CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
Pith reviewed 2026-06-28 06:10 UTC · model grok-4.3
The pith
A single transformer model jointly retrieves city-scale aerial matches and regresses precise 3-DoF pose from ground images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
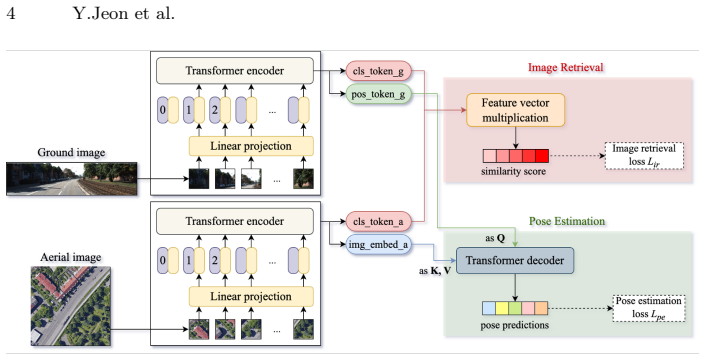
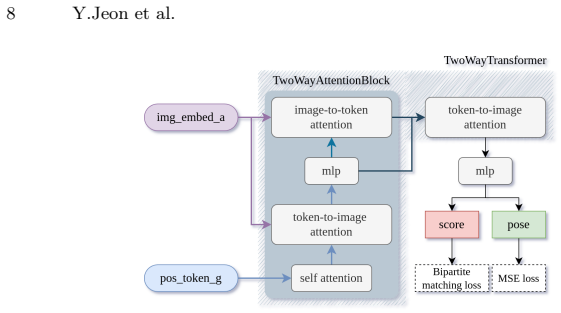
CIPER formulates cross-view geo-localization as simultaneous city-scale retrieval and 3-DoF pose estimation inside one network. A shared transformer encoder with task-specific tokens produces both global retrieval features and spatial localization cues. A two-way transformer pose decoder then performs bidirectional cross-attention that uses ground features as queries to close the domain gap. Set prediction under a unified multi-task loss yields stable regression without separate stages.
What carries the argument
shared transformer encoder with task-specific tokens that disentangles global retrieval features from spatial localization cues, together with a two-way transformer pose decoder that performs bidirectional cross-attention between ground and aerial views
If this is right
- Retrieval and pose estimation can be trained together so each task supplies supervisory signal to the other.
- No intermediate retrieval step is required before pose regression, removing one source of error accumulation.
- The same architecture remains effective when ground images have narrow fields of view or unknown heading.
- Set prediction replaces direct regression for the three pose parameters and stabilizes training under the joint objective.
Where Pith is reading between the lines
- The same token-disentanglement pattern could be tested on other cross-domain retrieval-plus-regression problems such as visual place recognition followed by metric localization.
- If the domain gap between views is reduced by the bidirectional decoder, similar attention patterns might help in other modality-mismatched settings like RGB-to-depth or satellite-to-street.
- Joint training may lower total parameter count and inference latency compared with maintaining two separate networks.
Load-bearing premise
A shared encoder can separate global match information from local geometry signals while the two-way decoder reliably bridges the large appearance gap between ground and aerial images.
What would settle it
On VIGOR, KITTI, or Ford Multi-AV, a cascaded retrieval-then-pose pipeline or two independent models would match or exceed CIPER's accuracy under limited field-of-view and arbitrary-orientation conditions.
