D³-MoE:Dual Disentangled Diffusion Mixture-of-Experts for Style-Controllable End-to-End Autonomous Driving
Pith reviewed 2026-06-28 05:59 UTC · model grok-4.3
The pith
D³-MoE disentangles behavioral style from physical long-lat axes in a diffusion mixture-of-experts so that multi-style trajectories can be generated and selected without averaging human demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
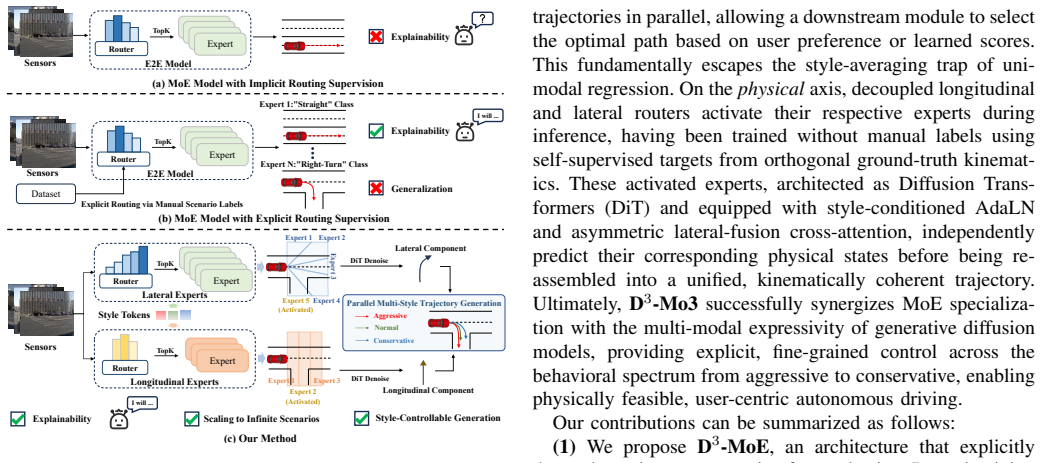
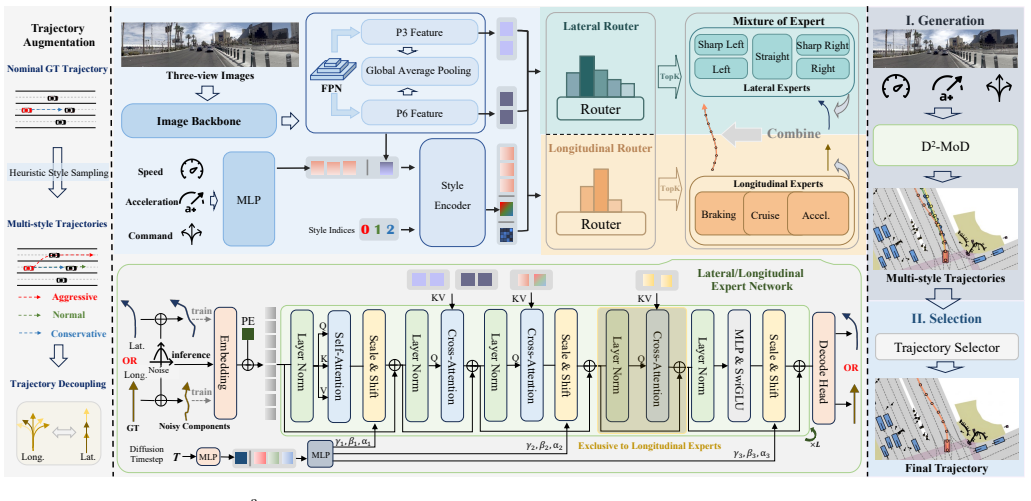
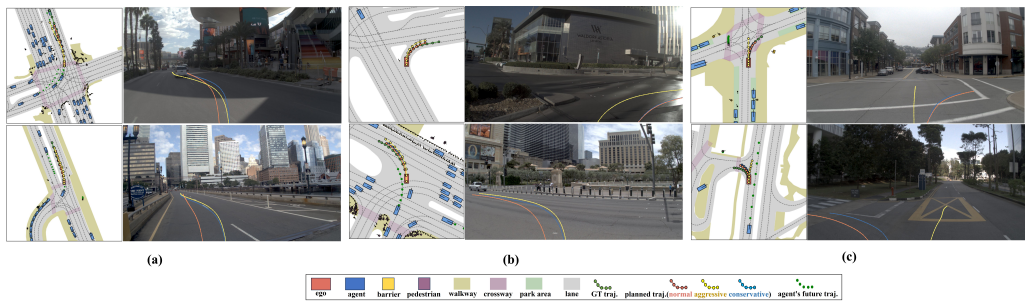
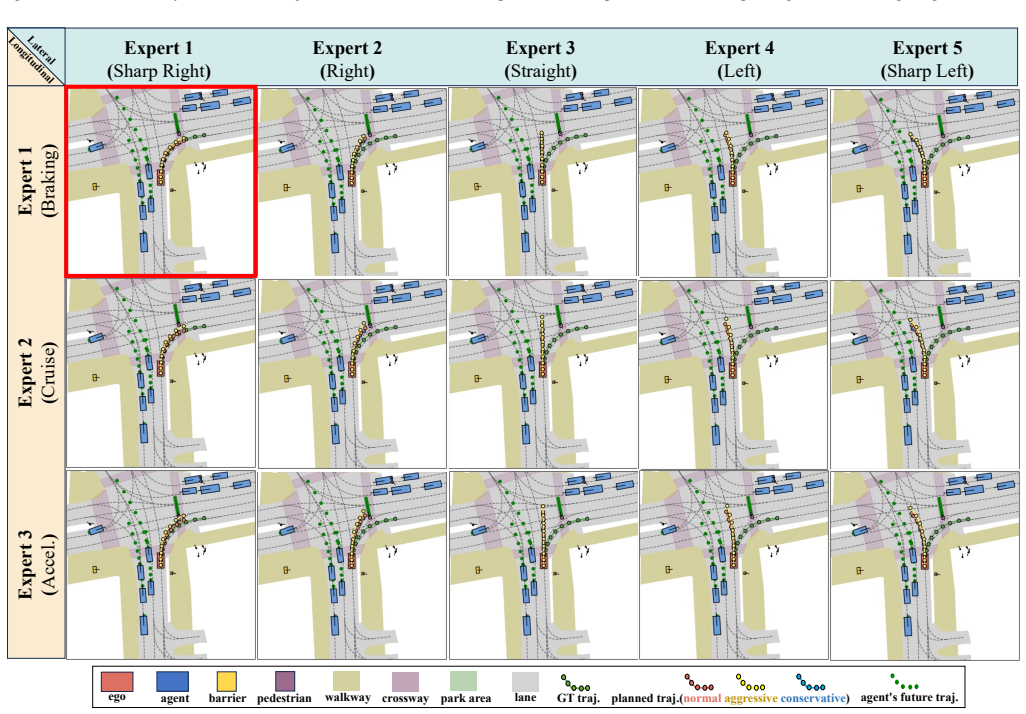
By decoupling generation from selection on the behavioral axis and longitudinal from lateral dynamics on the physical axis, the dual disentangled diffusion mixture-of-experts synthesizes multi-style candidate trajectories via style-conditioned diffusion while independent expert routers, trained on orthogonal ground-truth kinematics, predict their respective states before reassembly into kinematically coherent output, reaching 88.2 PDMS and 84.3 EPDMS on NAVSIM by default and higher with Best-of-Three ensemble.
What carries the argument
Dual disentanglement separating behavioral generation-selection from physical longitudinal-lateral routing inside style-conditioned Diffusion Transformer experts.
If this is right
- Multiple style-conditioned trajectories are generated in one forward pass for a single scene and can be chosen downstream by preference or score.
- Longitudinal and lateral experts activate separately at inference and each predicts only its own physical component.
