SMADE-IE: Sparse Multi-Agent Framework with Evidence-Driven Debate for Zero-Shot Information Extraction
Pith reviewed 2026-06-28 06:33 UTC · model grok-4.3
The pith
SMADE-IE routes inputs adaptively between global and type-centric modes then resolves agent conflicts with evidence-scored debate to raise zero-shot IE accuracy and cut token use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
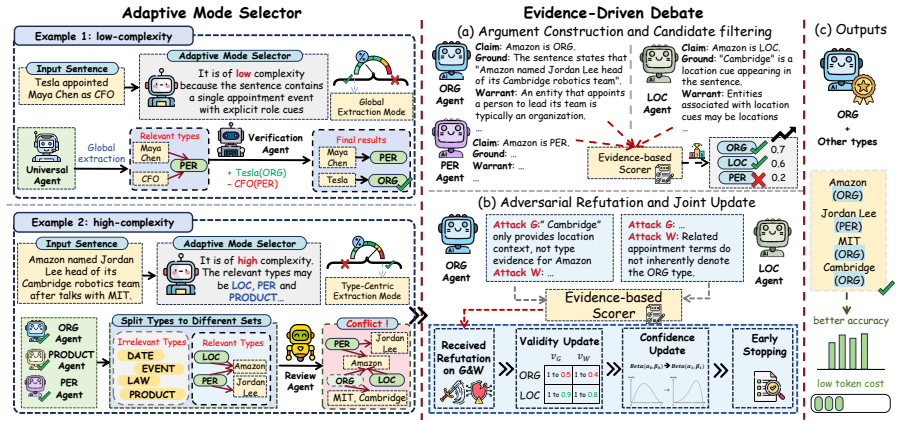
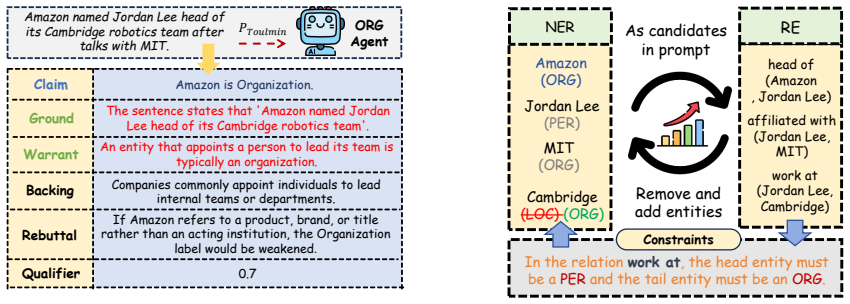
SMADE-IE first employs an Adaptive Mode Selector to dynamically route inputs into either a lightweight Global Extraction Mode or a Type-Centric Extraction Mode, reducing unnecessary type selection and reasoning noise; for conflicting predictions it introduces an Evidence-Driven Debate mechanism that structures arguments into Toulmin-style components and performs confidence aggregation through external evidence scoring and Bayesian updates.
What carries the argument
Adaptive Mode Selector that chooses between Global Extraction Mode and Type-Centric Extraction Mode, combined with Evidence-Driven Debate that structures arguments in Toulmin style and aggregates confidence via external evidence scoring plus Bayesian updates.
If this is right
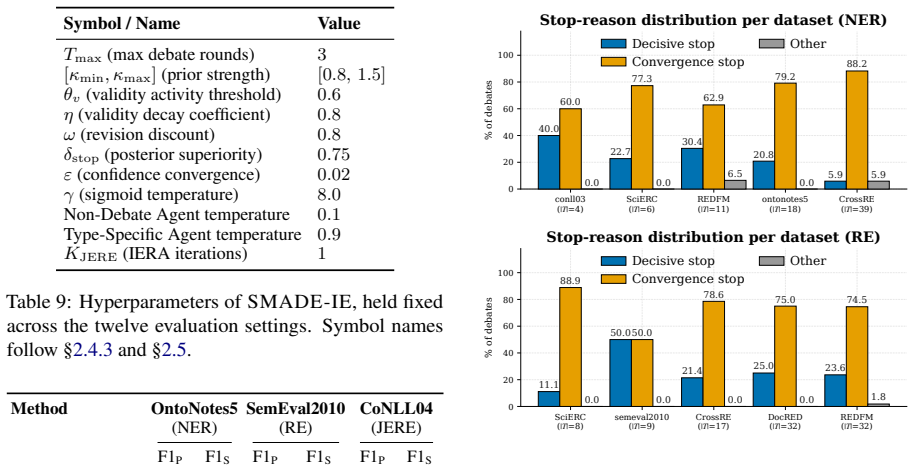
- SMADE-IE consistently outperforms existing zero-shot IE baselines on 9 benchmark datasets across NER, RE, and JERE tasks.
