Provably Reduced Sample Cost in Prior-Guided Hyperparameter Optimization
Pith reviewed 2026-06-28 07:38 UTC · model grok-4.3
The pith
Informative priors concentrating probability mass on near-optimal arms reduce the evaluations needed in multi-fidelity hyperparameter optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling priors directly over arm means as configuration performance within the fixed-budget best-arm identification framework, we derive explicit distribution-dependent error bounds that quantify the relationship between prior informativeness and evaluation budget. Our analysis shows that informative priors, which concentrate probability mass on near-optimal arms, yield reductions in the number of required evaluations, whereas baseline performance is recovered with uninformative or misleading priors.
What carries the argument
Fixed-budget best-arm identification framework with priors modeled over arm means, yielding distribution-dependent sample complexity bounds.
If this is right
- Informative priors reduce the number of evaluations required for multi-fidelity HPO.
- Uninformative or misleading priors produce no improvement and recover baseline performance.
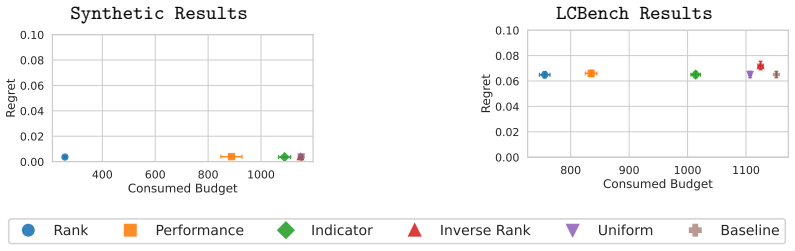
- Up to 90 percent budget reduction is observed on synthetic and LCBench benchmarks while retaining solution quality.
- The bounds supply a principled foundation for incorporating priors into compute-efficient AutoML.
Where Pith is reading between the lines
- The bounds could guide construction or selection of priors that maximize efficiency in new HPO tasks.
- The same modeling approach may extend to quantify prior benefits in other black-box optimization problems.
- The results support analysis of energy savings when prior information is available in large-scale ML pipelines.
Load-bearing premise
Priors can be modeled directly over the means of arm performances inside a fixed-budget best-arm identification setup to produce explicit error bounds linking prior quality to sample needs.
What would settle it
An experiment in which priors concentrating on near-optimal arms produce no reduction in evaluations below the no-prior baseline, or in which observed sample needs violate the derived bounds.
