Caliper: Probing Lexical Anchors versus Causal Structure in LLMs
Pith reviewed 2026-06-28 05:50 UTC · model grok-4.3
The pith
Replacing semantic names with placeholders in causal questions causes large accuracy drops in instruction-tuned LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
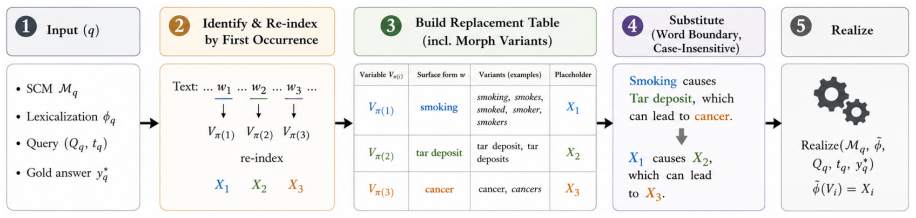
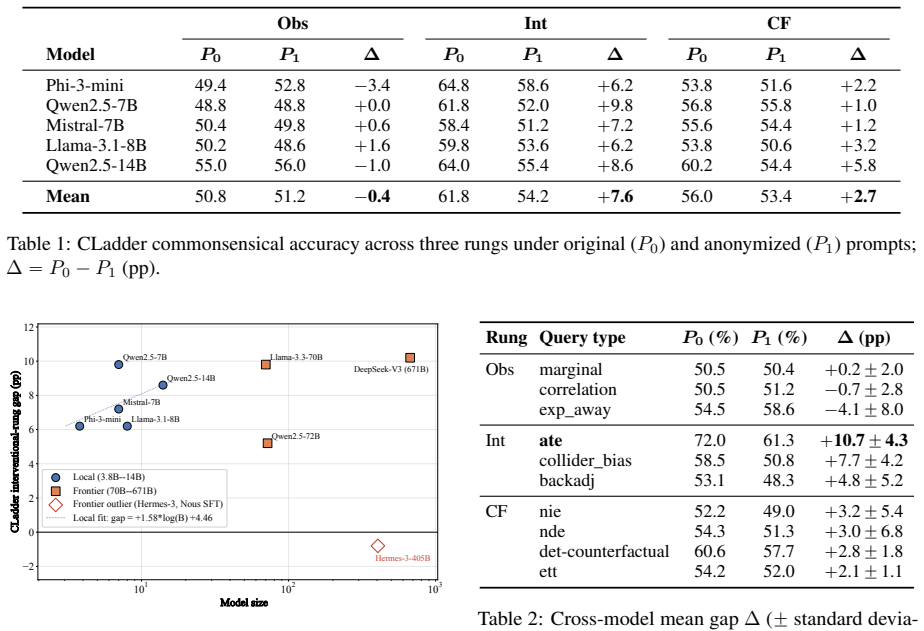
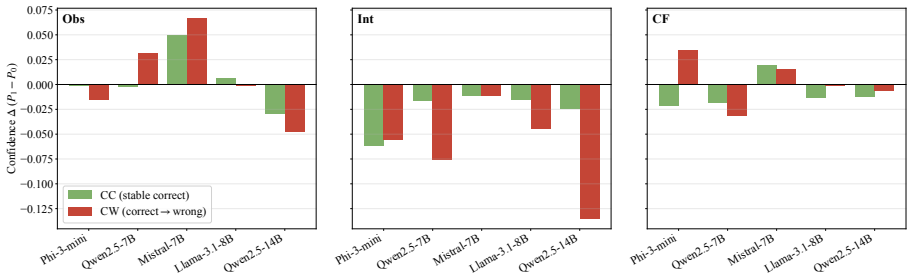
By applying Caliper to replace semantic variable names with placeholder tokens while preserving the causal graph and probabilistic specification, the evaluation reveals robust accuracy drops on causal reasoning benchmarks. Of 40 model-by-benchmark combinations, 39 exhibit positive gaps, with the effect diminishing on pseudoword subsets. This demonstrates that current instruction-tuned LLMs evaluated zero-shot exhibit little evidence of structural causal reasoning once lexical anchors are removed.