- Token efficiency improves through sparse agent selection and early-stopping debate.
- Boundary and type errors from monolithic prompting and cross-type conflicts from each-type prompting are reduced.
- The framework preserves flexibility for new schemas and domains without task-specific training.
Where Pith is reading between the lines
- If mode selection proves reliable it could be applied to other multi-agent LLM workflows to limit unnecessary reasoning steps.
- The dependence on external evidence points to possible gains from pairing the debate step with retrieval modules.
- Early stopping during debate may transfer to additional multi-agent settings where token budgets are tight.
Load-bearing premise
The Adaptive Mode Selector can correctly choose between Global Extraction Mode and Type-Centric Extraction Mode without introducing new boundary or type errors, and external evidence scoring plus Bayesian updates will reliably resolve cross-type conflicts.
What would settle it
On a new test set the mode selector's choices produce more missed entities or incorrect types than always using one fixed mode, or debate performance remains unchanged when external evidence scoring is removed.
Figures

read the original abstract
Zero-shot information extraction (IE) with large language models (LLMs) has attracted increasing attention due to its flexibility in adapting to new schemas and domains without task-specific training. Existing approaches mainly rely on monolithic prompting, each-type prompting, or multi-agent debate. However, monolithic prompting often suffers from boundary and type errors, while each-type prompting and multi-agent debate introduce cross-type conflicts, redundant agent interactions, and substantial token overhead. To address these challenges, we propose SMADE-IE, a sparse and evidence-driven multi-agent framework for zero-shot IE. SMADE-IE first employs an Adaptive Mode Selector to dynamically route inputs into either a lightweight Global Extraction Mode or a Type-Centric Extraction Mode, reducing unnecessary type selection and reasoning noise. For conflicting predictions, we further introduce an Evidence-Driven Debate mechanism that structures arguments into Toulmin-style components and performs confidence aggregation through external evidence scoring and Bayesian updates. Experimental results on 9 benchmark datasets across NER, RE, and JERE tasks show that SMADE-IE consistently outperforms existing zero-shot IE baselines while also improving token efficiency through sparse agent selection and early-stopping debate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SMADE-IE, a sparse multi-agent framework for zero-shot information extraction. It introduces an Adaptive Mode Selector that dynamically routes inputs to either a lightweight Global Extraction Mode or a Type-Centric Extraction Mode, and an Evidence-Driven Debate mechanism that structures arguments in Toulmin style, scores external evidence, and aggregates via Bayesian updates to resolve conflicts. The central claim is that this yields consistent outperformance over existing zero-shot IE baselines (monolithic prompting, each-type prompting, multi-agent debate) on 9 benchmark datasets spanning NER, RE, and JERE tasks, together with token savings from sparse agent selection and early-stopping debate.
Significance. If the empirical results hold after proper validation, the work offers a practical engineering advance for zero-shot IE by targeting specific error modes (boundary/type errors and cross-type conflicts) while controlling token cost. The combination of mode selection and structured Bayesian debate is a concrete contribution that could be adopted in other multi-agent LLM pipelines for structured prediction tasks.
major comments (3)
- [§3.1] §3.1 (Adaptive Mode Selector): The claim that the selector routes to Global vs. Type-Centric mode without introducing new boundary or type errors is load-bearing for the outperformance result, yet no ablation that compares the selector against always-Global and always-Type-Centric baselines on the same LLM outputs is reported; without this, gains could be artifacts of prompt templates rather than the routing mechanism.
- [§3.2] §3.2 (Evidence-Driven Debate): The assertion that Toulmin-structured arguments plus external-evidence scoring and Bayesian updates reliably resolve cross-type conflicts (vs. monolithic or standard multi-agent debate) is central to the token-efficiency and accuracy claims, but the manuscript provides no ablation that isolates the Bayesian update or the Toulmin components from simpler conflict-resolution heuristics.