Figures
read the original abstract
Large-scale hyperparameter optimization (HPO) in automated machine learning (AutoML) consumes substantial computational resources, raising growing concerns about scalability and energy efficiency. Existing methods use prior information heuristically to accelerate both black-box and multi-fidelity settings, but they lack a characterization of how prior informativeness quantitatively reduces sample complexity. In this work, we provide the first distribution-dependent sample complexity bounds for multi-fidelity HPO with priors through the formal lens of fixed-budget best-arm identification. By modeling priors directly over arm means as configuration performance, we derive explicit, distribution-dependent error bounds that quantify the relationship between priors and evaluation budget. Our analysis shows that informative priors, which concentrate probability mass on near-optimal arms, yield reductions in the number of required evaluations, whereas baseline performance is recovered with uninformative or misleading priors. We conduct proof-of-concept experiments on a synthetic benchmark and on LCBench, a common multi-fidelity HPO benchmark for deep learning, to confirm our theoretical results, achieving up to 90% budget reduction while retaining solution quality. Together, our results provide a principled foundation for prior-guided and compute-efficient green AutoML.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
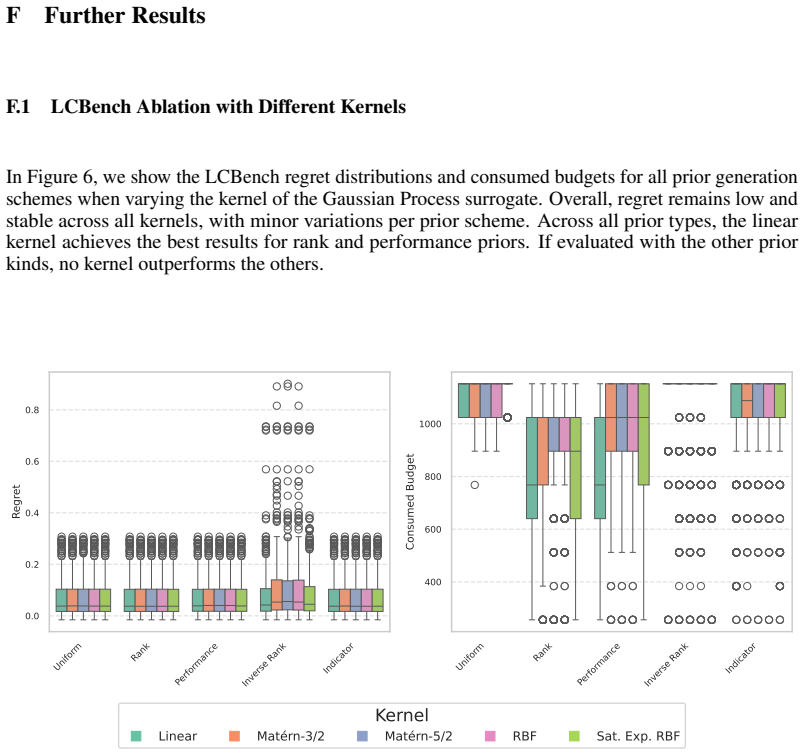
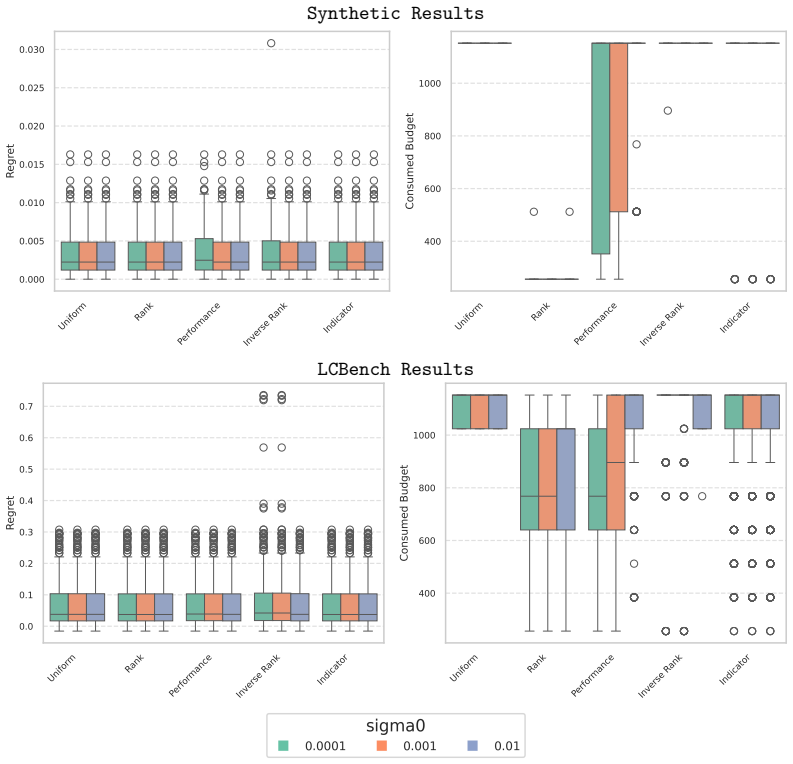
Summary. The paper claims to provide the first distribution-dependent sample complexity bounds for multi-fidelity hyperparameter optimization with priors, derived via the fixed-budget best-arm identification framework. By modeling priors directly over arm means (as configuration performance), it derives explicit error bounds quantifying how informative priors (concentrating mass near optimal arms) reduce required evaluations, while uninformative or misleading priors recover baseline performance. Proof-of-concept experiments on synthetic data and LCBench are reported to achieve up to 90% budget reduction while retaining solution quality.