- Style conditioning is injected through AdaLN and asymmetric cross-attention without requiring manual style labels.
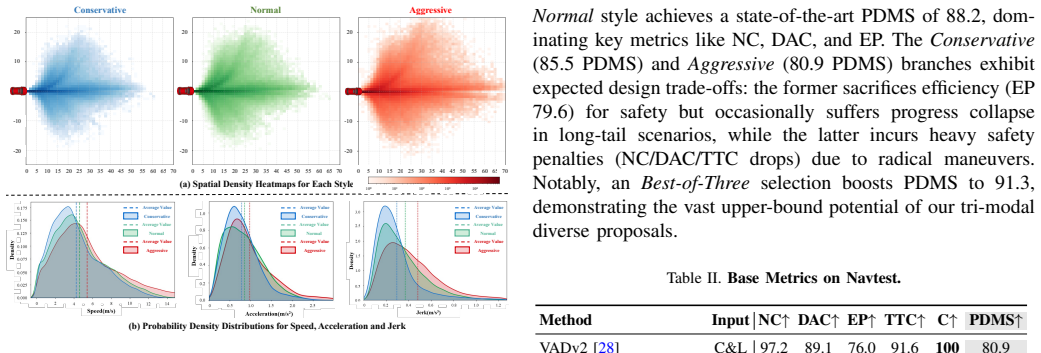
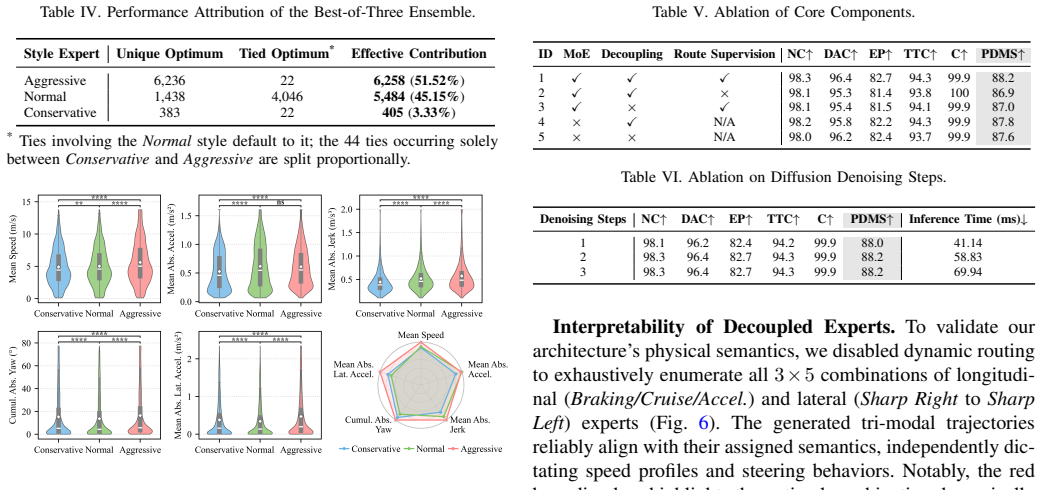
- Default performance reaches 88.2 PDMS and 84.3 EPDMS on NAVSIM, rising to 91.3 PDMS and 87.5 EPDMS under Best-of-Three ensemble.
Where Pith is reading between the lines
- The same behavioral-physical split might let other generative planners offer user-selectable modes without retraining the whole model.
- Measuring how often the reassembled paths violate basic kinematic constraints would directly test whether the orthogonal-router assumption holds in practice.
- If the self-supervised kinematic targets generalize across datasets, the approach could be applied to driving logs collected in new cities or weather conditions with little extra labeling.
Load-bearing premise
Self-supervised targets taken from orthogonal ground-truth kinematics are enough to train independent longitudinal and lateral routers whose separate outputs can be reassembled into safe, coherent trajectories.
What would settle it
Reassembled trajectories from the independent routers showing measurably higher rates of kinematic violation, jerk, or collision than a jointly trained baseline on the NAVSIM validation set.
