Test-Time Compute Scaling for ASR with Depth-Conditioned Looped Transformers
Pith reviewed 2026-06-28 06:55 UTC · model grok-4.3
The pith
LARM structures a shared Transformer encoder into loops that improve ASR word error rates as inference depth increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
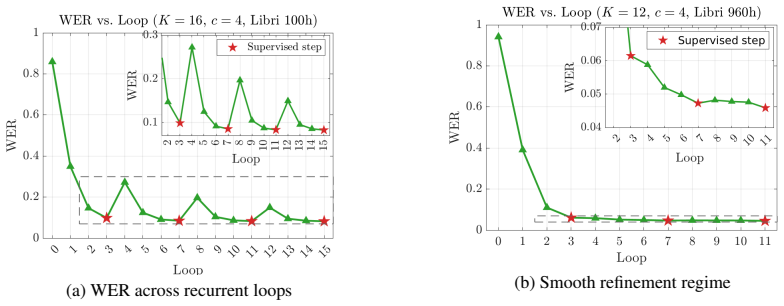
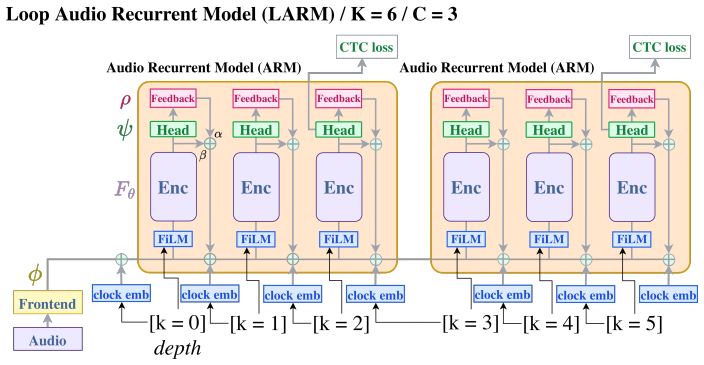
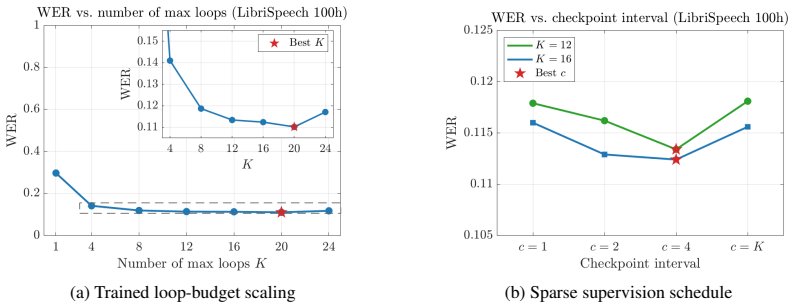
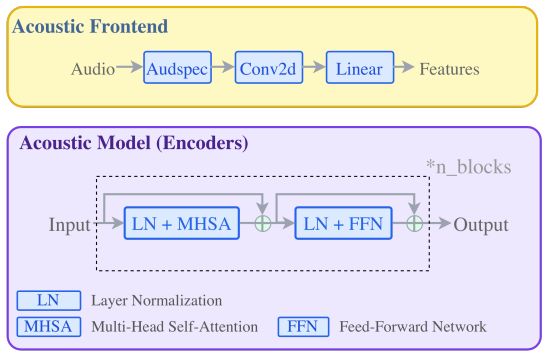
LARM is a depth-conditioned looped Transformer that turns recurrent encoder depth into a controllable test-time compute axis. By combining sparse CTC checkpoints, supervision-clock embeddings, FiLM depth conditioning, and delayed soft-posterior feedback, the architecture structures the loop into recognition checkpoints separated by latent refinement phases and lets shared weights specialize across recurrent steps. On LibriSpeech this produces steadily improving word error rates as the number of inference loops grows, reaching performance competitive with deeper unshared-parameter baselines and showing that test-time compute scaling extends to continuous non-autoregressive speech recognition.
What carries the argument
LARM, the depth-conditioned looped Transformer whose components structure recurrent steps into recognition checkpoints and latent refinement phases.
If this is right
- Word error rate on LibriSpeech decreases as the number of LARM inference loops is increased.
