AlphaQ: Calibration-Free Bit Allocation for Mixture-of-Experts Quantization
Pith reviewed 2026-06-28 07:03 UTC · model grok-4.3
The pith
A calibration-free method uses weight spectral heavy-tailedness to allocate bits across MoE experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
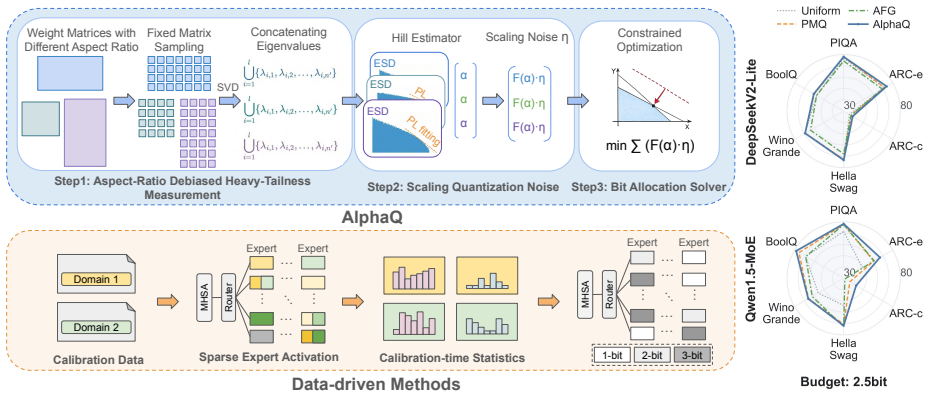
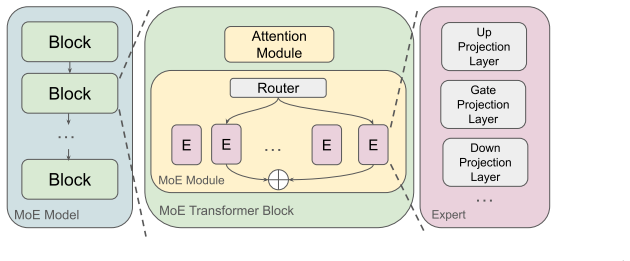
AlphaQ operationalizes the principle that experts with more heavy-tailed weight spectra are better trained and should receive higher bit-widths by measuring expert-wise spectral heavy-tailedness and solving a budget-constrained optimization problem that minimizes total quantization error.
What carries the argument
Expert-wise measurement of spectral heavy-tailedness from HT-SR theory to rank experts for bit allocation in a global optimization under bit budget.
Load-bearing premise
The heavy-tailedness of an expert's weight spectrum reliably signals its training quality and thus its deservingness of higher bit precision.
What would settle it
Observing that models quantized with the opposite allocation—higher bits to less heavy-tailed experts—achieve higher accuracy than AlphaQ under the same budget would falsify the claim.
Figures

read the original abstract
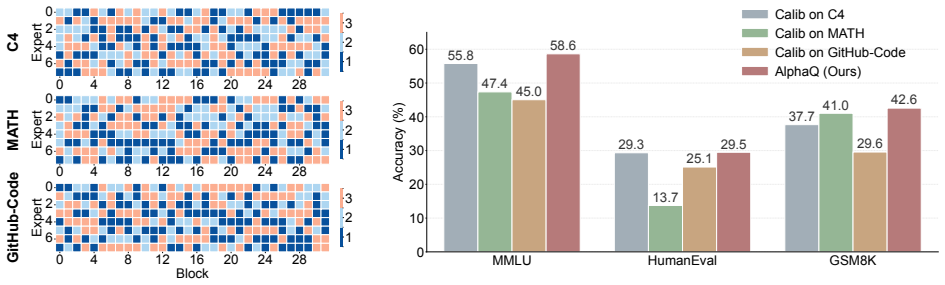
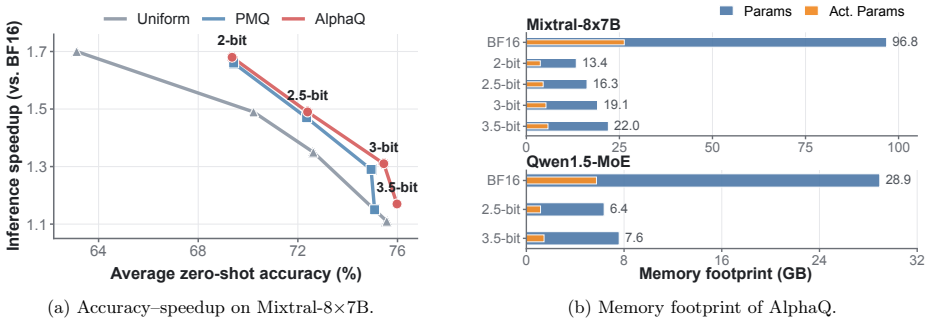
Mixture-of-Experts (MoE) architectures scale model capacity through sparse expert activation, but their deployment remains memory-bound because all expert weights must reside in memory. Mixed-precision quantization can substantially reduce this footprint by assigning different bit-widths to different experts. Existing approaches, however, typically rely on calibration data to estimate expert importance and determine bit allocation. For frontier MoE LLMs, the original training data, and hence the true training distribution, is proprietary and inaccessible. As a result, calibration sets are inevitably imperfect surrogates, and this can misestimate expert utilization and lead to suboptimal bit allocation. Motivated by the substantial cross-expert quality variability observed in modern MoE models, and by the success of Heavy-Tailed Self-Regularization (HT-SR) theory at predicting neural network model quality without access to training or testing data, we propose AlphaQ, a calibration-free