What carries the argument
Caliper, a controlled perturbation that replaces semantic variable names with placeholder tokens while preserving the causal graph and probabilistic specification of each question.
If this is right
- Lexical anonymization produces accuracy drops between 7.6 and 29.6 percentage points on CLadder, CRASS, and e-CARE across nine models.
- The accuracy gap shrinks dramatically on CLadder's pseudoword subset, confirming dependence on recognizable lexical items.
- Structured scaffolding and few-shot learning reduce the gap mainly by lowering performance on the original named questions rather than restoring performance on the anonymized versions.
- The drop appears in 39 of 40 model-by-benchmark cells and holds from 3.8B to 671B parameter models.
Where Pith is reading between the lines
- Causal benchmarks may need systematic use of abstract or randomized labels to isolate genuine structural reasoning.
- Training or fine-tuning regimes that deliberately expose models to anonymized causal graphs could be required to develop non-lexical reasoning.
- The same anonymization approach could be applied to other reasoning domains to check for hidden lexical dependencies.
Load-bearing premise
That replacing semantic variable names with placeholder tokens preserves the causal graph and probabilistic specification of each question without introducing unrelated difficulties that affect model performance.
What would settle it
A direct comparison in which models achieve statistically identical accuracy on the original and Caliper-perturbed versions of the same questions after any added difficulty from placeholders has been controlled.
Figures
read the original abstract
Large language models reach 50 to 70% accuracy on causal reasoning benchmarks such as CLadder, but it is unclear whether this reflects structural reasoning or lexical pattern matching. We introduce Caliper, a controlled perturbation that replaces semantic variable names with placeholder tokens while preserving the causal graph and probabilistic specification of each question. Across nine instruction-tuned LLMs from 3.8B to 671B and three causal reasoning benchmarks, lexical anonymization yields robust accuracy drops of +7.6, +27.0, and +11.1 pp on a local 3.8B-14B set, rising to +29.6 and +18.0 pp on CRASS and e-CARE across nine frontier models spanning the 2024-2026 generations. Of 40 engaged model-by-benchmark cells, 39 show a positive gap, and the gap collapses by 17x on CLadder's pseudoword subset. Structured scaffolding and few-shot in-context learning each narrow the gap, but mainly by lowering P0 accuracy on smaller models rather than recovering P1. Current instruction-tuned LLMs, evaluated zero-shot, show little evidence of structural causal reasoning once lexical anchors are removed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Caliper, a perturbation that replaces semantic variable names with placeholder tokens in causal reasoning benchmarks (CLadder, CRASS, e-CARE) while claiming to preserve the underlying causal graph and probabilistic specifications. Across nine instruction-tuned LLMs (3.8B–671B parameters) and three benchmarks, it reports consistent accuracy drops of +7.6 to +29.6 pp in 39 of 40 model-benchmark cells under zero-shot evaluation, with the gap collapsing 17x on CLadder's pseudoword subset. Structured scaffolding and few-shot learning narrow the gap mainly by reducing baseline accuracy rather than recovering performance on anonymized items. The central claim is that current LLMs show little evidence of structural causal reasoning once lexical anchors are removed.
Significance. If the perturbation cleanly isolates lexical effects, the results would provide direct empirical evidence that LLM performance on these benchmarks is driven primarily by lexical pattern matching rather than structural causal reasoning. The scale (nine models spanning 2024–2026 generations, three benchmarks, 40 cells) and the near-universal positive gap strengthen the finding. The work is purely empirical with no free parameters or circular derivations; the pseudoword control is a useful internal check. This would inform both capability assessment and benchmark construction in causal reasoning for LLMs.
major comments (2)
- [Methods / perturbation description] Perturbation validity (Methods / §3): the claim that placeholder replacement 'preserves the causal graph and probabilistic specification' is load-bearing for attributing accuracy drops to absence of structural reasoning. The manuscript provides insufficient detail on (a) how placeholders were selected to avoid tokenization boundary shifts or OOD format effects, (b) explicit controls comparing token-level statistics or parsing difficulty between P0 and P1 versions, and (c) whether the anonymized templates remain within the models' training distribution. Without these, drops could arise from non-lexical confounds even if models perform structural reasoning when anchors are present.
