MAOAM: Unified Object and Material Selection with Vision-Language Models
Pith reviewed 2026-06-28 11:03 UTC · model grok-4.3
The pith
MAOAM uses one vision-language model to select either objects or materials from text or click prompts and output pixel masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
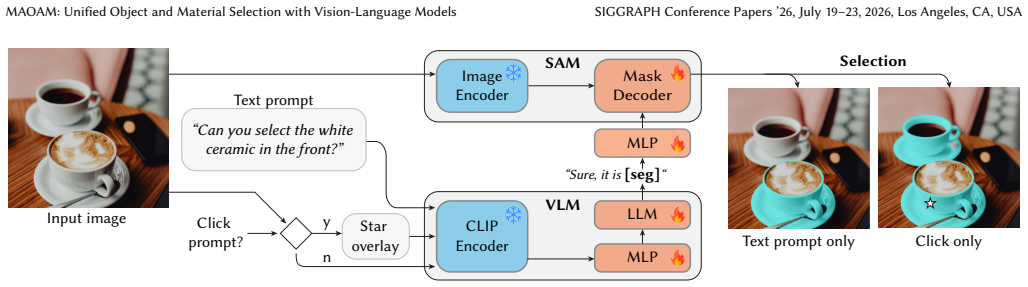
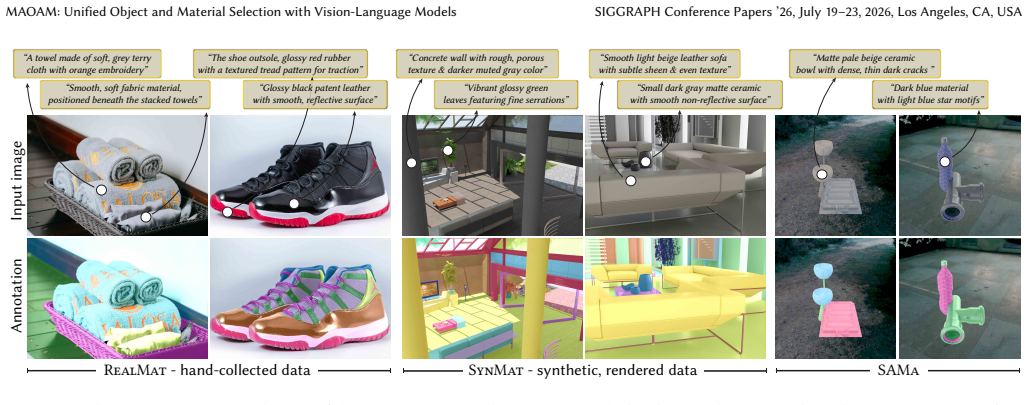
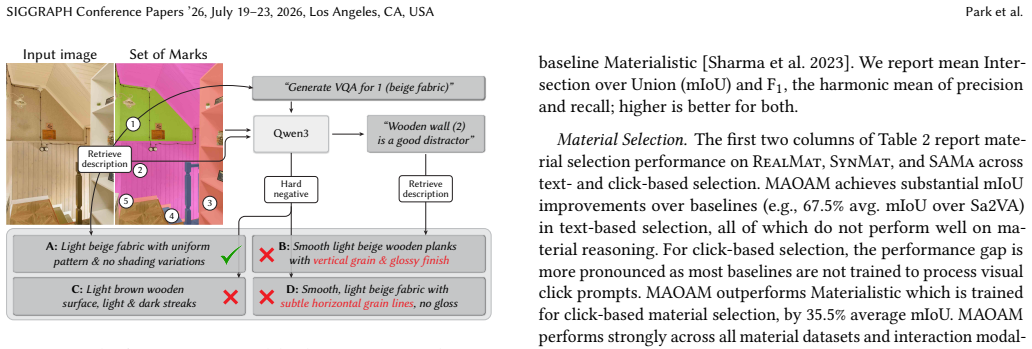
MAOAM is a unified selection framework in which a vision-language model interprets a user's object-level or material-level intent from text or click prompts, encodes the relevant visual entities, attributes, and spatial relations, and a segmentation head converts the output token into a pixel-accurate mask; the model is trained with a multi-task objective on click and text selection plus an auxiliary VQA task derived from VLM-generated material descriptions obtained through a scalable pipeline that collects real and synthetic images carrying material masks.
What carries the argument
VLM with segmentation head that interprets selection intent for objects or materials and decodes the output token into a mask.