bit-allocation method for MoE quantization. AlphaQ draws on HT-SR theory and follows a simple principle: experts with more heavy-tailed weight spectra are typically better trained and hence should receive higher bit-widths, while experts with weaker heavy-tailed structure can be quantized more aggressively. AlphaQ operationalizes this principle by measuring expert-wise spectral heavy-tailedness and solving a budget-constrained optimization problem that minimizes total quantization error under a global bit-budget constraint. Across several MoE models, AlphaQ consistently outperforms calibration-based baselines under matched bit budgets. Notably, on Qwen1.5-MoE, AlphaQ achieves near full-precision accuracy with an average expert precision of only 3.5 bits, while delivering more than 4$\times$ memory compression. Our code is available at https://github.com/Superone77/AlphaQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AlphaQ, a calibration-free mixed-precision quantization method for Mixture-of-Experts (MoE) models. It applies Heavy-Tailed Self-Regularization (HT-SR) theory to measure the heavy-tailedness of each expert's weight spectrum and solves a budget-constrained optimization to assign higher bit-widths to experts with stronger heavy-tailed spectra, claiming consistent outperformance over calibration-based baselines. On Qwen1.5-MoE it reports near full-precision accuracy at 3.5-bit average expert precision with >4× memory compression.
Significance. If the HT-SR heavy-tailedness measure reliably ranks expert quality and quantization sensitivity without any activation or calibration data, the result would enable practical deployment of frontier MoE LLMs where training data is inaccessible. The approach avoids the documented risk that imperfect calibration sets misestimate expert utilization.
major comments (3)
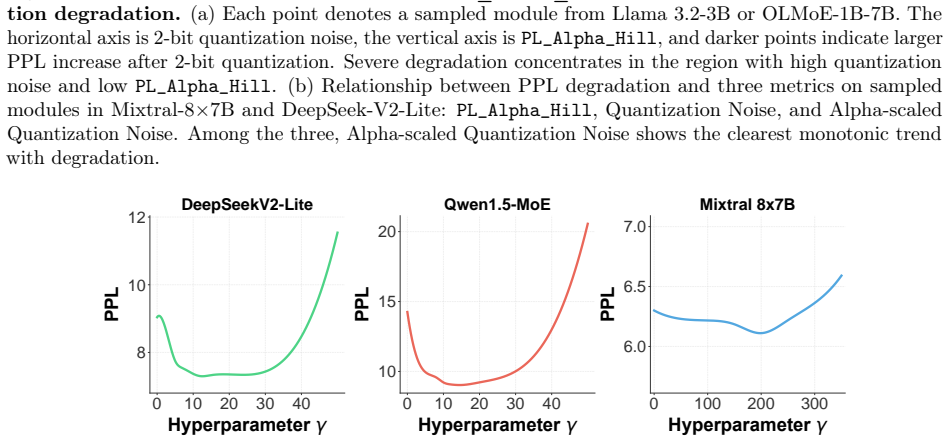
- [Abstract / principle statement] The central claim rests on the untested transfer of whole-model HT-SR results to per-expert bit allocation in sparsely activated MoE architectures. No ablation, correlation plot, or sensitivity analysis is shown demonstrating that experts with higher measured heavy-tailedness suffer larger accuracy drops under aggressive quantization than lower-HT experts (see skeptic note on weakest assumption).
