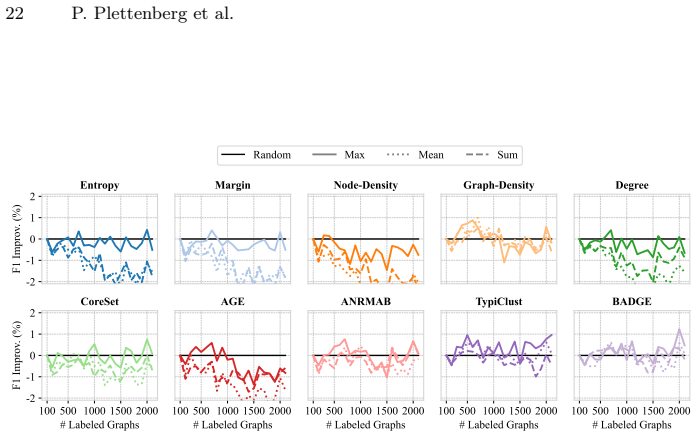
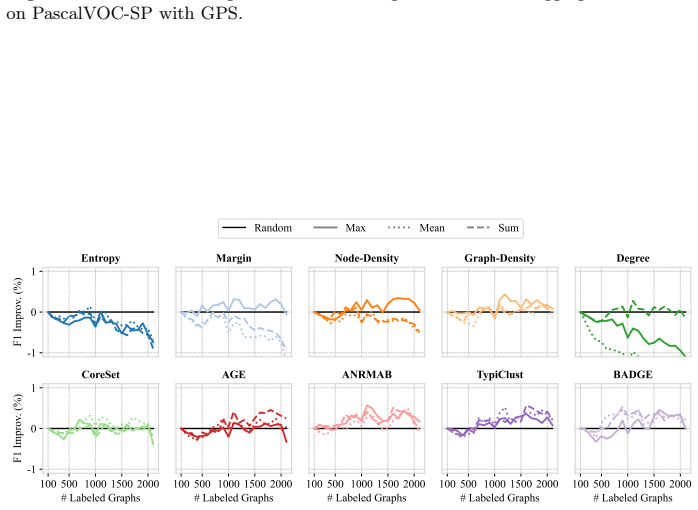
ALINC bridges the existing methodological gap by elevating node-level utility measures to graph-level selection criteria through various aggregation mechanisms. In an extensive benchmark including ten strategies, three aggregation methods, and four datasets, CoreSet, TypiClust, and BADGE are identified as the top-performing graph sampling strategies. The analysis reveals that the choice of aggregation method is pivotal because it substantially affects model performance and annotation costs. The framework is shown to be effective in two concrete use cases: site-of-metabolism prediction in molecules and design automation of printed circuit board schematics.
What carries the argument
Aggregation mechanisms that combine node-level utility scores into one graph-level selection score.
If this is right
- CoreSet, TypiClust, and BADGE become the leading strategies once node utilities are aggregated to the graph level.
- Switching the aggregation function can produce large swings in both final model accuracy and total annotation cost.
- The same graph-selection approach yields measurable gains on site-of-metabolism prediction tasks.
- The same graph-selection approach yields measurable gains on printed circuit board schematic design tasks.
Where Pith is reading between the lines
- The aggregation idea could be tested on other bundle-labeled domains such as protein complex prediction or scene graph annotation.
- Different graph sizes within one dataset may require size-aware aggregation to avoid bias toward larger graphs.
- Pairing the method with graph encoders that operate efficiently on small independent graphs could further lower labeling budgets.
Load-bearing premise
That annotating one node in a graph automatically supplies labels for every other node in the same graph.
What would settle it
A controlled experiment on a collection of independent graphs in which selecting and annotating individual nodes (without receiving the rest of the graph labels) produces higher accuracy at the same total annotation budget than any graph-level selection method.