- LARM performance becomes competitive with deeper Transformer encoders that do not share parameters.
- Test-time compute scaling applies to continuous non-autoregressive speech recognition in addition to autoregressive language-model reasoning.
Where Pith is reading between the lines
- Training one moderate-size model and then varying loop count at inference could replace the need to train and store multiple model sizes.
- The same conditioning pattern might let other sequence models trade recurrent depth for accuracy in tasks where output is produced in parallel rather than token by token.
Load-bearing premise
The listed conditioning components together cause shared weights to specialize usefully across recurrent steps instead of simply repeating the same computation.
What would settle it
An experiment on LibriSpeech in which increasing the number of LARM inference loops produces no further WER reduction or fails to match the accuracy of a deeper unshared encoder of comparable total compute.
Figures
read the original abstract
End-to-end ASR systems typically use fixed-depth acoustic encoders at inference, making it difficult to trade additional test-time computation for improved recognition without training a larger model. A natural approach is to reuse a shared Transformer block recurrently, but we find that naive looping does not fully exploit additional recurrent compute. We introduce LARM, a depth-conditioned looped Transformer that turns recurrent encoder depth into a controllable test-time compute axis. LARM combines sparse CTC checkpoints, supervision-clock embeddings, FiLM depth conditioning, and delayed soft-posterior feedback. These components structure the loop into recognition checkpoints separated by latent refinement phases and allow shared weights to specialize across recurrent steps. On LibriSpeech, LARM improves WER as the number of inference loops increases and achieves performance competitive with deeper unshared-parameter baselines. Our results show that test-time compute scaling can extend beyond autoregressive language-model reasoning to continuous non-autoregressive speech recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LARM, a depth-conditioned looped Transformer for end-to-end ASR. It reuses shared Transformer blocks recurrently at inference and combines sparse CTC checkpoints, supervision-clock embeddings, FiLM depth conditioning, and delayed soft-posterior feedback to structure the loop into recognition checkpoints separated by latent refinement phases. This allows shared weights to specialize across steps. On LibriSpeech, LARM shows WER decreasing as the number of inference loops increases and reaches performance competitive with deeper unshared-parameter baselines, demonstrating test-time compute scaling for non-autoregressive continuous recognition.
Significance. If the reported WER trends hold under detailed ablations and controls, the result is significant because it supplies an explicit, controllable test-time compute axis for fixed-parameter ASR encoders, extending scaling ideas from autoregressive language models to continuous non-autoregressive tasks. The empirical demonstration on a standard benchmark (LibriSpeech) with a concrete mechanism for specialization is a clear strength.
minor comments (3)
- [Abstract, §3] Abstract and §3: the claim that 'naive looping does not fully exploit additional recurrent compute' is stated without a quantitative comparison (e.g., WER vs. loop count for a plain recurrent baseline); adding this control would strengthen the motivation for the four proposed components.
- [§4] §4 (experimental setup): no mention of number of random seeds, error bars, or statistical significance for the WER curves; including these would make the scaling claim more robust.
- [§2.2] Notation in §2.2: the definition and injection point of 'supervision-clock embeddings' and the precise form of the 'delayed soft-posterior feedback' are described at a high level; a short equation or diagram would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the assessment of its significance for test-time compute scaling in non-autoregressive ASR, and the recommendation for minor revision. The referee's description of LARM accurately captures the proposed mechanism and empirical results on LibriSpeech.
Circularity Check
No significant circularity; empirical results on LibriSpeech
full rationale
The paper presents an empirical architecture (LARM) and measures its WER on LibriSpeech as a function of inference loops. No equations, predictions, or uniqueness theorems are claimed; the central result is a direct experimental comparison against deeper baselines. The listed components (sparse CTC, FiLM, etc.) are design choices whose effect is measured rather than derived by construction from the same data. No self-citation chain or fitted-input-as-prediction pattern appears in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer blocks can be weight-shared and executed recurrently while remaining trainable.