- [Abstract / method description] The abstract states that AlphaQ 'solves a budget-constrained optimization problem that minimizes total quantization error,' yet supplies no description of the objective function, the precise definition of per-expert quantization error, the solver used, or any guarantee that the resulting allocation is unique or stable under small perturbations of the HT-SR scores.
- [Abstract / experimental claim] The reported result on Qwen1.5-MoE (near full-precision at 3.5 bits, >4× compression) is presented without controls for routing frequency, expert interaction effects, or statistical significance across multiple random seeds or calibration-set choices; these omissions make it impossible to isolate the contribution of the HT-SR allocation from other factors.
minor comments (1)
- Notation for the HT-SR heavy-tailedness metric (e.g., power-law exponent or related quantity) should be defined explicitly in the main text rather than left implicit from prior HT-SR literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / principle statement] The central claim rests on the untested transfer of whole-model HT-SR results to per-expert bit allocation in sparsely activated MoE architectures. No ablation, correlation plot, or sensitivity analysis is shown demonstrating that experts with higher measured heavy-tailedness suffer larger accuracy drops under aggressive quantization than lower-HT experts (see skeptic note on weakest assumption).
Authors: We acknowledge that the direct per-expert validation of the HT-SR to quantization sensitivity link is an assumption transferred from whole-model results in prior HT-SR literature. Our empirical results across multiple MoE models demonstrate consistent outperformance, supporting the principle, but we agree that explicit ablations would strengthen the claim. In revision we will add a correlation plot between per-expert HT-SR scores and observed accuracy drop under uniform low-bit quantization, plus a sensitivity analysis. revision: yes
-
Referee: [Abstract / method description] The abstract states that AlphaQ 'solves a budget-constrained optimization problem that minimizes total quantization error,' yet supplies no description of the objective function, the precise definition of per-expert quantization error, the solver used, or any guarantee that the resulting allocation is unique or stable under small perturbations of the HT-SR scores.
Authors: The abstract is intentionally high-level; the full manuscript (Section 3) defines the objective as minimizing the sum of per-expert errors where error is inversely proportional to the HT-SR heavy-tailedness score (serving as a proxy for sensitivity), formulates it as a 0-1 knapsack problem, and solves it via a standard dynamic programming approach. We will revise the abstract to include a concise description of the objective and solver, and add a short stability analysis under HT-SR score perturbation. revision: partial
-
Referee: [Abstract / experimental claim] The reported result on Qwen1.5-MoE (near full-precision at 3.5 bits, >4× compression) is presented without controls for routing frequency, expert interaction effects, or statistical significance across multiple random seeds or calibration-set choices; these omissions make it impossible to isolate the contribution of the HT-SR allocation from other factors.
Authors: The method is calibration-free, so calibration-set variation does not apply. Routing frequency is inherent to the MoE forward pass and our bit allocation is independent of it; we will add an analysis of allocation vs. routing frequency in the revision. For statistical significance we will report mean and std over 3 random seeds for the Qwen1.5-MoE result. Expert interaction effects are a broader MoE property not isolated in prior quantization work either, but we can note this limitation explicitly. revision: partial
Circularity Check
No significant circularity; derivation applies external HT-SR principle to new MoE setting
full rationale
The paper measures per-expert spectral heavy-tailedness directly from weights, then feeds those measurements into a budget-constrained optimizer that assigns bit-widths. This chain does not reduce any quantity to a fitted parameter defined from the same performance data, nor does any equation equate an output to its input by construction. The motivating principle is imported from prior HT-SR literature rather than derived inside the paper; the empirical outperformance claims rest on direct comparisons under matched budgets, not on self-referential definitions. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heavy-Tailed Self-Regularization (HT-SR) theory can predict neural network model quality without access to training or testing data.