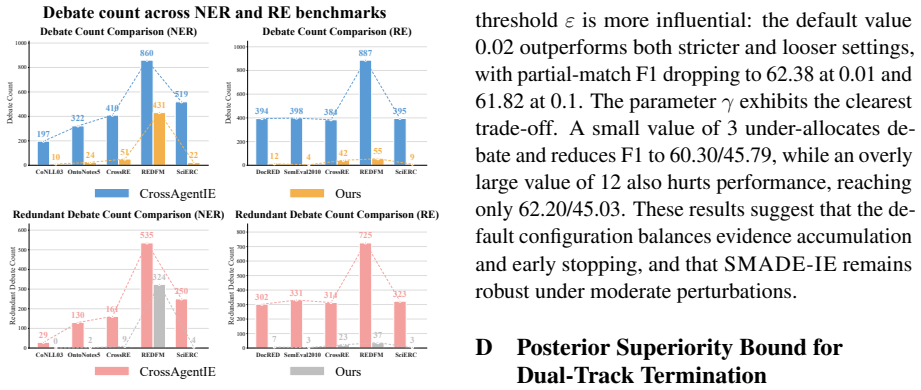
- [§4] §4 (Experimental Results): The headline statement of “consistent outperformance” and token savings on nine datasets requires tables that report per-task F1 (or equivalent), standard deviations across runs, statistical significance tests, and an error breakdown (boundary vs. type vs. conflict errors); the abstract supplies none of these, and the absence of such detail makes it impossible to verify whether the two premises actually hold on the LLM outputs.
minor comments (2)
- [Figure 1] The framework diagram (Figure 1) should explicitly annotate the Bayesian update step and the early-stopping criterion for clarity.
- [Appendix] Prompt templates for the Toulmin components and the mode selector should be placed in an appendix to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that additional ablations and expanded experimental reporting are needed to strengthen the claims. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Adaptive Mode Selector): The claim that the selector routes to Global vs. Type-Centric mode without introducing new boundary or type errors is load-bearing for the outperformance result, yet no ablation that compares the selector against always-Global and always-Type-Centric baselines on the same LLM outputs is reported; without this, gains could be artifacts of prompt templates rather than the routing mechanism.
Authors: We agree that an ablation isolating the routing mechanism is required. In the revision we will add a controlled comparison of the Adaptive Mode Selector against fixed always-Global and always-Type-Centric baselines, using identical LLM back-ends and prompt templates so that any performance difference can be attributed to the selector itself. revision: yes
-
Referee: [§3.2] §3.2 (Evidence-Driven Debate): The assertion that Toulmin-structured arguments plus external-evidence scoring and Bayesian updates reliably resolve cross-type conflicts (vs. monolithic or standard multi-agent debate) is central to the token-efficiency and accuracy claims, but the manuscript provides no ablation that isolates the Bayesian update or the Toulmin components from simpler conflict-resolution heuristics.
Authors: We acknowledge the value of component-level ablations. The revised manuscript will include variants that replace the Toulmin structure with simpler argument formats and replace the Bayesian update with majority voting or simple averaging, allowing direct measurement of each component's contribution to conflict resolution and token savings. revision: yes
-
Referee: [§4] §4 (Experimental Results): The headline statement of “consistent outperformance” and token savings on nine datasets requires tables that report per-task F1 (or equivalent), standard deviations across runs, statistical significance tests, and an error breakdown (boundary vs. type vs. conflict errors); the abstract supplies none of these, and the absence of such detail makes it impossible to verify whether the two premises actually hold on the LLM outputs.
Authors: We will expand Section 4 with per-task F1 tables that include standard deviations over multiple runs, statistical significance tests (paired t-tests and McNemar’s test), and a quantitative error breakdown by boundary, type, and conflict categories. The abstract will be updated to summarize these metrics and the observed improvements. revision: yes
Circularity Check
No significant circularity; empirical framework with independent experimental validation.