If this is right
- The same model supports both object and material selection without separate networks.
- Text-plus-click prompts at inference improve mask quality even though training used only uni-modal examples.
- Material selection enables direct re-texturing or instance editing of all surfaces sharing one material.
- Training with the auxiliary VQA task strengthens material understanding beyond pure segmentation.
Where Pith is reading between the lines
- Embedding the model in photo-editing tools would let users change every instance of a chosen material in one operation rather than clicking each surface separately.
- The same data-pipeline idea could be reused to add other selection criteria such as color families or lighting conditions if matching image collections exist.
- Running the model on video frames or 3-D rendered scenes would test whether material selections remain coherent across time or viewpoint changes.
Load-bearing premise
The material descriptions produced by the VLM data-generation pipeline are accurate and semantically rich enough to train effective material-level selection.
What would settle it
Collect a held-out set of images with human-verified material region annotations and measure whether MAOAM's material selections match those regions at rates no higher than an object-only baseline or random guessing.
Figures







read the original abstract
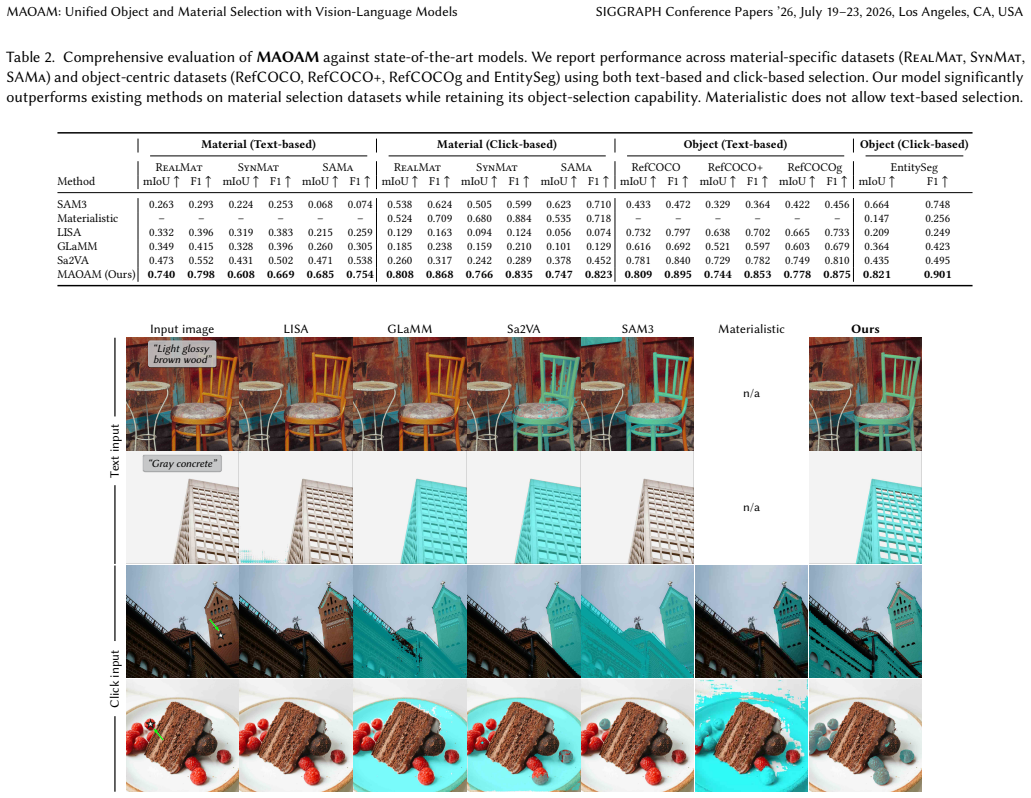
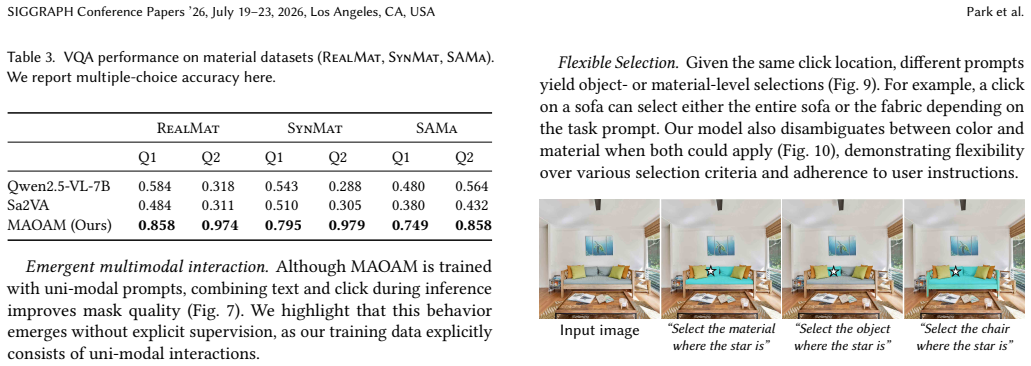
Selection is a core operation in interactive image editing. To be practical, a user should be able to specify and disambiguate the desired selection region through either text or click-based interactions, and the system should support selecting not only objects but also other criteria, such as materials. Material-based selection is valuable for tasks like re-texturing surfaces or editing instances of a specific material. However, existing vision-language-model (VLM) based selection methods are object-centric and typically support a single interaction modality, limiting their applicability. In this work, we thus present Mask Any Object And Material (MAOAM), a unified selection framework that enables precise object and material-level selection across both text- and click-based interactions. MAOAM leverages a VLM with a segmentation head to produce pixel-accurate masks from user prompts: the VLM interprets the user's selection intent (object or material-level) and encodes visual entities, attributes, and spatial relations, while the segmentation head decodes the output token into a mask. A key challenge is the lack of material selection datasets with text annotations. We propose a scalable data generation pipeline: we collect real and synthetic images with material masks, and leverage VLMs to generate material descriptions with rich visual-semantics. We train MAOAM with a multi-task objective over click and text-based selection, along with an auxiliary VQA task derived from the material descriptions to facilitate deeper material understanding. Despite being trained with uni-modal prompts, our model exhibits an emergent improvement in selection when combining