Be Fair! Can Machine Learning Engineering Agents Adhere to Fairness Constraints?
Pith reviewed 2026-06-28 07:07 UTC · model grok-4.3
The pith
Machine learning engineering agents generate pipelines with high variance that underperform human baselines on both accuracy and fairness in melanoma classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When evaluating two recent MLE agents on melanoma classification with a skin-tone fairness constraint, agent-generated pipelines show high variance and consistently underperform manually designed baselines in both predictive quality and fairness, despite fairness-oriented prompts.
What carries the argument
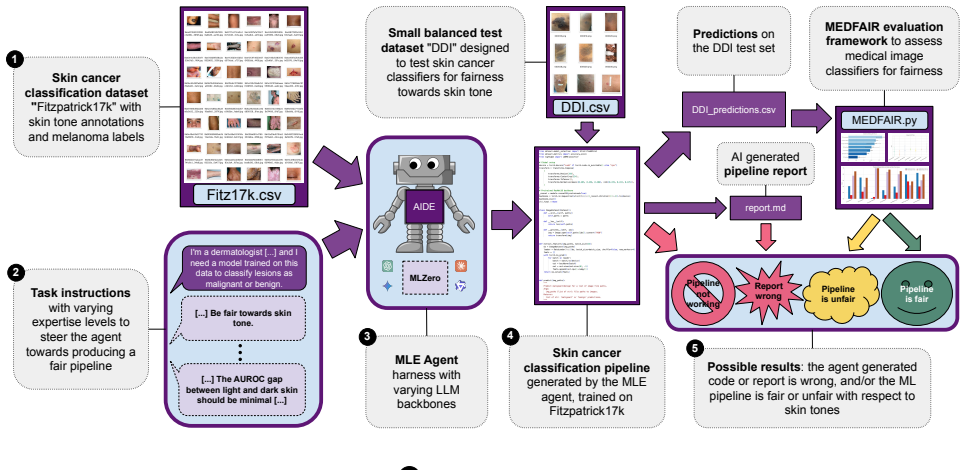
Exploratory evaluation of MLE agents on a melanoma classification task that enforces fairness across skin tones as the responsibility constraint.
If this is right
- MLE agents need redesign to let humans guide the search process during pipeline creation.
- Methods must be developed to let users reliably assess compliance and quality of generated pipelines.
- Current benchmarks are insufficient for judging whether MLE agents can be used safely in regulated domains.
Where Pith is reading between the lines
- The observed variance may stem from lack of built-in mechanisms for tracking how design choices affect fairness.
- Similar shortfalls could appear when agents face other constraints such as robustness or regulatory rules.
- Adding explicit human oversight loops during generation might reduce inconsistency in future agent versions.
Load-bearing premise
That the specific melanoma classification task with a skin-tone fairness constraint is representative enough of broader responsibility constraints to support general conclusions about MLE agent safety in sensitive domains.
What would settle it
If agent-generated pipelines on the melanoma task or a comparable task match or exceed manual baselines in both predictive quality and fairness measures, the reported underperformance would not hold.
Figures

read the original abstract
Machine learning engineering (MLE) agents promise to automate end-to-end ML pipeline development from raw data and natural language instructions, potentially making ML accessible to non-technical domain experts. However, in sensitive and regulated domains, this abstraction creates a responsibility gap: end-users may lack visibility into design choices that affect correctness, robustness, fairness, and regulatory compliance. We argue that existing benchmarks are insufficient to assess whether MLE agents can be safely applied in such settings. We propose desiderata for a responsibility-centered evaluation framework and conduct an exploratory study on melanoma classification, focusing on fairness across skin tones as a responsibility constraint. When evaluating two recent MLE agents, we find that agent-generated pipelines show high variance and consistently underperform manually designed baselines in both predictive quality and fairness, despite fairness-oriented prompts. These preliminary results suggest that further research is needed towards redesigning MLE agents to allow humans to guide the search process and reliably assess the compliance and quality of the generated ML pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that MLE agents create a responsibility gap in sensitive domains because end-users lack visibility into design choices affecting correctness, robustness, fairness, and compliance. Existing benchmarks are insufficient, so the authors propose desiderata for a responsibility-centered evaluation framework. They conduct an exploratory study on melanoma classification with a skin-tone fairness constraint, finding that two recent MLE agents produce pipelines with high variance that consistently underperform manually designed baselines on both predictive quality and fairness, even with fairness-oriented prompts. The results suggest that MLE agents need redesign to support human guidance and reliable compliance assessment.