full rationale
The paper introduces SMADE-IE as an engineering framework for zero-shot IE, using an Adaptive Mode Selector and Evidence-Driven Debate mechanism, validated through experiments on 9 benchmark datasets. No equations, fitted parameters renamed as predictions, or derivation chains appear in the text. Claims of outperformance rest on empirical results rather than any self-referential mathematical reduction or load-bearing self-citation. The design choices are presented as novel contributions tested externally, making the central results self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Elisa Bassignana and Barbara Plank. 2022. CrossRE : A cross-domain dataset for relation extraction. In Findings of the EMNLP 2022, pages 3592--3604
2022
-
[2]
Zhijun Chen, Hailong Sun, Wanhao Zhang, Chunyi Xu, Qianren Mao, and Pengpeng Chen. 2023. Neural-hidden-crf: A robust weakly-supervised sequence labeler. In Proceedings of the ACM SIGKDD 2023, page 274–285. ACM
2023
-
[3]
Hyeong Kyu Choi, Jerry Zhu, and Sharon Li. 2026. Debate or vote: Which yields better decisions in multi-agent large language models? In Proceedings of the NIPS 2026
2026
-
[4]
Wei Fan, JinYi Yoon, and Bo Ji. 2026. imad: Intelligent multi-agent debate for efficient and accurate llm inference. Proceedings of the AAAI 2026, 40(35):29403–29411
2026
-
[5]
Neil De La Fuente, Oscar Sainz, Iker Garc \'i a-Ferrero, and Eneko Agirre. 2025. GUIDEX : Guided synthetic data generation for zero-shot information extraction. In Findings of the ACL 2025, pages 24248--24262
2025
-
[6]
Chufan Gao, Xulin Fan, Jimeng Sun, and Xuan Wang. 2024. P rompt RE : Weakly-supervised document-level relation extraction via prompting-based data programming. In Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024), pages 132--145
2024
-
[7]
Yong Guan, Hao Peng, Lei Hou, and Juanzi Li. 2025. MMD - ERE : Multi-agent multi-sided debate for event relation extraction. In Proceedings of the COLING 2025, pages 6889--6896
2025
-
[8]
Ankita Gupta, Ethan Zuckerman, and Brendan O ' Connor. 2024. Harnessing toulmin ' s theory for zero-shot argument explication. In Proceedings of the ACL 2024, pages 10259--10276
2024
- [9]
-
[10]
Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid \'O S \'e aghdha, Sebastian Pad \'o , Marco Pennacchiotti, Lorenza Romano, and Stan Szpakowicz. 2010. S em E val-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. In Proceedings of the 5th International Workshop on Semantic Evaluation, pages 33--38
2010
-
[11]
Tianyu Hu, Zhen Tan, Song Wang, Huaizhi Qu, and Tianlong Chen. 2025. Multi-agent debate for llm judges with adaptive stability detection. In Advances in Neural Information Processing Systems, pages 46504--46540
2025
-
[12]
Pere-Llu \'i s Huguet Cabot, Simone Tedeschi, Axel-Cyrille Ngonga Ngomo, and Roberto Navigli. 2023. RED ^ fm : A filtered and multilingual relation extraction dataset. In Proceedings of the ACL 2023, pages 4326--4343
2023
-
[13]
Nitisha Jain. 2020. Domain-specific knowledge graph construction for semantic analysis. In Proceedings of the Semantic Web: ESWC 2020, pages 250--260
2020
-
[14]
Nanda Kambhatla. 2004. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL) Companion Volume, pages 22--25
2004
-
[15]
Lafferty, Andrew McCallum, and Fernando C
John D. Lafferty, Andrew McCallum, and Fernando C. N. Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML), pages 282--289
2001
-
[16]
Guozheng Li, Peng Wang, and Wenjun Ke. 2023 a . Revisiting large language models as zero-shot relation extractors. In Findings of the EMNLP 2023, pages 6877--6892
2023
-
[17]
Yinghao Li, Colin Lockard, Prashant Shiralkar, and Chao Zhang. 2023 b . Extracting shopping interest-related product types from the web. In Findings of the ACL 2023, pages 7509--7525
2023
-
[18]
Yinghao Li, Rampi Ramprasad, and Chao Zhang. 2024. A simple but effective approach to improve structured language model output for information extraction. In Findings of the EMNLP 2024, pages 5133--5148
2024
-
[19]
Yinghao Li, Le Song, and Chao Zhang. 2022. Sparse conditional hidden markov model for weakly supervised named entity recognition. In Proceedings of the ACM SIGKDD 2022, page 978–988
2022
-
[20]