text and clicks at inference, enabling flexible image editing workflows. Experiments demonstrate accurate and coherent selections across diverse objects, materials, and interaction scenarios, highlighting robustness in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MAOAM, a VLM-based framework with a segmentation head for unified object- and material-level selection in images. It supports both text and click prompts, introduces a scalable pipeline that uses VLMs to generate material descriptions from masked images, trains via a multi-task objective (selection + auxiliary VQA), and reports an emergent benefit from combined text+click prompts at inference along with accurate performance across diverse scenarios.
Significance. If the central claims hold, the work would be significant for interactive image editing by extending VLM selection beyond object-centric, single-modality methods to include material-level disambiguation with flexible interactions. The scalable data-generation pipeline and multi-task training that yields emergent cross-modal behavior are concrete strengths that could influence downstream editing tools.
major comments (2)
- [Data Generation Pipeline] Data Generation Pipeline section: the central claim that the pipeline produces 'rich visual-semantics' sufficient for material-level selection and the auxiliary VQA task rests on unvalidated VLM-generated descriptions. No quantitative accuracy metric, human agreement study, or error analysis on the generated text is reported; if hallucinations or omissions are present, both the multi-task objective and the claimed material selection accuracy would be undermined.
- [Experiments] Experiments section: the claim of 'accurate and coherent selections' and 'emergent improvement' when combining text and clicks is presented without reported ablations isolating the contribution of the auxiliary VQA task or the material-description quality, making it difficult to assess whether the multi-task objective is load-bearing for the reported robustness.
minor comments (2)
- [Method] Notation for the segmentation head output token and its decoding into masks could be clarified with an explicit equation or diagram reference.
- [Experiments] The abstract states results 'across diverse objects, materials, and interaction scenarios' but the experiments section would benefit from a table summarizing quantitative metrics (e.g., IoU, precision) against explicit baselines for both object and material tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and commit to revisions that directly strengthen the validation and analysis sections.
read point-by-point responses
-
Referee: [Data Generation Pipeline] Data Generation Pipeline section: the central claim that the pipeline produces 'rich visual-semantics' sufficient for material-level selection and the auxiliary VQA task rests on unvalidated VLM-generated descriptions. No quantitative accuracy metric, human agreement study, or error analysis on the generated text is reported; if hallucinations or omissions are present, both the multi-task objective and the claimed material selection accuracy would be undermined.