invented entities (1)
-
LARM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Looped transformers as programmable computers
Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. InProc. of International Conference on Machine Learning, pages 11398–11442, 2023
2023
-
[5]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Mask CTC: Non-Autoregressive End-to-End ASR with CTC and Mask Predict
Yosuke Higuchi, Shinji Watanabe, Nanxin Chen, Tetsuji Ogawa, and Tetsunori Kobayashi. Mask CTC: Non-Autoregressive End-to-End ASR with CTC and Mask Predict. InProc. of Interspeech 2020, pages 3655–3659, 2020
2020
-
[7]
Align-refine: Non-autoregressive speech recognition via iterative realignment
Ethan A Chi, Julian Salazar, and Katrin Kirchhoff. Align-refine: Non-autoregressive speech recognition via iterative realignment. InProc. of North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1920–1927, 2021
1920
-
[8]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProc. of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[9]
Librispeech: An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An ASR corpus based on public domain audio books. InProc. of the IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015
2015
-
[10]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute op- timally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. OpenAI o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProc. of Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
2025
-
[13]
Self-Refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-Refine: Iterative refinement with self-feedback. InProc. of Advances in neural information processing systems, volume 36, pages 46534–46594, 2023. 10
2023
-
[14]
arXiv preprint arXiv:2310.02226 , year =
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226, 2023
-
[15]
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-STaR:: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Jacob Pfau, William Merrill, and Samuel R Bowman. Let’s think dot by dot: Hidden computation in transformer language models.arXiv preprint arXiv:2404.15758, 2024
-
[17]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite BERT for self-supervised learning of language representations.arXiv preprint arXiv:1909.11942, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[18]
Deep equilibrium models
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. InProc. of Advances in Neural Information Processing Systems, volume 32, 2019
2019
-
[19]
On the Turing Completeness of Modern Neural Network Architectures
Jorge Pérez, Javier Marinkovi ´c, and Pablo Barceló. On the turing completeness of modern neural network architectures.arXiv preprint arXiv:1901.03429, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[20]
Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks
Avi Schwarzschild, Eitan Borgnia, Arjun Gupta, Furong Huang, Uzi Vishkin, Micah Goldblum, and Tom Goldstein. Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks. InProc. of Advances in Neural Information Processing Systems, volume 34, pages 6695–6706, 2021
2021
-
[21]
Im- puter: Sequence modelling via imputation and dynamic programming
William Chan, Chitwan Saharia, Geoffrey Hinton, Mohammad Norouzi, and Navdeep Jaitly. Im- puter: Sequence modelling via imputation and dynamic programming. InProc. of International Conference on Machine Learning, pages 1403–1413. PMLR, 2020
2020
-
[22]
Hierarchical multitask learning with CTC
Ramon Sanabria and Florian Metze. Hierarchical multitask learning with CTC. InProc. of IEEE Spoken Language Technology Workshop (SLT), pages 485–490. IEEE, 2018
2018
-
[23]
arXiv preprint arXiv:2104.02724 , year=
Jumon Nozaki and Tatsuya Komatsu. Relaxing the conditional independence assumption of CTC-based ASR by conditioning on intermediate predictions.arXiv preprint arXiv:2104.02724, 2021
-
[24]
Better Intermediates Improve CTC Inference
Tatsuya Komatsu, Yusuke Fujita, Jaesong Lee, Lukas Lee, Shinji Watanabe, and Yusuke Kida. Better Intermediates Improve CTC Inference. InProc. of Interspeech 2022, pages 4965–4969, 2022
2022
-
[25]
Non-autoregressive ASR with self-conditioned folded encoders
Tatsuya Komatsu. Non-autoregressive ASR with self-conditioned folded encoders. InProc. of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7427–7431, 2022
2022
-
[26]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProc. of Interna- tional Conference on Learning Representations, 2019
2019
-
[27]
Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D
Daniel S. Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, and Quoc V . Le. SpecAugment: A simple data augmentation method for automatic speech recognition. InProc. of Interspeech 2019, pages 2613–2617, 2019
2019
-
[28]
KenLM: Faster and smaller language model queries
Kenneth Heafield. KenLM: Faster and smaller language model queries. InProc. of the Sixth Workshop on Statistical Machine Translation, pages 187–197, July 2011. 11 A Additional Architectural Details A.1 CTC Prediction Head The CTC prediction head ψ is implemented as a linear projection from the hidden dimension d to the output vocabularyV: ℓ(k) =ψ(z (k)) =...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.