Pierre Lison, Jeremy Barnes, and Aliaksandr Hubin. 2021. skweak: Weak supervision made easy for nlp. In Proceedings of the ACL 2021, page 337–346
2021
-
[21]
Jian Liu, Yubo Chen, Kang Liu, Wei Bi, and Xiaojiang Liu. 2020. Event extraction as machine reading comprehension. In Proceedings of the EMNLP 2020, pages 1641--1651
2020
-
[22]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157--173
2024
-
[23]
Jie Lou, Yaojie Lu, Dai Dai, Wei Jia, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. 2023. Universal information extraction as unified semantic matching. In Proceedings of the AAAI 2023, pages 13318--13326
2023
-
[24]
Meng Lu, Yuzhang Xie, Zhenyu Bi, Shuxiang Cao, and Xuan Wang. 2025. CrossAgentIE : Cross-type and cross-task multi-agent LLM collaboration for zero-shot information extraction. In Findings of the ACL 2025, pages 13953--13977
2025
-
[25]
Yaojie Lu, Qing Liu, Dai Dai, Xinyan Xiao, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. 2022. Unified structure generation for universal information extraction. In Proceedings of the ACL 2022, pages 5755--5772
2022
-
[26]
Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi. 2018. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Proceedings of the EMNLP 2018, pages 3219--3232
2018
-
[27]
Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Ningyu Zhang, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, and 1 others. 2025. Oneke: A dockerized schema-guided llm agent-based knowledge extraction system. In Companion Proceedings of the ACM WWW 2025, pages 2871--2874
2025
-
[28]
Pranav Mahajan, Ihor Kendiukhov, Syed Hussain, and Lydia Nottingham. 2026. https://arxiv.org/abs/2601.21975 Mind the gap: How elicitation protocols shape the stated-revealed preference gap in language models . Preprint, arXiv:2601.21975
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Andrew McCallum and Wei Li. 2003. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural Language Learning (CoNLL), pages 188--191
2003
-
[30]
Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Hwee Tou Ng, Anders Bj \"o rkelund, Olga Uryupina, Yuchen Zhang, and Zhi Zhong. 2013. Towards robust linguistic analysis using O nto N otes. In Proceedings of the CoNLL 2013, pages 143--152
2013
-
[31]
Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In Proceedings of the ECML-PKDD 2010, pages 148--163
2010
-
[32]
Bryan Rink and Sanda Harabagiu. 2010. UTD : Classifying semantic relations by combining machine learning and rich linguistic features. In Proceedings of the 5th International Workshop on Semantic Evaluation (SemEval), pages 256--259
2010
-
[33]
Dan Roth and Wen-tau Yih. 2004. A linear programming formulation for global inference in natural language tasks. In Proceedings of the NAACL 2004, pages 1--8
2004
-
[34]
Oscar Sainz, Iker Garc \' a-Ferrero, Rodrigo Agerri, Oier Lacalle, German Rigau, and Eneko Agirre. 2024. Gollie: Annotation guidelines improve zero-shot information-extraction. In Proceedings of the ICLR 2024, pages 47083--47107
2024
-
[35]
Chi, Nathanael Sch\" a rli, and Denny Zhou
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Sch\" a rli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In Proceedings of the ICML 2023, pages 31210--31227
2023
-
[36]
Yuchen Shi, Guochao Jiang, Tian Qiu, and Deqing Yang. 2024. Agentre: An agent-based framework for navigating complex information landscapes in relation extraction. In Proceedings of the ACM CIKM 2024, page 2045–2055
2024
-
[37]
Hongduan Tian, Xiao Feng, Rolan Yan, Bo Han, and 1 others. 2026. Multi-agent debate with memory masking. In The Fourteenth International Conference on Learning Representations
2026
-
[38]
Tjong Kim Sang and Fien De Meulder
Erik F. Tjong Kim Sang and Fien De Meulder. 2003. Introduction to the C o NLL -2003 shared task: Language-independent named entity recognition. In Proceedings of the NAACL 2003, pages 142--147
2003
-
[39]
Sijia Wang and Lifu Huang. 2024. Debate as optimization: Adaptive conformal prediction and diverse retrieval for event extraction. In Findings of the EMNLP 2024, pages 16422--16435
2024
-
[40]
Zihan Wang, Ziqi Zhao, Yougang Lyu, Zhumin Chen, Maarten de Rijke, and Zhaochun Ren. 2025. A cooperative multi-agent framework for zero-shot named entity recognition. In Proceedings of the WWW 2025, pages 4183--4195