Reference graph
Works this paper leans on
-
[1]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
12 Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Haojie Duanmu, Xiuhong Li, Zhihang Yuan, Size Zheng, Jiangfei Duan, Xingcheng Zhang, and Dahua Lin. Mxmoe: Mixed-precision quantization for moe with accuracy and performance co-design.arXiv preprint arXiv:2505.05799,
-
[5]
Qmoe: Practical sub-1-bit compression of trillion-parameter models.arXiv preprint arXiv:2310.16795,
Elias Frantar and Dan Alistarh. Qmoe: Practical sub-1-bit compression of trillion-parameter models.arXiv preprint arXiv:2310.16795,
-
[6]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[8]
A. Gholami, Z. Yao, S. Kim, C. Hooper, M. W. Mahoney, and K. Keutzer. AI and memory wall. Technical Report Preprint: arXiv:2403.14123,
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Di He, Songjun Tu, Ajay Jaiswal, Li Shen, Ganzhao Yuan, Shiwei Liu, and Lu Yin
URLhttps://arxiv.org/abs/2506.14562. Di He, Songjun Tu, Ajay Jaiswal, Li Shen, Ganzhao Yuan, Shiwei Liu, and Lu Yin. Alphadecay: Module-wise weight decay for heavy-tailed balancing in LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026a. URLhttps://openreview.net/forum?id=MKEDsVWHd0. Di He, Songjun Tu, Keyu Wang, Lu Y...
-
[11]
L. Hodgkinson, Z. Wang, and M. W. Mahoney. Models of heavy-tailed mechanistic universality. Technical Report Preprint: arXiv:2506.03470,
-
[12]