Significance. If the empirical pattern holds beyond the reported task, the work identifies a practical barrier to safe deployment of automated ML engineering in regulated settings and supplies an initial responsibility-focused evaluation template. The explicit call for human-in-the-loop search mechanisms and the framing around a concrete fairness constraint provide a concrete starting point for subsequent agent redesign research.
major comments (2)
- [Abstract; experimental study description] The central empirical claim (high variance and consistent underperformance relative to manual baselines) rests on a single melanoma classification task with a skin-tone constraint. This is load-bearing for the manuscript's suggestion that agents require redesign for safe use in sensitive domains, because other responsibility constraints (privacy budgets, distribution-shift robustness, regulatory auditability) may interact differently with agent search strategies, as noted in the stress-test concern.
- [Abstract; results paragraph] The abstract states that agent pipelines show 'high variance and consistently underperform' but supplies no dataset sizes, number of runs, statistical tests, or error bars. Without these details the robustness of the reported performance gap cannot be assessed, directly affecting the strength of the call for agent redesign.
minor comments (1)
- [Introduction / desiderata paragraph] The desiderata for the responsibility-centered framework are introduced but not enumerated in the provided abstract; a numbered list or table would improve clarity for readers attempting to apply the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our exploratory study. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract; experimental study description] The central empirical claim (high variance and consistent underperformance relative to manual baselines) rests on a single melanoma classification task with a skin-tone constraint. This is load-bearing for the manuscript's suggestion that agents require redesign for safe use in sensitive domains, because other responsibility constraints (privacy budgets, distribution-shift robustness, regulatory auditability) may interact differently with agent search strategies, as noted in the stress-test concern.
Authors: We agree that the evaluation is confined to a single task and constraint, which limits the generalizability of the empirical pattern. The manuscript already frames the work as exploratory and calls for further research on agent redesign; we will revise the discussion section to more explicitly state this scope limitation, note that other constraints may interact differently with agent strategies, and outline directions for broader stress-testing. This revision will better contextualize the findings without changing the core observation from the reported study. revision: yes
-
Referee: [Abstract; results paragraph] The abstract states that agent pipelines show 'high variance and consistently underperform' but supplies no dataset sizes, number of runs, statistical tests, or error bars. Without these details the robustness of the reported performance gap cannot be assessed, directly affecting the strength of the call for agent redesign.
Authors: We agree that the abstract should convey key experimental parameters to allow readers to assess robustness. The full manuscript reports the experimental protocol (including dataset details and multiple runs), but we will revise the abstract to include dataset size, number of runs, and a brief mention of observed variance. We will also verify that error bars and any applicable statistical information are clearly presented in the results figures and text. revision: yes
Circularity Check
No circularity: direct empirical comparison without derivations or self-referential fits
full rationale
The paper performs an exploratory empirical study evaluating two MLE agents on melanoma classification with a skin-tone fairness constraint, comparing agent-generated pipelines to manually designed baselines. No equations, fitted parameters, or derivation chains appear in the work. The central claim (high variance and underperformance despite fairness prompts) rests on direct experimental measurements rather than reducing to self-definitions, renamed known results, or load-bearing self-citations. The single-task limitation noted in the skeptic attack concerns generalizability of conclusions, not circularity in the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Investigating the Quality of DermaMNIST and Fitzpatrick17k Dermatological Image Datasets.Scientific Data12, 1, 2025
