Archi: Agentic Operations at the CMS Experiment
Pith reviewed 2026-06-28 03:19 UTC · model grok-4.3
The pith
Archi deploys private agents that integrate CMS documentation, historical data, and live monitoring to answer real operator queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
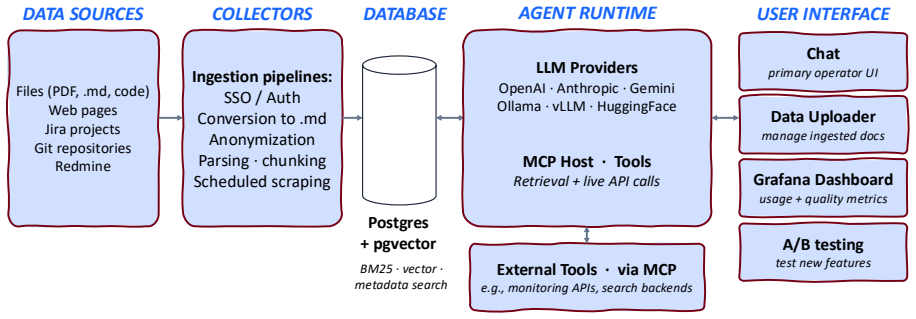
Archi is an end-to-end framework for scientific collaborations that performs systematic ingestion and organization of heterogeneous data sources and then deploys configurable, private, extensible agents that retrieve and reason over the organized data; the CMS deployment demonstrates that such agents resolve real-world operational queries posed by computing operators.
What carries the argument
Archi, the framework that ingests heterogeneous data sources and deploys configurable private agents to retrieve and reason over them.
If this is right
- Operators gain a single interface that surfaces answers from documentation, logs, and live systems without manual searching.
- Sensitive collaboration data can remain under local control when open-weight models are used.
- The same ingestion-plus-agent pattern can be replicated in other scientific computing teams that manage heterogeneous records.
Where Pith is reading between the lines
- The approach may shorten the time between an operator encountering an issue and obtaining a usable diagnosis.
- Extending the ingested sources to include more real-time streams could further reduce reliance on human memory during shifts.
- Similar agent setups could be tested on other LHC experiments to check whether the effectiveness observed at CMS generalizes.
Load-bearing premise
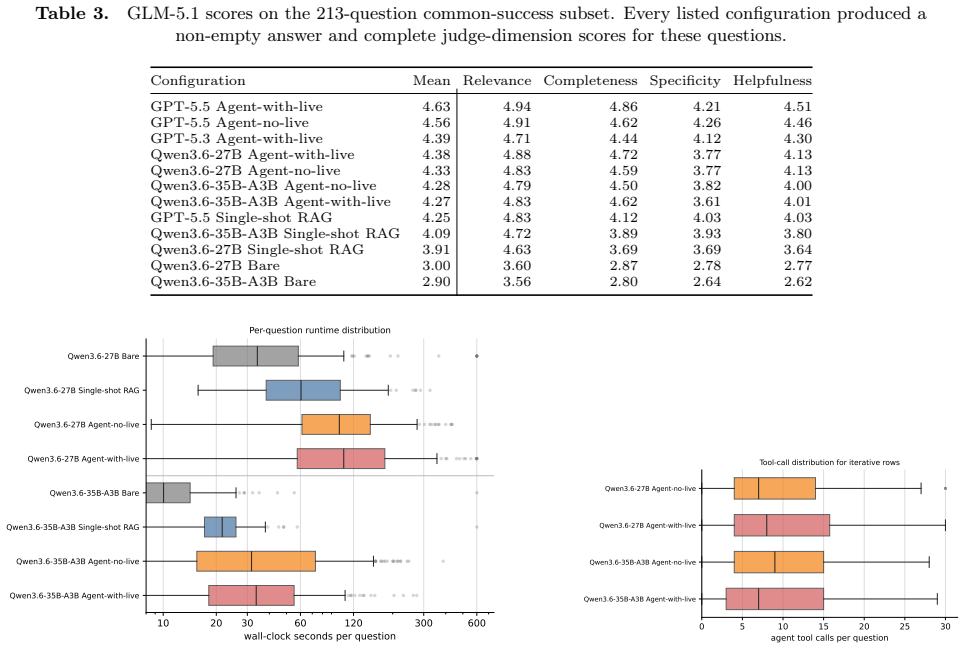
The question set drawn from actual production use and graded by mixed human-automated panels gives an unbiased measure of operational effectiveness.