Significance. If the bounds correctly handle multi-fidelity structure, the work supplies a principled, quantitative link between prior informativeness and evaluation budget in HPO, offering a foundation for compute-efficient AutoML. The explicit distribution-dependent bounds and experimental validation on a standard benchmark constitute strengths that enable falsifiable predictions.
major comments (1)
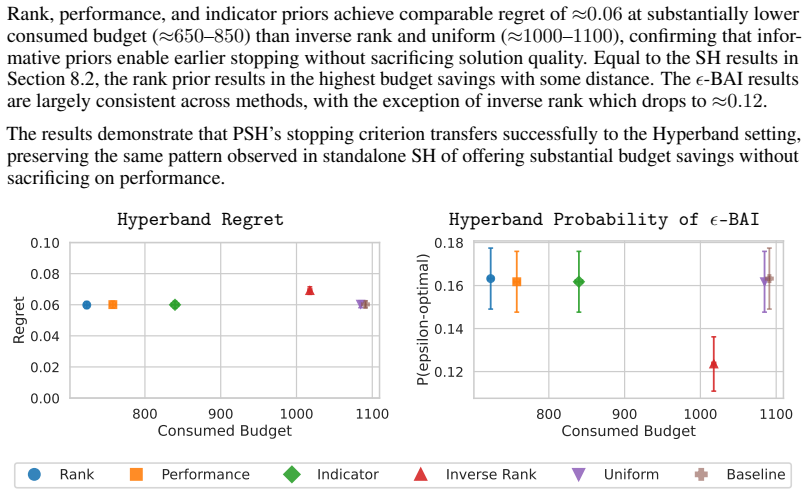
- [theoretical analysis] Abstract and theoretical analysis: the claim of multi-fidelity HPO bounds with reduced sample cost is not supported by the stated modeling. The derivation places priors directly over arm means as configuration performance and produces distribution-dependent error bounds, but supplies no indication that a fidelity-dependent observation model, bias term, or cost-weighted allocation enters the bounds. If every evaluation is treated as a direct, unbiased observation of the target mean, the claimed reduction in total compute (rather than raw evaluation count) does not necessarily follow.
Simulated Author's Rebuttal
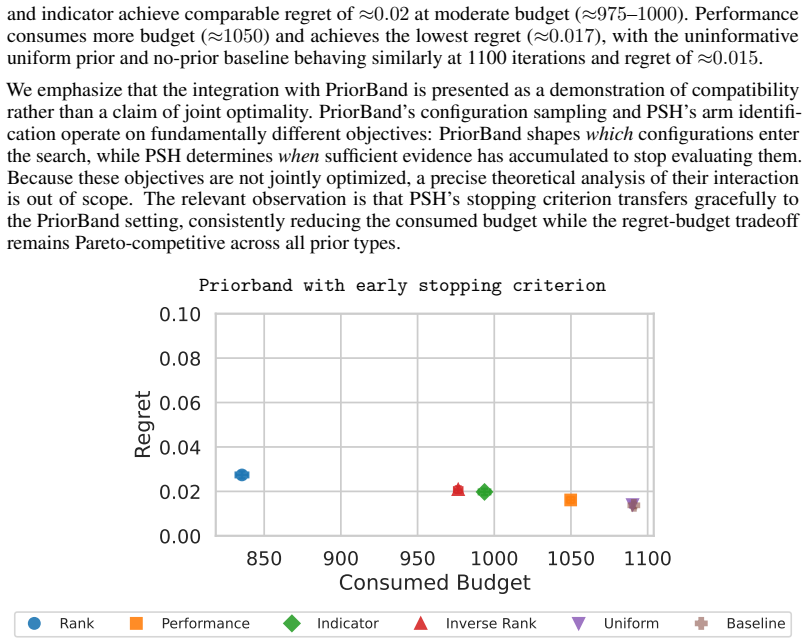
We thank the referee for the careful and constructive review. The feedback highlights an important gap between the modeling assumptions and the multi-fidelity claims, which we address directly below.
read point-by-point responses
-
Referee: [theoretical analysis] Abstract and theoretical analysis: the claim of multi-fidelity HPO bounds with reduced sample cost is not supported by the stated modeling. The derivation places priors directly over arm means as configuration performance and produces distribution-dependent error bounds, but supplies no indication that a fidelity-dependent observation model, bias term, or cost-weighted allocation enters the bounds. If every evaluation is treated as a direct, unbiased observation of the target mean, the claimed reduction in total compute (rather than raw evaluation count) does not necessarily follow.