Figures
read the original abstract
Active learning (AL) for node classification typically focuses on selecting the most informative nodes for annotation within one or a few large graphs (e.g., in social network analysis). However, in other domains, such as molecular chemistry or electronic design automation, datasets consist of thousands of independent graphs. In many of these inductive settings, annotating an individual node requires a full-graph analysis, which effectively yields the remaining node labels on-the-fly. Therefore, these scenarios require AL strategies that select entire graphs instead of single nodes, a problem which has not been tackled in the literature so far. Thus, we introduce ALINC, an AL framework for inductive node classification via graph sampling. It bridges the existing methodological gap by elevating node-level utility measures to graph-level selection criteria through various aggregation mechanisms. In an extensive benchmark including ten strategies, three aggregation methods, and four datasets, we identify CoreSet, TypiClust, and BADGE as the top-performing graph sampling strategies. Our detailed analysis further reveals that the choice of the aggregation method is pivotal, as it substantially affects model performance and annotation costs. Finally, we demonstrate the effectiveness of ALINC in two use case studies: site-of-metabolism prediction in molecules and design automation of printed circuit board schematics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ALINC, an active learning framework for inductive node classification on datasets of thousands of independent graphs (e.g., molecules, PCB schematics). It argues that annotating one node requires full-graph analysis that yields all node labels on-the-fly, necessitating selection of entire graphs rather than nodes; ALINC elevates node-level utilities (CoreSet, TypiClust, BADGE, etc.) to graph level via aggregation functions. An extensive benchmark with ten strategies, three aggregations, and four datasets identifies CoreSet, TypiClust, and BADGE as top performers, shows aggregation choice is pivotal, and demonstrates effectiveness in two use-case studies.
Significance. If the motivating premise holds, the work fills a genuine gap between standard node-level AL and multi-graph inductive settings, with the benchmark providing actionable guidance on strategy and aggregation selection. The identification of aggregation method as a first-order factor is a useful empirical contribution.
major comments (2)
- [Abstract / Introduction] Abstract (and presumably §1): The central premise that 'annotating an individual node requires a full-graph analysis, which effectively yields the remaining node labels on-the-fly' is asserted without citation, empirical support, or domain-specific argument. This premise is load-bearing for the claimed methodological gap; if annotation in the cited domains (site-of-metabolism, PCB design) does not automatically produce the full label set, existing node-level AL strategies remain directly applicable and the motivation for graph-level selection via aggregation collapses.
- [Abstract / Experiments] Benchmark description (abstract): The claim that CoreSet, TypiClust, and BADGE are the top-performing graph sampling strategies rests on an 'extensive benchmark' whose experimental controls, statistical reporting, multiple-run variance, and handling of post-hoc strategy selection are not verifiable from the provided text; without these details the ranking cannot be treated as robust.
minor comments (2)
- [Experiments] Clarify whether the four datasets are all multi-graph inductive collections or include single-graph transductive cases, and report per-dataset statistics (number of graphs, average nodes/edges).
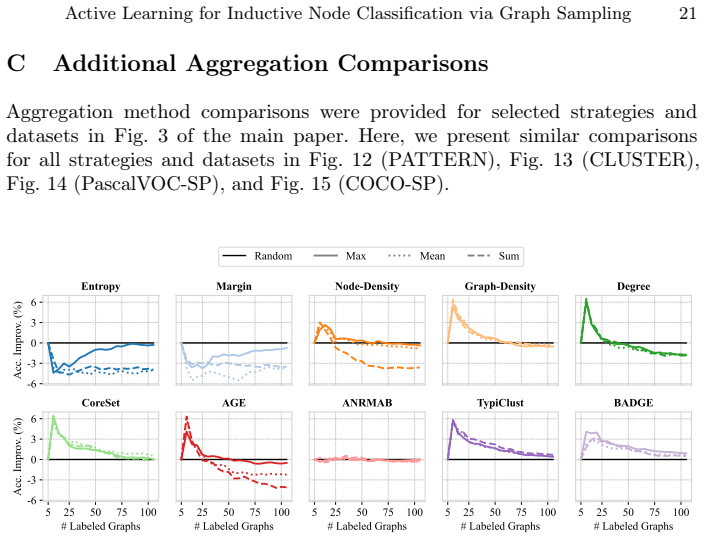
- [Method] The three aggregation mechanisms should be formally defined (e.g., mean, max, sum) with explicit equations rather than left as 'various aggregation mechanisms'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract / Introduction] Abstract (and presumably §1): The central premise that 'annotating an individual node requires a full-graph analysis, which effectively yields the remaining node labels on-the-fly' is asserted without citation, empirical support, or domain-specific argument. This premise is load-bearing for the claimed methodological gap; if annotation in the cited domains (site-of-metabolism, PCB design) does not automatically produce the full label set, existing node-level AL strategies remain directly applicable and the motivation for graph-level selection via aggregation collapses.