Figures
read the original abstract
Traditional end-to-end autonomous driving frameworks frequently suffer from the "style-averaging" dilemma when trained on high-variance human demonstrations, yielding homogenized, style-uncontrollable, and even kinematically unsafe policies. To overcome this limitation, we present D$^3$-MoE (Dual Disentangled Diffusion Mixture-of-Experts), which disentangles trajectory modeling along two complementary axes. On the behavioral axis, generation is decoupled from selection: a style-conditioned diffusion process synthesizes multi-style candidate trajectories in parallel within a single scene, allowing a downstream module to select the optimal trajectory based on user preference or an evaluation score. On the physical axis, decoupled longitudinal and lateral routers activate their respective experts during inference time, trained without manual labels using self-supervised targets from orthogonal ground-truth kinematics. These activated experts, architected as Diffusion Transformers (DiT) and equipped with style-conditioned AdaLN and asymmetric lateral-fusion cross-attention, independently predict their corresponding physical state before being reassembled into a unified, kinematically coherent trajectory. Extensive evaluations on the challenging NAVSIM benchmark demonstrate that D$^3$-MoE achieves state-of-the-art planning performance, reaching 88.2 PDMS and 84.3 EPDMS by default. Moreover, our Best-of-Three ensemble strategy effectively broadens the multi-modal solution space, raising performance to 91.3 PDMS and 87.5 EPDMS. Both quantitative and qualitative analyses jointly confirm the framework's advantages in planning quality and style controllability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents D³-MoE, a Dual Disentangled Diffusion Mixture-of-Experts architecture for end-to-end autonomous driving. It disentangles modeling along a behavioral axis (style-conditioned diffusion generating multi-style candidate trajectories for downstream selection) and a physical axis (self-supervised decoupled longitudinal and lateral routers activating DiT experts with style-conditioned AdaLN and asymmetric cross-attention, whose independent predictions are reassembled into a single trajectory). The central claims are resolution of style-averaging, style controllability without manual labels, and SOTA planning performance on NAVSIM (88.2 PDMS / 84.3 EPDMS default; 91.3 / 87.5 with Best-of-Three ensemble).
Significance. If the reassembly produces kinematically coherent and safe trajectories and the reported gains are reproducible, the dual-disentanglement approach could meaningfully advance controllable multi-modal planning by separating style variation from physical axes in a parameter-efficient MoE diffusion framework. The self-supervised router training from orthogonal kinematics is a notable design choice that avoids manual labeling.
major comments (2)
- [Abstract / physical-axis description] Abstract / physical-axis description: the claim that independently generated longitudinal and lateral diffusion trajectories can be reassembled into 'kinematically coherent' outputs rests on the unstated assumption that separate diffusion processes plus router gating are sufficient. No consistency loss, kinematic projection, or joint refinement step is described; this assumption is load-bearing for both the PDMS/EPDMS claims and the safety of the resulting policies.
- [Experimental evaluation] Experimental evaluation: the abstract states specific benchmark numbers (88.2 PDMS, 84.3 EPDMS, etc.) and 'extensive evaluations,' yet the manuscript supplies no experimental protocol, baseline comparisons, ablation studies, or error analysis, rendering the central performance claims unevaluable from the provided text.
minor comments (1)
- Define all acronyms (PDMS, EPDMS, DiT, AdaLN, MoE) on first use and ensure consistent notation for the two disentanglement axes throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the physical-axis reassembly and experimental details. We address each point below with honest clarifications based on the manuscript content and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / physical-axis description] Abstract / physical-axis description: the claim that independently generated longitudinal and lateral diffusion trajectories can be reassembled into 'kinematically coherent' outputs rests on the unstated assumption that separate diffusion processes plus router gating are sufficient. No consistency loss, kinematic projection, or joint refinement step is described; this assumption is load-bearing for both the PDMS/EPDMS claims and the safety of the resulting policies.