Abhishek et al. Investigating the Quality of DermaMNIST and Fitzpatrick17k Dermatological Image Datasets.Scientific Data12, 1, 2025
2025
-
[2]
Gender Shades: Intersectional Accuracy Disparities in Com- mercial Gender Classification.FAccT’18
Boulamwini et al. Gender Shades: Intersectional Accuracy Disparities in Com- mercial Gender Classification.FAccT’18
-
[3]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering.ICLR’25
Chan et al . MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering.ICLR’25
-
[4]
Disparities in dermatology AI performance on a diverse, curated clinical image set.Science Advances8, 32, 2022
Daneshjou et al. Disparities in dermatology AI performance on a diverse, curated clinical image set.Science Advances8, 32, 2022
2022
-
[5]
Chameleon: Foundation Models for Fairness-aware Multi-modal Data Augmentation to Enhance Coverage of Minorities.VLDB’24
Erfanian et al. Chameleon: Foundation Models for Fairness-aware Multi-modal Data Augmentation to Enhance Coverage of Minorities.VLDB’24
-
[6]
EU AI Act, Regulation 2024/1689, https://eur-lex.europa.eu/eli/reg/2024/1689/oj
2024
-
[7]
Mlzero: A multi-agent system for end-to-end machine learning automation.NeurIPS’25
Fang et al . Mlzero: A multi-agent system for end-to-end machine learning automation.NeurIPS’25
-
[8]
CatDB: Data-Catalog-Guided, LLM-Based Generation of Data-Centric ML Pipelines.VLDB’25
Fathollahzadeh et al. CatDB: Data-Catalog-Guided, LLM-Based Generation of Data-Centric ML Pipelines.VLDB’25
-
[9]
Artificial Intelligence-Enabled Device Software Functions: Lifecycle Man- agement and Marketing Submission Recommendations
FDA. Artificial Intelligence-Enabled Device Software Functions: Lifecycle Man- agement and Marketing Submission Recommendations
-
[10]
Dataprism: Disconnect between data and systems.SIGMOD’22
Galhotra et al. Dataprism: Disconnect between data and systems.SIGMOD’22
-
[11]
Data distribution debugging in ML pipelines.VLDBJ’21
Grafberger et al. Data distribution debugging in ML pipelines.VLDBJ’21
-
[12]
Evaluating deep neural networks trained on clinical images in dermatology with the fitzpatrick 17k dataset.CVPR’21
Groh et al . Evaluating deep neural networks trained on clinical images in dermatology with the fitzpatrick 17k dataset.CVPR’21
-
[13]
Automated data cleaning can hurt fairness in machine learning-based decision making.TKDE’23
Guha et al. Automated data cleaning can hurt fairness in machine learning-based decision making.TKDE’23
-
[14]
AIDE: AI-Driven Exploration in the Space of Code
Jiang et al. AIDE: AI-Driven Exploration in the Space of Code.arXiv:2502.13138
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
What is Wrong With Automation Bias?.Phil
Jovchevski et al. What is Wrong With Automation Bias?.Phil. & Tech.’26
-
[16]
Navigating data errors in ML pipelines.SIGMOD’25
Karlaš et al. Navigating data errors in ML pipelines.SIGMOD’25
-
[17]
Minimax pareto fairness: A multi objective perspectiveICML’20
Martinez et al. Minimax pareto fairness: A multi objective perspectiveICML’20
-
[18]
Mle-star: Machine learning engineering agent via search and targeted refinement.NeurIPS’25
Nam et al. Mle-star: Machine learning engineering agent via search and targeted refinement.NeurIPS’25
-
[19]
From Benchmarking to Understanding FairML.ECAI’25
Pechenizkiy et al. From Benchmarking to Understanding FairML.ECAI’25
-
[20]
stratum: A System Infrastructure for Massive Agent-Centric ML Workloads.arXiv:2603.03589
Phani et al. stratum: A System Infrastructure for Massive Agent-Centric ML Workloads.arXiv:2603.03589
-
[21]
Everyone wants to do the model work, not the data work
Sambasivan et al. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI.CHI’25
-
[22]
Through the fairness lens: Experimental analysis and evalua- tion of entity matching.VLDB’23
Sambasivan et al. Through the fairness lens: Experimental analysis and evalua- tion of entity matching.VLDB’23
-
[23]
Taming Technical Bias in ML PipelinesIEEE DEBull’20
Schelter et al. Taming Technical Bias in ML PipelinesIEEE DEBull’20
-
[24]
Responsible data management.Comm
Stoyanovich et al. Responsible data management.Comm. ACM65, 6
-
[25]
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench.NeurIPS’25
Toledo et al. AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench.NeurIPS’25
-
[26]
SIIM-ISIC Melanoma Classification 2020, Kaggle
Zawacki et al . SIIM-ISIC Melanoma Classification 2020, Kaggle. https://kaggle.com/competitions/siim-isic-melanoma-classification
2020
-
[27]
MEDFAIR: benchmarking fairness for medical imaging.ICLR’22
Zong et al. MEDFAIR: benchmarking fairness for medical imaging.ICLR’22. 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.