Authors: We agree that the current theoretical derivation models each observation as an unbiased sample from the target arm mean and does not yet incorporate a fidelity-dependent observation model, bias terms for lower-fidelity evaluations, or explicit cost-weighted allocation. Consequently, the stated bounds quantify reductions in the number of evaluations rather than total computational cost. To resolve this, we will revise the theoretical analysis section to introduce a multi-fidelity observation model (with fidelity-specific bias and variance) and a cost function that enters the fixed-budget allocation rule. The revised bounds will then explicitly relate prior informativeness to reductions in total compute while recovering the original results as a special case when all evaluations are at full fidelity. revision: yes
Circularity Check
Derivation self-contained in standard BAI framework; no reduction to inputs or self-citations
full rationale
The paper models priors directly over arm means within the fixed-budget best-arm identification setting and derives explicit distribution-dependent error bounds from that framework. No equations or steps are shown reducing by construction to fitted parameters, renamed predictions, or load-bearing self-citations; the claimed relationship between prior informativeness and evaluation budget follows from the standard BAI analysis once the prior is placed on the means. The multi-fidelity aspect is invoked but does not alter the core derivation into a circular form. This is the normal non-circular outcome for a theoretical bounds paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Priors can be modeled directly over arm means representing configuration performance.
- domain assumption The fixed-budget best-arm identification framework applies to multi-fidelity HPO with priors.
Reference graph
Works this paper leans on
-
[1]
A. Atsidakou, S. Katariya, S. Sanghavi, and B. Kveton. Bayesian fixed-budget best-arm identification.arXiv preprint arXiv:2211.08572, 2022
-
[2]
Audibert and S
J.-Y . Audibert and S. Bubeck. Best arm identification in multi-armed bandits. InCOLT-23th Conference on learning theory-2010, pages 13–p, 2010
2010
-
[3]
Bischl, M
B. Bischl, M. Binder, M. Lang, T. Pielok, J. Richter, S. Coors, J. Thomas, T. Ullmann, M. Becker, A. Boulesteix, D. Deng, and M. Lindauer. Hyperparameter optimization: Foundations, algo- rithms, best practices, and open challenges.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, page e1484, 2023
2023
-
[4]
Bohdal, L
O. Bohdal, L. Balles, M. Wistuba, B. Ermis, C. Archambeau, and G. Zappella. PASHA: Efficient HPO and NAS with progressive resource allocation. InThe Eleventh International Conference on Learning Representations (ICLR’23). ICLR, 2023. Published online:iclr.cc
2023
-
[5]
Brandt, E
J. Brandt, E. Schede, B. Haddenhorst, V . Bengs, E. Hüllermeier, and K. Tierney. AC-Band: A combinatorial bandit-based approach to algorithm configuration. In B. Williams, S. Bernardini, Y . Chen, and J. Neville, editors,Proceedings of the Thirty-Seventh Conference on Artificial Intelligence (AAAI’23). Association for the Advancement of Artificial Intelli...