Xing Hu, Zhixuan Chen, Dawei Yang, Zukang Xu, Chen Xu, Zhihang Yuan, Sifan Zhou, and Jiangyong Yu. Moequant: Enhancing quantization for mixture-of-experts large language models via expert-balanced sampling and affinity guidance.arXiv preprint arXiv:2505.03804, 2025a. Yuanzhe Hu, Kinshuk Goel, Vlad Killiakov, and Yaoqing Yang. Eigenspectrum analysis of neu...
-
[13]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Vignesh Kothapalli, Tianyu Pang, Shenyang Deng, Zongmin Liu, and Yaoqing Yang. Crafting heavy-tails in weight matrix spectrum without gradient noise.arXiv preprint arXiv:2406.04657,
-
[15]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[16]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024a. Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Cha...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
C. H. Martin and M. W. Mahoney. Rethinking generalization requires revisiting old ideas: statistical mechanics approaches and complex learning behavior. Technical Report Preprint: arXiv:1710.09553,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
OLMoE: Open Mixture-of-Experts Language Models
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, et al. Olmoe: Open mixture-of-experts language models.arXiv preprint arXiv:2409.02060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The curse of depth in large language models.arXiv preprint arXiv:2502.05795,
15 Wenfang Sun, Xinyuan Song, Pengxiang Li, Lu Yin, Yefeng Zheng, and Shiwei Liu. The curse of depth in large language models.arXiv preprint arXiv:2502.05795,