Figures


read the original abstract
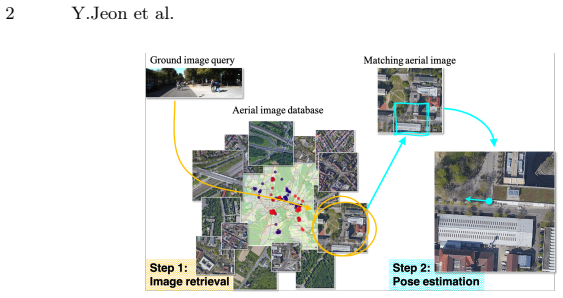
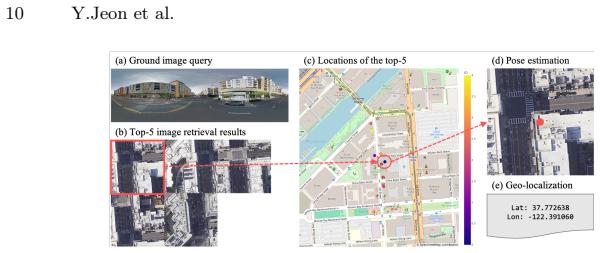
Cross-view geo-localization estimates the geographic location of a ground image by matching it against an aerial image database. Existing methods tackle this through either large-scale retrieval or precise pose estimation, but not both: retrieval-based methods enable wide-area search at the cost of localization accuracy, while pose estimation methods achieve high precision within only a narrow search space. Naively cascading these pipelines introduces error propagation and inconsistent feature representations. We formulate cross-view geo-localization as a unified problem requiring simultaneous city-scale retrieval and precise 3-DoF pose estimation. We propose CIPER (Cross-view Image-retrieval and Pose-estimation transformER), a single architecture that jointly performs both tasks through mutually beneficial feature learning. CIPER uses a shared transformer encoder with task-specific tokens to disentangle global retrieval features from spatial localization cues. To bridge the large domain gap between ground and aerial views, we introduce a two-way transformer pose decoder that uses ground features as spatial queries for bidirectional cross-attention. A set prediction strategy further enables stable 3-DoF regression under a unified multi-task objective. Experiments on VIGOR, KITTI, and Ford Multi-AV demonstrate competitive performance, especially under limited field-of-view and arbitrary orientation conditions. Code is available at https://github.com/yurimjeon1892/CIPER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CIPER, a single transformer architecture for unified cross-view geo-localization that jointly solves city-scale image retrieval and precise 3-DoF pose estimation. It employs a shared encoder with task-specific tokens to separate global and spatial features, a two-way transformer pose decoder with bidirectional cross-attention to address the ground-aerial domain gap, and set prediction for stable regression under a multi-task objective. Experiments are reported on VIGOR, KITTI, and Ford Multi-AV, with emphasis on limited-FOV and arbitrary-orientation cases; code is released.
Significance. If the joint-training results hold with clear gains over separate pipelines, the work would be significant for eliminating error propagation and inconsistent features in cascaded retrieval-plus-pose systems. The open-source code is a clear strength for reproducibility.
major comments (1)
- [Abstract, §4] Abstract and §4 (Experiments): the central claim of 'mutually beneficial feature learning' and 'competitive performance' is stated without any quantitative metrics, tables, error bars, or ablation results on the multi-task loss; this directly limits verification of whether the shared encoder and two-way decoder deliver the advertised joint benefit.
minor comments (2)
- [§3.3] The multi-task objective is described in prose but would benefit from an explicit equation showing the retrieval loss, pose regression loss, and any weighting coefficients.
- [Figure 2] Figure 2 (architecture diagram) would be clearer with explicit labels for the task-specific tokens and the direction of the bidirectional cross-attention.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and commit to revisions that strengthen the quantitative support for our claims.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the central claim of 'mutually beneficial feature learning' and 'competitive performance' is stated without any quantitative metrics, tables, error bars, or ablation results on the multi-task loss; this directly limits verification of whether the shared encoder and two-way decoder deliver the advertised joint benefit.