2023
-
[6]
Brandt, M
J. Brandt, M. Wever, V . Bengs, and E. Hüllermeier. Best arm identification with retroactively increased sampling budget for more resource-efficient hpo. In K. Larson, editor,Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI’24), 2024
2024
-
[7]
Castellanos-Nieves and L
D. Castellanos-Nieves and L. García-Forte. Strategies of automated machine learning for energy sustainability in green artificial intelligence.Applied Sciences, 14(14), 2024
2024
-
[8]
Castellanos-Nieves and L
D. Castellanos-Nieves and L. García-Forte. Improving automated machine-learning systems through green ai.Applied Sciences, 13(20), 2023
2023
-
[9]
Eggensperger, P
K. Eggensperger, P. Müller, N. Mallik, M. Feurer, R. Sass, A. Klein, N. Awad, M. Lindauer, and F. Hutter. HPOBench: A collection of reproducible multi-fidelity benchmark problems for HPO. In J. Vanschoren and S. Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks. Curran Associates, 2021. 10
2021
-
[10]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
N. Erickson, J. Mueller, A. Shirkov, H. Zhang, P. Larroy, M. Li, and A. Smola. Autogluon- tabular: Robust and accurate automl for structured data.arXiv:2003.06505 [stat.ML], 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[11]
Even-Dar, S
E. Even-Dar, S. Mannor, and Y . Mansour. Pac bounds for multi-armed bandit and markov decision processes. InInternational Conference on Computational Learning Theory, pages 255–270. Springer, 2002
2002
-
[12]
Falkner, G
A. Falkner, G. Friedrich, K. Schekotihin, R. Taupe, and E. Teppan. Industrial applications of answer set programming.KI-Künstliche Intelligenz, pages 1–12, 2018
2018
-
[13]
Feurer, J
M. Feurer, J. Springenberg, and F. Hutter. Initializing Bayesian Hyperparameter Optimization via meta-learning. In B. Bonet and S. Koenig, editors,Proceedings of the Twenty-ninth AAAI Conference on Artificial Intelligence (AAAI’15), pages 1128–1135. AAAI Press, 2015
2015
-
[14]
Feurer, K
M. Feurer, K. Eggensperger, S. Falkner, M. Lindauer, and F. Hutter. Auto-Sklearn 2.0: Hands- free automl via meta-learning.Journal of Machine Learning Research, 23(261):1–61, 2022
2022
-
[15]
Giovanelli, A
J. Giovanelli, A. Tornede, T. Tornede, and M. Lindauer. Interactive hyperparameter opti- mization in multi-objective problems via preference learning. In M. J. Wooldridge, J. G. Dy, and S. Natarajan, editors,Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI’24). AAAI Press, 2024
2024
-
[16]
Hutter, L
F. Hutter, L. Kotthoff, and J. Vanschoren, editors.Automated Machine Learning: Methods, Systems, Challenges. Springer, 2019. Available for free athttp://automl.org/book
2019
-
[17]
Hvarfner, D
C. Hvarfner, D. Stoll, A. Souza, L. Nardi, M. Lindauer, and F. Hutter. πBO: Augmenting Acquisition Functions with User Beliefs for Bayesian Optimization. InThe Tenth International Conference on Learning Representations (ICLR’22). ICLR, 2022. Published online: iclr.cc
2022
-
[18]
Proceedings of the International Conference on Learning Representations (ICLR’17), 2017. ICLR. Published online:iclr.cc
2017
-
[19]
Jamieson and A
K. Jamieson and A. Talwalkar. Non-stochastic best arm identification and Hyperparameter Optimization. In A. Gretton and C. Robert, editors,Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics (AISTATS’16), volume 51. Proceedings of Machine Learning Research, 2016
2016
-
[20]
Klein, S
A. Klein, S. Falkner, J. Springenberg, and F. Hutter. Learning curve prediction with Bayesian neural networks. InThe Fifth International Conference on Learning Representations (ICLR’17) ICL [18]. Published online:iclr.cc
-
[21]
Lederer, J
A. Lederer, J. Umlauft, and S. Hirche. Uniform error bounds for gaussian process regression with application to safe control.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[22]
F. Li, S. Wang, and K. Li. Lamda: Two-phase multi-fidelity hpo via learning promising regions from data. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[23]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar. Hyperband: Bandit- based configuration evaluation for Hyperparameter Optimization. InThe Fifth International Conference on Learning Representations (ICLR’17)ICL [18]. Published online:iclr.cc
-
[24]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar. Hyperband: A novel bandit-based approach to Hyperparameter Optimization.Journal of Machine Learning Research, 18(185):1–52, 2018
2018
-
[25]
Mallik, C
N. Mallik, C. Hvarfner, D. Stoll, M. Janowski, E. Bergman, M. Lindauer, L. Nardi, and F. Hutter. PriorBand: HyperBand + human expert knowledge. In F. Ferreira, Q. Lei, E. Triantafillou, J. Vanschoren, and H. Yao, editors,NeurIPS 2022 Workshop on Meta-Learning, 2022
2022
-
[26]
Mallik, C
N. Mallik, C. Hvarfner, E. Bergman, D. Stoll, M. Janowski, M. Lindauer, L. Nardi, and F. Hutter. PriorBand: Practical hyperparameter optimization in the age of deep learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Proceedings of the 37th International Conference on Advances in Neural Information Processing Systems ...