- [Results] Statistical reporting (Results / abstract): the abstract states 'consistent positive gaps in 39 of 40 cells' and specific deltas (+7.6, +27.0, +29.6 pp) but does not report per-cell standard errors, p-values, or confidence intervals. Given that the central claim rests on the robustness of these gaps across model sizes and benchmarks, the absence of significance testing or variance estimates weakens the ability to rule out noise, especially on smaller models where variance is typically higher.
minor comments (2)
- [Methods] Clarify the exact placeholder vocabulary and sampling procedure (e.g., whether placeholders are drawn from a fixed set or generated per question) to allow replication.
- [Results] Figure or table showing per-model per-benchmark accuracy for both P0 and P1 conditions would improve readability; current aggregate deltas make it hard to inspect outliers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Methods / perturbation description] Perturbation validity (Methods / §3): the claim that placeholder replacement 'preserves the causal graph and probabilistic specification' is load-bearing for attributing accuracy drops to absence of structural reasoning. The manuscript provides insufficient detail on (a) how placeholders were selected to avoid tokenization boundary shifts or OOD format effects, (b) explicit controls comparing token-level statistics or parsing difficulty between P0 and P1 versions, and (c) whether the anonymized templates remain within the models' training distribution. Without these, drops could arise from non-lexical confounds even if models perform structural reasoning when anchors are present.
Authors: We agree that expanded documentation of the perturbation would strengthen the manuscript. In revision we will augment §3 with: (a) explicit description of placeholder selection (neutral tokens such as VAR1/VAR2 chosen to avoid boundary shifts and format changes), and (b) quantitative comparisons of token length, frequency, and parsing difficulty between P0 and P1 versions. For (c), we will add a limitations paragraph noting that direct verification against proprietary training corpora is not possible and will report any available proxies (e.g., perplexity). revision: partial
-
Referee: [Results] Statistical reporting (Results / abstract): the abstract states 'consistent positive gaps in 39 of 40 cells' and specific deltas (+7.6, +27.0, +29.6 pp) but does not report per-cell standard errors, p-values, or confidence intervals. Given that the central claim rests on the robustness of these gaps across model sizes and benchmarks, the absence of significance testing or variance estimates weakens the ability to rule out noise, especially on smaller models where variance is typically higher.
Authors: We accept that variance estimates would improve transparency. In the revised manuscript we will add per-cell standard errors (or bootstrap intervals where feasible) to the Results section and will note them in the abstract. Because the evaluations are deterministic zero-shot on fixed items, traditional run-to-run variance is limited, but we will also report stability across prompt paraphrases and data subsets to address the concern. revision: yes
- Direct assessment of whether anonymized templates lie inside each model's training distribution, which cannot be performed without access to proprietary training data.
Circularity Check
No circularity: purely empirical perturbation study with no derivations or self-referential quantities
full rationale
The paper introduces Caliper as a controlled lexical perturbation on existing causal benchmarks (CLadder, CRASS, e-CARE) and reports accuracy drops across models. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on direct zero-shot measurements and the observation that the gap collapses on the pseudoword subset; these are falsifiable empirical results, not reductions to the paper's own inputs by construction. The perturbation's validity is an assumption open to external testing rather than a self-definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The placeholder substitution preserves the causal graph and probabilistic specification exactly.