Authors: We agree that the current manuscript lacks direct quantitative validation of the VLM-generated material descriptions. While end-to-end selection performance provides indirect support, this does not substitute for explicit checks on description quality. In the revised version we will add a human agreement study on a sampled subset of generated descriptions together with an error analysis categorizing hallucinations, omissions, and attribute accuracy. This will be reported with inter-annotator agreement metrics. revision: yes
-
Referee: [Experiments] Experiments section: the claim of 'accurate and coherent selections' and 'emergent improvement' when combining text and clicks is presented without reported ablations isolating the contribution of the auxiliary VQA task or the material-description quality, making it difficult to assess whether the multi-task objective is load-bearing for the reported robustness.
Authors: We acknowledge the absence of targeted ablations on the auxiliary VQA task and on material-description quality. The reported results demonstrate overall performance and the emergent text+click behavior, yet do not isolate the contribution of each component. In revision we will add (i) an ablation removing the VQA loss and (ii) a controlled comparison using lower-quality or template-based descriptions, reporting the resulting changes in selection metrics and emergent behavior. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes a training pipeline that uses external VLMs to generate material descriptions from images with masks, then trains a VLM+segmentation model on a multi-task objective (click/text selection + auxiliary VQA). No equations, fitted parameters, or predictions are shown to reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The data-generation step relies on off-the-shelf VLMs rather than the model's own outputs, and experimental claims are presented as empirical results rather than derived identities. This matches the default case of an independent modeling effort.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can accurately interpret and encode selection intent for objects, materials, attributes, and spatial relations from text or click prompts
Reference graph
Works this paper leans on
-
[1]
1994 , publisher=
An introduction to the conjugate gradient method without the agonizing pain , author=. 1994 , publisher=
1994
-
[2]
International Conference on Computer Vision (ICCV) , month =
Qi, Lu and Kuen, Jason and Shen, Tiancheng and Gu, Jiuxiang and Guo, Weidong and Jia, Jiaya and Lin, Zhe and Yang, Ming-Hsuan , title =. International Conference on Computer Vision (ICCV) , month =
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Glamm: Pixel grounding large multimodal model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
and Chai, Yuning and Park, Dennis and Lee, Yong Jae , title =
Cai, Mu and Liu, Haotian and Mustikovela, Siva Karthik and Meyer, Gregory P. and Chai, Yuning and Park, Dennis and Lee, Yong Jae , title =. IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[5]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Xia, Zhuofan and Han, Dongchen and Han, Yizeng and Pan, Xuran and Song, Shiji and Huang, Gao , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[7]
European Conference on Computer Vision , pages=
Psalm: Pixelwise segmentation with large multi-modal model , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[8]
arXiv preprint arXiv:2503.06520 , year =
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement , author =. arXiv preprint arXiv:2503.06520 , year =
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lisa: Reasoning segmentation via large language model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
ACM i3D , year=
Transforming a Non-Differentiable Rasterizer into a Differentiable One with Stochastic Gradient Estimation , author=. ACM i3D , year=
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Hu, Rui and Zhu, Lianghui and Zhang, Yuxuan and Cheng, Tianheng and Liu, Lei and Liu, Heng and Ran, Longjin and Chen, Xiaoxin and Liu, Wenyu and Wang, Xinggang , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[12]
2025 , eprint=
SAM 3: Segment Anything with Concepts , author=. 2025 , eprint=
2025
- [13]
-
[14]
arXiv preprint arXiv:2408.00714 , url=