Authors: We agree that the manuscript would benefit from more explicit quantitative evidence. While §4 reports competitive results on VIGOR, KITTI, and Ford Multi-AV (including limited-FOV and arbitrary-orientation cases), we did not include dedicated ablations isolating the multi-task loss or direct head-to-head comparisons of the joint model versus separate retrieval-plus-pose pipelines with error bars. In the revision we will add a new ablation table and associated text in §4 that quantifies performance differences under joint versus separate training, along with standard deviations from repeated runs, to directly substantiate the mutual-benefit claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes a new neural architecture (CIPER) for joint cross-view retrieval and 3-DoF pose estimation. Its central claims rest on the design of a shared transformer encoder with task-specific tokens, a two-way pose decoder, and a set-prediction loss; these are presented as engineering choices motivated by standard transformer practices rather than as derivations that reduce to fitted inputs or self-citations. No equations are shown that equate a claimed prediction to a parameter fit by construction, and the experimental results on VIGOR, KITTI, and Ford Multi-AV are reported as empirical outcomes, not as tautological consequences of the model definition. The architecture description is self-contained and does not invoke load-bearing uniqueness theorems or ansatzes from the authors' prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The International Journal of Robotics Research39(12), 1367–1376 (2020)
Agarwal, S., Vora, A., Pandey, G., Williams, W., Kourous, H., McBride, J.: Ford multi-av seasonal dataset. The International Journal of Robotics Research39(12), 1367–1376 (2020)
2020
-
[2]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., Sivic, J.: Netvlad: Cnn ar- chitecture for weakly supervised place recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5297–5307 (2016)
2016
-
[3]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
The International Journal of Robotics Research32(11), 1231–1237 (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The International Journal of Robotics Research32(11), 1231–1237 (2013)
2013
-
[6]
Hu, S., Feng, M., Nguyen, R.M., Lee, G.H.: Cvm-net: Cross-view matching net- workforimage-basedground-to-aerialgeo-localization.In:ProceedingsoftheIEEE Conference on Computer Vision and Pattern Recognition. pp. 7258–7267 (2018)
2018
-
[7]
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. arXiv preprint arXiv:2304.02643 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
In: ICML deep learning workshop
Koch, G., Zemel, R., Salakhutdinov, R., et al.: Siamese neural networks for one- shot image recognition. In: ICML deep learning workshop. vol. 2, pp. 1–30. Lille (2015)
2015
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lentsch, T., Xia, Z., Caesar, H., Kooij, J.F.: Slicematch: Geometry-guided aggrega- tion for cross-view pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17225–17234 (2023)
2023
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, L., Li, H.: Lending orientation to neural networks for cross-view geo- localization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5624–5633 (2019)
2019
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion
Regmi, K., Shah, M.: Bridging the domain gap for ground-to-aerial image match- ing. In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion. pp. 470–479 (2019)
2019
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shi, Y., Li, H.: Beyond cross-view image retrieval: Highly accurate vehicle local- ization using satellite image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17010–17020 (2022)
2022
-
[13]
Advances in Neural Information Processing Systems 32(2019)
Shi, Y., Liu, L., Yu, X., Li, H.: Spatial-aware feature aggregation for image based cross-view geo-localization. Advances in Neural Information Processing Systems 32(2019)
2019
-
[14]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Shi, Y., Wu, F., Perincherry, A., Vora, A., Li, H.: Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21516–21526 (2023) 16 Y.Jeon et al
2023
-
[15]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(3), 2682–2697 (2022)
Shi, Y., Yu, X., Liu, L., Campbell, D., Koniusz, P., Li, H.: Accurate 3-dof cam- era geo-localization via ground-to-satellite image matching. IEEE Transactions on Pattern Analysis and Machine Intelligence45(3), 2682–2697 (2022)
2022
-
[16]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Shi, Y., Yu, X., Liu, L., Zhang, T., Li, H.: Optimal feature transport for cross- view image geo-localization. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 34, pp. 11990–11997 (2020)
2020
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Toker, A., Zhou, Q., Maximov, M., Leal-Taixé, L.: Coming down to earth: Satellite- to-street view synthesis for geo-localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6488–6497 (2021)
2021
-
[18]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Wang, S., Zhang, Y., Perincherry, A., Vora, A., Li, H.: View consistent purification for accurate cross-view localization. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 8197–8206 (2023)
2023
-
[19]
In: European Conference on Computer Vision
Xia, Z., Booij, O., Manfredi, M., Kooij, J.F.: Visual cross-view metric localization with dense uncertainty estimates. In: European Conference on Computer Vision. pp. 90–106. Springer (2022)
2022
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yan, Q., Zheng, J., Reding, S., Li, S., Doytchinov, I.: Crossloc: Scalable aerial local- ization assisted by multimodal synthetic data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17358–17368 (2022)
2022
-
[21]
Advances in Neural Information Processing Systems34, 29009–29020 (2021)
Yang, H., Lu, X., Zhu, Y.: Cross-view geo-localization with layer-to-layer trans- former. Advances in Neural Information Processing Systems34, 29009–29020 (2021)
2021
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, S., Shah, M., Chen, C.: Transgeo: Transformer is all you need for cross-view image geo-localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1162–1171 (2022)
2022
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, S., Yang, T., Chen, C.: Vigor: Cross-view image geo-localization beyond one- to-one retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3640–3649 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.