What would settle it
A collection of live CMS operator queries on which the deployed Archi instance returns incorrect, incomplete, or unhelpful answers despite the relevant data being present in the ingested sources.
Figures

read the original abstract
We present Archi, an open-source, end-to-end framework for scientific collaborations that combines the systematic ingestion and organization of heterogeneous data sources with the deployment of configurable, private, and extensible agents that retrieve and reason over them. An instance of Archi has been deployed for the Computing Operations team of the CMS experiment at CERN's LHC since February 2026 as a support agent for technical operators, offering retrieval and analysis capabilities by combining documentation, historical data, and live monitoring systems. We evaluate the system on operator feedback and a question set collected from production usage, graded by human and automated panels. The system proves effective at operational tasks, resolving real-world queries posed by CMS operators. We also observe that locally-hosted, open-weight models perform competitively, enabling fully private management of sensitive data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Archi, an open-source framework that ingests heterogeneous data sources and deploys configurable, private agents for retrieval and reasoning in scientific collaborations. It reports deployment of an instance at the CMS Computing Operations team since February 2026, where the agent combines documentation, historical data, and live monitoring to support technical operators. The central claim is that the system proves effective at operational tasks, based on evaluation using operator feedback and a question set collected from production usage and graded by human and automated panels; it also notes competitive performance from locally-hosted open-weight models.
Significance. If the evaluation methodology and quantitative results were provided, a documented, open-source deployment of an agentic system in a major HEP experiment's operations could be of practical significance for improving efficiency in large-scale scientific infrastructure and could serve as a template for other collaborations. The focus on fully private, locally-hosted models addresses data-sensitivity concerns relevant to the field.
major comments (2)
- [Abstract] Abstract: the claim that the system 'proves effective at operational tasks, resolving real-world queries' is unsupported by any quantitative metrics, baselines, error rates, or description of the question-set sampling procedure, exclusion criteria, or grading instructions given to the human and automated panels.
- [Evaluation] Evaluation description (wherever presented): no information is supplied on how the production question set was collected, whether it is representative, inter-rater reliability of the panels, or any tabulated scores that would allow verification of the effectiveness statement.
minor comments (2)
- The deployment date of February 2026 is in the future relative to the manuscript's arXiv identifier; clarify whether this is a planned date, a typographical error, or requires updating.
- [Abstract] The abstract refers to 'operator feedback' without indicating whether this is quantitative (e.g., satisfaction scores) or merely anecdotal.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the evaluation methodology. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the system 'proves effective at operational tasks, resolving real-world queries' is unsupported by any quantitative metrics, baselines, error rates, or description of the question-set sampling procedure, exclusion criteria, or grading instructions given to the human and automated panels.
Authors: We agree the abstract claim would be strengthened by supporting details. The manuscript describes evaluation on operator feedback and a production question set graded by human and automated panels. We will revise the abstract to reference key quantitative outcomes and evaluation approach, and expand the main text with sampling procedure, exclusion criteria, and grading instructions. revision: yes
-
Referee: [Evaluation] Evaluation description (wherever presented): no information is supplied on how the production question set was collected, whether it is representative, inter-rater reliability of the panels, or any tabulated scores that would allow verification of the effectiveness statement.