Reference graph
Works this paper leans on
-
[2]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, and 1 others. 2020. https://arxiv.org/abs/2005.14165 Language models are few-shot learners . In Advances in Neural Information Processing Systems (NeurIPS)
Pith/arXiv arXiv 2020
-
[3]
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tram \`e r, and Chiyuan Zhang. 2023. https://openreview.net/forum?id=TatRHT_1cK Quantifying memorization across neural language models . In International Conference on Learning Representations (ICLR)
2023
-
[4]
Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, and Baishakhi Ray. 2025. https://aclanthology.org/2025.emnlp-main.511 Benchmarking large language models under data contamination: A survey from static to dynamic evaluation . In Proceedings of the 2025 Conference on Empirical Methods in Natu...
2025
-
[5]
Haoang Chi, He Li, Wenjing Yang, Feng Liu, Long Lan, Xiaoguang Ren, Tongliang Liu, and Bo Han. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/af2bb2b2280d36f8842e440b4e275152-Abstract-Conference.html Unveiling causal reasoning in large language models: Reality or mirage? In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[6]
DeepSeek-AI . 2024. https://arxiv.org/abs/2412.19437 DeepSeek-V3 technical report . Preprint, arXiv:2412.19437
Pith/arXiv arXiv 2024
-
[7]
Zahra Dehghanighobadi, Asja Fischer, and Muhammad Bilal Zafar. 2025. https://aclanthology.org/2025.emnlp-main.396 Can LLM s explain themselves counterfactually? In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
-
[8]
Li Du, Xiao Ding, Kai Xiong, Ting Liu, and Bing Qin. 2022. https://doi.org/10.18653/v1/2022.acl-long.33 e- CARE : A new dataset for exploring explainable causal reasoning . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pages 432--446
-
[9]
Tibshirani
Bradley Efron and Robert J. Tibshirani. 1993. An Introduction to the Bootstrap. Chapman & Hall/CRC
1993
-
[10]
Yanai Elazar, Hongming Zhang, Yoav Goldberg, and Dan Roth. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.819 Back to square one: Artifact detection, training and commonsense disentanglement in the W inograd schema . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP)
-
[11]
Tao Feng, Lizhen Qu, Niket Tandon, Zhuang Li, Xiaoxi Kang, and Gholamreza Haffari. 2025. https://aclanthology.org/2025.acl-long.471 On the reliability of large language models for causal discovery . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL)
2025
-
[12]
J \"o rg Frohberg and Frank Binder. 2022. https://aclanthology.org/2022.lrec-1.229 CRASS : A novel data set and benchmark to test counterfactual reasoning of large language models . In Proceedings of the Thirteenth Language Resources and Evaluation Conference (LREC), pages 2126--2140
2022
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, and 1 others. 2024. https://arxiv.org/abs/2407.21783 The Llama 3 herd of models . arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[14]
Choquette-Choo, Katherine Lee, and A
Jamie Hayes, Marika Swanberg, Harsh Chaudhari, Itay Yona, Ilia Shumailov, Milad Nasr, Christopher A. Choquette-Choo, Katherine Lee, and A. Feder Cooper. 2025. https://aclanthology.org/2025.naacl-long.469 Measuring memorization in language models via probabilistic extraction . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of ...
2025
-
[15]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, and 1 others. 2023. https://arxiv.org/abs/2310.06825 Mistral 7B . arXiv preprint arXiv:2310.06825
Pith/arXiv arXiv 2023
-
[16]
Zhijing Jin, Yuen Chen, Felix Leeb, Luigi Gresele, Ojasv Kamal, Zhiheng Lyu, Kevin Blin, Fernando Gonzalez Adauto, Max Kleiman-Weiner, Mrinmaya Sachan, and Bernhard Sch \"o lkopf. 2023. https://arxiv.org/abs/2312.04350 CL adder: Assessing causal reasoning in language models . In Advances in Neural Information Processing Systems (NeurIPS)
arXiv 2023
-
[18]
Xiaoyu Liu, Paiheng Xu, Junda Wu, Jiaxin Yuan, Yifan Yang, Yuhang Zhou, Fuxiao Liu, Tianrui Guan, Haoliang Wang, Tong Yu, Julian McAuley, Wei Ai, and Furong Huang. 2025. https://aclanthology.org/2025.findings-naacl.427 Large language models and causal inference in collaboration: A comprehensive survey . In Findings of the Association for Computational Lin...