2025
-
[41]
Ruiyu Xiao, Lei Wu, Yuhang Gou, Weinan Zhang, and Ting Liu. 2024. Prove your point!: Bringing proof-enhancement principles to argumentative essay generation. In EMNLP 2024, pages 18995--19008
2024
-
[42]
Tingyu Xie, Qi Li, Jian Zhang, Yan Zhang, Zuozhu Liu, and Hongwei Wang. 2023. Empirical study of zero-shot NER with C hat GPT . In Proceedings of the EMNLP 2023, pages 7935--7956
2023
-
[43]
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, and Enhong Chen. 2024. Large language models for generative information extraction: A survey. Frontiers of Computer Science, 18(6):186357
2024
-
[44]
Minglai Yang, Ethan Huang, Liang Zhang, Mihai Surdeanu, William Yang Wang, and Liangming Pan. 2025. How is llm reasoning distracted by irrelevant context? an analysis using a controlled benchmark. In Proceedings of the EMNLP 2025, pages 13340--13358
2025
-
[45]
Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, and Maosong Sun. 2019. D oc RED : A large-scale document-level relation extraction dataset. In Proceedings of the ACL 2019, pages 764--777
2019
-
[46]
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, pages 2335--2344
2014
-
[47]
Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. 2023. A lign S core: Evaluating factual consistency with a unified alignment function. In Proceedings of the ACL 2023, pages 11328--11348
2023
-
[48]
Duzhen Zhang, Zhong-Zhi Li, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Xiuyi Chen, Yingying Zhang, and 1 others. 2025 a . From system 1 to system 2: A survey of reasoning large language models. IEEE Transactions on Pattern Analysis and Machine Intelligence
2025
-
[49]
Zikang Zhang, Wangjie You, Tianci Wu, Xinrui Wang, Juntao Li, and Min Zhang. 2025 b . A survey of generative information extraction. In Proceedings of the COLING 2025, pages 4840--4870
2025
-
[50]
Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu. 2017. Joint extraction of entities and relations based on a novel tagging scheme. In Proceedings of the ACL 2017, pages 1227--1236
2017
-
[51]
Information Extraction: A Multidisciplinary Approach to an Emerging Information Technology , year =
Grishman, Ralph , title =. Information Extraction: A Multidisciplinary Approach to an Emerging Information Technology , year =
-
[52]
Extracting Shopping Interest-Related Product Types from the Web
Li, Yinghao and Lockard, Colin and Shiralkar, Prashant and Zhang, Chao. Extracting Shopping Interest-Related Product Types from the Web. Findings of the ACL 2023. 2023
2023
-
[53]
Unified Structure Generation for Universal Information Extraction
Lu, Yaojie and Liu, Qing and Dai, Dai and Xiao, Xinyan and Lin, Hongyu and Han, Xianpei and Sun, Le and Wu, Hua. Unified Structure Generation for Universal Information Extraction. Proceedings of the ACL 2022. 2022
2022
-
[54]
Proceedings of the AAAI 2023 , pages=
Universal information extraction as unified semantic matching , author=. Proceedings of the AAAI 2023 , pages=
2023
-
[55]
2023 , eprint=
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction , author=. 2023 , eprint=
2023
-
[56]
Proceedings of the ICLR 2024 , pages=
Gollie: Annotation guidelines improve zero-shot information-extraction , author=. Proceedings of the ICLR 2024 , pages=
2024
-
[57]
GUIDEX : Guided Synthetic Data Generation for Zero-Shot Information Extraction
Fuente, Neil De La and Sainz, Oscar and Garc \'i a-Ferrero, Iker and Agirre, Eneko. GUIDEX : Guided Synthetic Data Generation for Zero-Shot Information Extraction. Findings of the ACL 2025. 2025
2025
-
[58]
Frontiers of Computer Science , volume=
Large language models for generative information extraction: A survey , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[59]
2024 , eprint=
ChatIE: Zero-Shot Information Extraction via Chatting with ChatGPT , author=. 2024 , eprint=
2024
-
[60]
Revisiting Large Language Models as Zero-shot Relation Extractors
Li, Guozheng and Wang, Peng and Ke, Wenjun. Revisiting Large Language Models as Zero-shot Relation Extractors. Findings of the EMNLP 2023. 2023
2023
-
[61]
Empirical Study of Zero-Shot NER with C hat GPT