Authors: We agree that the premise requires stronger substantiation to support the claimed gap. While the manuscript is grounded in domain practices for the cited applications, we will revise the abstract and introduction to include domain-specific arguments and citations describing typical annotation workflows in molecular chemistry and PCB design. revision: yes
-
Referee: [Abstract / Experiments] Benchmark description (abstract): The claim that CoreSet, TypiClust, and BADGE are the top-performing graph sampling strategies rests on an 'extensive benchmark' whose experimental controls, statistical reporting, multiple-run variance, and handling of post-hoc strategy selection are not verifiable from the provided text; without these details the ranking cannot be treated as robust.
Authors: The full manuscript contains the experimental details on controls, variance across runs, and statistical reporting. To improve verifiability of the abstract claim, we will revise the abstract to briefly reference the robustness measures and direct readers to the experimental section for full controls and post-hoc handling. revision: partial
Circularity Check
Empirical benchmark study with no derivations or self-referential reductions
full rationale
The paper presents an empirical active learning benchmark for graph sampling in inductive node classification settings. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central methodological claim rests on a stated domain assumption about annotation costs rather than any reduction of outputs to inputs by construction. The work is self-contained as a comparative study of existing strategies (CoreSet, TypiClust, BADGE) under aggregation mechanisms, with no circular steps identified.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICLR (2021)
Alon, U., Yahav, E.: On the bottleneck of graph neural networks and its practical implications. In: ICLR (2021)
2021
-
[2]
In: ICLR (2020)
Ash, J.T., Zhang, C., Krishnamurthy, A., Langford, J., Agarwal, A.: Deep batch active learning by diverse, uncertain gradient lower bounds. In: ICLR (2020)
2020
-
[3]
Bemis, G.W., Murcko, M.A.: The properties of known drugs. 1. molecular frame- works. J. Med. Chem.39(15), 2887–2893 (1996)
1996
-
[4]
Bresson, X., Laurent, T.: Residual gated graph convnets. arXiv preprint arXiv:1711.07553 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Brody, S., Alon, U., Yahav, E.: How attentive are graph attention networks? In: ICLR (2022)
2022
-
[6]
In: VISIGRAPP (2019)
Brust, C.A., Käding, C., Denzler, J.: Active learning for deep object detection. In: VISIGRAPP (2019)
2019
-
[7]
Active Learning for Graph Embedding
Cai, H., Zheng, V.W., Chang, K.C.C.: Active learning for graph embedding. arXiv preprint arXiv:1705.05085 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
In: ICML (2022)
Chen, D., O’Bray, L., Borgwardt, K.: Structure-aware transformer for graph repre- sentation learning. In: ICML (2022)
2022
-
[9]
JCIM64(2), 348–358 (2024)
Chen, Y., Seidel, T., Jacob, R.A., Hirte, S., Mazzolari, A., Pedretti, A., Vistoli, G., Langer, T., Miljkovic, F., Kirchmair, J.: Active learning approach for guiding site-of-metabolism measurement and annotation. JCIM64(2), 348–358 (2024)
2024
-
[10]
JMLR24(43), 1–48 (2023)
Dwivedi, V.P., Joshi, C.K., Luu, A.T., Laurent, T., Bengio, Y., Bresson, X.: Bench- marking graph neural networks. JMLR24(43), 1–48 (2023)
2023
-
[11]
In: NeurIPS (2022)