2025
-
[19]
Inbal Magar and Roy Schwartz. 2022. https://doi.org/10.18653/v1/2022.acl-short.18 Data contamination: From memorization to exploitation . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), Short Papers, pages 157--165
-
[20]
Tom McCoy, Ellie Pavlick, and Tal Linzen. 2019. https://doi.org/10.18653/v1/P19-1334 Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pages 3428--3448
-
[21]
Tarun Ram Menta, Susmit Agrawal, and Chirag Agarwal. 2025. https://aclanthology.org/2025.naacl-long.535 Analyzing memorization in large language models through the lens of model attribution . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL)
2025
-
[22]
Martina Miliani, Serena Auriemma, Alessandro Bondielli, Emmanuele Chersoni, Lucia Passaro, Irene Sucameli, and Alessandro Lenci. 2025. https://aclanthology.org/2025.findings-acl.891 ExpliCa : Evaluating explicit causal reasoning in large language models . In Findings of the Association for Computational Linguistics: ACL 2025
2025
-
[23]
Nous Research . 2024. https://arxiv.org/abs/2408.11857 Hermes 3 technical report . Preprint, arXiv:2408.11857
arXiv 2024
-
[24]
Judea Pearl. 2009. Causality: Models, Reasoning, and Inference, 2 edition. Cambridge University Press, Cambridge, UK
2009
-
[25]
Qwen Team . 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
Pith/arXiv arXiv 2025
-
[26]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. https://doi.org/10.18653/v1/2020.acl-main.442 Beyond accuracy: Behavioral testing of NLP models with C heck L ist . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 4902--4912
-
[27]
Rahul Babu Shrestha, Simon Malberg, and Georg Groh. 2025. https://aclanthology.org/2025.nlp4dh-1.29 From causal parrots to causal prophets? T owards sound causal reasoning with large language models . In Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities (NLP4DH)
2025
-
[28]
Longxuan Yu, Delin Chen, Siheng Xiong, Qingyang Wu, Dawei Li, Zhikai Chen, Xiaoze Liu, and Liangming Pan. 2025. https://aclanthology.org/2025.naacl-long.622 CausalEval : Towards better causal reasoning in language models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL)
2025
-
[29]
Matej Ze c evi \'c , Moritz Willig, Devendra Singh Dhami, and Kristian Kersting. 2023. https://openreview.net/forum?id=tv46tCzs83 Causal parrots: Large language models may talk causality but are not causal . Transactions on Machine Learning Research
2023
-
[30]
Yu Zhou, Xingyu Wu, Beicheng Huang, Jibin Wu, Liang Feng, and Kay Chen Tan. 2024. https://arxiv.org/abs/2404.06349 CausalBench : A comprehensive benchmark for causal learning capability of LLM s . arXiv preprint arXiv:2404.06349
arXiv 2024
-
[31]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[32]
Publications Manual , year = "1983", publisher =
1983
-
[33]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[34]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[35]
Dan Gusfield , title =. 1997
1997
-
[36]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[37]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[38]
arXiv preprint arXiv:2404.14219 , year=
Phi-3 technical report: A highly capable language model locally on your phone , author=. arXiv preprint arXiv:2404.14219 , year=
-
[39]
International Conference on Learning Representations (ICLR) , year=
Synthetic and natural noise both break neural machine translation , author=. International Conference on Learning Representations (ICLR) , year=
-
[40]
International Conference on Learning Representations (ICLR) , year=
Quantifying memorization across neural language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[41]
Back to square one: Artifact detection, training and commonsense disentanglement in the
Elazar, Yanai and Zhang, Hongming and Goldberg, Yoav and Roth, Dan , booktitle=. Back to square one: Artifact detection, training and commonsense disentanglement in the. 2021 , doi=
2021
-
[42]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , doi=
2020
-
[43]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages=
Annotation artifacts in natural language inference data , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages=. 2018 , doi=
2018