-
[21]
Wei Tao, Haocheng Lu, Xiaoyang Qu, Bin Zhang, Kai Lu, Jiguang Wan, and Jianzong Wang. Moqae: Mixed-precision quantization for long-context llm inference via mixture of quantization-aware experts. arXiv preprint arXiv:2506.07533,
-
[22]
Automated fine-grained mixture-of-experts quantization
Zhanhao Xie, Yuexiao Ma, Xiawu Zheng, Fei Chao, Wanchen Sui, Yong Li, Shen Li, and Rongrong Ji. Automated fine-grained mixture-of-experts quantization. InFindings of the Association for Computational Linguistics: ACL 2025, pages 27024–27037,
2025
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[25]
Zihao Zheng, Xiuping Cui, Size Zheng, Maoliang Li, Jiayu Chen, Yun Liang, and Xiang Chen. Dynamo: Runtime switchable quantization for moe with cross-dataset adaptation.arXiv preprint arXiv:2503.21135,
-
[26]
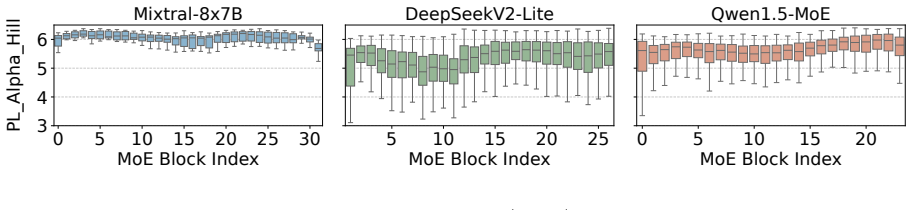
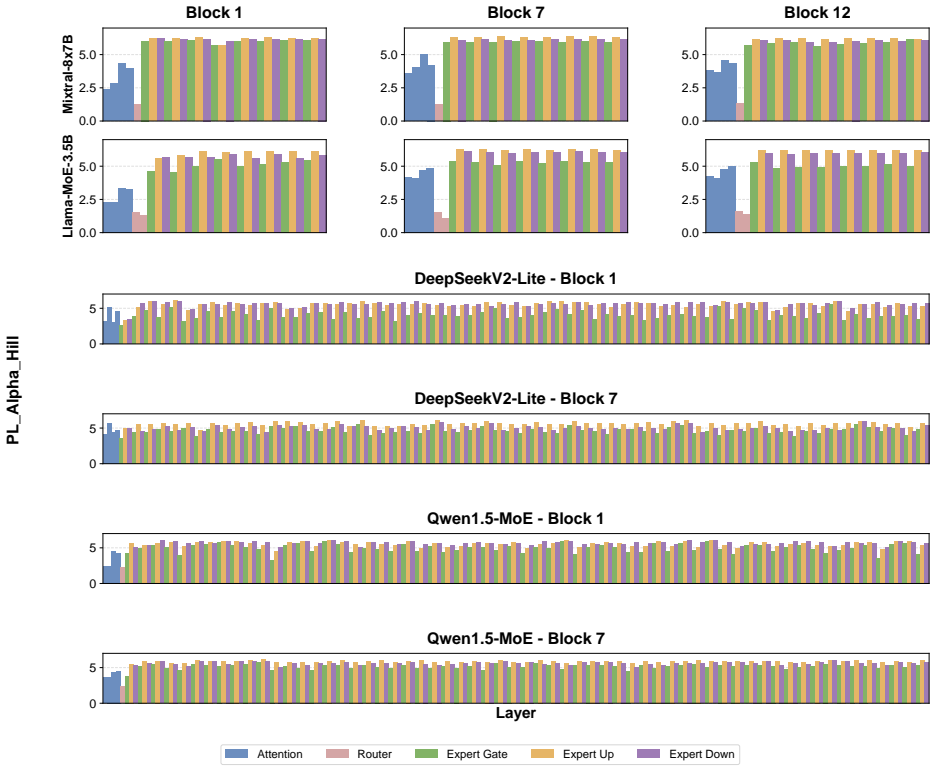
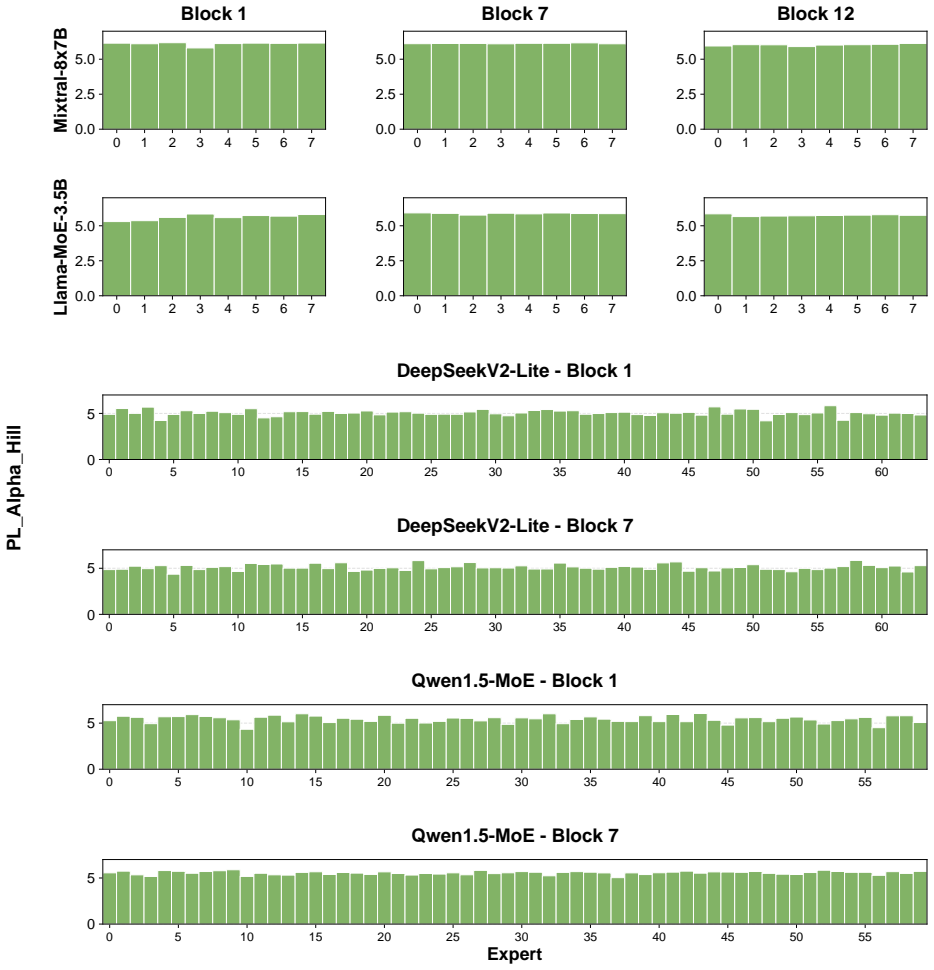
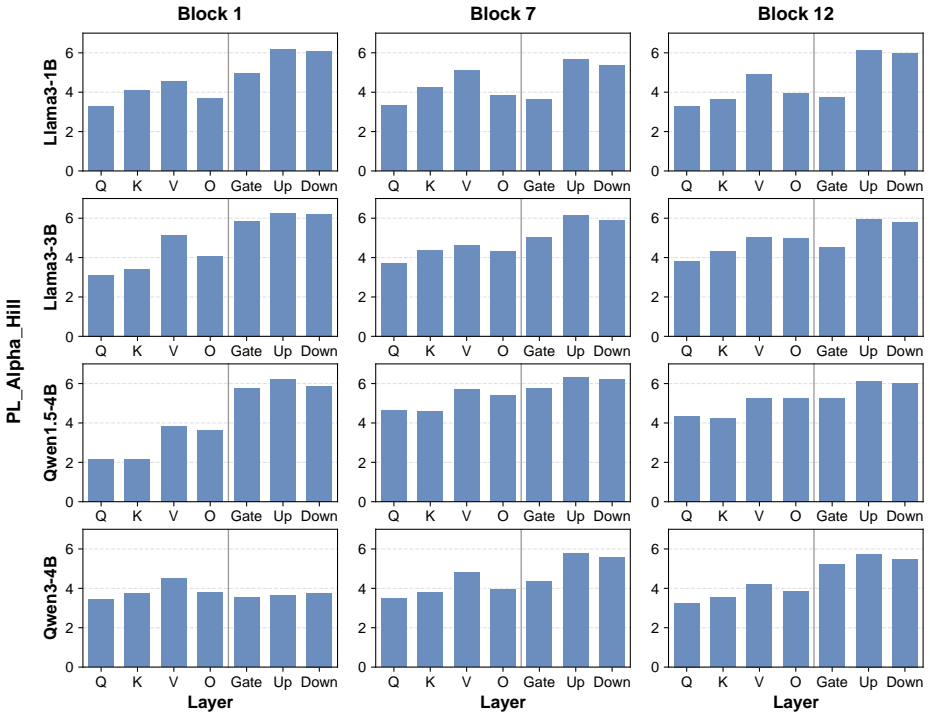
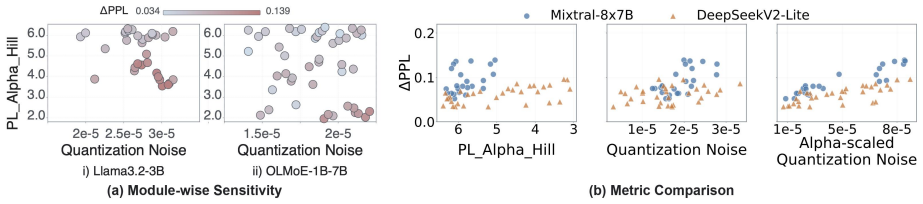
These results show that experts within the same MoE layer can exhibit differentPL_Alpha_Hill values, indicating that expert importance is heterogeneous even within a single block. For comparison, Figure 9 reports layer- wisePL_Alpha_Hilldistributions for four non-MoE models, including Llama3-1B (Grattafiori et al., 2024), Llama3-3B, Qwen1.5-4B (Team, 2024...