Xie, Tingyu and Li, Qi and Zhang, Jian and Zhang, Yan and Liu, Zuozhu and Wang, Hongwei. Empirical Study of Zero-Shot NER with C hat GPT. Proceedings of the EMNLP 2023. 2023
2023
-
[62]
MMD - ERE : Multi-Agent Multi-Sided Debate for Event Relation Extraction
Guan, Yong and Peng, Hao and Hou, Lei and Li, Juanzi. MMD - ERE : Multi-Agent Multi-Sided Debate for Event Relation Extraction. Proceedings of the COLING 2025. 2025
2025
-
[63]
Proceedings of the AAAI 2026 , author=
iMAD: Intelligent Multi-Agent Debate for Efficient and Accurate LLM Inference , volume=. Proceedings of the AAAI 2026 , author=. 2026 , pages=
2026
-
[64]
Proceedings of the ICML 2023 , pages =
Large Language Models Can Be Easily Distracted by Irrelevant Context , author =. Proceedings of the ICML 2023 , pages =
2023
-
[65]
Proceedings of the EMNLP 2025 , pages=
How is llm reasoning distracted by irrelevant context? an analysis using a controlled benchmark , author=. Proceedings of the EMNLP 2025 , pages=
2025
-
[66]
The Fourteenth International Conference on Learning Representations , year=
Multi-Agent Debate with Memory Masking , author=. The Fourteenth International Conference on Learning Representations , year=
-
[67]
Proceedings of the NIPS 2026 , year=
Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models? , author=. Proceedings of the NIPS 2026 , year=
2026
-
[68]
Relation Classification via Convolutional Deep Neural Network
Zeng, Daojian and Liu, Kang and Lai, Siwei and Zhou, Guangyou and Zhao, Jun. Relation Classification via Convolutional Deep Neural Network. Proceedings of the COLING 2014. 2014
2014
-
[69]
2015 , eprint=
Bidirectional LSTM-CRF Models for Sequence Tagging , author=. 2015 , eprint=
2015
-
[70]
Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
Zheng, Suncong and Wang, Feng and Bao, Hongyun and Hao, Yuexing and Zhou, Peng and Xu, Bo. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. Proceedings of the ACL 2017. 2017
2017
-
[71]
2024 , eprint=
YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction , author=. 2024 , eprint=
2024
-
[72]
Proceedings of the ICLR 2024 , volume=
Gollie: Annotation guidelines improve zero-shot information-extraction , author=. Proceedings of the ICLR 2024 , volume=
2024
-
[73]
Denoising Multi-Source Weak Supervision for Neural Text Classification
Ren, Wendi and Li, Yinghao and Su, Hanting and Kartchner, David and Mitchell, Cassie and Zhang, Chao. Denoising Multi-Source Weak Supervision for Neural Text Classification. Findings of EMNLP 2020. 2020
2020
-
[74]
BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision , booktitle=
Liang, Chen and Yu, Yue and Jiang, Haoming and Er, Siawpeng and Wang, Ruijia and Zhao, Tuo and Zhang, Chao , year=. BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision , booktitle=
-
[75]
skweak: Weak Supervision Made Easy for NLP
Lison, Pierre and Barnes, Jeremy and Hubin, Aliaksandr. skweak: Weak Supervision Made Easy for NLP. Proceedings of the ACL 2021. 2021
2021
-
[76]
Sparse Conditional Hidden Markov Model for Weakly Supervised Named Entity Recognition , booktitle=
Li, Yinghao and Song, Le and Zhang, Chao , year=. Sparse Conditional Hidden Markov Model for Weakly Supervised Named Entity Recognition , booktitle=
-
[77]
Neural-Hidden-CRF: A Robust Weakly-Supervised Sequence Labeler , booktitle=
Chen, Zhijun and Sun, Hailong and Zhang, Wanhao and Xu, Chunyi and Mao, Qianren and Chen, Pengpeng , year=. Neural-Hidden-CRF: A Robust Weakly-Supervised Sequence Labeler , booktitle=
-
[78]
P rompt RE : Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming
Gao, Chufan and Fan, Xulin and Sun, Jimeng and Wang, Xuan. P rompt RE : Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming. Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024). 2024
2024
-
[79]
skweak: Weak Supervision Made Easy for NLP , booktitle=
Lison, Pierre and Barnes, Jeremy and Hubin, Aliaksandr , year=. skweak: Weak Supervision Made Easy for NLP , booktitle=
-
[80]
A Survey of Generative Information Extraction
Zhang, Zikang and You, Wangjie and Wu, Tianci and Wang, Xinrui and Li, Juntao and Zhang, Min. A Survey of Generative Information Extraction. Proceedings of the COLING 2025. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.