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Jin, Zhijing and Chen, Yuen and Leeb, Felix and Gresele, Luigi and Kamal, Ojasv and Lyu, Zhiheng and Blin, Kevin and Adauto, Fernando Gonzalez and Kleiman-Weiner, Max and Sachan, Mrinmaya and Sch. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[45]
arXiv preprint arXiv:2305.00050 , year=
Causal reasoning and large language models: Opening a new frontier for causality , author=. arXiv preprint arXiv:2305.00050 , year=
-
[46]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), Short Papers , pages=
Data contamination: From memorization to exploitation , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), Short Papers , pages=. 2022 , doi=
2022
-
[47]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , pages=. 2019 , doi=
2019
-
[48]
Beyond accuracy: Behavioral testing of
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer , booktitle=. Beyond accuracy: Behavioral testing of. 2020 , doi=
2020
-
[49]
Transactions on Machine Learning Research , year=
Causal parrots: Large language models may talk causality but are not causal , author=. Transactions on Machine Learning Research , year=
-
[50]
Proceedings of the Thirteenth Language Resources and Evaluation Conference (LREC) , pages=
Frohberg, J. Proceedings of the Thirteenth Language Resources and Evaluation Conference (LREC) , pages=. 2022 , url=
2022
-
[51]
Du, Li and Ding, Xiao and Xiong, Kai and Liu, Ting and Qin, Bing , booktitle=. e-. 2022 , doi=
2022
-
[52]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , year=
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[54]
2024 , eprint=
Hermes 3 technical report , author=. 2024 , eprint=
2024
-
[55]
2009 , publisher =
Causality: Models, Reasoning, and Inference , author =. 2009 , publisher =
2009
-
[56]
Biometrics Bulletin , volume =
Wilcoxon, Frank , title =. Biometrics Bulletin , volume =. 1945 , doi =
1945
-
[57]
, title =
Efron, Bradley and Tibshirani, Robert J. , title =. 1993 , isbn =
1993
-
[58]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and others , journal =. 2023 , url =
2023
-
[59]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and others , journal =. The. 2024 , url =
2024
-
[60]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Unveiling Causal Reasoning in Large Language Models: Reality or Mirage? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[61]
2025 , url =
Yu, Longxuan and Chen, Delin and Xiong, Siheng and Wu, Qingyang and Li, Dawei and Chen, Zhikai and Liu, Xiaoze and Pan, Liangming , booktitle =. 2025 , url =
2025
-
[62]
From Causal Parrots to Causal Prophets?
Shrestha, Rahul Babu and Malberg, Simon and Groh, Georg , booktitle =. From Causal Parrots to Causal Prophets?. 2025 , url =
2025
-
[63]
Findings of the Association for Computational Linguistics: NAACL 2025 , year =
Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey , author =. Findings of the Association for Computational Linguistics: NAACL 2025 , year =
2025
-
[64]
2024 , url =
Zhou, Yu and Wu, Xingyu and Huang, Beicheng and Wu, Jibin and Feng, Liang and Tan, Kay Chen , journal =. 2024 , url =
2024
-
[65]
2025 , url =
Miliani, Martina and Auriemma, Serena and Bondielli, Alessandro and Chersoni, Emmanuele and Passaro, Lucia and Sucameli, Irene and Lenci, Alessandro , booktitle =. 2025 , url =
2025
-
[66]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Benchmarking Large Language Models Under Data Contamination: A Survey from Static to Dynamic Evaluation , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2025
-
[67]
Dehghanighobadi, Zahra and Fischer, Asja and Zafar, Muhammad Bilal , booktitle =. Can. 2025 , url =
2025
-
[68]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
On the Reliability of Large Language Models for Causal Discovery , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[69]
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year =
Analyzing Memorization in Large Language Models through the Lens of Model Attribution , author =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year =
2025
-
[70]
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year =
Measuring memorization in language models via probabilistic extraction , author =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.