Authors: The manuscript provides a high-level description of the evaluation using operator feedback and the production question set. We acknowledge the need for additional specifics on collection, representativeness, inter-rater reliability, and tabulated scores. We will revise the evaluation section to include these details and any available quantitative metrics to support verification. revision: yes
Circularity Check
No circularity: empirical deployment report with external evaluation
full rationale
The paper describes deployment of an agent framework and reports effectiveness based on production usage questions graded by panels. No equations, fitted parameters, predictions, or derivations appear. Evaluation uses external operator feedback and collected questions without any self-referential reduction to inputs by construction. The central claim is an empirical observation, not a derived result that collapses to its own data or citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. Hou, Y. Zhao, S. Wang, H. Wang, ACM Trans. Softw. Eng. Methodol. (2026), just Ac- cepted
2026
-
[2]
com/langchain-ai/langgraph (2026)
LangChain Authors,LangGraph, https://github. com/langchain-ai/langgraph (2026)
2026
-
[3]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, Y. Cao,React: Synergiz- ing reasoning and acting in language models (2023),2210.03629,https://arxiv.org/abs/ 2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
M. Honnibal, I. Montani, S. Van Landeghem, A.Boyd,spaCy: Industrial-strength Natural Lan- guage Processing in Python(2020),https:// doi.org/10.5281/zenodo.1212303
-
[5]
web.cern.ch(2026)
CMS Collaboration,CMS computing operations: Mission and structure,https://cms-compops. web.cern.ch(2026)
2026
-
[6]
com/dmwm/WMCore(2026)
CMS Collaboration,WMCore: CMS work- load management software,https://github. com/dmwm/WMCore(2026)
2026
-
[7]
Öztürk, P
H. Öztürk, P. Paparrigopoulos, A. Man- rique Ardila, R. Chauhan, K. Ellis, C. Em- manouil, D. Kovalskyi, E. Vaandering, M. Voet- berg, A. Wightman,Recent Experience with the CMS Data Management System, inEPJ Web of Conferences (CHEP 2025)(2025), p. 01151
2025
-
[8]
Bird, Annual Review of Nuclear and Particle Science61, 99 (2011)
I. Bird, Annual Review of Nuclear and Particle Science61, 99 (2011)
2011
-
[9]
Any Data, Any Time, Anywhere: Global Data Access for Science
K. Bloom, T. Boccali, B. Bockelman, D. Bradley, S. Dasu, J. Dost, F. Fanzago, I. Sfiligoi, A.M. Tadel, M. Tadel et al.,Any data, any time, anywhere: Global data access for science (2015),1508.01443,https://arxiv.org/abs/ 1508.01443
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Barisits et al., Computing and Software for Big Science3, 11 (2019)
M. Barisits et al., Computing and Software for Big Science3, 11 (2019)
2019
-
[11]
Murray, M
S. Murray, M. Patrascoiu, L. Mascetti, J.P. Lopes, S. Misra, E. Silva Junior, EPJ Web of Conferences295, 01031 (2024)
2024
-
[12]
Bockelman, M
B. Bockelman, M. Livny, B. Lin, F. Prelz, Jour- nal of Computational Science52, 101213 (2021), case Studies in Translational Computer Science
2021
-
[13]
Aimar, A
A. Aimar, A. Aguado Corman, P. Andrade, S. Belov, B. Garrido Bear, J. Delgado Fer- nanFdez, A. Fiorot, M. Georgiou, E. Karavakis etal.,Unified Monitoring Architecture for IT and Grid Services, inJ. Phys.: Conf. Ser.(2017), Vol. 898, p. 092033
2017
-
[14]
The Cognition Team,DeepWiki: AI docs for any repo,https://cognition.ai/blog/ deepwiki(2025), accessed: 2026-05-25
2025
-
[15]
F. Rehm, G. Guerrieri, M. Guijarro, S. Val- lecorsa, V. Kain,AccGPT: A CERN Knowledge Retrieval Chatbot, inEPJ Web of Conferences (2025), Vol. 337, p. 01279
2025
-
[16]
Beringer, D
J. Beringer, D. Dal Santo, G. Egan, A.A. Elliot, G. Facini, D. Murnane, S. Van Stroud, B. So- pio, A. Couthures, X. Li et al.,chATLAS: An AI assistant for the ATLAS collaboration, ATL- SOFT-SLIDE-2025-250 (2025)
2025
-
[17]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. tau Yih, T. Rocktäschel et al.,Retrieval- Augmented Generation for Knowledge-Intensive NLP Tasks(2021),2005.11401,https:// arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, H. Wang (2024), 2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [19]
- [20]
-
[21]
I don't have access to look that up
M. Mascheroni, J. Balcas, S. Belforte, B.P. Bock- elman, J.M. Hernández, D. Ciangottini, P.B. Konstantinov, J.M.D. Silva, M.A.B.M. Ali, A.M. Melo et al., Journal of Physics: Conference Series 664, 062038 (2015), accessed: 2026-06-01 A Automated Judge Prompt The four-judge panel and the source-free GLM-5.1 judge use the reference-free prompt below, repro- ...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.