SAM 2: Segment Anything in Images and Videos , author=. arXiv preprint arXiv:2408.00714 , url=
-
[15]
SoftwareX , volume=
ACORNS: An easy-to-use code generator for gradients and Hessians , author=. SoftwareX , volume=. 2022 , publisher=
2022
-
[16]
1999 , publisher=
Numerical optimization , author=. 1999 , publisher=
1999
-
[17]
Neural computation , volume=
Fast exact multiplication by the Hessian , author=. Neural computation , volume=. 1994 , publisher=
1994
-
[18]
ACM Sigplan Notices , volume=
Smooth interpretation , author=. ACM Sigplan Notices , volume=. 2010 , publisher=
2010
-
[19]
2014 , publisher=
Solving transcendental equations: the Chebyshev polynomial proxy and other numerical rootfinders, perturbation series, and oracles , author=. 2014 , publisher=
2014
-
[20]
IEEE 1988 Int Conf Neural Networks , pages=
Backpropagation: Past and future , author=. IEEE 1988 Int Conf Neural Networks , pages=. 1988 , organization=
1988
-
[21]
The rendering equation , author=. Proc. SIGGRAPH , year=
-
[22]
NeurIPS , volume=
Learning with differentiable pertubed optimizers , author=. NeurIPS , volume=
-
[23]
Perturbations, Optimization, and Statistics , volume=
Perturbation techniques in online learning and optimization , author=. Perturbations, Optimization, and Statistics , volume=. 2016 , publisher=
2016
-
[24]
IEEE Trans, Vis, and Comp, Graph, , volume=
Caustics mapping: An image-space technique for real-time caustics , author=. IEEE Trans, Vis, and Comp, Graph, , volume=
-
[25]
A versatile scene model with differentiable visibility applied to generative pose estimation , author=. Proc. ICCV , year=
-
[26]
Soft rasterizer: A differentiable renderer for image-based 3d reasoning , author=. Proc. ICCV , year=
-
[27]
OpenDR: An approximate differentiable renderer , author=. Proc. ECCV , year=
-
[28]
arXiv preprint arXiv:2006.12057 , year=
Differentiable rendering: A survey , author=. arXiv preprint arXiv:2006.12057 , year=
arXiv 2006
-
[29]
ACM Tran Graph
Reparameterizing discontinuous integrands for differentiable rendering , author=. ACM Tran Graph. , volume=
-
[30]
Neural 3d mesh renderer , author=. Proc. CVPR , year=
-
[31]
Differentiable
Li, Tzu-Mao and Aittala, Miika and Durand, Fr. Differentiable. ACM Trans Graph. , volume=
-
[32]
Im2vec: Synthesizing vector graphics without vector supervision , author=. Proc. CVPR , year=
-
[33]
ACM Trans
Differentiable signed distance function rendering , author=. ACM Trans. Graph. (Proc. SIGGRAPH) , volume=
-
[34]
NeurIPS , volume=
Differentiable rendering with perturbed optimizers , author=. NeurIPS , volume=
-
[35]
ACM SIGGRAPH , year=
Node Graph Optimization Using Differentiable Proxies , author=. ACM SIGGRAPH , year=
-
[36]
ACM Trans Graph (Proc
Metappearance: Meta-Learning for Visual Appearance Reproduction , author=. ACM Trans Graph (Proc. SIGGRAPH Asia) , year=
-
[37]
arXiv preprint arXiv:2210.03510 , year=
Learning to Learn and Sample BRDFs , author=. arXiv preprint arXiv:2210.03510 , year=
-
[38]
J of the American Statistical Association , volume=
Safe and effective importance sampling , author=. J of the American Statistical Association , volume=
-
[39]
and Deussen, Oliver and Cohen-Or, Daniel , title =
Petersen, Felix and Bermano, Amit H. and Deussen, Oliver and Cohen-Or, Daniel , title =
-
[40]
GenDR: A Generalized Differentiable Renderer , author=. Proc. CVPR , year=
-
[41]
Mathematical proceedings of the Cambridge philosophical society , volume=
General principles of antithetic variates , author=. Mathematical proceedings of the Cambridge philosophical society , volume=
-
[42]
ACM Trans
Unbiased warped-area sampling for differentiable rendering , author=. ACM Trans. Graph. , volume=
-
[43]
Importance sampling
Belhe, Yash and Xu, Bing and Bangaru, Sai Praveen and Ramamoorthi, Ravi and Li, Tzu-Mao , journal=. Importance sampling. 2024 , publisher=
2024
-
[44]
Antithetic sampling for
Zhang, Cheng and Dong, Zhao and Doggett, Michael and Zhao, Shuang , journal=. Antithetic sampling for
-
[45]
SIAM Scientific Computing , volume=
A nonlinear primal-dual method for total variation-based image restoration , author=. SIAM Scientific Computing , volume=. 1999 , publisher=
1999
-
[46]
Fast image deconvolution using hyper-Laplacian priors , author=. Proc. NeurIPS , volume=
-
[47]