Dwivedi, V.P., Rampášek, L., Galkin, M., Parviz, A., Wolf, G., Luu, A.T., Beaini, D.: Long range graph benchmark. In: NeurIPS (2022)
2022
-
[12]
In: ICML (2024)
Fuchsgruber, D., Wollschläger, T., Charpentier, B., Oroz, A., Günnemann, S.: Uncertainty for active learning on graphs. In: ICML (2024)
2024
-
[13]
In: IJCAI (2018)
Gao, L., Yang, H., Zhou, C., Wu, J., Pan, S., Hu, Y.: Active discriminative network representation learning. In: IJCAI (2018)
2018
-
[14]
In: ICML (2022)
Hacohen, G., Dekel, A., Weinshall, D.: Active learning on a budget: Opposite strategies suit high and low budgets. In: ICML (2022)
2022
-
[15]
In: NeurIPS (2017) 16 P
Hamilton, W., Ying, Z., Leskovec, J.: Inductive representation learning on large graphs. In: NeurIPS (2017) 16 P. Plettenberg et al
2017
-
[16]
In: NeurIPS (2020)
Hu, S., Xiong, Z., Qu, M., Yuan, X., Côté, M.A., Liu, Z., Tang, J.: Graph policy network for transferable active learning on graphs. In: NeurIPS (2020)
2020
-
[17]
In: NeurIPS (2020)
Hu, W., Fey, M., Zitnik, M., Dong, Y., Ren, H., Liu, B., Catasta, M., Leskovec, J.: Open graph benchmark: Datasets for machine learning on graphs. In: NeurIPS (2020)
2020
-
[18]
In: ICLR (2019)
Hu, W., Liu, B., Gomes, J., Zitnik, M., Liang, P., Pande, V., Leskovec, J.: Strategies for pre-training graph neural networks. In: ICLR (2019)
2019
-
[19]
In: ECML PKDD (2024)
Huseljic, D., Hahn, P., Herde, M., Rauch, L., Sick, B.: Fast fishing: Approximating bait for efficient and scalable deep active image classification. In: ECML PKDD (2024)
2024
-
[20]
In: IAL @ ECML PKDD
Huseljic, D., Herde, M., Hahn, P., Sick, B.: Role of hyperparameters in deep active learning. In: IAL @ ECML PKDD. pp. 19–24 (2023)
2023
-
[21]
In: CVPR (2026)
Huseljic, D., Herde, M., Rauch, L., Hahn, P., Sick, B.: Cleaning the pool: Progressive filtering of unlabeled pools in deep active learning. In: CVPR (2026)
2026
-
[22]
In: ICLR (2017)
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. In: ICLR (2017)
2017
-
[23]
Expert Opin
Litsa, E.E., Das, P., Kavraki, L.E.: Machine learning models in the prediction of drug metabolism: challenges and future perspectives. Expert Opin. Drug Metab. Toxicol.17(11), 1245–1247 (2021)
2021
-
[24]
TMLR (2023)
Ma, J., Ma, Z., Chai, J., Mei, Q.: Partition-based active learning for graph neural networks. TMLR (2023)
2023
-
[25]
In: ICLR (2020)
Oono, K., Suzuki, T.: Graph neural networks exponentially lose expressive power for node classification. In: ICLR (2020)
2020
-
[26]
In: ECML PKDD (2025)
Plettenberg, P., Alcalde, A., Sick, B., Thomas, J.M.: Graph neural networks for automatic addition of optimizing components in printed circuit board schematics. In: ECML PKDD (2025)
2025
-
[27]
TMLR (2025)
Plettenberg, P., Köhler, D., Sick, B., Thomas, J.M.: Flow-attentional graph neural networks. TMLR (2025)
2025
-
[28]
In: NeurIPS (2022)
Rampášek, L., Galkin, M., Dwivedi, V.P., Luu, A.T., Wolf, G., Beaini, D.: Recipe for a general, powerful, scalable graph transformer. In: NeurIPS (2022)
2022
-
[29]
In: ECML PKDD (2023)
Rauch, L., Aßenmacher, M., Huseljic, D., Wirth, M., Bischl, B., Sick, B.: Activeglae: A benchmark for deep active learning with transformers. In: ECML PKDD (2023)
2023
-
[30]
Reiser, P., Neubert, M., Eberhard, A., Torresi, L., Zhou, C., Shao, C., Metni, H., van Hoesel, C., Schopmans, H., Sommer, T., et al.: Graph neural networks for materials science and chemistry. Commun. Mater.3(1), 93 (2022)
2022
-
[31]
KBS 21(7), 727–739 (2008)