2024
-
[27]
19 0 1 2 3 4 5 6 7 0.0 2.5 5.0Mixtral-8x7B Block 1 0 1 2 3 4 5 6 7 0.0 2.5 5.0 Block 7 0 1 2 3 4 5 6 7 0.0 2.5 5.0 Block 12 0 1 2 3 4 5 6 7 0.0 2.5 5.0Llama-MoE-3.5B 0 1 2 3 4 5 6 7 0.0 2.5 5.0 0 1 2 3 4 5 6 7 0.0 2.5 5.0 0 5 10 15 20 25 30 35 40 45 50 55 60 0 5 DeepSeekV2-Lite - Block 1 0 5 10 15 20 25 30 35 40 45 50 55 60 0 5 DeepSeekV2-Lite - Block 7 0...
2008
-
[28]
and Uniform under four bits-per-layer budget settings: 2.0 / 2.5 / 3.0 / 3.5. For evaluation, we report perplexity (PPL↓) on WikiText2 and average zero-shot accuracy (Avg.↑) over six benchmarks: PIQA (Bisk et al., 2020), ARC-Easy, ARC-Challenge (Clark et al., 2018), HellaSwag (Zellers et al., 2019), WinoGrande (Sakaguchi et al., 2021), and BoolQ (Clark et al.,
2020
-
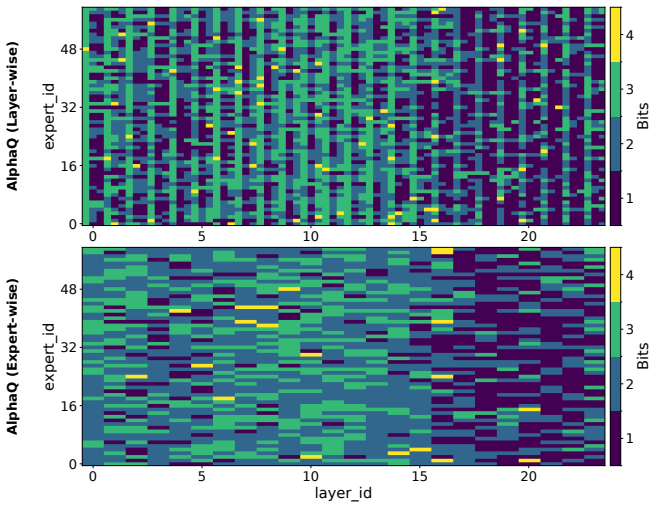
[29]
using the EleutherAI LM Harness (Gao et al., 2024). In Figure 12, Figure 13, and Figure 14, we report detailed bit allocation results from AlphaQ under a 2-bit budget, with both layer-wise and expert-wise settings. 23 Table 7: Results on DeepSeekV2-Lite. Perplexity↓on WikiText2 and accuracy↑on six zero-shot tasks. The best results in each bit-width are hi...
-
[30]
We therefore implement decode-specific fused Triton kernels that fuse unpacking, dequantization, and GEMM into a single kernel
backend: a CUDA kernel performs bit unpacking and dequantization, followed byTensorCoreGEMM.Profilingshowsthisdecompositionishighlyeffectiveinprefill, whichiscompute-bound, but yields limited speedups in memory-bound decode due to data movement between the dequantization and GEMM; concretely,Memcpy HtoD and aten::copy_ become dominant in decode. We theref...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.