2023
-
[27]
Mohr and M
F. Mohr and M. Wever. Naive automated machine learning.Machine Learning, 112, 2023
2023
-
[28]
Müller, M
S. Müller, M. Feurer, N. Hollmann, and F. Hutter. PFNs4BO: In-Context Learning for Bayesian Optimization. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning (ICML’23), volume 202 ofProceedings of Machine Learning Research. PMLR, 2023
2023
-
[29]
Ordoumpozanis and G
K. Ordoumpozanis and G. A. Papakostas. Green ai: Assessing the carbon footprint of fine- tuning pre-trained deep learning models in medical imaging. In2024 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT). IEEE, 2024
2024
-
[30]
Perrone, H
V . Perrone, H. Shen, M. Seeger, C. Archambeau, and R. Jenatton. Learning search spaces for bayesian optimization: Another view of hyperparameter transfer learning. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alche Buc, E. Fox, and R. Garnett, editors,Proceedings of the 33rd International Conference on Advances in Neural Information Processing Syst...
2019
-
[31]
Pfisterer, L
F. Pfisterer, L. Schneider, J. Moosbauer, M. Binder, and B. Bischl. YAHPO Gym – an effi- cient multi-objective multi-fidelity benchmark for hyperparameter optimization. In I. Guyon, M. Lindauer, M. van der Schaar, F. Hutter, and R. Garnett, editors,Proceedings of the First International Conference on Automated Machine Learning. Proceedings of Machine Lear...
2022
-
[32]
Rakotoarison, S
H. Rakotoarison, S. Adriaensen, N. Mallik, S. Garibov, E. Bergman, and F. Hutter. In-context freeze-thaw bayesian optimization for hyperparameter optimization. In R. Salakhutdinov, Z. Kolter, K. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning (ICML’24), volume 251 o...
2024
-
[33]
Rasmussen and C
C. Rasmussen and C. Williams.Gaussian Processes for Machine Learning. The MIT Press, 2006
2006
-
[34]
Rothfuss, V
J. Rothfuss, V . Fortuin, M. Josifoski, and A. Krause. Pacoh: Bayes-optimal meta-learning with pac-guarantees. InInternational Conference on Machine Learning, pages 9116–9126. PMLR, 2021
2021
-
[35]
Schede, J
E. Schede, J. Brandt, A. Tornede, M. Wever, V . Bengs, E. Hüllermeier, and K. Tierney. A survey of methods for automated algorithm configuration.jair, 75:425–487, 2022
2022
-
[36]
R. Schwartz, J. Dodge, N. A. Smith, and O. Etzioni. Green AI.arXiv:1907.10597v3 [cs.CY], 2019
-
[37]