Rodriguez, M.A.: Grammar-based random walkers in semantic networks. KBS 21(7), 727–739 (2008)
2008
-
[32]
In: BMVC (2018)
Roy, S., Unmesh, A., Namboodiri, V.P.: Deep active learning for object detection. In: BMVC (2018)
2018
-
[33]
In: ICLR (2018)
Sener, O., Savarese, S.: Active learning for convolutional neural networks: A core-set approach. In: ICLR (2018)
2018
-
[34]
Technical Report, University of Wisconsin-Madison, Department of Computer Sciences (2009)
Settles, B.: Active learning literature survey. Technical Report, University of Wisconsin-Madison, Department of Computer Sciences (2009)
2009
-
[35]
In: ICML (2023)
Shirzad, H., Velingker, A., Venkatachalam, B., Sutherland, D.J., Sinop, A.K.: Exphormer: Sparse transformers for graphs. In: ICML (2023)
2023
-
[36]
JCIM59(8), 3400–3412 (2019)
Sicho, M., Stork, C., Mazzolari, A., de Bruyn Kops, C., Pedretti, A., Testa, B., Vistoli, G., Svozil, D., Kirchmair, J.: Fame 3: predicting the sites of metabolism in synthetic compounds and natural products for phase 1 and phase 2 metabolic enzymes. JCIM59(8), 3400–3412 (2019)
2019
-
[37]
In: NeurIPS (2023) Active Learning for Inductive Node Classification via Graph Sampling 17
Song,Z.,Zhang,Y.,King,I.:Nochange,nogain:Empoweringgraphneuralnetworks with expected model change maximization for active learning. In: NeurIPS (2023) Active Learning for Inductive Node Classification via Graph Sampling 17
2023
-
[38]
TMLR (2024)
Tönshoff, J., Ritzert, M., Rosenbluth, E., Grohe, M.: Where did the gap go? reassessing the long-range graph benchmark. TMLR (2024)
2024
-
[39]
In: ICLR (2018)
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y.: Graph attention networks. In: ICLR (2018)
2018
-
[40]
NeurIPS33, 5776–5788 (2020)
Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., Zhou, M.: Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers. NeurIPS33, 5776–5788 (2020)
2020
-
[41]
arXiv preprint arXiv:1910.07567 (2019)
Wu, Y., Xu, Y., Singh, A., Yang, Y., Dubrawski, A.: Active learning for graph neural networks via node feature propagation. arXiv preprint arXiv:1910.07567 (2019)
-
[42]
IEEE TBD8(4), 920–932 (2022)
Xie, Y., Lv, S., Qian, Y., Wen, C., Liang, J.: Active and semi-supervised graph neural networks for graph classification. IEEE TBD8(4), 920–932 (2022)
2022
-
[43]
Xu, K., Hu, W., Leskovec, J., Jegelka, S.: How powerful are graph neural networks? In: ICLR (2019)
2019
-
[44]
Ying, C., Cai, T., Luo, S., Zheng, S., Ke, G., He, D., Shen, Y., Liu, T.Y.: Do transformers really perform badly for graph representation? In: NeurIPS (2021)
2021
-
[45]
JCIM53(12), 3373–3383 (2013)
Zaretzki, J., Matlock, M., Swamidass, S.J.: Xenosite: accurately predicting cyp- mediated sites of metabolism with neural networks. JCIM53(12), 3373–3383 (2013)
2013
-
[46]
In: ICLR (2022)
Zhang, W., Wang, Y., You, Z., Cao, M., Huang, P., Shan, J., Yang, Z., Cui, B.: Information gain propagation: a new way to graph active learning with soft labels. In: ICLR (2022)
2022
-
[47]
In: VLDB (2021) 18 P
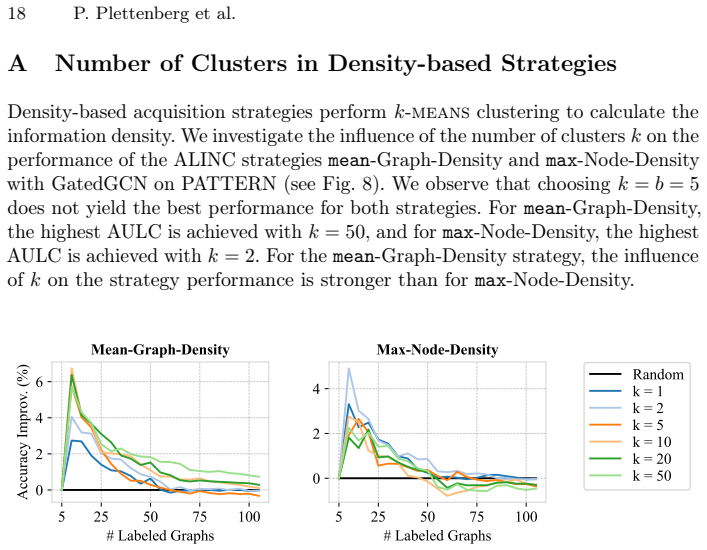
Zhang, W., Yang, Z., Wang, Y., Shen, Y., Li, Y., Wang, L., Cui, B.: Grain: Improving data efficiency of graph neural networks via diversified influence maximization. In: VLDB (2021) 18 P. Plettenberg et al. A Number of Clusters in Density-based Strategies Density-based acquisition strategies performk-meansclustering to calculate the information density. W...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.