Authors: The manuscript relies on the self-supervised router training from orthogonal ground-truth kinematics (longitudinal vs. lateral) to ensure the independent DiT expert predictions remain compatible when reassembled by direct concatenation of states. No consistency loss, projection, or joint refinement is present because the orthogonal decomposition and asymmetric cross-attention are designed to preserve physical consistency without additional terms. We agree the reassembly step is described too briefly in the abstract and method overview. We will expand the physical-axis section with an explicit reassembly procedure, a diagram of state concatenation, and a short discussion of why kinematic coherence holds under the orthogonal training regime. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: the abstract states specific benchmark numbers (88.2 PDMS, 84.3 EPDMS, etc.) and 'extensive evaluations,' yet the manuscript supplies no experimental protocol, baseline comparisons, ablation studies, or error analysis, rendering the central performance claims unevaluable from the provided text.
Authors: The full manuscript contains Section 4 (Experiments) that specifies the NAVSIM evaluation protocol, data preprocessing, metric definitions, full baseline tables with comparisons to prior methods, ablation studies isolating the dual disentanglement and MoE routers, and both quantitative error breakdowns and qualitative trajectory visualizations. The abstract only summarizes headline numbers. If the review text was limited to the abstract excerpt, the complete paper already supplies the requested protocol and analyses. We will add a one-paragraph summary of the experimental setup to the abstract and ensure all tables are cross-referenced in the main text for easier navigation. revision: partial
Circularity Check
No significant circularity in claimed derivation chain
full rationale
The paper describes an architectural method (dual disentanglement along behavioral and physical axes, self-supervised routers from orthogonal kinematics, DiT experts with AdaLN and cross-attention, reassembly into trajectories) whose performance is reported via benchmark evaluation on NAVSIM rather than any first-principles derivation or prediction. No equations, uniqueness theorems, or fitted-parameter renamings appear that would reduce the reported PDMS/EPDMS scores or style controllability to inputs by construction. The self-supervised targets and reassembly are presented as design choices whose validity is assessed empirically, not as a closed loop equivalent to the inputs. This is the normal case of an empirical ML systems paper whose central claims remain independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[2]
Multi-agent tra- jectory prediction with difficulty-guided feature enhancement network,
G. Xin, D. Chu, L. Lu, Z. Deng, Y . Lu, and X. Wu, “Multi-agent tra- jectory prediction with difficulty-guided feature enhancement network,” IEEE Robotics and Automation Letters, 2025
2025
-
[3]
Safe and stylized trajectory planning for autonomous driving via diffusion model,
S. Pei, Y . Wang, Y . Zhu, C. Sun, Q. Li, Y . Zhao, and H. Tan, “Safe and stylized trajectory planning for autonomous driving via diffusion model,”arXiv preprint arXiv:2602.04329, 2026
-
[4]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang,et al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[5]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
2022
-
[6]
Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving,
R. Feng, N. Xi, D. Chu, R. Wang, Z. Deng, A. Wang, L. Lu, J. Wang, and Y . Huang, “Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving,”IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 226–233, 2025
2025
-
[7]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 164– 10 183, 2024
2024
-
[8]
Z. Wu, S. Pan, S. Chen, S. Yang, and Y . Huang, “A unified candidate set with scene-adaptive refinement via diffusion for end-to-end autonomous driving,”arXiv preprint arXiv:2602.03112, 2026
-
[9]