Texture mapping progressive meshes , author=. Proc. SIGGRAPH , pages=
-
[48]
SIGGRAPH , pages=
Geometric modeling in shape space , author=. SIGGRAPH , pages=
-
[49]
A duality based approach for realtime
Zach, Christopher and Pock, Thomas and Bischof, Horst , booktitle=. A duality based approach for realtime
-
[50]
, author=
Anisotropic Huber-L1 Optical Flow. , author=. BMVC , volume=. 2009 , organization=
2009
-
[51]
ICML , pages=
Learning recurrent neural networks with hessian-free optimization , author=. ICML , pages=
-
[52]
arXiv preprint arXiv:1301.3584 , year=
Revisiting natural gradient for deep networks , author=. arXiv preprint arXiv:1301.3584 , year=
-
[53]
Adahessian: An adaptive second order optimizer for machine learning , author=. Proc. AAAI , volume=
-
[54]
arXiv preprint arXiv:2204.06125 , volume=
Hierarchical text-conditional image generation with clip latents , author=. arXiv preprint arXiv:2204.06125 , volume=
-
[55]
Inverse global illumination: Recovering reflectance models of real scenes from photographs , author=. Proc. SIGGRAPH , pages=
-
[56]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[57]
arXiv preprint arXiv:1609.04747 , year=
An overview of gradient descent optimization algorithms , author=. arXiv preprint arXiv:1609.04747 , year=
-
[58]
ACM Trans
Projective sampling for differentiable rendering of geometry , author=. ACM Trans. Graph. , volume=
-
[59]
Optimally combining sampling techniques for Monte Carlo rendering , author=. POrioc. SIGGRAPH , pages=
-
[60]
1998 , publisher=
Robust Monte Carlo methods for light transport simulation , author=. 1998 , publisher=
1998
-
[61]
ACM Trans
Mitsuba 2: A retargetable forward and inverse renderer , author=. ACM Trans. Graph. , volume=
-
[62]
Deep-learning the Latent Space of Light Transport , author=. Comp. Graph. Forum , volume=
-
[63]
The computer journal , volume=
A rapidly convergent descent method for minimization , author=. The computer journal , volume=. 1963 , publisher=
1963
-
[64]
arXiv preprint arXiv:2006.03427 , year=
Learning Neural Light Transport , author=. arXiv preprint arXiv:2006.03427 , year=
arXiv 2006
-
[65]
NeuRIPS , volume=
Learning to predict 3d objects with an interpolation-based differentiable renderer , author=. NeuRIPS , volume=
-
[66]
NeuRIPS , volume=
Unsupervised learning of shape and pose with differentiable point clouds , author=. NeuRIPS , volume=
-
[67]
R efer I t G ame: Referring to Objects in Photographs of Natural Scenes
Kazemzadeh, Sahar and Ordonez, Vicente and Matten, Mark and Berg, Tamara. R efer I t G ame: Referring to Objects in Photographs of Natural Scenes. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ). 2014
2014
-
[68]
Dist: Rendering deep implicit signed distance function with differentiable sphere tracing , author=. Proc. CVPR , year=
-
[69]
3DV , year=
V-net: Fully convolutional neural networks for volumetric medical image segmentation , author=. 3DV , year=
-
[70]
Inverse rendering for complex indoor scenes: Shape, spatially-varying lighting and svbrdf from a single image , author=. Proc. CVPR , year=
-
[71]
Note sur la convergence de m
Polak, Elijah and Ribiere, Gerard , journal=. Note sur la convergence de m. 1969 , publisher=
1969
-
[72]
ACM SIGGRAPH , year=
Eikonal Fields for Refractive Novel-View Synthesis , author=. ACM SIGGRAPH , year=
-
[73]
Sdfdiff: Differentiable rendering of signed distance fields for 3d shape optimization , author=. Proc. CVPR , year=
-
[74]
Escaping plato's cave using adversarial training: 3d shape from unstructured 2d image collections , author=. Proc. ICCV , year=
-
[75]
Multi-view supervision for single-view reconstruction via differentiable ray consistency , author=. Proc. CVPR , year=
-
[76]
Comm ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Comm ACM , volume=
-
[77]
Differentiable Rendering using
Xing, Jiankai and Luan, Fujun and Yan, Ling-Qi and Hu, Xuejun and Qian, Houde and Xu, Kun , journal=. Differentiable Rendering using
-
[78]
arXiv preprint arXiv:1212.4507 , year=
Variational optimization , author=. arXiv preprint arXiv:1212.4507 , year=
-
[79]
, author=
Optimization by Variational Bounding. , author=. ESANN , year=
-
[80]
ICML , pages=
Do differentiable simulators give better policy gradients? , author=. ICML , pages=. 2022 , organization=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.