J. Seng, F. Ventola, Z. Yu, and K. Kersting. Hyperparameter optimization via interacting with probabilistic circuits. In R. Garnett, C. Doerr, J. van Rijn, and L. Akoglu, editors,Proceedings of the Third International Conference on Automated Machine Learning. Proceedings of Machine Learning Research, 2025
2025
-
[38]
Souza, L
A. Souza, L. Nardi, L. Oliveira, K. Olukotun, M. Lindauer, and F. Hutter. Bayesian optimization with a prior for the optimum. In N. Oliver, F. Pérez-Cruz, S. Kramer, J. Read, and J. A. Lozano, editors,Machine Learning and Knowledge Discovery in Databases. Research Track, volume 12975 ofLecture Notes in Artificial Intelligence, page 265–296. Springer-Verlag, 2021
2021
-
[39]
Srinivas, A
N. Srinivas, A. Krause, S. Kakade, and M. Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. In J. Fürnkranz and T. Joachims, editors, Proceedings of the 27th International Conference on Machine Learning (ICML’10), pages 1015–1022. Omnipress, 2010
2010
-
[40]
Tornede, A
T. Tornede, A. Tornede, J. Hanselle, F. Mohr, M. Wever, and E. Hüllermeier. Towards green automated machine learning: Status quo and future directions.Journal of Artificial Intelligence Research, 77:427–457, 2023. 12
2023
-
[41]
van Rijn and F
J. van Rijn and F. Hutter. Hyperparameter importance across datasets. In Y . Guo and F. Fa- rooq, editors,Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’18), pages 2367–2376. ACM Press, 2018
2018
-
[42]
Zimmer, M
L. Zimmer, M. Lindauer, and F. Hutter. Auto-Pytorch: Multi-fidelity metalearning for efficient and robust AutoDL.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43: 3079–3090, 2021. 13 Overview of the Appendix A List of Symbols 15 B Theoretical Guarantees 16 B.1 Expected behavior of Prior-Guided Successive Halving . . . . . . . . . . . . ....
2021
-
[43]
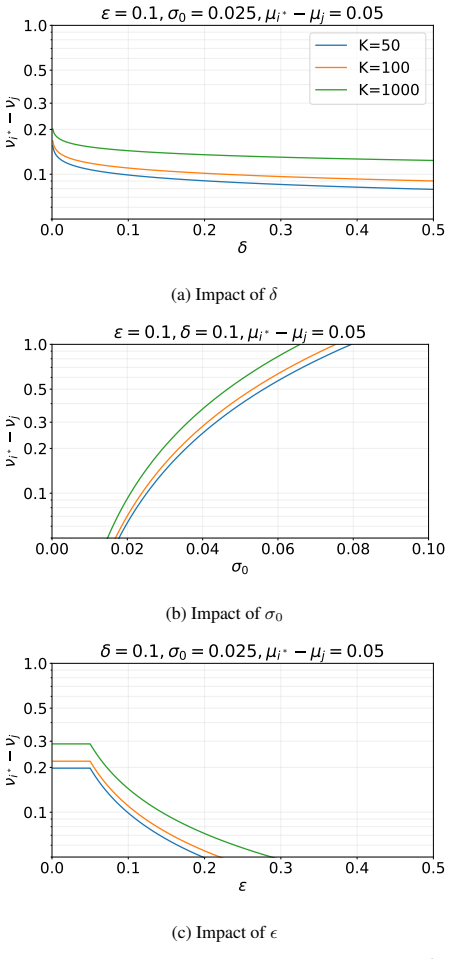
ln 2 log2(K)( K 2 −1) δ ! − (νj∗ −ν j) max{ϵ, µj∗ −µ j} 2σ2 0 # . (20) Proof.Case 1: Let for allj∈ K\{j ∗}:µ j∗ −µ j ≥ϵ. Then we have N≥max j∈K\{j ∗} 4RΣ (µj∗ −µ j)2 ·
and arms are eliminated based on their posterior means (Algorithm 2). Let j∗ denote the optimal arm. We define the error eventEϵ as returning an arm j such that µj∗ −µ j > ϵ. The expected probability of error is bounded by summing the risk over allRrounds: E[P(Eϵ |µ)]≤ R−1X r=0 Cr,ϵ X j∈K,j̸=j ∗ exp −(νj∗ −ν j)2 4σ2 0 exp − nrϵ2 4Σ (10) Proof. The algorit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.