Unleashing the Potential of Diffusion Models for End-to-End Autonomous Driving
Y . Zheng, T. Tan, B. Huang, E. Liu, R. Liang, J. Zhang, J. Cui, G. Chen, K. Ma, H. Ye,et al., “Unleashing the potential of diffusion models for end-to-end autonomous driving,”arXiv preprint arXiv:2602.22801, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Implicit behavioral cloning,
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson, “Implicit behavioral cloning,” inConference on robot learning. PMLR, 2022, pp. 158–168
2022
-
[11]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[12]
Drivefine: Refining-augmented masked diffusion vla for precise and robust driving,
C. Dang, S. Ang, Y . Li, H. Tian, J. Wang, G. Li, H. Ye, J. Ma, L. Chen, and Y . Wang, “Drivefine: Refining-augmented masked diffusion vla for precise and robust driving,”arXiv preprint arXiv:2602.14577, 2026
-
[13]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang,et al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,”arXiv preprint arXiv:2411.15139, 2024
-
[14]
FeaXDrive: Feasibility-aware Trajectory-Centric Diffusion Planning for End-to-End Autonomous Driving
B. Wang, Z. Li, M. Liu, X. Zhang, B. Leng, and L. Xiong, “Feaxdrive: Feasibility-aware trajectory-centric diffusion planning for end-to-end autonomous driving,”arXiv preprint arXiv:2604.12656, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
J. Zou, S. Chen, B. Liao, Z. Zheng, Y . Song, L. Zhang, Q. Zhang, W. Liu, and X. Wang, “Diffusiondrivev2: Reinforcement learning-constrained truncated diffusion modeling in end-to-end autonomous driving,”arXiv preprint arXiv:2512.07745, 2025
-
[16]
Guideflow: Constraint-guided flow matching for planning in end-to-end autonomous driving,
L. Liu, C. Jia, G. Yu, Z. Song, J. Li, F. Jia, P. Wu, X. Hao, and Y . Luo, “Guideflow: Constraint-guided flow matching for planning in end-to-end autonomous driving,”arXiv preprint arXiv:2511.18729, 2025
-
[17]
Trajdiff: End-to-end autonomous driving without perception annotation,
X. Gui, J. Zhao, W. Han, J. Wang, J. Gong, F. Tan, C.-z. Xu, and J. Shen, “Trajdiff: End-to-end autonomous driving without perception annotation,”arXiv preprint arXiv:2512.00723, 2025
-
[18]
DIVER: Reinforced Diffusion Breaks Imitation Bottlenecks in End-to-End Autonomous Driving
Z. Song, L. Liu, H. Pan, B. Liao, M. Guo, L. Yang, Y . Zhang, S. Xu, C. Jia, and Y . Luo, “Diver: Reinforced diffusion breaks imi- tation bottlenecks in end-to-end autonomous driving,”arXiv preprint arXiv:2507.04049, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Pie: Perception and interaction enhanced end-to-end motion planning for autonomous driving,
C. Yuan, Z. Lu, Z. Zhang, Y . Zhao, Z. Huang, S. Sun, J. Sun, J. Li, C. D. W. Lee, D. Li,et al., “Pie: Perception and interaction enhanced end-to-end motion planning for autonomous driving,”arXiv preprint arXiv:2509.18609, 2025
-
[20]
Generalizing motion planners with mixture of experts for autonomous driving,
Q. Sun, H. Wang, J. Zhan, F. Nie, X. Wen, L. Xu, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Generalizing motion planners with mixture of experts for autonomous driving,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 6033–6039
2025
-
[21]
Trajmoe: Scene-adaptive trajectory planning with mixture of experts and reinforcement learning,
Z. Xing, P. Yang, L. Wang, Y . Zhang, Y . Hu, Y . Zheng, J. Wang, Y . Gao, G. Li, K. Ma,et al., “Trajmoe: Scene-adaptive trajectory planning with mixture of experts and reinforcement learning,”arXiv preprint arXiv:2512.07135, 2025
-
[22]
Geminus: Dual-aware global and scene-adaptive mixture-of-experts for end-to-end autonomous driving,
C. Wan, Y . Cui, J. Du, S. Yang, Y . Bai, P. Yi, N. Li, and Y . Huang, “Geminus: Dual-aware global and scene-adaptive mixture-of-experts for end-to-end autonomous driving,”arXiv preprint arXiv:2507.14456, 2025
-
[23]
Mose: Skill-by-skill mixture-of-experts learning for embodied autonomous machines,
L. Xu, J. Yu, X. Peng, Y . Chen, W. Li, J. Yoo, S. Chunag, D. Lee, D. Ji, and C. Zhang, “Mose: Skill-by-skill mixture-of-experts learning for embodied autonomous machines,”arXiv preprint arXiv:2507.07818, 2025
-
[24]
Expertad: Enhancing autonomous driving systems with mixture of experts,
H. Jiang, X. Huang, Y . Lu, D. Wang, Y . Cao, C. Sha, B. Chen, K. Chen, and X. Peng, “Expertad: Enhancing autonomous driving systems with mixture of experts,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 7, 2026, pp. 5378–5387
2026
-
[25]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
2017
-
[26]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone,et al., “Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 28 706– 28 719, 2024
2024
-
[27]
Hydra-mdp++: Advancing end-to-end driving via expert- guided hydra-distillation,
K. Li, Z. Li, S. Lan, Y . Xie, Z. Zhang, J. Liu, Z. Wu, Z. Yu, and J. M. Alvarez, “Hydra-mdp++: Advancing end-to-end driving via expert- guided hydra-distillation,”arXiv preprint arXiv:2503.12820, 2025
-
[28]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Vadv2: End-to-end vectorized autonomous driving via probabilistic planning,”arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Para- drive: Parallelized architecture for real-time autonomous driving,
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone, “Para- drive: Parallelized architecture for real-time autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 449–15 458
2024
-
[30]
Drivex: Omni scene modeling for learning generalizable world knowledge in autonomous driving,
C. Shi, S. Shi, K. Sheng, B. Zhang, and L. Jiang, “Drivex: Omni scene modeling for learning generalizable world knowledge in autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 28 599–28 609
2025
-
[31]
Enhancing End-to-End Autonomous Driving with Latent World Model
Y . Li, L. Fan, J. He, Y . Wang, Y . Chen, Z. Zhang, and T. Tan, “Enhancing end-to-end autonomous driving with latent world model,”arXiv preprint arXiv:2406.08481, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
S. Zeng, X. Chang, M. Xie, X. Liu, Y . Bai, Z. Pan, M. Xu, X. Wei, and N. Guo, “Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving,”arXiv preprint arXiv:2505.17685, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning
I. Rawal, S. Gupta, Y . Hu, and W. Zhan, “Nord: A data-efficient vision- language-action model that drives without reasoning,”arXiv preprint arXiv:2602.21172, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Epona: Autoregressive diffusion world model for autonomous driving,
K. Zhang, Z. Tang, X. Hu, X. Pan, X. Guo, Y . Liu, J. Huang, L. Yuan, Q. Zhang, X.-X. Long,et al., “Epona: Autoregressive diffusion world model for autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 27 220–27 230
2025
-
[35]
Distilldrive: End-to- end multi-mode autonomous driving distillation by isomorphic hetero- source planning model,
R. Yu, X. Zhang, R. Zhao, H. Yan, and M. Wang, “Distilldrive: End-to- end multi-mode autonomous driving distillation by isomorphic hetero- source planning model,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 26 188–26 197
2025
-
[36]
Prix: Learning to plan from raw pixels for end-to-end autonomous driving,
M. Wozniak, L. Liu, Y . Cai, and P. Jensfelt, “Prix: Learning to plan from raw pixels for end-to-end autonomous driving,”IEEE Robotics and Automation Letters, vol. 11, no. 5, pp. 6400–6407, 2026
2026
-
[37]
Drivesuprim: Towards precise trajectory selection for end-to-end plan- ning,
W. Yao, Z. Li, S. Lan, Z. Wang, X. Sun, J. M. Alvarez, and Z. Wu, “Drivesuprim: Towards precise trajectory selection for end-to-end plan- ning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 14, 2026, pp. 11 910–11 918
2026
-
[38]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang,et al., “Recogdrive: A reinforced cognitive framework for end- to-end autonomous driving,”arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
ipad: Iterative proposal-centric end-to-end autonomous driving
K. Guo, H. Liu, X. Wu, J. Pan, and C. Lv, “ipad: Itera- tive proposal-centric end-to-end autonomous driving,”arXiv preprint arXiv:2505.15111, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.